- The paper demonstrates that selecting hyperpriors from the generalized Gamma family significantly enforces sparsity and stability in Bayesian inverse problems.
- It introduces a convergent Proximal Alternating Linearized Minimization (PALM) algorithm that efficiently updates sparse coefficients and hyperparameters.
- Empirical evaluations on image deblurring show that optimal hyperprior choices enhance restoration quality and suppress noise-induced artifacts.
Sparsity via Hyperpriors in the Empirical Bayes Framework: Theory, Algorithms, and Applications
Overview and Motivation
This paper presents a rigorous theoretical and algorithmic investigation of how the selection of hyperpriors within the Empirical Bayes Framework (EBF) impacts sparsity and stability in Bayesian inverse problems, particularly focusing on high-dimensional sparse recovery scenarios such as image deblurring under noisy and ill-posed conditions. The authors develop a precise mathematical connection linking the structure of the hyperprior—especially those from the generalized Gamma family—to both the sparsity of the resulting solutions and their robustness to noise. They further introduce a provably convergent numerical solver based on Proximal Alternating Linearized Minimization (PALM) that accommodates both convex and concave hyperprior structures. Comprehensive numerical experiments are provided to corroborate the theoretical insights.
The formulation commences with a standard linear inverse model: y=Fx+ϵ
where x represents the signal or coefficients to be estimated, with an assumed sparse representation under an appropriate dictionary (e.g., DCT basis), and ϵ∼N(0,σ−1I).
EBF proceeds by alternating the estimation of x and its associated variance hyperparameters γ, where the prior on x is taken as N(0,diag(γ)). Unlike classical sparse Bayesian learning (SBL), which often employs non-informative or weakly informative hyperpriors and maximizes the evidence (marginal likelihood), EBF incorporates explicit hyperpriors over γ, thus tightly controlling the solution's inductive bias and its sparsity properties.
The marginal posterior for γ is: π(γ∣y)∝∣S(γ)∣−1/2exp(−21y⊤S(γ)−1y−i=1∑nH(γi))
where S(γ)=σ−1I+Fdiag(γ)F⊤ and H(⋅) encodes the negative logarithm of the hyperprior.
Analytical Characterization of Sparsity-Inducing Hyperpriors
The authors introduce a precise KKT-based analytic framework to analyze how H(γ) influences the sparsity of stationary points of the MAP objective. For hyperpriors H that are strictly increasing and convex (e.g., half-Laplace, half-generalized Gaussian with $0 < p < 1$), the nonzero solutions for each γ are explicitly bounded and promote more aggressive shrinkage of small coefficients compared to the non-informative case, resulting in sparser solutions. Specifically:
- The half-Laplace (p=1) and half-generalized Gaussian ($0 < p < 1$) hyperpriors not only admit zero solutions for sufficiently low information content (q−p2 thresholding) but also tighten the region for nonzero γ⋆.
