- The paper presents a novel multi-model pipeline for generating a demographically balanced synthetic face dataset tailored for verification tasks.
- It quantifies model bias by revealing lower performance for female and East Asian faces, using metrics like TAR and EER.
- The study highlights that realistic ID card style adaptations further degrade verification accuracy and emphasizes ethical concerns.
Designing and Generating Diverse, Equitable Face Image Datasets for Face Verification Tasks
Motivation and Background
The efficacy and fairness of face verification systems in practical applications such as online banking, device authentication, and document verification are fundamentally constrained by bias in existing datasets. Legacy datasets, including LFW, RFW, and CFP-FP, are characterized by overrepresentation of certain demographics (notably white male celebrities) and lack intersectional diversity. This demographic imbalance, combined with unlicensed image sourcing, introduces significant bias and ethical risk, impeding the broad deployment of equitable face verification technologies. Recent advances in synthetic face generation via T2I models and diffusion-based methods offer new possibilities for producing demographically balanced synthetic datasets, potentially redressing these limitations.
Methodology Overview
The work proposes a robust pipeline for generating synthetic face images that are diverse in race, gender, permanent traits, and other facial characteristics relevant to identity card photo constraints. Four diffusion-based T2I models—Stable Diffusion 3.5, CosmicMan, Kandinsky, and FLUX.1—are employed with carefully engineered prompts combining a comprehensive set of facial attributes (A). Prompt engineering is critical, as adherence for less common features (e.g. albinism, vitiligo, Down syndrome) remains challenging for existing generative models (Figure 1).




Figure 1: Prompt adherence issues in T2I models for synthetically generating faces with rare attributes such as albinism, Down syndrome, braces, and vitiligo.
Universal prompt refinements enforce realistic skin details and background uniformity, and negative prompts are used to further suppress undesired traits. Images generated are filtered by automated quality scores and by manual inspection to eliminate failures such as multi-face scenes. The process is repeated to maximize diversity and realism, typically requiring around 20 generations per image.
Example outputs from this multi-model generative pipeline demonstrate the breadth of feature and demographic diversity achievable via this approach (Figure 2).









Figure 2: Synthetic faces generated for a representative set of prompt combinations across racial, gender, and trait diversity, sourced from four different T2I models.
Identity Variation and ID Card Styling
For each unique identity, multiple variations are created using Arc2Face and PuLID generative models, combined recursively for extended diversity. To simulate ID card scenarios, generated images undergo background replacement (using HivisionIDPhotos) and style transfer (using PAMA with 23 nation-specific ID template images). This filter chain modifies the facial renders to more closely emulate real-world ID photo characteristics (Figure 3), enhancing the benchmark's relevance for document-style verification settings.
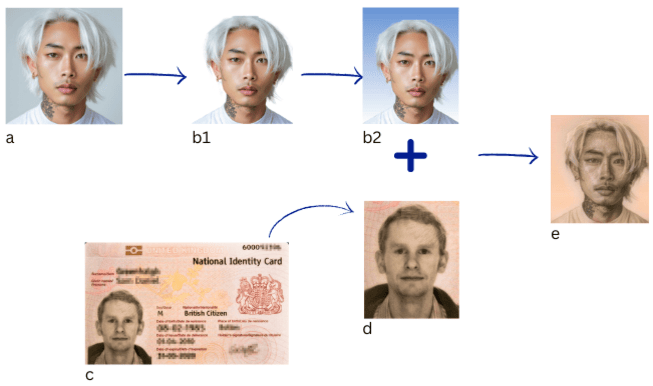
Figure 3: Schematic illustration of style extraction and filtering to match the ID card format for synthetic face images.
DIF-V Dataset Composition
The outcome is the Diverse and Inclusive Faces for Verification (DIF-V) dataset comprising 27,780 images from 926 unique identities. Per identity, 30 image variants (covering diverse traits and styles) are produced. Gender and race distributions are tightly controlled for balance: approximately 300 images per gender and 115 identities per race, across eight racial categories, including representation for Pacific Islanders distinct from other Asian groups.
