Misaligned by Design: Incentive Failures in Machine Learning
Abstract: The cost of error in many high-stakes settings is asymmetric: misdiagnosing pneumonia when absent is an inconvenience, but failing to detect it when present can be life-threatening. Because of this, AI models used to assist such decisions are frequently trained with asymmetric loss functions that incorporate human decision-makers' trade-offs between false positives and false negatives. In two focal applications, we show that this standard alignment practice can backfire. In both cases, it would be better to train the machine learning model with a loss function that ignores the human's objective and then adjust predictions ex post according to that objective. We rationalize this result using an economic model of incentive design with endogenous information acquisition. The key insight from our theoretical framework is that machine classifiers perform not one but two incentivized tasks: choosing how to classify and learning how to classify. We show that while the adjustments engineers use correctly incentivize choosing, they can simultaneously reduce the incentives to learn. Our formal treatment of the problem reveals that methods embraced for their intuitive appeal can in fact misalign human and machine objectives in predictable ways.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how we train AI systems to make important decisions, like spotting pneumonia in chest X-rays. People often tell the AI: “Missing pneumonia is much worse than mistakenly saying someone has it,” so they train the AI with extra penalties for the worse mistake. The authors show that this common practice can backfire. Surprisingly, it can be better to train the AI in a neutral way first, and only afterward adjust its predictions to match the human goals.
Key Questions
To make the ideas clear, the paper asks three simple questions:
- Does training the AI with the human’s preferences baked into its training make it perform better?
- Why might that kind of training actually make the AI learn less useful information?
- Is it better to train normally and then adjust the AI’s predictions at the end to match what people care about?
Methods and Approach
The authors use both real experiments and a simple theory to explore the problem.
- Two real-world tests:
- Medical diagnosis: training a deep neural network to detect pneumonia from chest X-rays.
- Image recognition: training a transformer model on CIFAR (a popular dataset of photos) to identify hard-to-spot categories.
- Two training strategies:
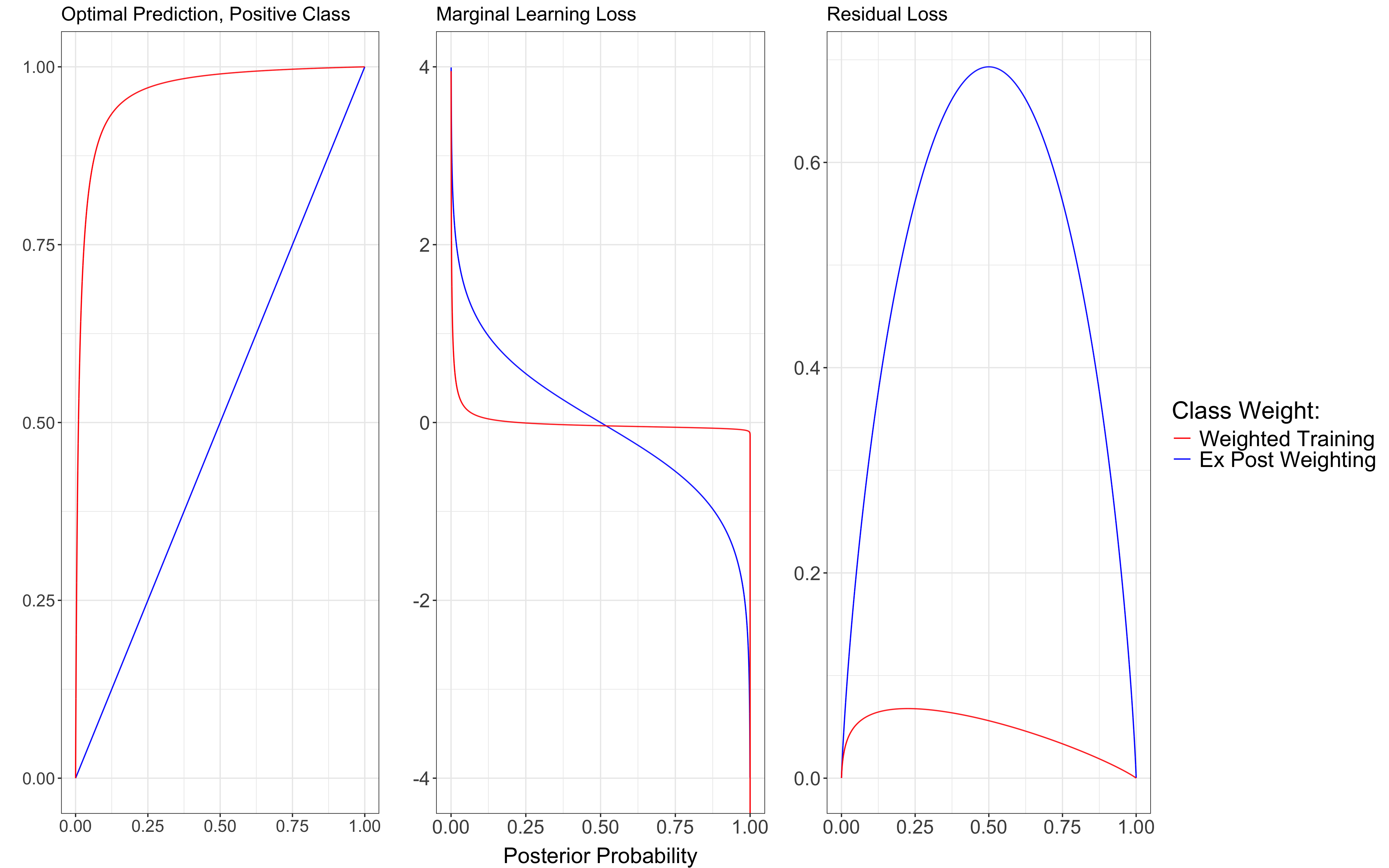
- Weighted Training: train the AI with a “tilted” loss function that punishes some mistakes more than others (for example, missing pneumonia is punished far more than falsely saying pneumonia is present).