- For generalized Gamma hyperpriors, the interplay between the shape parameters α, β, and ζ governs the sparsity-promotion threshold precisely.
This framework provides a complete phase diagram of sparse, non-sparse, and unstable regimes as a function of the hyperprior parameters.
Algorithmic Approach: Proximal Alternating Linearized Minimization (PALM)
To solve the arising non-convex optimization, the authors deploy a Proximal Alternating Linearized Minimization (PALM) algorithm. The method alternates closed-form updates for x and coordinate-wise updates (often closed-form via cubic/quadratic root finding, e.g., Cardano's formula, in the case of classical hyperpriors) for γ.
Key features of the algorithm:
- It accommodates both convex and concave (and piecewise non-convex) H, ensuring convergence to stationary points for a wide range of hyperprior choices.
- For structured, orthogonal transforms like the DCT, the forward operator F allows for efficient computation of both the updates and the required diagonals/state statistics using Woodbury or similar identities.
- Once a component of γ collapses to zero, all subsequent iterates retain this zero value, enabling dynamic dimensionality reduction and computational savings.
Convergence properties are formally established: the objective is strictly decreasing, has bounded subsequence convergence, and limit points are (coordinate-wise) KKT stationary.
Empirical Evaluation: Image Deblurring and Sparsity Control
Experimental Setup
Experiments focus on 2D image deblurring under Gaussian blur and additive noise, estimating sparse DCT coefficient maps. The impact of different hyperpriors (half-Laplace, half-Gaussian, half-generalized Gaussian with varying p, and various Gamma family priors) is systematically explored.
The evaluation assesses both restoration quality (relative error to ground truth) and achieved sparsity (rate of zero coefficients), for varying noise levels and ill-posedness.
Visual Comparison and Numerical Results
Empirical results unambiguously demonstrate:
- The half-Laplace and half-generalized Gaussian ($0 < p < 1$) hyperpriors produce the sparsest and most stable coefficient maps, yielding sharp sector-shaped nonzero regions and suppressing restoration artifacts.



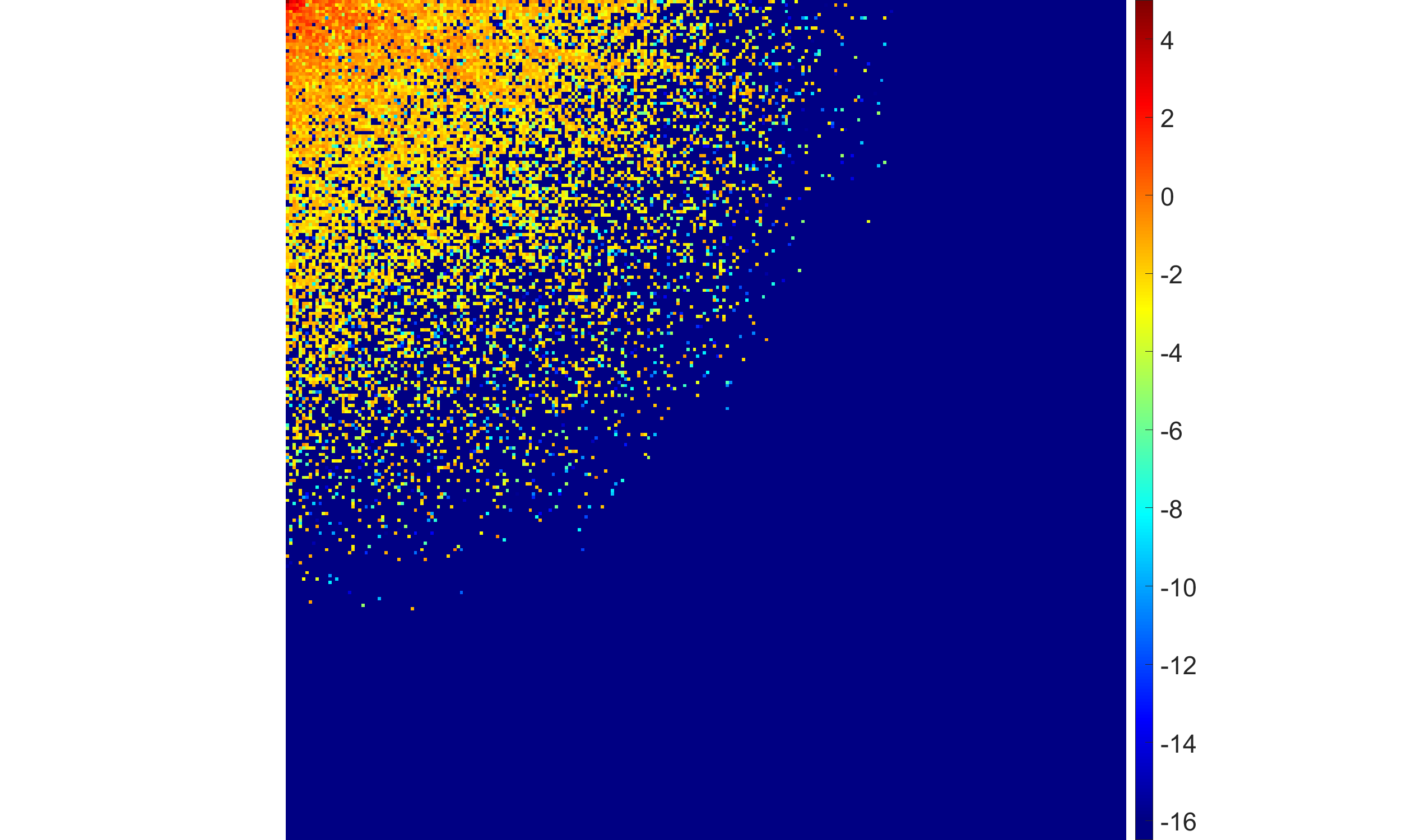
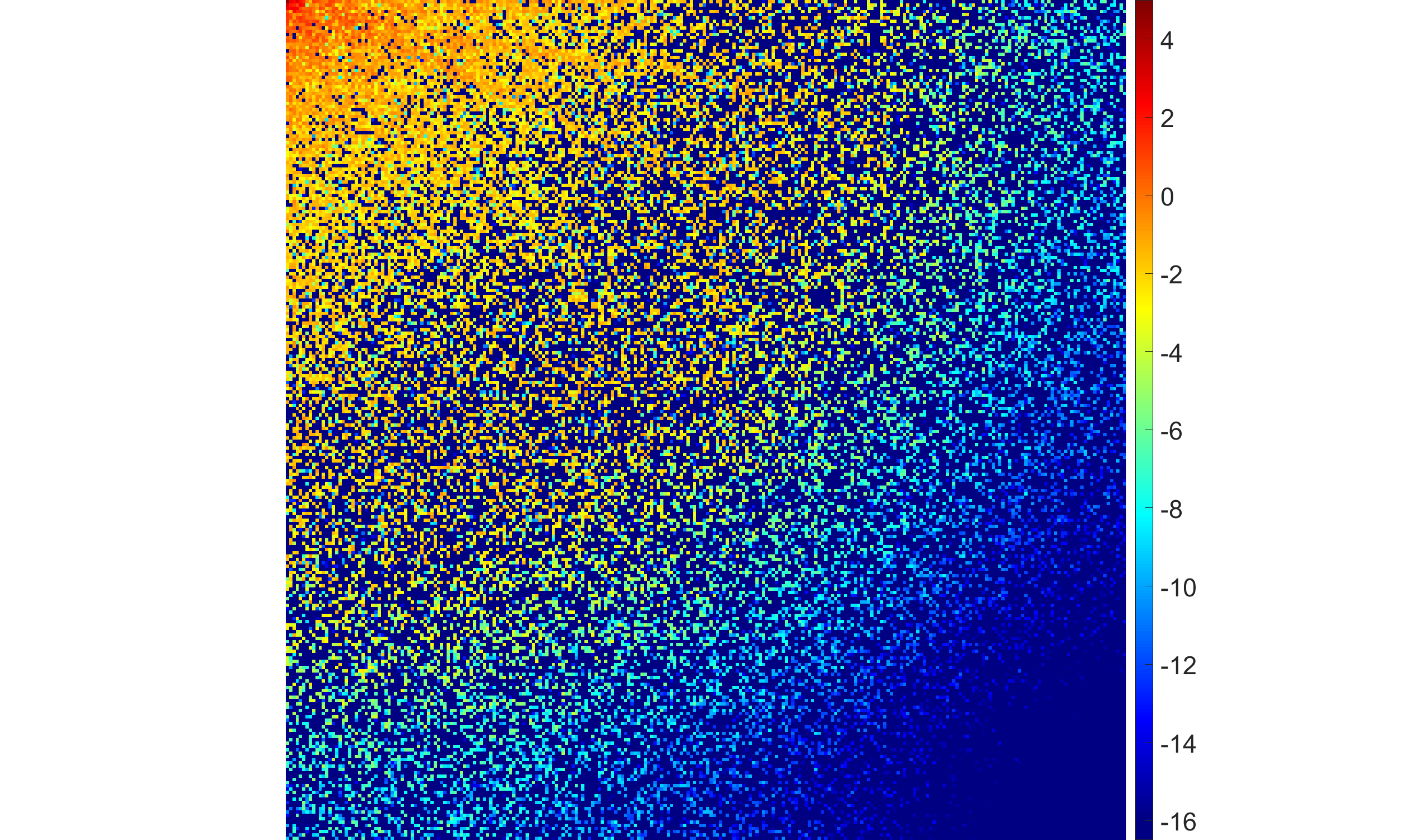

Figure 1: Comparisons among half-Laplace, half-Gaussian, and SBL solutions: the half-Laplace exhibits higher sparsity and less high-frequency artifact energy in both the coefficient and image domains.
- Reducing the shape parameter p in the half-generalized Gaussian hyperprior transits the solution from moderate to highly sparse, but excessively small p can lead to oversmoothing.


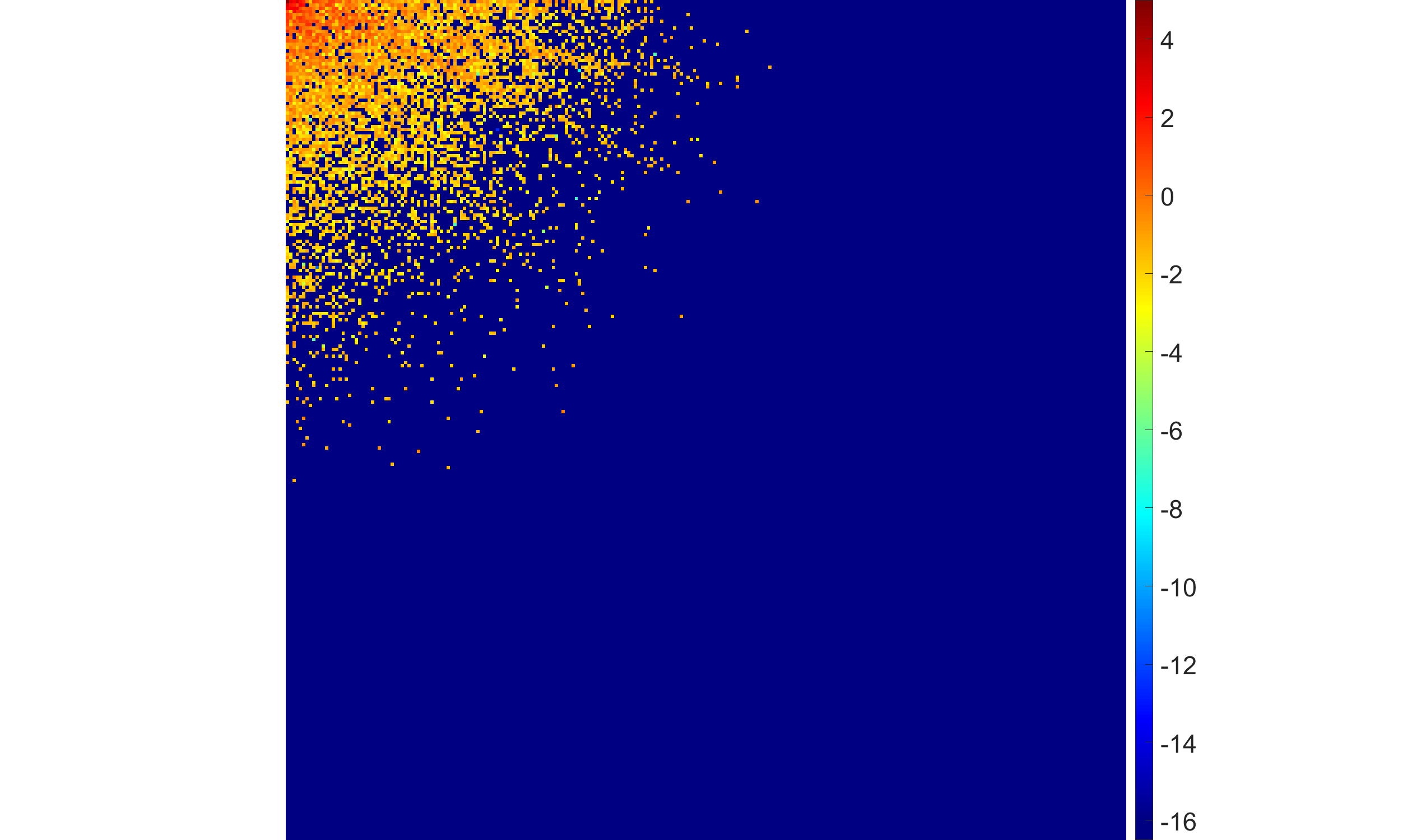
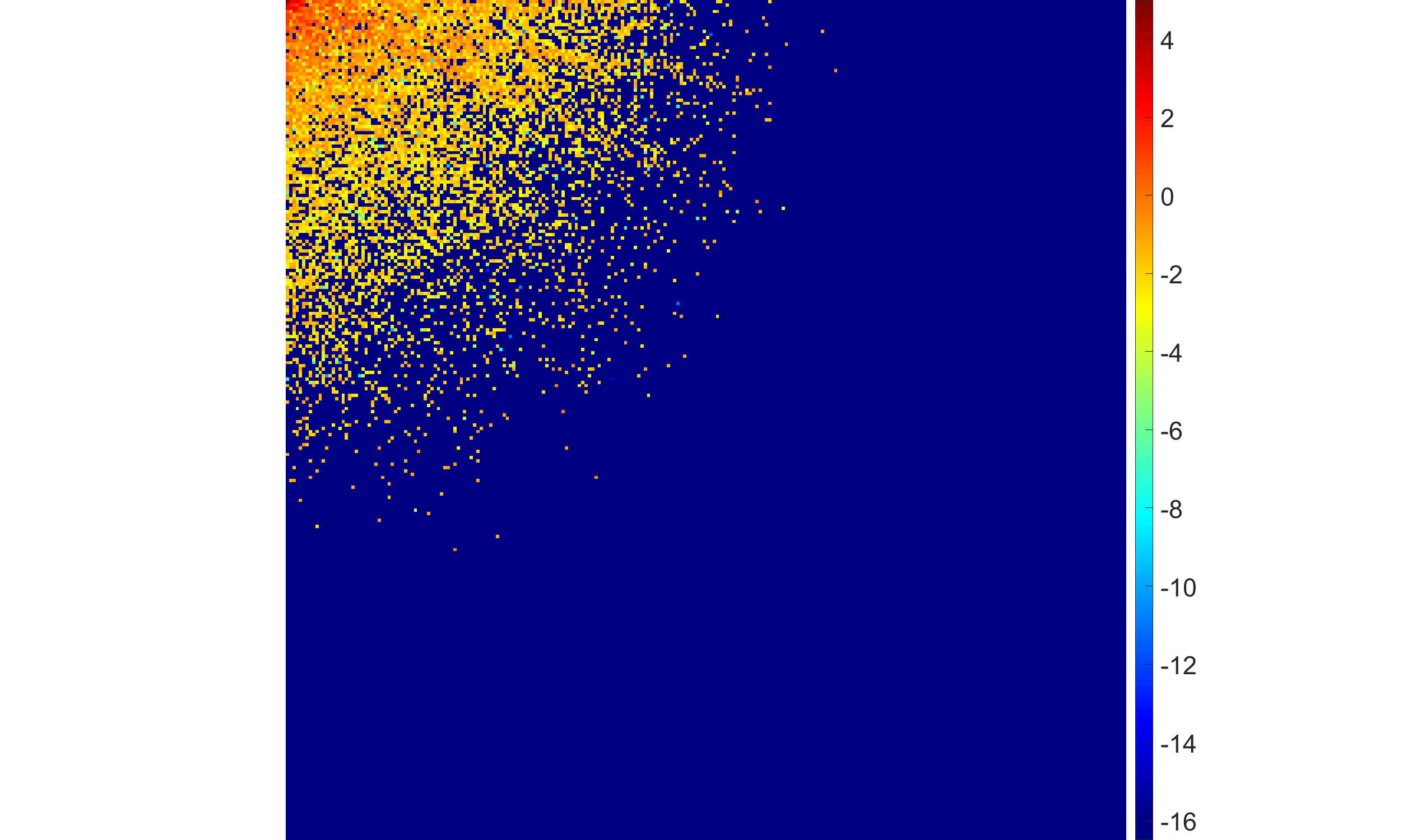
Figure 2: Effects of half-generalized Gaussian hyperpriors with decreasing p; lower p increasingly zeros out high-frequency coefficients but may sacrifice significant detail.
