Self-adaptive weighting and sampling for physics-informed neural networks
Published 7 Nov 2025 in stat.ML, cs.AI, cs.LG, and physics.comp-ph | (2511.05452v2)
Abstract: Physics-informed deep learning has emerged as a promising framework for solving partial differential equations (PDEs). Nevertheless, training these models on complex problems remains challenging, often leading to limited accuracy and efficiency. In this work, we introduce a hybrid adaptive sampling and weighting method to enhance the performance of physics-informed neural networks (PINNs). The adaptive sampling component identifies training points in regions where the solution exhibits rapid variation, while the adaptive weighting component balances the convergence rate across training points. Numerical experiments show that applying only adaptive sampling or only adaptive weighting is insufficient to consistently achieve accurate predictions, particularly when training points are scarce. Since each method emphasizes different aspects of the solution, their effectiveness is problem dependent. By combining both strategies, the proposed framework consistently improves prediction accuracy and training efficiency, offering a more robust approach for solving PDEs with PINNs.
The paper presents a hybrid adaptive weighting and sampling method that balances residual contributions for effective PINN training.
It dynamically reallocates collocation points based on residuals to resolve sharp gradients and accelerate convergence.
Empirical results on multiple PDE benchmarks demonstrate significant error reductions and computational efficiency gains even with smaller training sets.
Self-Adaptive Weighting and Sampling for Physics-Informed Neural Networks
Introduction
This work introduces a hybrid adaptive weighting and sampling strategy for Physics-Informed Neural Networks (PINNs) aimed at improving both prediction accuracy and training efficiency when solving partial differential equations (PDEs). The authors systematically address two persistent issues in PINN training: the imbalance in loss terms due to heterogeneous solution features and the inefficiency of uniform sampling in resolving sharp gradients or localized phenomena. The proposed framework demonstrates robust performance across multiple canonical PDE benchmarks by dynamically balancing residual contributions and reallocating training points toward regions of interest based on residual information.
Background and Motivation
Physics-informed neural networks enable solution of PDEs by penalizing the violation of differential operators and boundary/initial conditions within the loss function. The canonical PINN loss is
Ltotal=LPDE+LBC,
where both terms are typically evaluated over a set of collocation points covering the domain’s interior and boundary. However, uniform sampling of these points often leads to inadequate resolution in regions with high gradients or singularities and suboptimal convergence due to the disparate nature and scale of loss components.
Existing literature offers several pointwise adaptive strategies:
Adaptive weighting addresses loss imbalance, but its efficacy wanes if point placement fails to resolve sharp-solution features.
Adaptive sampling focuses collocation points on regions with high residuals but may not sufficiently balance the rates of convergence for all points, especially in multi-loss settings.
The current work proposes a composite approach where adaptive weighting based on the balanced residual decay rate (BRDR) and self-adaptive residual-based sampling are integrated. With this, sampling priorities and loss contributions are co-optimized, yielding noticeable reductions in prediction error and computational cost across a diversity of PDE types.
Adaptive Weighting: The BRDR Method
The BRDR method aims to equalize the rates at which residual loss terms decay by assigning dynamic, pointwise weights. For each residual (from both the equation and boundary losses), the key quantity is the inverse residual decay rate (IRDR):
IRDRt=R4(t)+ϵR2(t)
Here, R4(t) is an exponential moving average of the fourth power of the residual, smoothed over recent steps, while ϵ ensures numerical stability. Points with slow-decaying residuals (large IRDR values) receive higher weights. The weights are normalized to have unit mean and themselves updated via an exponential moving average for stability.
This method successfully prevents the domination of hard-to-train points and ensures global convergence is not bottlenecked by isolated slow-residual locations. However, if the collocation points do not sufficiently cover steep-gradient or boundary layer regions, overfitting and poor generalization can still ensue.
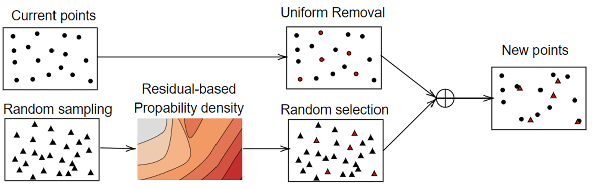
Self-Adaptive Sampling Based on Residuals
When adaptive weighting is used with a sparse, non-adaptive point set, large solution errors may persist in unsampled regions—particularly around sharp features—despite minimized training residuals. The sampling strategy remedies this by iteratively updating a fraction of training points post-optimization steps, selecting candidates with probability proportional to their squared residuals, subject to residual clipping to avoid over-focusing on very high residuals:
p(x)=∑xRclipped2(x)Rclipped2(x)
Rclipped2(x)=max(R^2,min(R2(x),γR^2))
where R^2 is the median residual and γ is a scaling parameter. Only a proportion pu of training points are exchanged in each sampling iteration, mitigating training set instability.