- Ex Post Weighting: train the AI with a standard loss function (neutral, not tilted), and after training, adjust the model’s outputs to reflect what humans care about (for example, shift the thresholds so the AI errs on the safe side).
- A big idea from their theory:
- An AI does two jobs, not one:
- 1) Choosing: making a prediction based on what it knows.
- 2) Learning: figuring out which features matter and how to tell classes apart.
- Training with heavy weights (punishments) correctly nudges the AI’s choices (it will favor catching positives, like pneumonia). But it can accidentally make learning worse. Why? Because most AI learning uses something like “gradient descent,” which is like walking downhill toward the best solution. Changing the loss function changes the shape of the hill. If the hill gets too flat in the places where learning happens, the AI has less “pull” to learn fine details. In other words, heavily tilted training can make the model confident too soon, even when it hasn’t learned enough to justify that confidence.
Think of it like studying for a test:
- Weighted Training says, “Getting question type A wrong is terrible!” That might make you always guess “A” even when you’re unsure, so you stop studying the harder parts closely.
- Ex Post Weighting says, “Study normally to learn everything well,” and then, on test day, “If you’re unsure, lean toward answering A.” This way, you still learn deeply first.
Main Findings
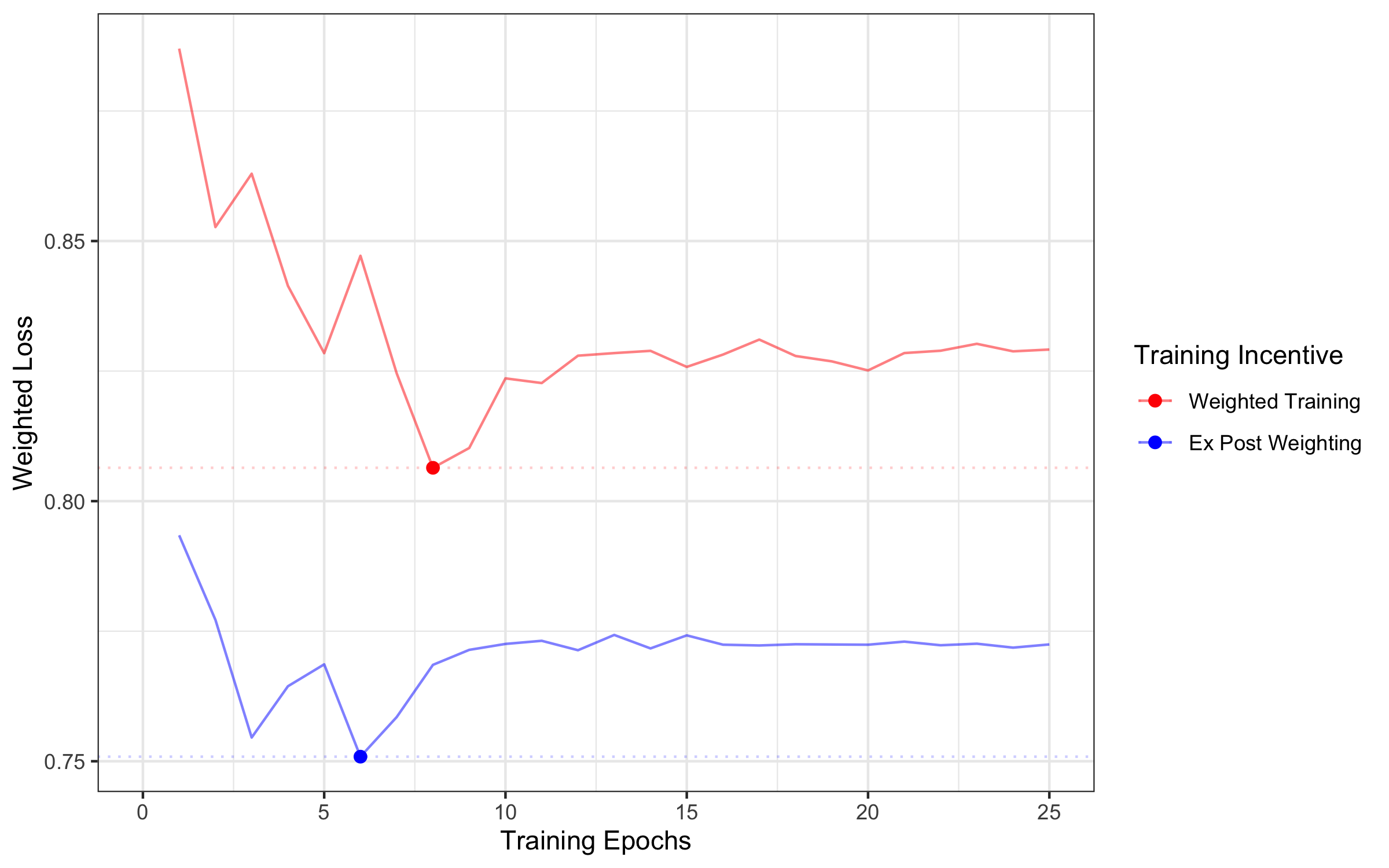
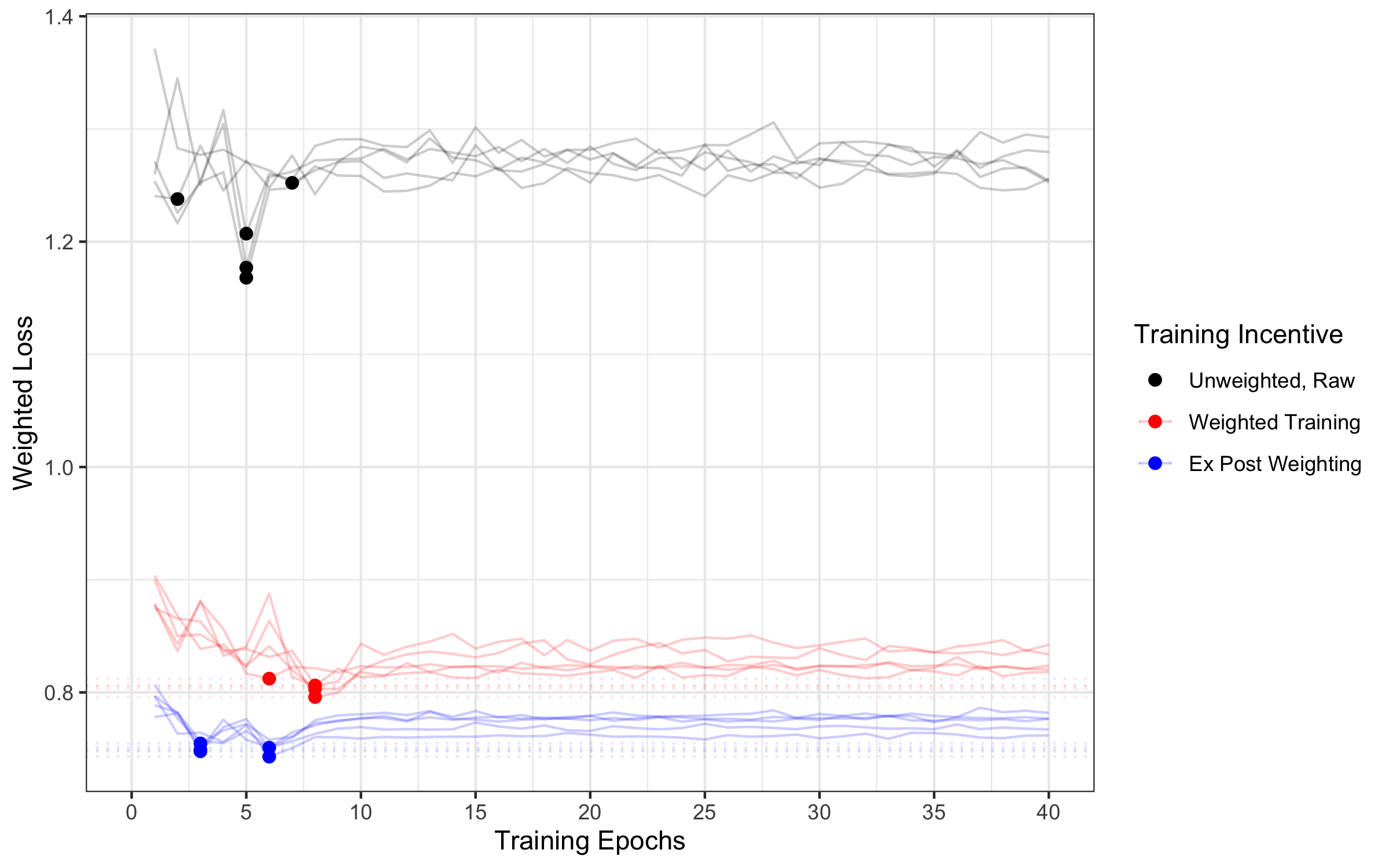
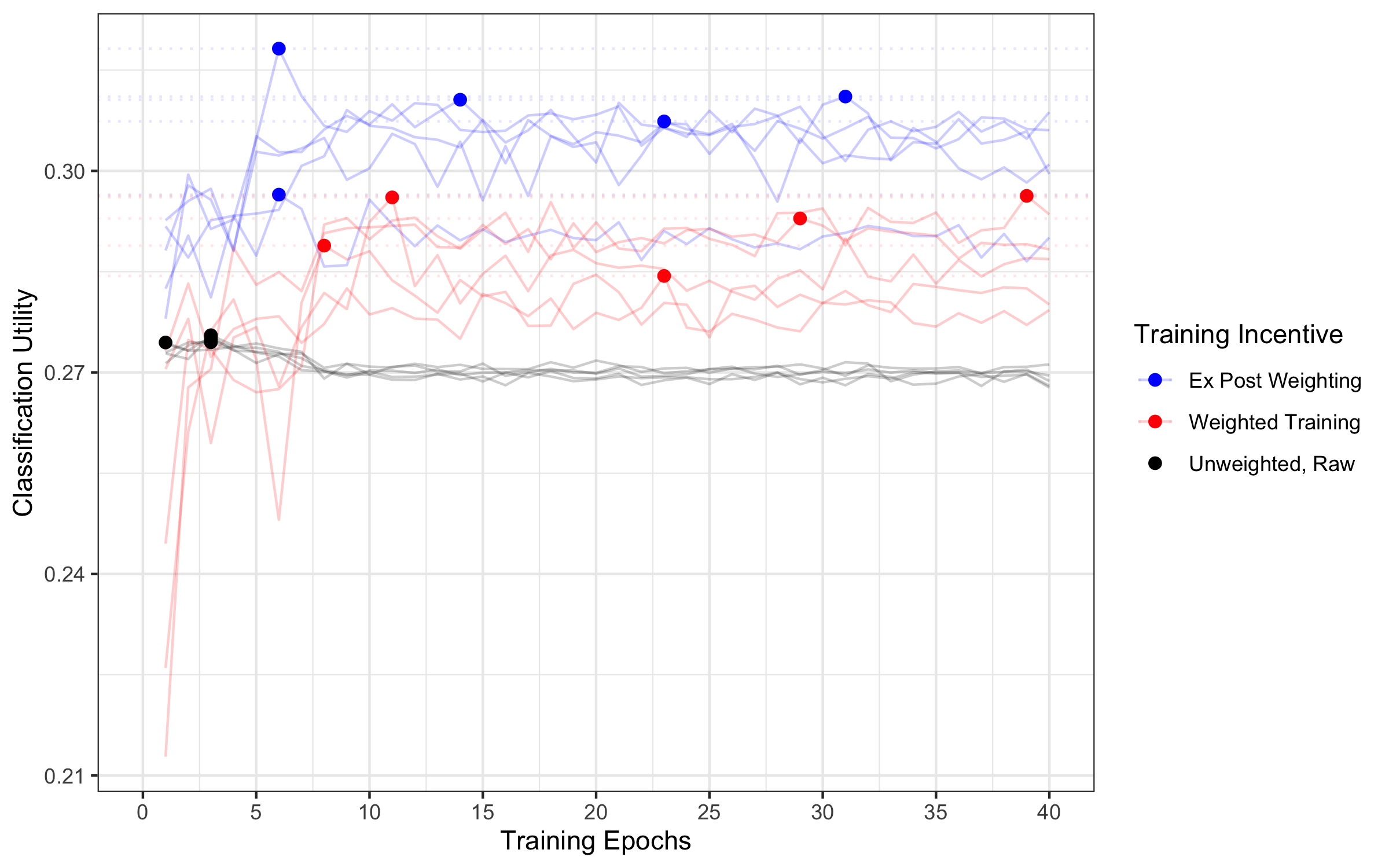
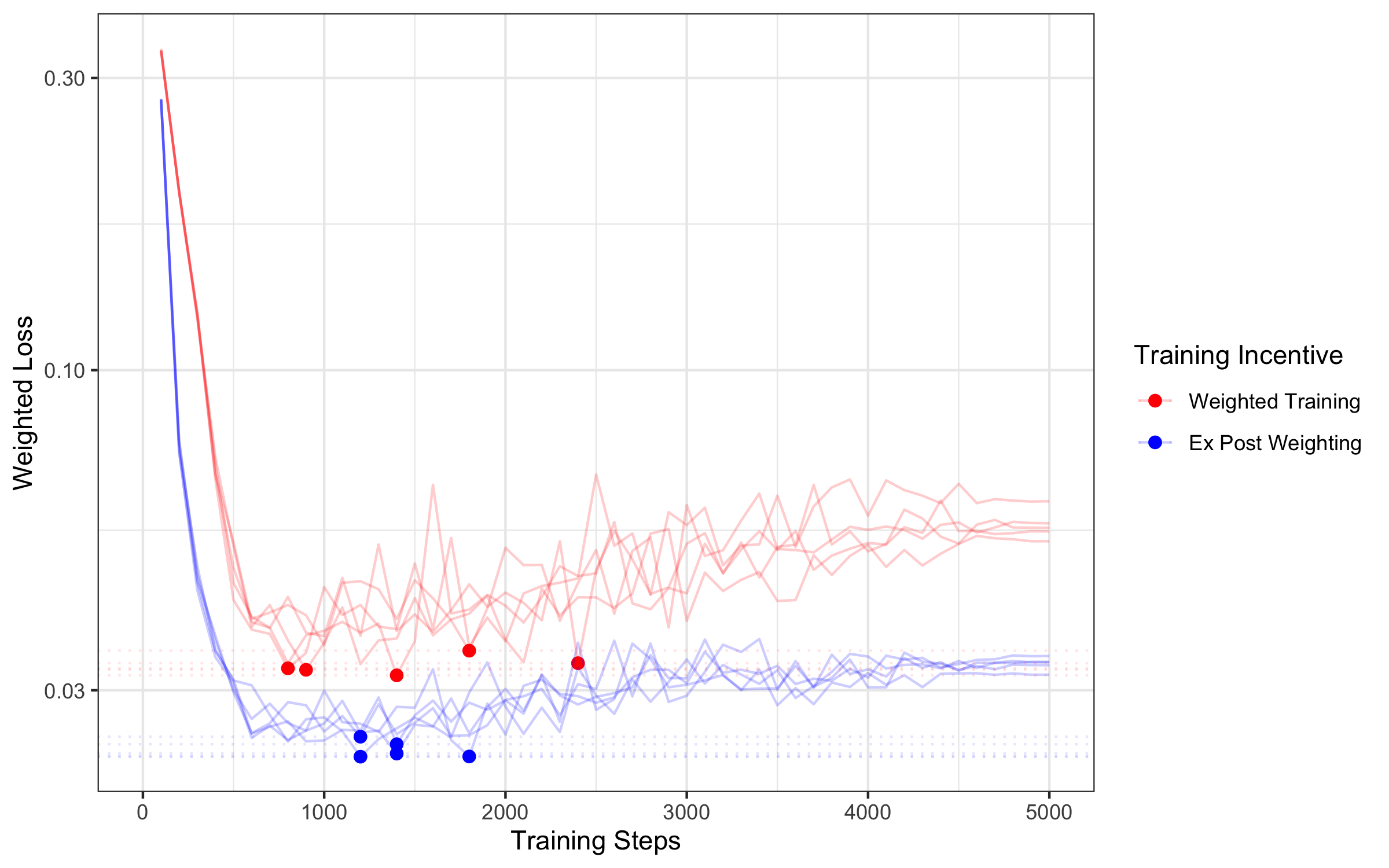
- In both the medical X-ray task and the CIFAR image task, training with neutral loss and adjusting outputs afterward worked better than weighting during training.