- The parameter α in the Gamma hyperprior controls the sparsity regime sharply; for α<1, solutions are globally sparse; for α>1, no sparsity is induced.


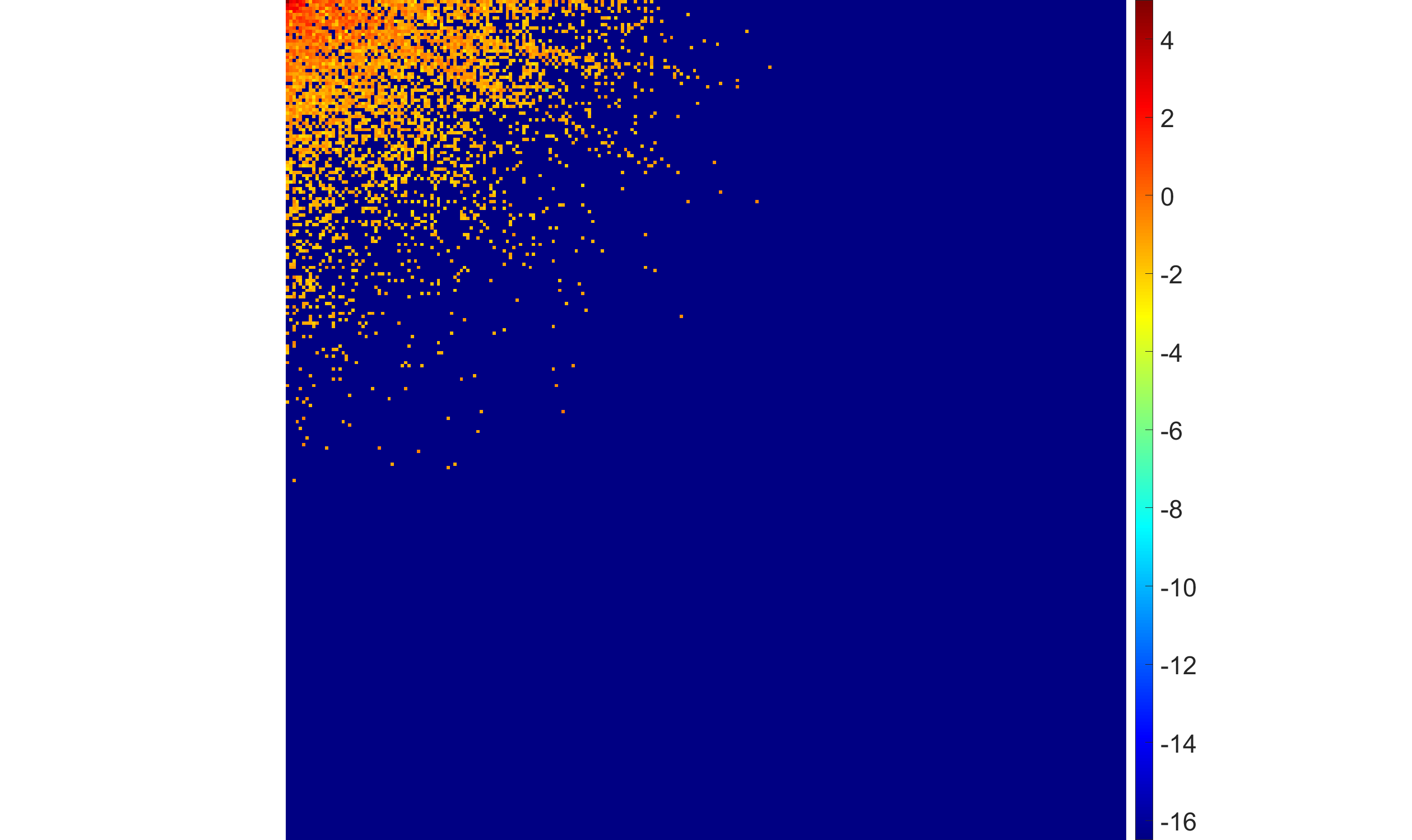
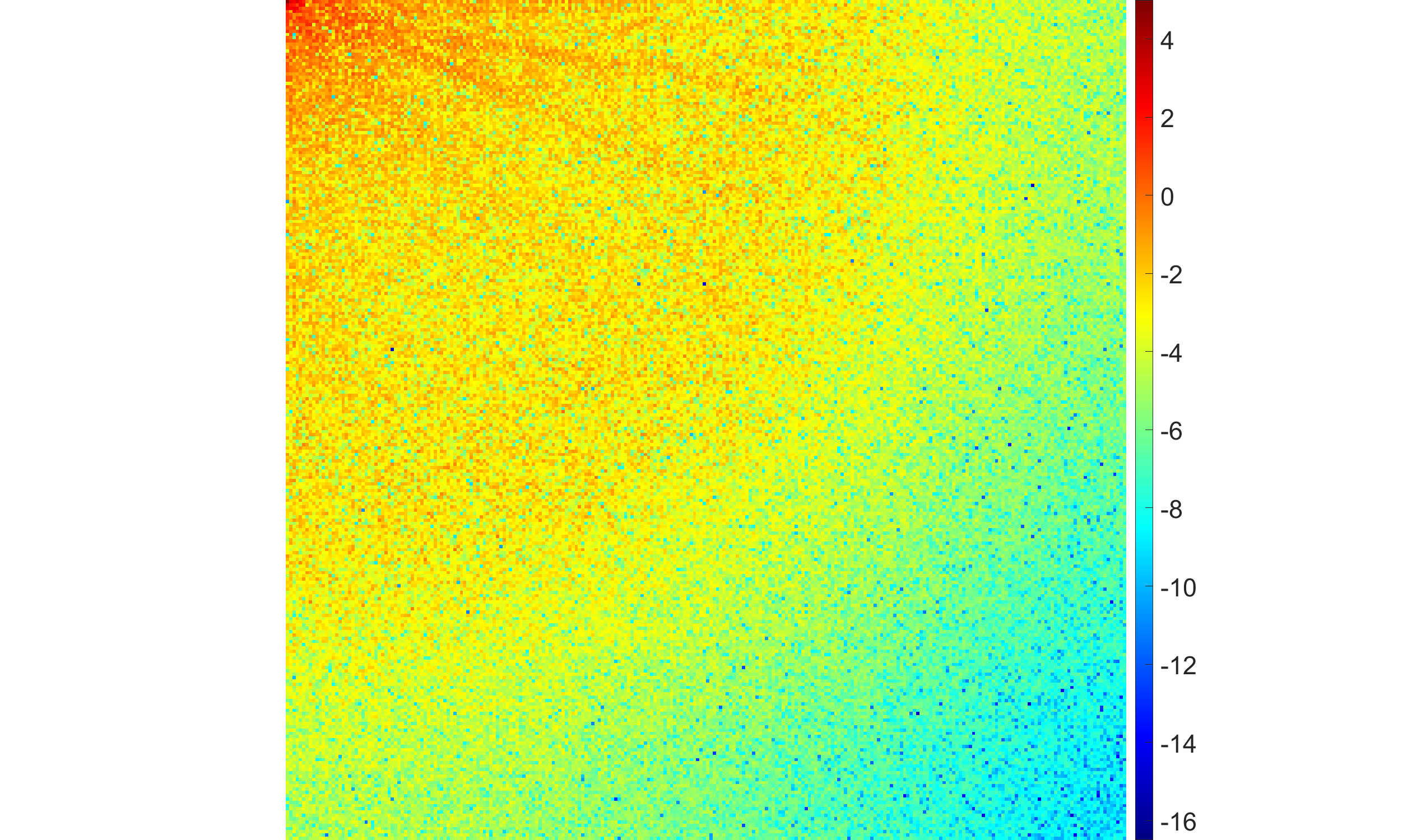
Figure 3: Impact of Gamma hyperprior shape parameter α on the sparsity and fidelity of restoration; only for α<1 do most coefficients collapse to zero.