Weights and exponential moving averages for newly added points are estimated using inverse distance weighting (IDW) interpolation from their neighbors, thus maintaining smoothness in residual and weight fields during dynamic set updates.
Figure 1: Schematic illustration of the implementation process for self-adaptive sampling based on residuals.
Algorithmic Integration
Adaptive weighting and sampling are interleaved within the training loop. At every optimization step, pointwise weights and exponential moving averages are updated according to BRDR. Every Ns steps, the adaptive sampler stochastically refreshes pu fraction of the training set using residual-informed probabilities, with interpolated initialization for new point weights and moving averages. This strategy is robust against sampling oscillations and sharp spatial/temporal gradient features.
Numerical Evaluation
The hybrid approach is validated on four canonical PDEs:
1D singular-perturbation problem
Allen–Cahn equation
Burgers equation
Lid-driven cavity flow
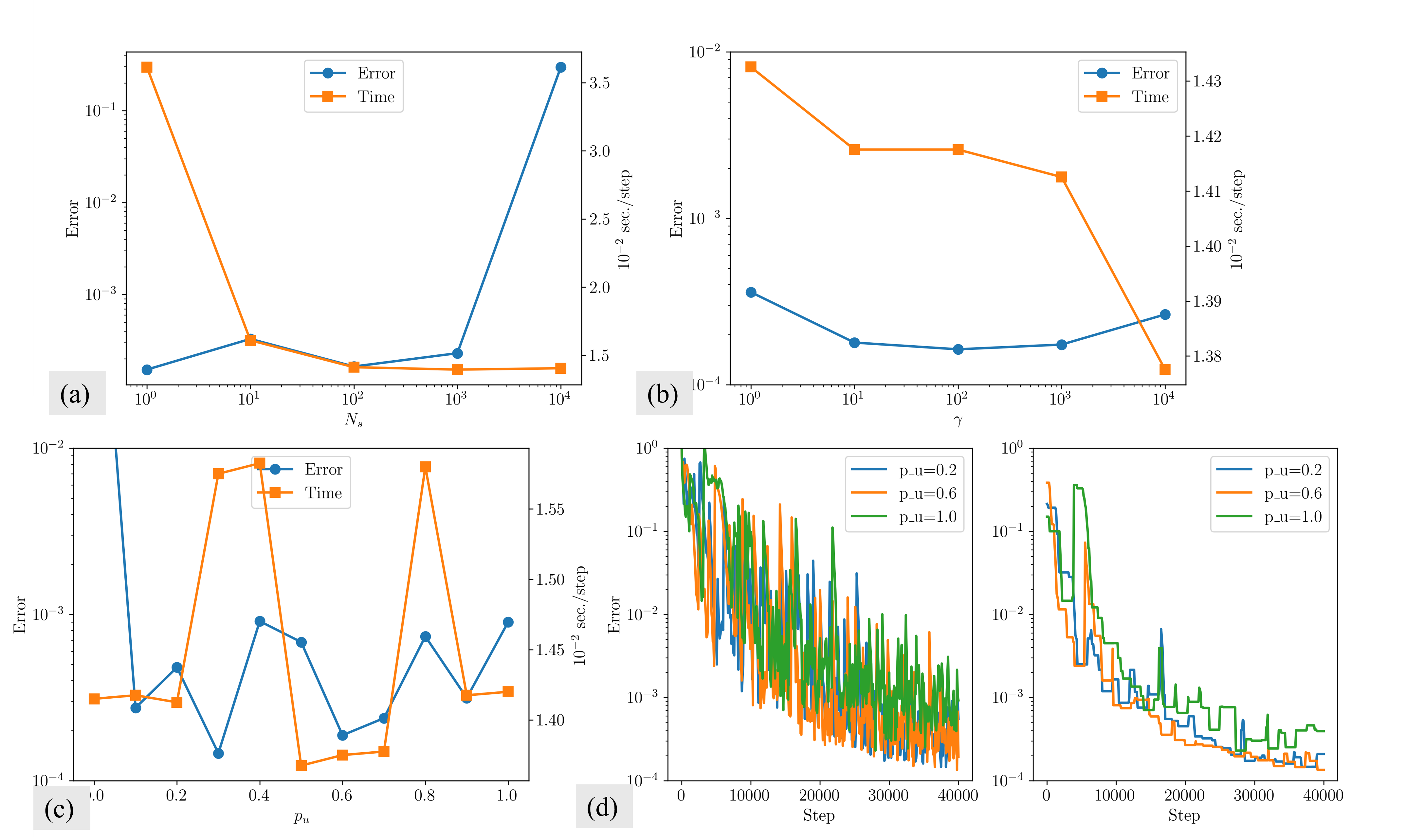
Training uses an mFCN (6 layers, 128 neurons/layer, tanh activations) with Kaiming initialization, Adam optimizer, and appropriate learning rate schedules. Empirical parameter studies confirm the stability of the default hyperparameters for BRDR (βc=βw=0.999), and for adaptive sampling (γ=100, pu=0.2, Ns=100).