- Even when judged by the weighted goal itself (the very thing the weights were meant to optimize), Ex Post Weighting won. That’s a strong result: the “train neutral, adjust later” method does better at the human’s own objective.
- Example: In the pneumonia detection task, the “train neutral, adjust later” approach consistently had lower weighted loss (roughly a 7% improvement) compared to training with weights from the start.
- Why it happens: Weighted Training inflates the model’s predictions toward the favored class (like “pneumonia”), which reduces the model’s incentive to learn more precise information. Ex Post Weighting keeps learning incentives strong, then adjusts decisions afterward to match the human priorities.
Implications and Impact
This work changes how we think about “alignment” (making AI do what people intend):
- Don’t bake all human preferences into the training loss. That can misalign the model’s learning incentives and lead to worse results.
- Do train the model to learn as well as possible first, and then adjust its predictions to reflect real-world costs and ethics. This separates learning (getting good information) from choosing (making the final call), which makes both steps work better.
- Practical impact:
- In medicine, this can mean safer diagnostics: the model learns more detailed signals and still errs on the side of caution after training.
- In finance or safety-critical systems, it can reduce costly mistakes without hurting the model’s ability to learn.
- Big picture: The paper shows that AI training is also an “incentive design” problem. If we shape incentives the wrong way, we may get confident but shallow learning. If we shape them wisely, we get deeper learning and better decisions.
In short, the best strategy is to let the AI become a strong learner first, and then align its final decisions with human values afterward.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following points summarize what remains missing, uncertain, or unexplored, and suggest concrete directions for future research:
- Generality across tasks and modalities: Assess whether ALP failures persist beyond image classification to NLP, tabular, time-series forecasting, structured prediction, and multi-label settings common in medical imaging.
- Scope of architectures: Test the phenomenon across a broader range of models (e.g., CNNs of varying depth, RNNs, graph neural networks, LLMs, self-supervised and foundation models) to determine architecture-specific effects.
- Loss function coverage: Examine non–strictly-proper and margin-based losses (e.g., hinge loss, focal loss, Tversky loss), regression losses, and ranking/surrogate losses to see whether the learning-incentive dampening persists outside strictly proper scoring rules.
- Weight magnitude and thresholds: Characterize analytically and empirically the weight ratios (and utility structures) at which weighted training begins to harm learning; identify sufficient/necessary conditions for misalignment as a function of and .
- Calibration dependence: Quantify how miscalibration affects ex post utility transformations; systematically compare unweighted training + calibration (temperature scaling, isotonic) against weighted training with and without calibration.
- Practical post-processing beyond argmax: Evaluate decision rules relevant to deployments (thresholded treatment decisions, decision curves, ROC/PR-based cost optimization, top-k, abstention/deferral) versus the paper’s argmax mapping.
- Representation-level impacts: Measure how utility-weighted training alters learned representations relative to unweighted training (e.g., CKA similarity, probing tasks, linear separability), and whether representational changes explain performance differences.
- Finite-sample regimes and variance-bias trade-offs: Analyze whether weighted training offers variance reduction for rare classes in small data regimes, and when that potential benefit outweighs learning-incentive dampening.
- Class-imbalance remedies: Benchmark ex post weighting against alternative tactics (focal loss, logit adjustment, oversampling/undersampling, SMOTE, cost-sensitive re-sampling, label smoothing) under matched budgets and controls.
- Multi-label clinical classification: Clarify how the proposed ex post utility mapping extends to multi-label predictions (common in ChestX-ray14) and evaluate per-label versus joint decision utilities.
- Distribution shift and robustness: Test stability under covariate, label, and prior shifts; measure calibration drift and decision robustness for ex post weighting vs weighted training in out-of-distribution settings.
- Adversarial and noise robustness: Investigate susceptibility to adversarial perturbations and label noise; determine whether one approach yields more robust decision boundaries or uncertainty estimates.
- Optimizer and training dynamics: Assess sensitivity to optimizer choice (SGD, Adam, AdamW), learning-rate schedules, momentum, batch size, regularization (weight decay, dropout), warm-up, early stopping, and mixed precision.
- Hybrid and curriculum strategies: Explore training schedules that decouple learning and choosing (e.g., unweighted pretraining followed by mild weighting, curriculum-weight schedules that anneal weights over time), and compare to pure ex post adjustments.
- Utility elicitation and misspecification: Develop methods to elicit, validate, and update human utility functions; quantify performance sensitivity to misspecified or time-varying utility weights and to heterogeneous stakeholder objectives.
- Multi-objective and constrained settings: Extend the framework to multiple competing objectives (e.g., accuracy, recall, fairness, cost) and constrained optimization (e.g., minimum recall constraints), comparing ex post post-processing to Lagrangian/constrained training.
- Fairness and subgroup effects: Evaluate subgroup error rates, calibration, and fairness metrics (EO, DP) under ex post vs weighted training, including group-specific utilities/thresholds and their impact on disparities.