- Both increased noise and higher ill-posedness (more severe blur, larger σker) drive EBF to suppress high-frequency coefficients more aggressively, leading to increased sparsity but at the cost of potential loss of detail.




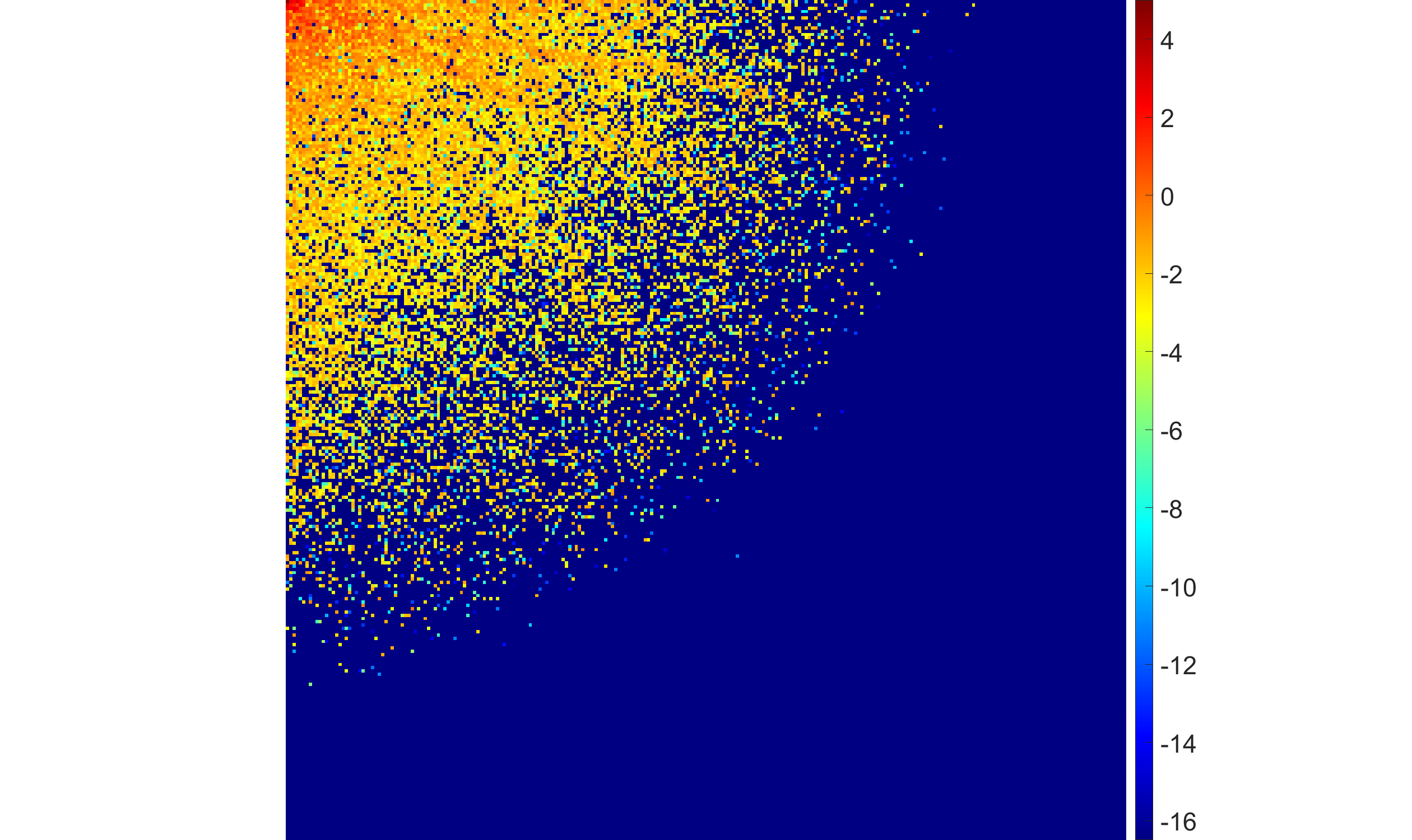