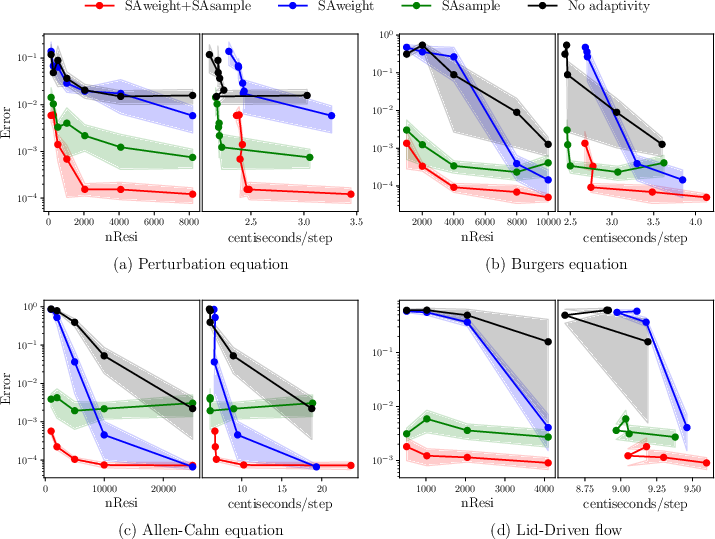
Figure 2: PINN prediction errors (left) and training time cost (right) for four representative PDE benchmarks under various training strategies and batch sizes.
Perturbation Problem
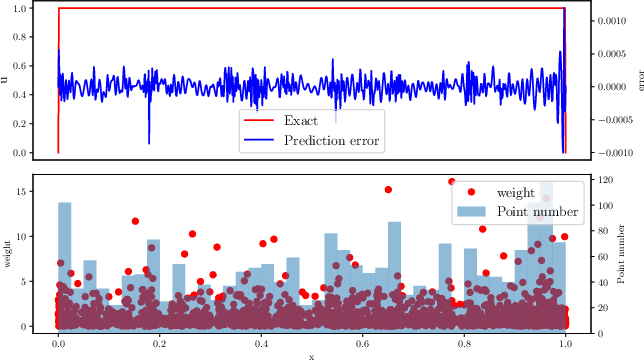
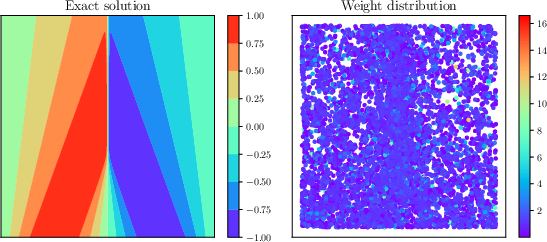
This stiff ODE, with solutions exhibiting thin boundary layers, illustrates a failure mode of PINNs with uniform sampling—minimal training residual but large prediction error in the boundary layer. Adaptive sampling alone significantly boosts accuracy, while adaptive weighting is insufficient unless the batch size is high. The combined approach reduces L2 error to 0.01% with 2048 points—surpassing both prior work and standard PINNs by a large margin with a much smaller batch size. The distribution of weighted training points shows concentration in the layers and nearly uniform weighting across points.
Figure 3: Perturbation problem: PINN prediction errors and exact solution (top), alongside adaptive weights and residual point distributions (bottom).