Empirical Benchmarking and Bias Analysis
Extensive evaluation of state-of-the-art face verification models (ArcFace, Facenet) on DIF-V reveals persistent bias in verification performance. Accuracy, True Acceptance Rate (TAR) at 1% False Acceptance Rate (FAR), Equal Error Rate (EER), and AUC are computed for subgroups by gender and race.
Quantitative results show systematic underperformance of both models for female faces relative to male and non-binary counterparts, especially for ArcFace (Figure 4).
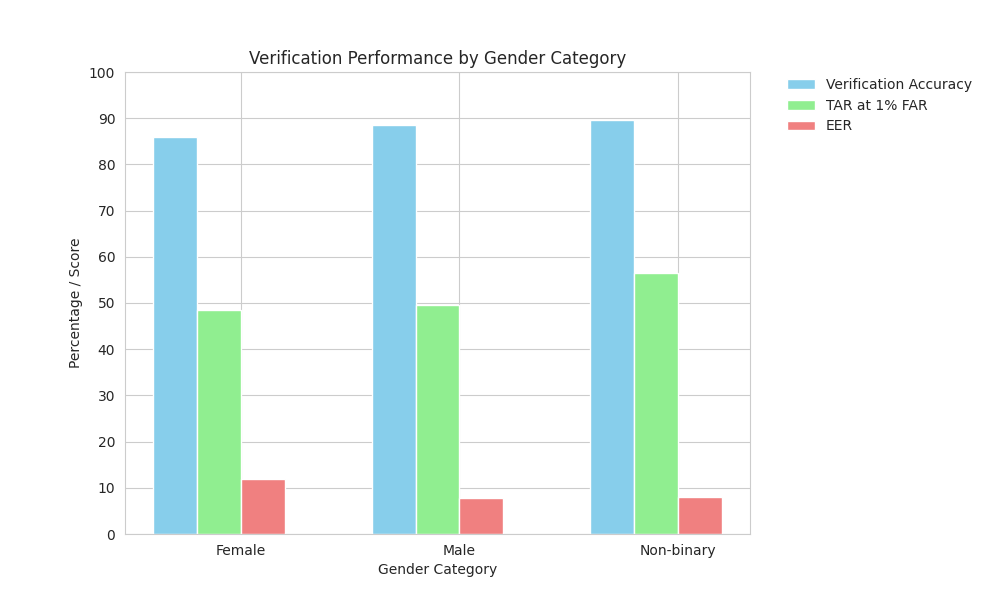
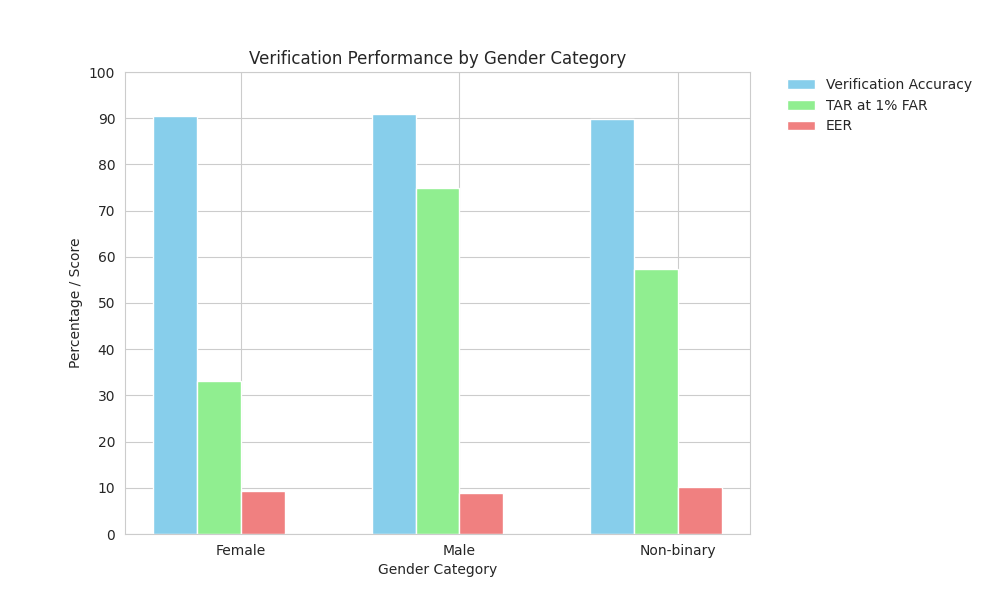
Figure 4: Comparative verification metrics by gender for DIF-V using ArcFace and Facenet; male subgroup consistently achieves highest TAR and lowest EER.