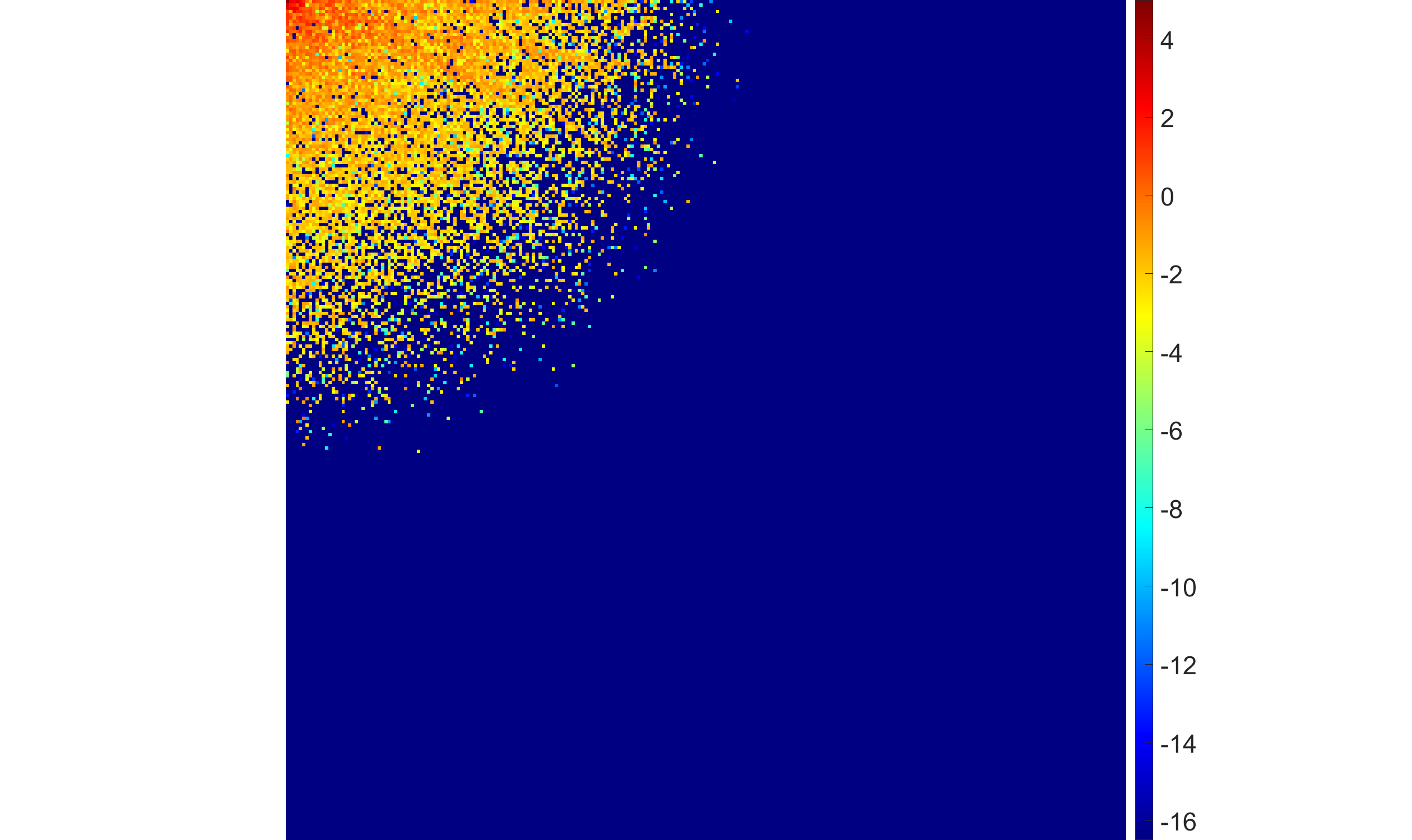



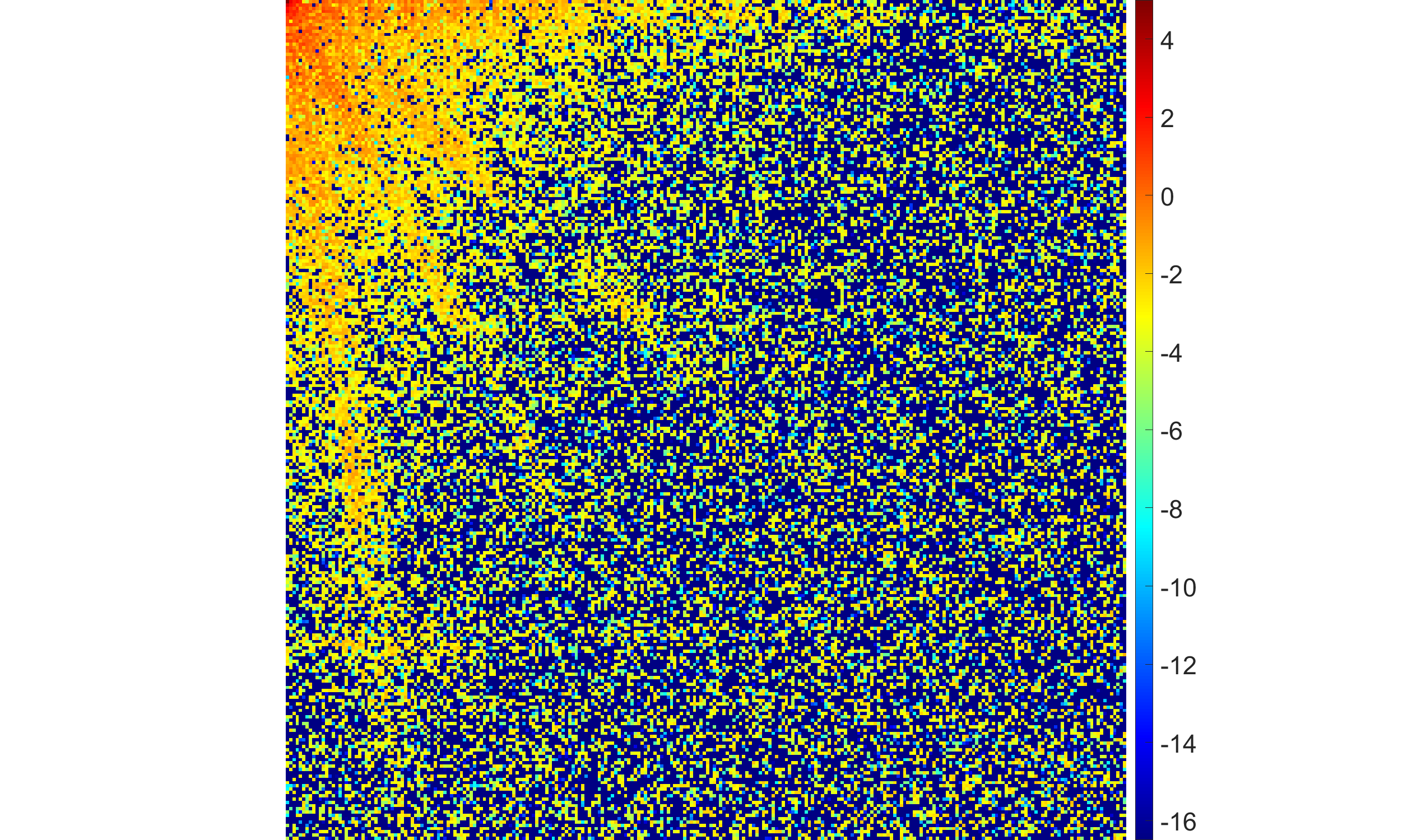
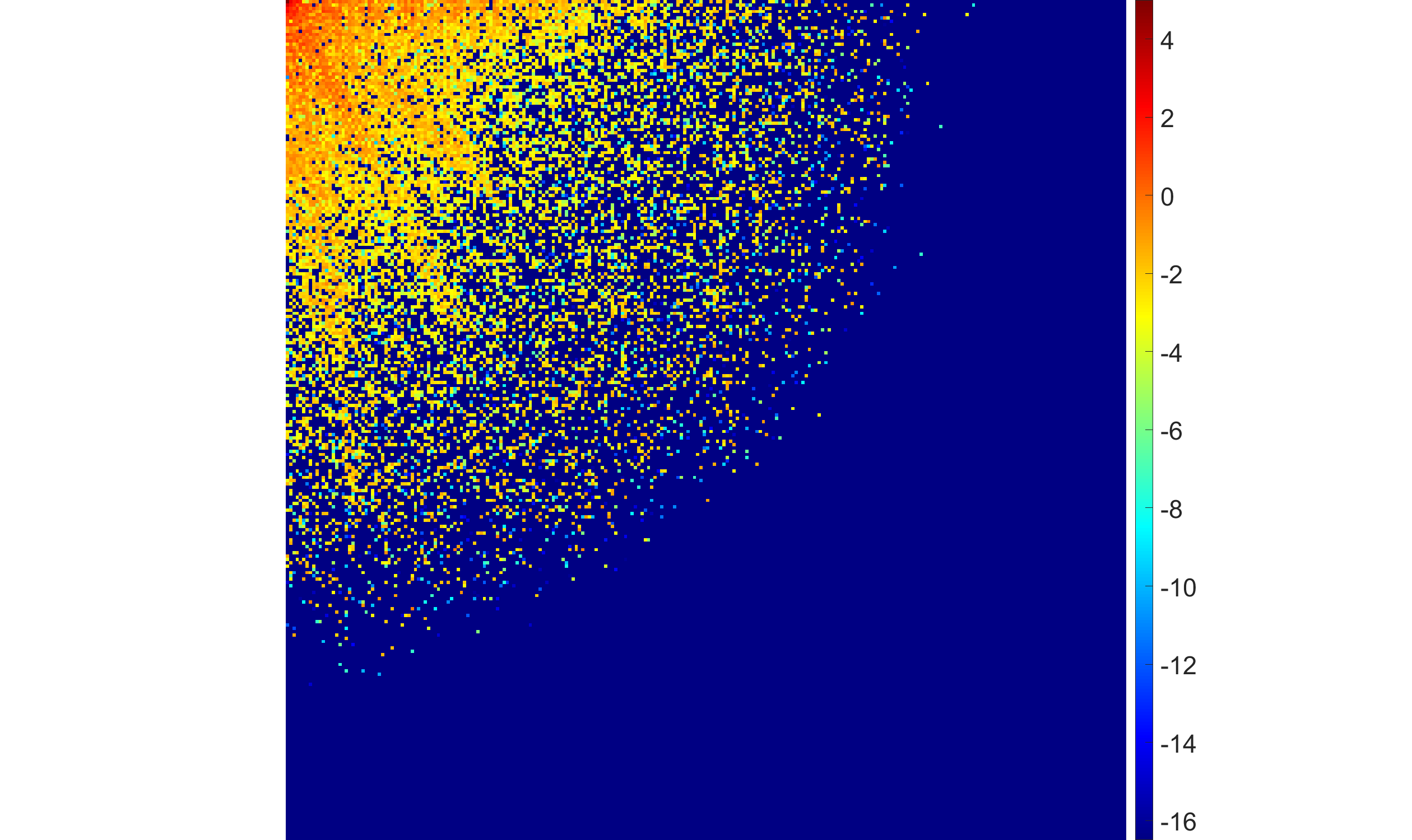
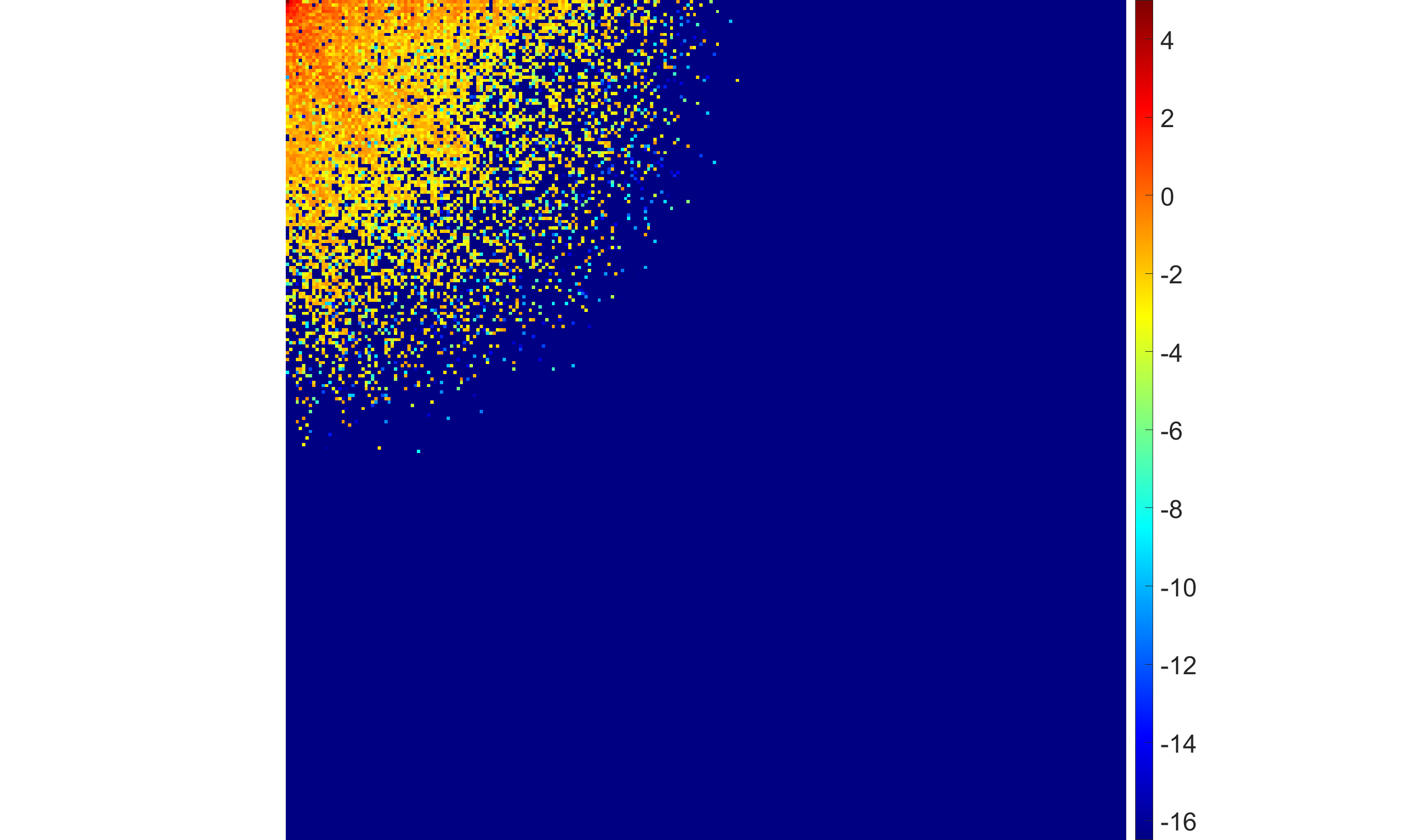
Figure 4: EBF with half-Laplace hyperprior demonstrates adaptive suppression of high-frequency coefficients with varying blur intensity.