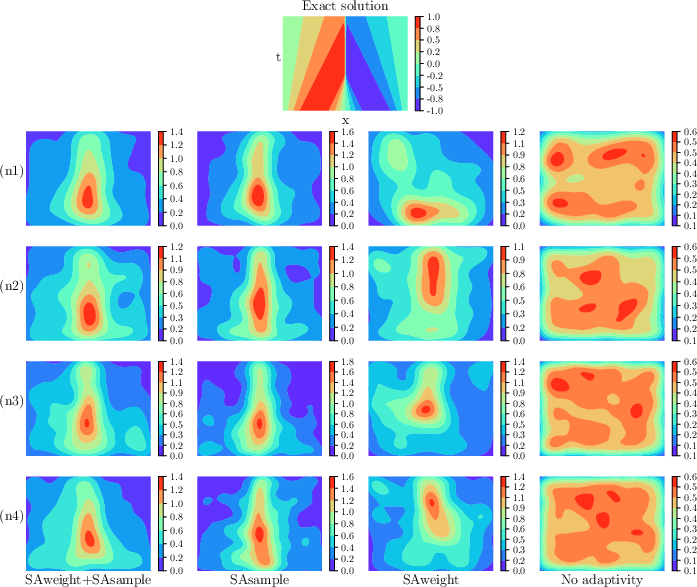
Allen–Cahn and Burgers Equations
For time-dependent nonlinear PDEs with propagating fronts or shocks, adaptive weighting yields improvements only when the batch size is sufficiently large, whereas adaptive sampling alone is relatively batch-size invariant but may over-concentrate on large-gradient regions. The combined method achieves minimal errors at all tested batch sizes and optimally balances between focusing on initial/boundary conditions and capturing localized solution features.
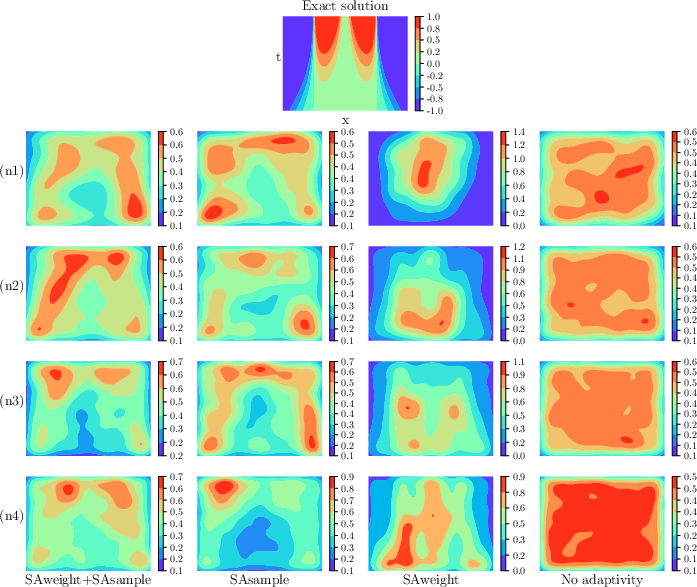
Weighted kernel density estimates confirm that the joint method spatially allocates points and density where both initial conditions and sharp fronts/shocks are important for regression.
Figure 4: Weighted density estimation for the Allen–Cahn equation under different sampling, weighting, and batch size regimes.
Figure 5: Weighted density estimation for the Burgers equation across training strategies and increasing collocation counts.