Race subgroup analysis exposes pronounced disparities: models perform worst on East Asian and Southeast Asian faces, while Indian and White faces attain peak accuracy and TAR (Figure 5).
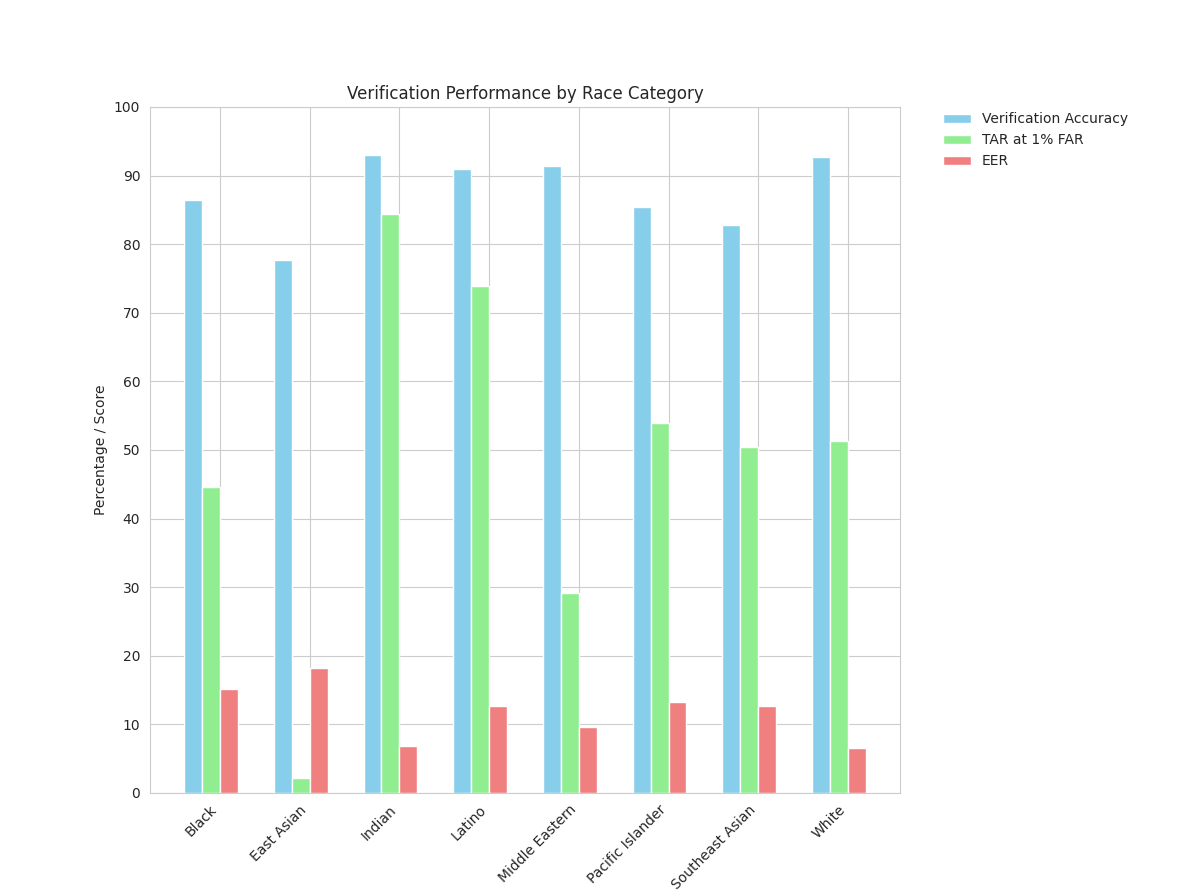