- Theoretical bounds on learning incentives: Provide formal bounds or comparative statics for the residual learning loss gradient under utility weighting, and characterize regimes where weighting could increase learning incentives (as suggested for “easy” learning regions).
- Information acquisition costs: Incorporate explicit costs for learning (e.g., computation, exploration) and derive design rules for when and how incentive shaping should prioritize learning versus choice.
- Uncertainty quantification: Compare Bayesian models, ensembles, and conformal prediction under ex post vs weighted training to determine impacts on calibrated uncertainty and decision coverage.
- Clinical utility translation: Link weighted-loss reductions to real clinical outcomes (e.g., mortality, resource use) with clinician-in-the-loop studies; validate utility functions against patient and system-level objectives.
- Statistical rigor and reproducibility: Report confidence intervals, significance tests, and power analyses across many seeds and datasets; release code and detailed protocols for replicability, including precise data splits and preprocessing.
- Alternative ex post mappings: Evaluate simpler deployment-ready adjustments (threshold tuning, cost curves, ROC-based decision optimization, operating-point selection) against the proposed normalization, including implications for calibration and interpretability.
- Label quality sensitivity: Analyze robustness to noisy and weak labels (common in ChestX-ray14), including how ex post transformations interact with label uncertainty and whether denoising or relabeling changes conclusions.
- Downstream pipeline impacts: Study how ex post weighting interacts with clinical workflows, cascading decision systems, and regulators’ requirements for calibrated probabilities versus utility-optimized decisions.
Practical Applications
Overview
Below are practical, real-world applications derived from the paper’s findings and methods. Each item specifies the sector, concrete use case, tools/products/workflows that might emerge, and assumptions or dependencies affecting feasibility. The applications are grouped by immediacy of deployment.
Immediate Applications
The following applications can be adopted now with current tooling and data science practices.
- Healthcare (radiology, triage, decision support)
- Use case: Pneumonia and other condition detection from imaging; triage recommendations that reflect asymmetric error costs (e.g., high cost of false negatives).
- Workflow: Train classifiers with standard proper losses (e.g., unweighted cross-entropy), calibrate predictions, then apply an ex post “utility transformer” to map predicted class probabilities into decision-ready scores using the paper’s rule ; set decision thresholds that reflect clinical utility and hospital policy; audit internal and external alignment by comparing weighted loss and realized clinical utility.
- Tools/products: Alignment layer for PyTorch/TensorFlow; calibration tools (temperature scaling, isotonic regression); threshold optimizers; MLOps templates that separate training objectives from decision policies; alignment audit dashboards.
- Assumptions/dependencies: Availability of calibrated class probabilities; well-specified utility weights; clinical validation and governance; monitoring for dataset shift; ability to implement post-processing in the inference stack.
- Finance (credit underwriting and fraud detection)
- Use case: Calibrated probability-of-default models and fraud detectors where false negatives are costlier than false positives.
- Workflow: Train unweighted models to maximize learning; calibrate; implement ex post policy engines that convert probabilities to actions based on expected profit/loss, regulatory constraints, and risk appetite; dynamically vary thresholds by segment, transaction amount, or macro conditions without retraining.
- Tools/products: Risk policy engine; stakeholder utility configuration; alignment metrics (weighted loss vs. unweighted performance with ex post decisions); A/B testing harnesses.
- Assumptions/dependencies: Reliable calibration; accurate utility/cost models; governance for fairness and compliance; ongoing monitoring under distribution shift.
- Safety and content moderation
- Use case: Moderation of harmful content where missing violations is costlier than over-removal.
- Workflow: Train unweighted classifiers to learn features effectively; calibrate; apply jurisdiction- or platform-specific ex post thresholds and utility mappings; support rapid policy updates without retraining models.
- Tools/products: Policy rule layer; regional policy profiles; audit trail of ex post decisions; alignment scorecards.
- Assumptions/dependencies: Clear, maintainable utility definitions; robust calibration; explainability and appeal mechanisms.
- Hiring and admissions support
- Use case: Candidate screening with asymmetric costs (e.g., missing qualified candidates versus interviewing weaker candidates).
- Workflow: Train unweighted scoring models; calibrate; apply ex post decision thresholds (and fairness constraints) that reflect institutional priorities; document alignment outcomes.
- Tools/products: Fairness-aware post-processing libraries; utility-aware threshold setters; governance dashboards.
- Assumptions/dependencies: Validated calibration; clear stakeholder utilities and fairness requirements; human-in-the-loop review.
- MLOps and model governance
- Use case: Institutionalization of “train-unconstrained, align in post-processing” as a pipeline pattern.
- Workflow: Decouple training objective (proper scoring rule) from deployment objective (utility-aware decisions); add an ex post utility transformer and thresholding module; instrument internal/external alignment metrics; integrate with model cards and documentation.
- Tools/products: SDKs for alignment layers; standard operating procedures (SOPs); compliance-ready documentation templates.
- Assumptions/dependencies: Engineering capacity to modularize inference; stakeholder utilities documented; alignment metrics incorporated into CI/CD.
- Benchmarking and evaluation (industry and academia)
- Use case: Systematic comparison of weighted training versus ex post weighting on internal (weighted loss) and external (utility) alignment metrics.
- Workflow: Add a test harness that trains both regimes, applies post-processing, and reports the paper’s internal/external alignment measures; adopt this as a pre-deployment check.
- Tools/products: Alignment audit toolkit; experiment orchestration scripts; reproducible benchmark reports.
- Assumptions/dependencies: Representative test sets; careful normalization of weights; consistent calibration across runs.