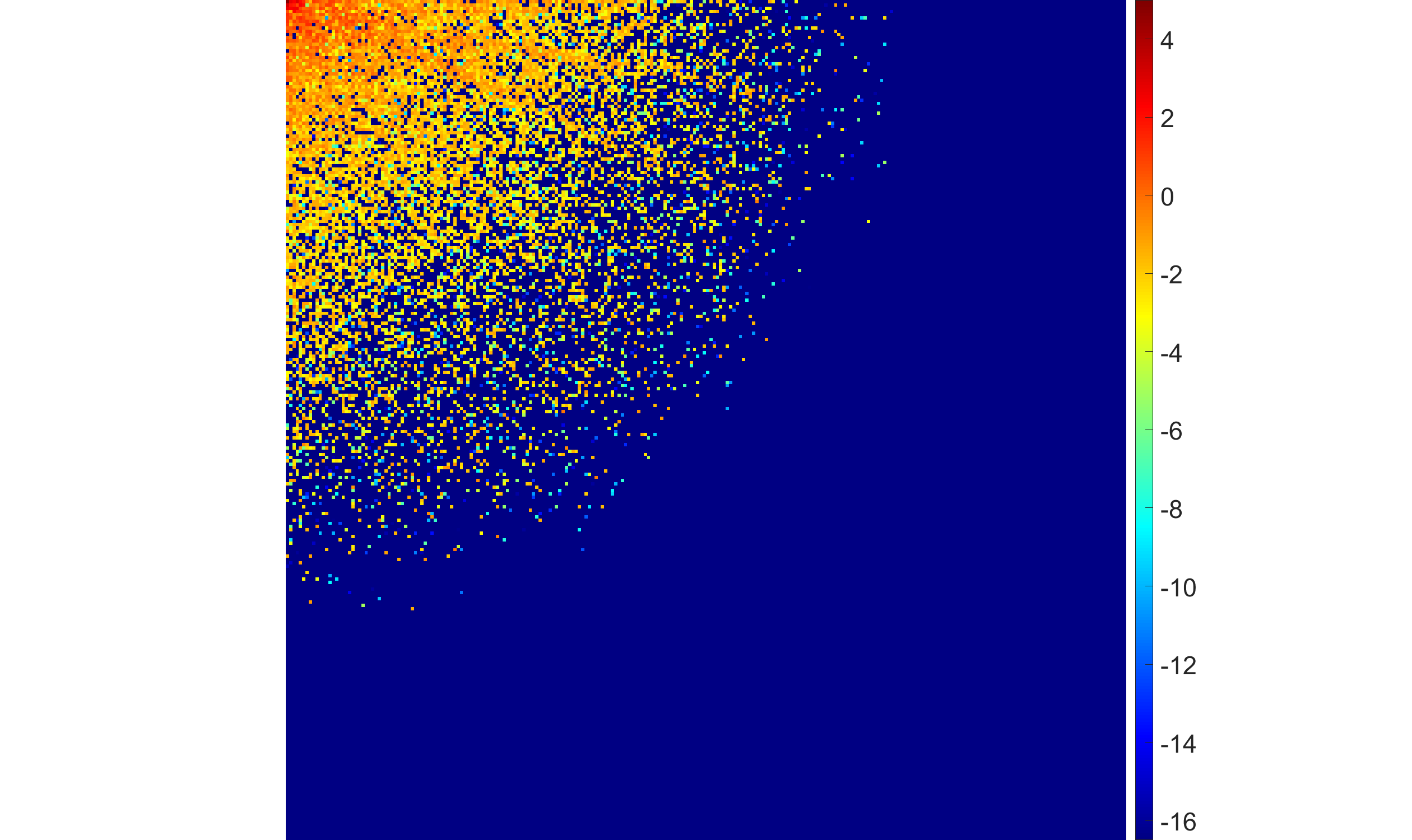
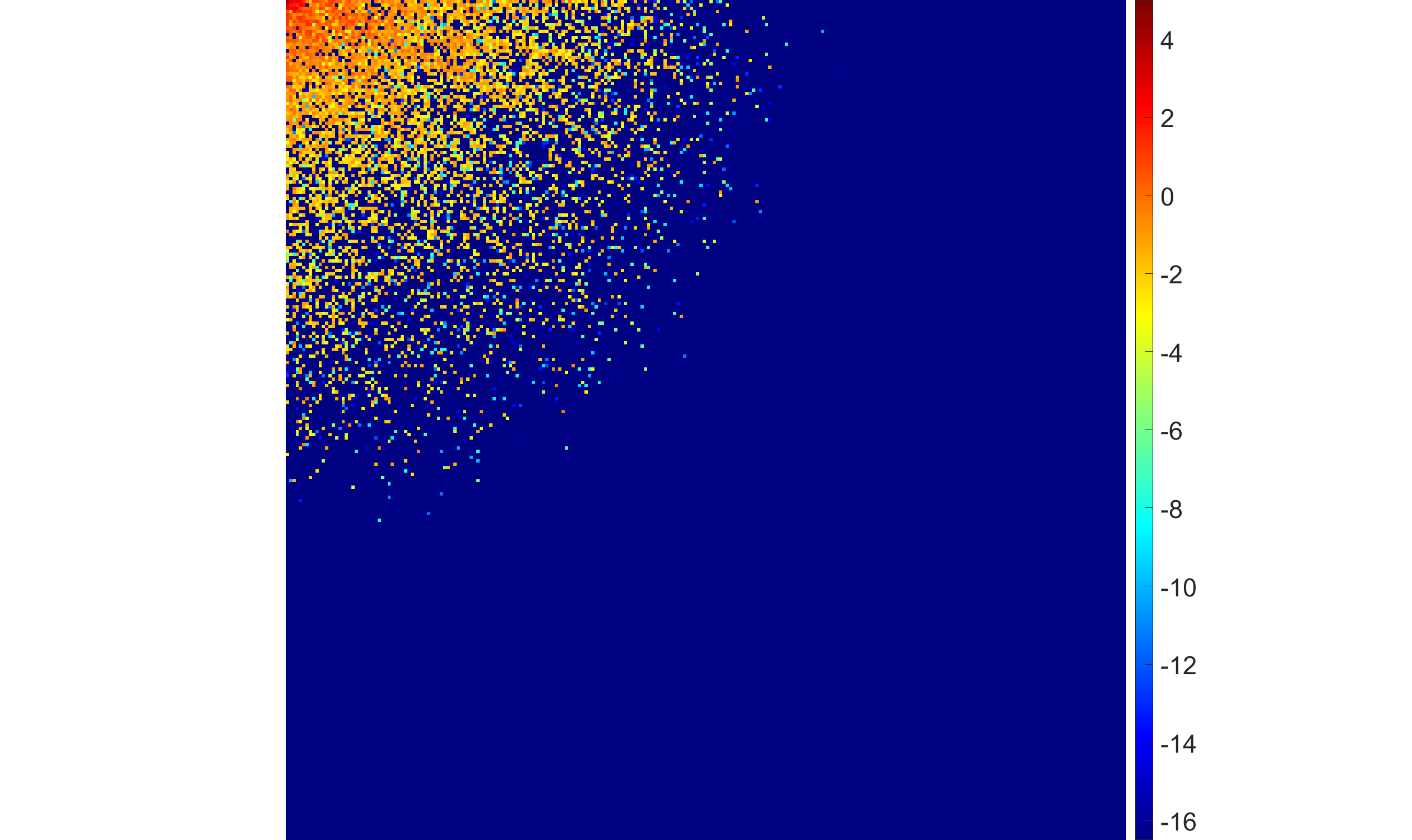


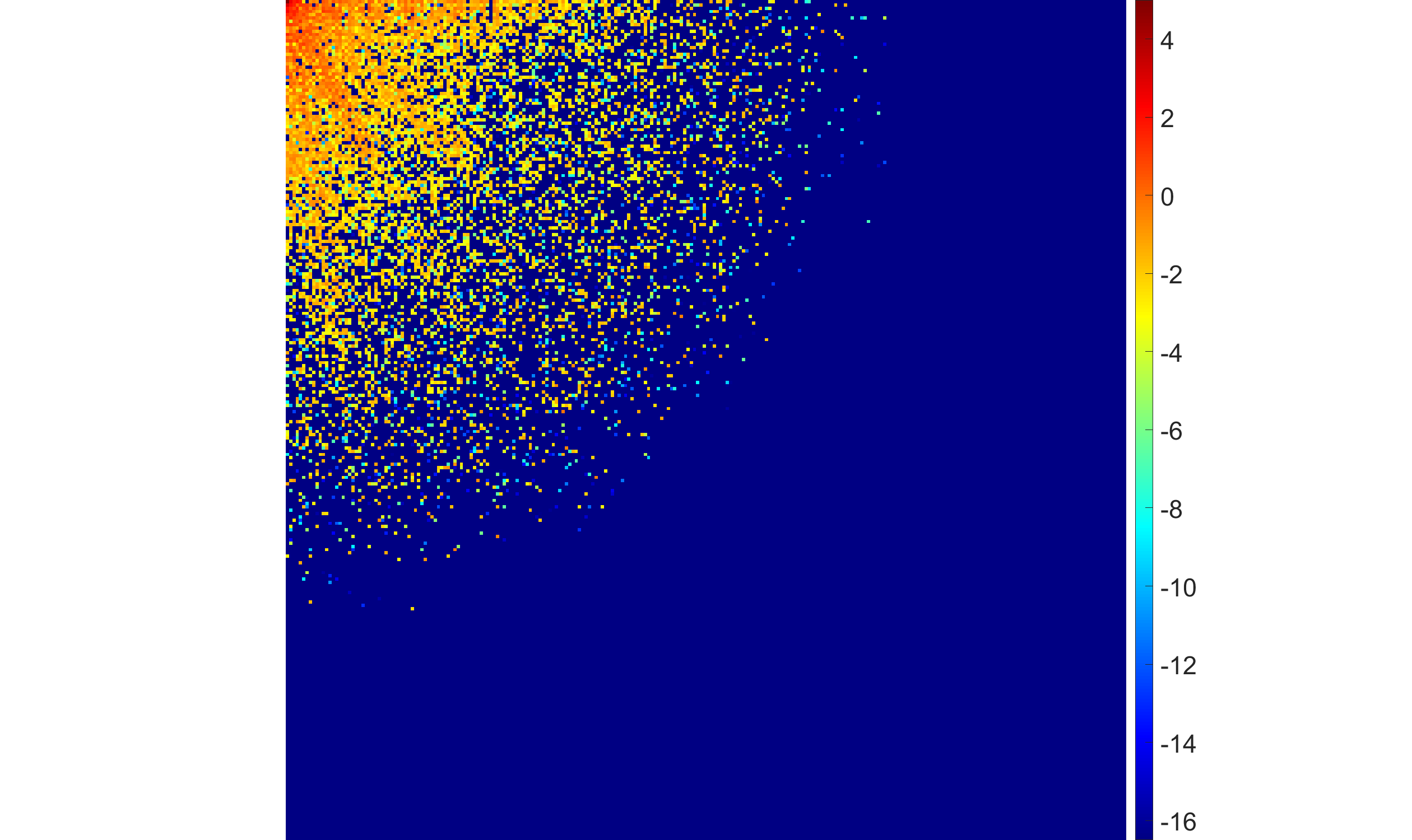
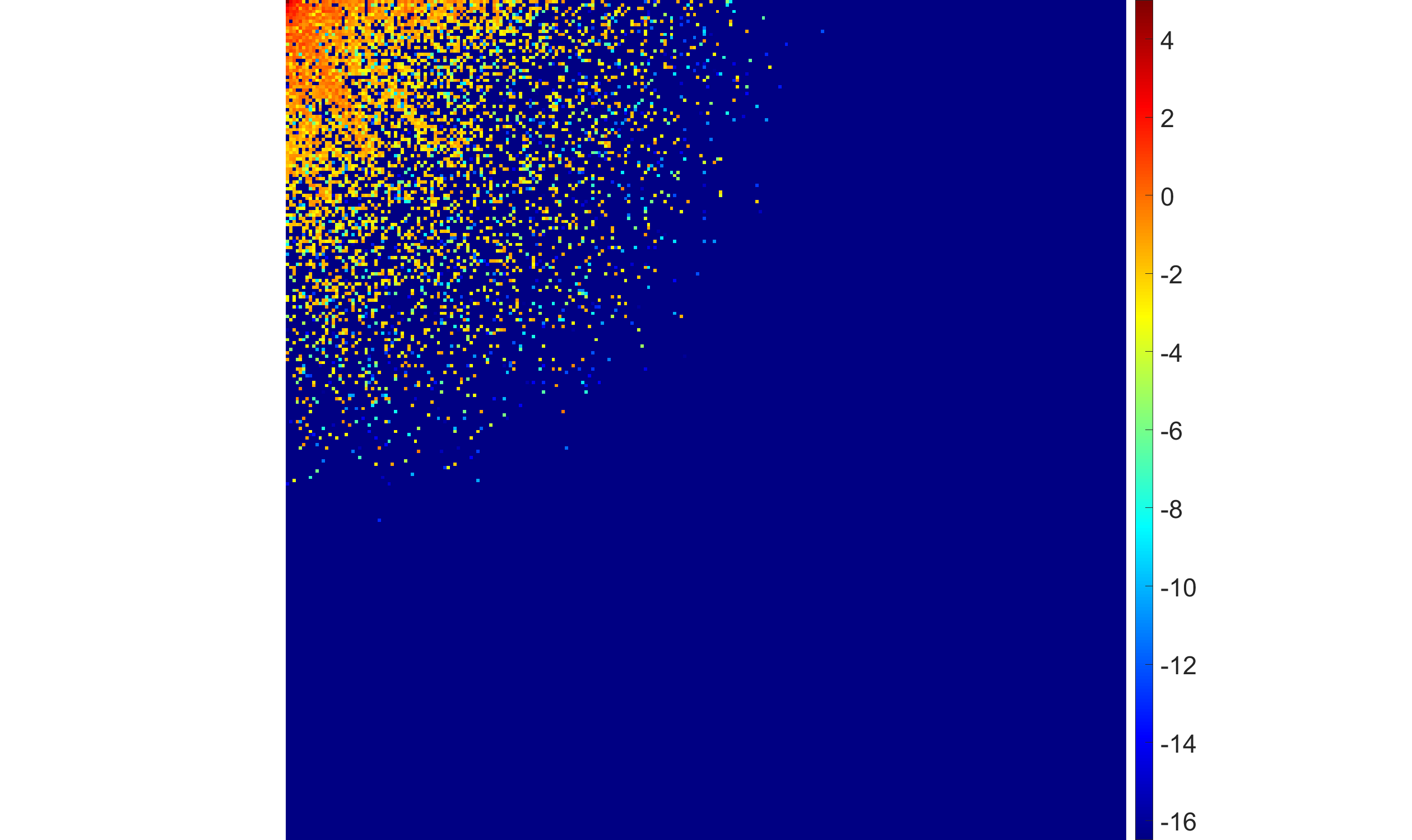
Figure 5: EBF with half-Laplace hyperprior under rising noise levels: more high-frequency DCT coefficients shrink to zero as noise increases, favoring robustness over fine detail.
- The PALM solver demonstrates swift and monotonic convergence under a range of hyperprior strengths and problem settings.