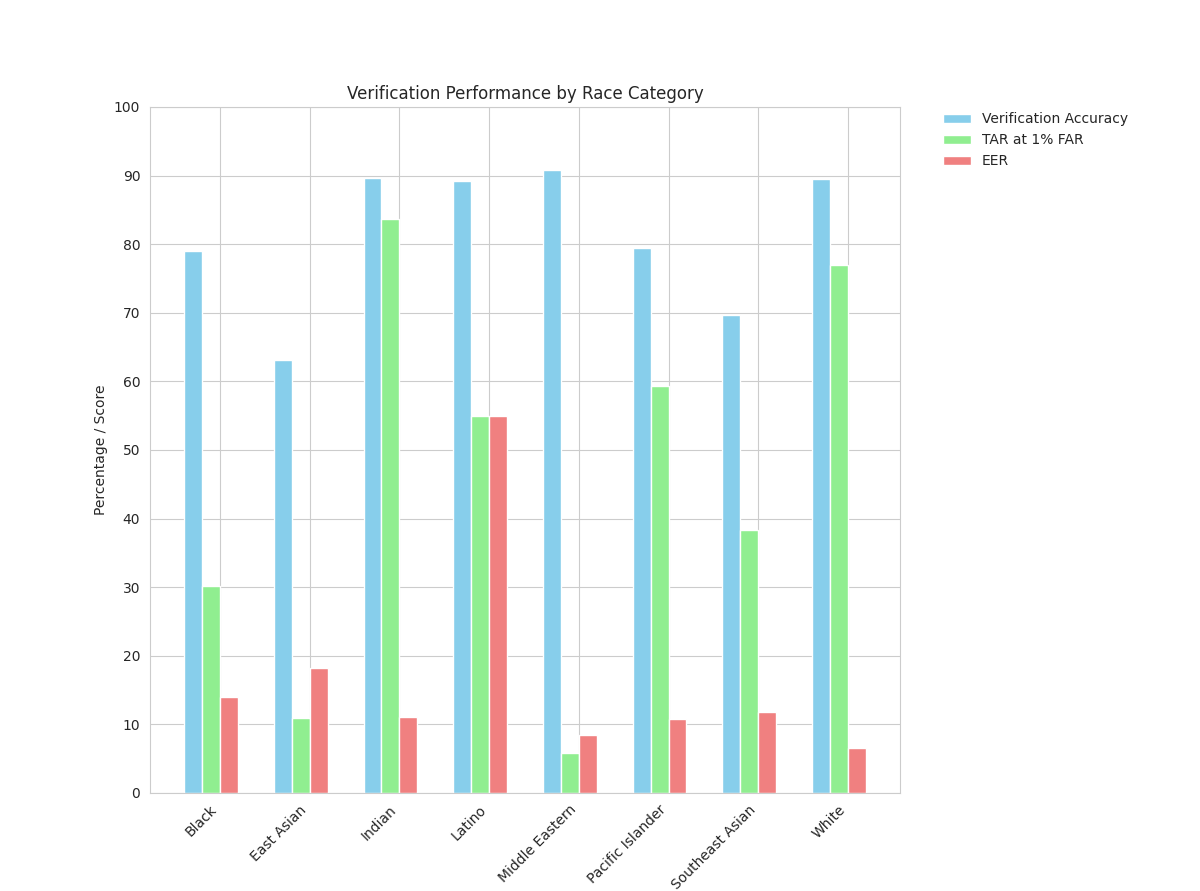
Figure 5: Verification accuracy, TAR, and EER across racial subgroups for ArcFace and Facenet on DIF-V; significant performance penalties are evident for East Asian subgroups.