- Policy and procurement guidance
- Use case: Immediate guidance to avoid class-weighted training for alignment when ex post alignment yields better outcomes.
- Workflow: Require vendors to provide calibrated probabilities and post-processing controls; mandate alignment audits; specify documentation for utility definitions and ex post decision policies.
- Tools/products: Procurement checklists; alignment reporting standards; regulator-facing model cards.
- Assumptions/dependencies: Institutional buy-in; clear compliance criteria; capacity to assess alignment reports.
- Daily life (consumer apps)
- Use case: Spam filtering, notification prioritization, home security alerts.
- Workflow: Allow users to adjust alert thresholds and preferences (i.e., cost of missing an alert vs. receiving a false alarm) via ex post settings; keep models trained on unweighted losses for better general learning.
- Tools/products: User-facing “risk/strictness” sliders; calibrated probability displays; local policy rules.
- Assumptions/dependencies: Usable calibration; simple utility proxies; privacy- and resource-aware inference.
Long-Term Applications
These applications require further research, scaling, or development before broad deployment.
- Standards and certification for alignment-by-post-processing
- Use case: Institutionalize best practices that decouple training from decision objectives across sectors (healthcare, finance, public services).
- Products/workflows: ISO/IEEE-like standards; third-party certification; regulatory guidance that endorses ex post alignment when conditions (proper scoring rules, calibration) are met.
- Assumptions/dependencies: Consensus among regulators and standard bodies; robust evidence across diverse domains; reliable auditability.
- Incentive-aware loss design
- Use case: Design new loss functions that preserve strong learning incentives while enabling principled constraints (e.g., robustness, fairness) without dampening gradients.
- Products/workflows: Theoretically grounded “incentive-preserving” losses; hybrid training strategies that manage exploration vs. exploitation.
- Assumptions/dependencies: Formal guarantees; empirical validation across architectures (CNNs, transformers, LLMs).
- Sequential decision-making and reinforcement learning
- Use case: Safe RL with ex post safety shields that implement utility-aware policies without degrading exploration/learning.
- Products/workflows: Policy shields; offline RL pipelines with post-processed decisions; POMDP-aware alignment modules.
- Assumptions/dependencies: Extensions of the paper’s framework beyond classification; practical safety verification; calibrated value estimates.
- Multi-stakeholder welfare aggregation
- Use case: Align decisions to aggregate utilities from multiple stakeholders (patients, clinicians, payers; regulators and platforms; lenders and consumers) via ex post mappings.
- Products/workflows: Governance platforms to define, negotiate, and apply aggregated utility functions; configurable decision policies at runtime.
- Assumptions/dependencies: Methods for eliciting and maintaining utilities; conflict resolution mechanisms; legal and ethical frameworks.
- Dynamic alignment under resource and context constraints
- Use case: Real-time adaptation of ex post policies to staffing levels, bed availability, market volatility, or threat levels without retraining.
- Products/workflows: Context-aware policy engines; scenario-based alignment tuning; simulation-backed policy testing.
- Assumptions/dependencies: High-quality contextual signals; robust calibration under drift; safe policy updates.
- Robustness and distribution shift research
- Use case: Evaluate whether ex post alignment maintains performance under domain shift better than training-time weighting; develop calibration under shift.
- Products/workflows: Shift-aware calibration; domain adaptation with alignment guarantees; monitoring frameworks.
- Assumptions/dependencies: Access to shift detection; scalable recalibration; causal data insights.
- Fairness and welfare-aware post-processing
- Use case: Combine fairness constraints with utility-aware ex post alignment to manage both equity and asymmetric error costs.
- Products/workflows: Post-processing that enforces fairness (e.g., group thresholds) and utility alignment; evaluation suites for trade-offs.
- Assumptions/dependencies: Clear fairness definitions; stakeholder agreement on trade-offs; validated calibration across groups.
- Education and training
- Use case: Update data science curricula and certification programs to teach the separation of learning and decision incentives; highlight pitfalls of weighted training.
- Products/workflows: Course modules; case studies; lab exercises that replicate the paper’s findings.
- Assumptions/dependencies: Curriculum adoption; accessible datasets and tooling; educator training.
- Data and utility elicitation practices
- Use case: Institutional processes to elicit, maintain, and audit utility functions (error costs) used in ex post alignment.
- Products/workflows: Utility elicitation surveys; incident-based re-estimation of utilities; governance logs.
- Assumptions/dependencies: Stakeholder engagement; periodic review processes; ethical oversight.
- AutoML and platform integration
- Use case: Build AutoML features that default to proper scoring rules for training and expose configurable ex post alignment modules and calibration steps.
- Products/workflows: Turnkey “alignment layer” in cloud ML platforms; one-click calibration; policy configuration UIs.
- Assumptions/dependencies: Platform partnerships; user education; guardrails to prevent misuse of class-weighted training.
Notes on Assumptions and Dependencies
- The approach relies on training with proper scoring rules and producing calibrated probabilities; calibration is a critical dependency for effective ex post alignment.
- Utility weights must be elicited and regularly reviewed; mis-specified utilities will misguide ex post decisions.
- The empirical evidence spans two standard tasks (medical imaging and CIFAR); broader generalization is likely but not guaranteed—teams should perform alignment audits on their specific problems.
- Class imbalance concerns should be addressed via data strategies (e.g., sampling, augmentation) and calibration rather than training-time class weighting when the goal is human-utility alignment; in rare cases where learning is trivially easy at extremes, weighting may still help, and should be evaluated empirically.