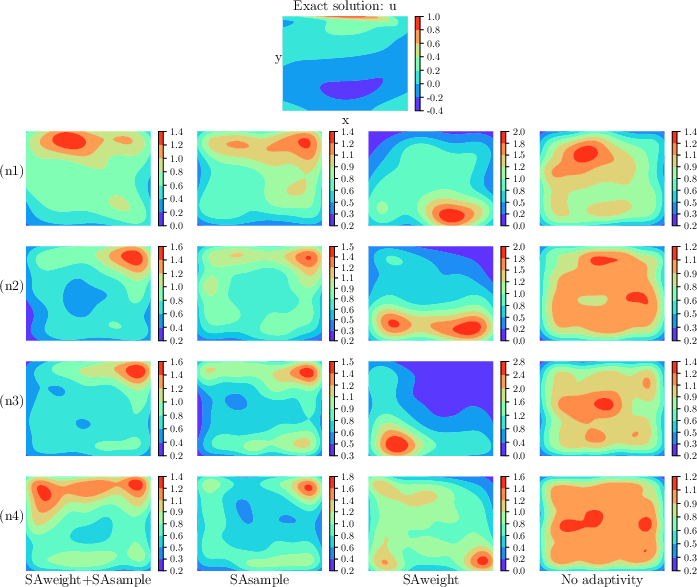
Lid-driven Cavity Flow
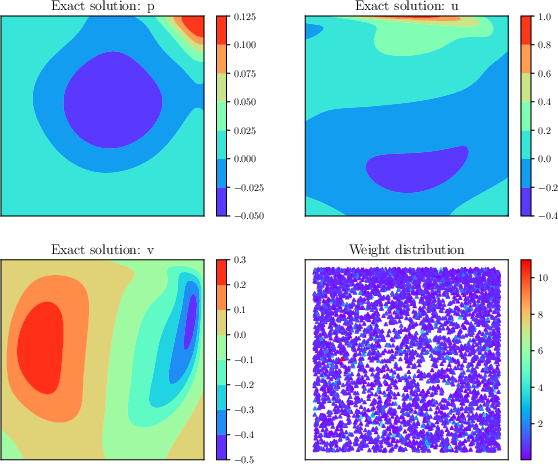
For incompressible Navier–Stokes with sharp vortical features near boundaries and corners, similar trends emerge. Adaptive weighting alone increases density near regions critical for capturing secondary vortices; adaptive sampling fixes on large-gradient regions (top-right corner). Their combination ensures comprehensive focus and achieves uniformly low errors.
Figure 6: Weighted density estimation for the lid-driven cavity flow, emphasizing emphasis on vortices and sharp boundary layers with hybrid adaptive strategy.
Hyperparameter Robustness
A systematic study on the Burgers equation explores:
Update frequency (Ns): Lower values increase accuracy at minor computational cost.
Fraction updated (pu): Optimal within [0.2, 0.6]; updating all points every cycle can degrade stability.
Figure 7: Hyperparameter study of adaptive sampling for the Burgers equation: error and training time versus update frequency, clipping, and point update fraction.
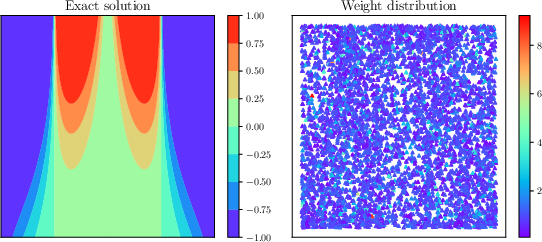
Distribution of Training Points and Weights
Visualizations after training indicate that adaptive sampling clusters points in regions of steep gradients, while adaptive weighting ensures a nearly uniform distribution of weights, leading to balanced convergence across the sampled domain.
Figure 8: Allen-Cahn equation: exact solution (left) and color-mapped weight distribution over residual points (right).
Figure 9: Burgers equation: PINN prediction errors, ground truth (left), and colored weight distribution (right) following adaptive training.
Figure 10: Lid-driven cavity flow: PINN errors and reference solution (left); training point distribution colored by weights (right).
Implications and Future Directions
This work demonstrates that neither adaptive weighting nor sampling alone is sufficient for universal PINN robustness—especially under limited training point budgets or challenging solution features. However, their principled combination achieves consistently high accuracy, efficient training, and robustness across diverse PDEs.
From a theoretical perspective, the BRDR-weighted adaptive sampler offers a pathway toward convergence guarantees in multi-loss PINN settings, while shedding light on the nuanced interaction between point density and loss landscape geometry. Practically, the method is straightforward to implement in contemporary deep learning frameworks, introduces only modest computational overhead, and requires minimal tuning.
Future extensions include:
Automated hyperparameter optimization across even wider problem classes (e.g., high-dimensional, multi-physics PDEs).
Integration with advanced initialization and continual learning schemes.
Coupling with operator learning (e.g., DeepONet) or multi-fidelity/data-driven PINNs.
Conclusion
The self-adaptive hybrid weighting and sampling framework for PINNs synchronizes the strengths of both residual-driven sampling and balanced weight assignment throughout training. Empirical evidence illustrates that this method significantly improves accuracy and efficiency on canonical PDE benchmarks, even in the low batch size or highly nonuniform solution regime. This approach forms a strong foundation for further advances in computational PDE learning with neural networks.