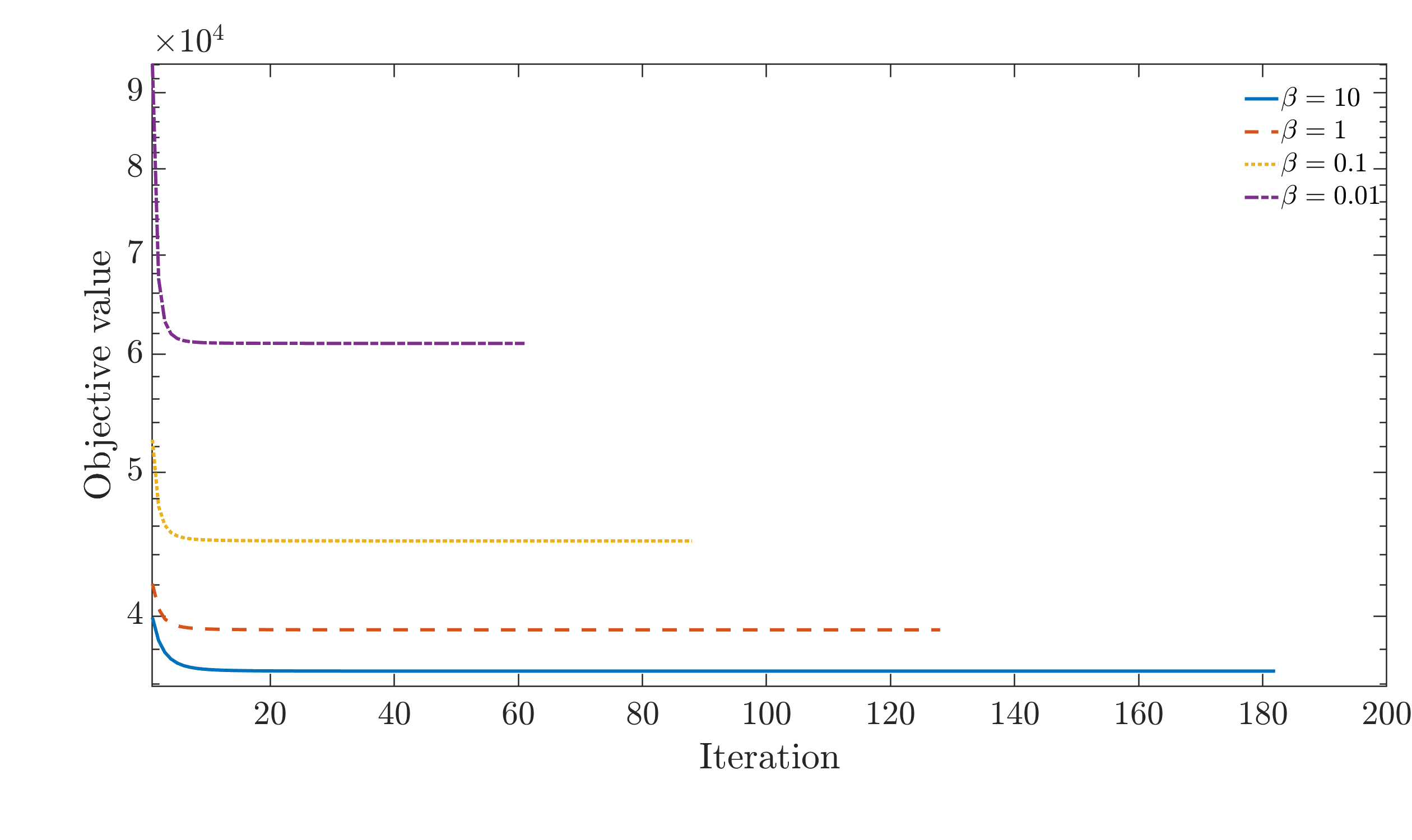
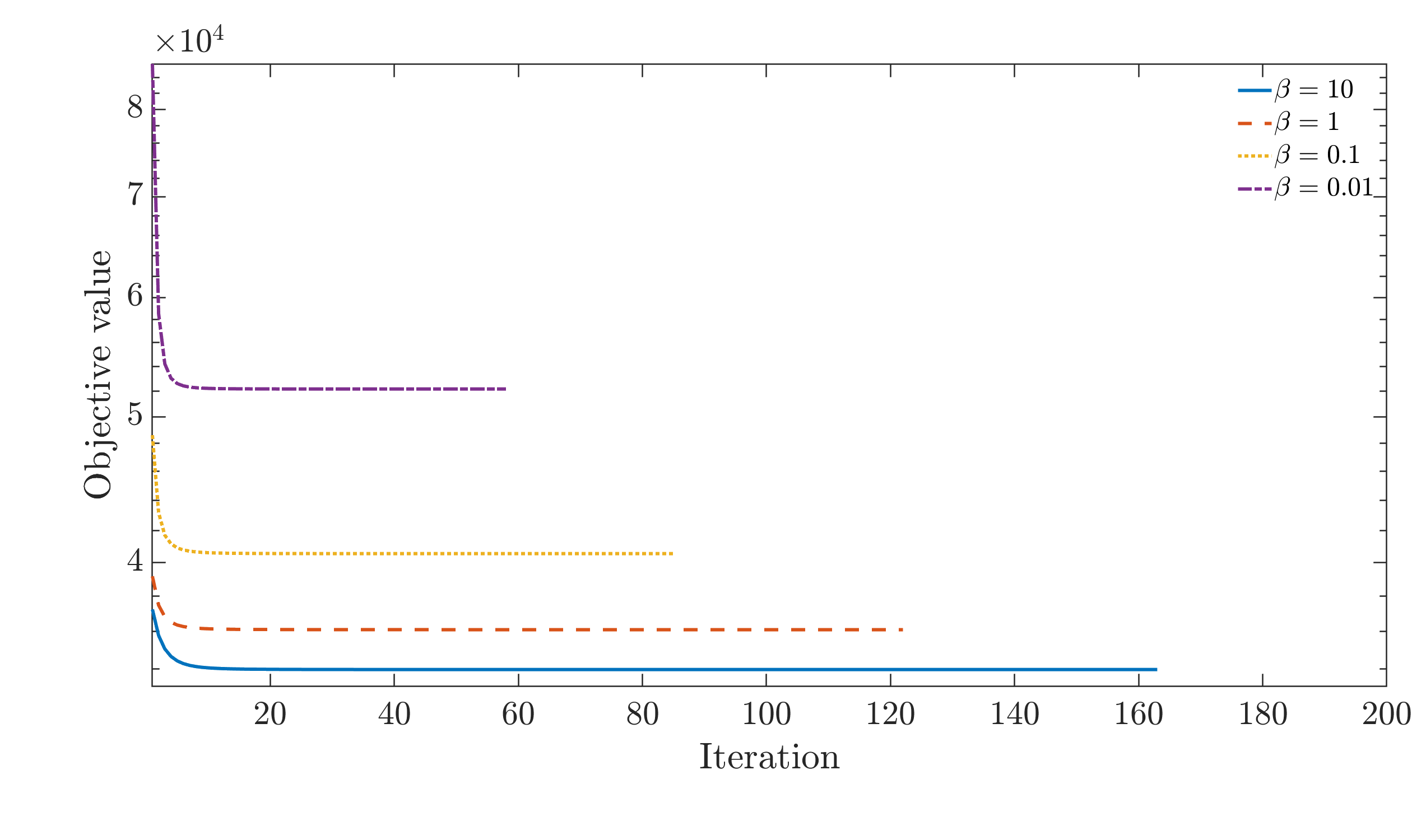
Figure 6: Monotonic objective descent curves for PALM under various hyperprior strengths, confirming robustness and efficiency.
Implications and Future Directions
Practical Implications
- This study provides a decisive operational recipe for practitioners: Half-Laplace and half-generalized Gaussian hyperpriors with $0 < p < 1$ are optimal for promoting sparsity and stability in EBF for linear inverse problems, including compressive imaging. These priors should be preferred over classical (inverse-)Gamma or half-Gaussian forms when structural sparsity is critical.
- The explicit analytic bounds allow automated hyperparameter selection to match a given target sparsity or stability.
- The PALM algorithm, with componentwise closed-form updates and guaranteed convergence, ensures scalability for high-dimensional problems, particularly when leveraged with fast transforms/bases.
Theoretical Impact and Open Problems
- The establishment of a theoretical correspondence between hyperprior monotonicity/convexity and thresholding behavior of zeros/nonsparse solutions creates a precise dictionary for designing custom hyperpriors.
- The existence and characterization of coordinate-wise local minima for all convex and certain nonconvex hyperpriors opens directions for further study into global convergence, especially for more complex or nonseparable priors (e.g., group, tree-structured, or heavy-tailed Student's t).
- The formalism here can generalize to hierarchical Bayesian models in deep generative priors, variational autoencoder settings, or complex measurement processes where hyperparameter learning is central.
Limitations and Outlook
- The analysis is currently most robust for separable, elementwise hyperpriors; extension to correlated/group sparsity priors remains an open avenue.
- The convergence theory for truly general, highly nonconvex (multimodal) H is not addressed and warrants further investigation.
- Future work can leverage the efficient PALM schema for a broader class of sparsity-inducing transforms and for integration into automatic, data-driven hyperprior learning.
Conclusion
This work presents a comprehensive analytic and algorithmic foundation for exploiting hyperpriors in the empirical Bayes framework for sparse inverse problems. The mathematical characterization of sparsity promotion and solution stability as a function of hyperprior structure—validated by strong empirical results—constitutes a valuable resource for practitioners and theorists seeking principled, adaptive, and scalable sparsity control under challenging measurement and noise conditions.