- Alignment should be monitored under distribution shift; recalibration and policy updates may be required.
- Governance, documentation, and human oversight are essential in high-stakes deployments.
Glossary
- Algorithmic design: An approach to designing algorithms that explicitly incorporate human objectives, constraints, or fairness considerations. "a process referred to as ``algorithmic design''"
- Aligned learning premise (ALP): The assumption that training a model directly on the human’s objective improves performance on that objective by informing what the model learns. "Implicit in these adjustments is what we term the aligned learning premise (ALP)"
- Argmax classification rule: A decision rule that selects the class with the highest value (e.g., probability or utility) by taking the argument that maximizes a function. "which is a simple argmax classification rule."
- Asymmetric loss functions: Loss functions that penalize different types of errors unequally to reflect domain-specific costs (e.g., false negatives vs. false positives). "are frequently trained with asymmetric loss functions that incorporate human decision-makers' trade-offs between false positives and false negatives."
- Bayesian learning: A framework where learning proceeds by updating beliefs (probability distributions) about uncertain states using Bayes’ rule. "By taking a Bayesian learning approach, our paper also connects machine learning with the information design literature"
- Blackwell (1953) ordering: A formal comparison of information structures where one is more informative than another if it yields better decisions under any objective. "the classical definition and ordering of \textcite{blackwell1953equivalent}."
- Calibrated predictions: Predictions whose stated probabilities match observed frequencies of outcomes. "optimal predictions will be calibrated"
- Calibrating coarsening: A post-processing method that adjusts and potentially simplifies model outputs to improve calibration or decision quality. "a calibrating coarsening of the machine outputs"
- Class imbalance: A situation where some classes are much rarer than others in the training data, potentially biasing learning. "issues of class imbalance in training data"
- Class-weighted cross entropy: A loss function that scales cross-entropy by class-specific weights to reflect class importance or imbalance. "The common case of class-weighted cross entropy is a specialization in two ways."
- Cost-sensitive learning: Techniques that incorporate varying costs of different errors directly into the training objective. "the machine learning literature on cost-sensitive learning and classification"
- Cross entropy: A standard probabilistic loss measuring divergence between predicted and true distributions, often implemented via logistic loss. "cross entropy and mean squared error"
- Endogenous information acquisition: Learning effort or information gathering that is determined within the model as a function of incentives and objectives. "incentive design with endogenous information acquisition."
- Empirical risk: The average loss of a predictor evaluated on data, used as the optimization objective in training. "the empirical risk can be expressed as:"
- Euclidean inner product: The standard dot product operation used to define expected losses and utilities in vector form. "denotes the Euclidean inner product"
- Expected utility: The average utility over possible outcomes, weighted by their probabilities, used to evaluate decisions. "maximizes the human's expected utility."
- Ex post adjustments: Transformations applied to predictions after training to align them with human objectives. "and then adjust predictions ex post according to that objective."
- Inference: The stage after training where the model is used to produce predictions or decisions on new data. "this stage in developing the AI system is referred to as ``inference.''"
- Information design literature: An economic theory area studying optimal shaping and disclosure of information to influence decisions. "connects machine learning with the information design literature"
- Information structure: The mapping from raw data to beliefs (probability distributions) that determines what is learned. "acquire a perfectly informative information structure"
- Inverse probability-weighted cross entropy: A weighting scheme where class weights are inversely proportional to class frequencies to correct imbalance. "we also consider training according to inverse probability-weighted cross entropy"
- Learning rate: A hyperparameter controlling the step size in gradient-based optimization during training. "a corresponding change in the learning rate"
- Logistic loss: The per-class negative log-probability used in classification, underlying cross-entropy. "logistic loss, ."
- Mean squared error: A loss function for regression measuring the average of squared differences between predicted and true values. "cross entropy and mean squared error"
- Nondegenerate utility: A utility function in which every class has at least one action yielding positive utility. "the utility function is nondegenerate"
- Posterior class distributions: The probabilities of classes conditional on observed predictions or features after learning. "posterior class distributions"
- Posterior probability: The probability of a class after observing data or intermediate signals, reflecting updated beliefs. "each posterior probability of the ``positive'' class"
- Soft-max function: A normalization function that converts raw scores into a probability distribution over classes. "generated by applying the soft-max function to raw outputs."
- Stochastic gradient descent: An iterative optimization method that updates parameters using noisy gradient estimates from mini-batches. "stochastic gradient descent over a high dimensional surface toward a locally optimal solution."
- Strictly proper loss function: A loss where the expected loss is uniquely minimized by predicting the true probability distribution. "a loss function $$ that is strictly proper"
- Threshold rule: A decision policy that takes an action when a predicted probability exceeds a specified threshold. "post processing could be a threshold rule"
- Utility-weighted loss: A training objective that weights prediction errors by utilities to reflect human preferences. "utility-weighted loss function"
- Utility-weighted prediction: A prediction formed by transforming probabilities to reflect expected utility across classes. "the unique optimal utility-weighted prediction"
- Variational encoders: Neural architectures that learn compressed stochastic representations, often used for modeling constrained learning. "use variational encoders to model how humans with cognitive constraints learn from the world."
- Vision transformers: Transformer-based architectures adapted for image tasks using patch embeddings and self-attention. "CIFAR image classification with vision transformers"
- Weighted resampling: A technique that oversamples or undersamples classes during training according to specified weights. "weighted resampling of the training data."
- Welfare-aware machine learning: Methods that incorporate societal or stakeholder welfare into ML objectives and design. "``welfare-aware machine learning''"
Collections
Sign up for free to add this paper to one or more collections.