A critical finding is that applying ID card style transformations to face images further degrades model performance—accuracy and TAR drop substantially post-styling (Figure 6), highlighting the challenge current models face for document-style verification.
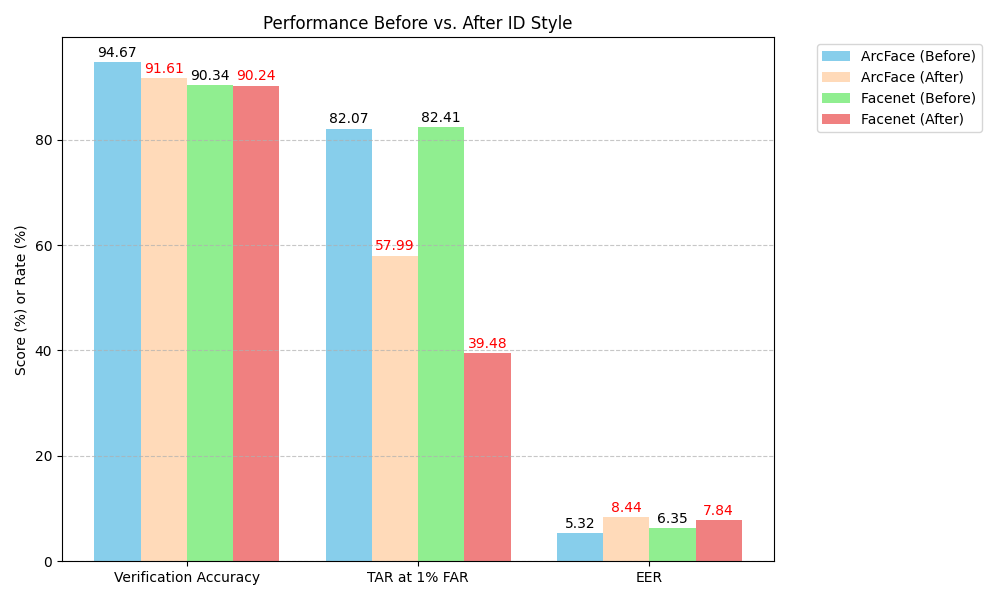
Figure 6: Model performance before and after ID style modification; ID card styling leads to marked deterioration in verification accuracy and TAR.
Ethical and Societal Considerations
The dataset design and generation pipeline foreground ethical risks endemic to generative models trained on web-scale data, which may encode and amplify gender, race, and other biases present in society. Furthermore, the realistic quality of AI-generated content exacerbates risks of misinformation and misuse, especially with ID-style images for impersonation or fraud. The provenance and attribution of synthetic content is a persistent challenge.
Implications and Future Directions
The DIF-V dataset provides a synthetic, balanced resource for systematic benchmarking and bias auditing of face verification models in demographic and document-specific contexts. The methodology could be expanded by iterating prompt engineering for emergent traits, integrating new generative or editing models, and automating style adaptation for region-specific ID schemas. Numerically, explicit bias metrics (e.g. subgroup calibration errors) could be incorporated alongside verification scores for more granular analysis.
From a model development perspective, these findings underscore the vulnerability of current state-of-the-art verification models to demographic and style transfer shifts, motivating research into debiasing algorithms, prompt-robust generative models, and fine-tuning schemes tailored for equitable verification performance across diverse populations and scenarios. The pipeline establishes a reproducible framework for developing and auditing future synthetic datasets targeting biometric tasks.
Conclusion
This work offers a comprehensive approach for building large-scale, demographically balanced synthetic face verification datasets, employing advanced diffusion-based generation, attribute-driven prompt engineering, and identity-variant synthesis combined with ID card style adaptation. Rigorous benchmarking on DIF-V exposes persistent verification biases by gender and race and reveals susceptibility to ID style modifications. These results sharpen the need for improved fairness in biometric systems and provide a blueprint for future dataset and model development aimed at robust, inclusive face verification.

