SPICE: Self-Play In Corpus Environments Improves Reasoning
Abstract: Self-improving systems require environmental interaction for continuous adaptation. We introduce SPICE (Self-Play In Corpus Environments), a reinforcement learning framework where a single model acts in two roles: a Challenger that mines documents from a large corpus to generate diverse reasoning tasks, and a Reasoner that solves them. Through adversarial dynamics, the Challenger creates an automatic curriculum at the frontier of the Reasoner's capability, while corpus grounding provides the rich, near-inexhaustible external signal necessary for sustained improvement. Unlike existing ungrounded self-play methods that offer more limited benefits, SPICE achieves consistent gains across mathematical (+8.9%) and general reasoning (+9.8%) benchmarks on multiple model families. Our analysis reveals how document grounding is a key ingredient in SPICE to continuously generate its own increasingly challenging goals and achieve them, enabling sustained self-improvement.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SPICE, a way for an AI model to teach and test itself using real documents from the web. The model plays two roles: it creates questions based on a document (like a quiz maker) and then tries to answer those questions without seeing the document (like a student). By repeating this game many times, the model learns to think more clearly and solve harder problems, especially in math and general knowledge.
What questions is the paper trying to answer?
Here are the main things the researchers wanted to figure out:
- Can an AI keep improving its reasoning by practicing on questions it creates from real documents, instead of only using pre-made datasets?
- Does grounding questions and answers in actual documents reduce “hallucinations” (made-up facts)?
- Is it better for the AI to have different roles—one making questions and one solving them—so the tasks stay genuinely challenging?
- Will this approach help across different subjects (like math and general knowledge), not just in one area?
How does SPICE work? Methods explained simply
Think of SPICE like a two-player game, except it’s the same model playing both parts:
- Challenger (quiz maker): The model reads a slice of a real document (like a Wikipedia-like page) and creates a question and the correct answer based on that document. It can make:
- Multiple-choice questions (MCQs)
- Free-form questions where the answer is a number, expression, or short text
- Reasoner (student): The model tries to answer the question without seeing the document—only the question itself. This creates “information asymmetry,” meaning the solver doesn’t know the source, so it must reason instead of memorizing.
Rewards (how the model learns):
- The Reasoner gets rewarded when it answers correctly.
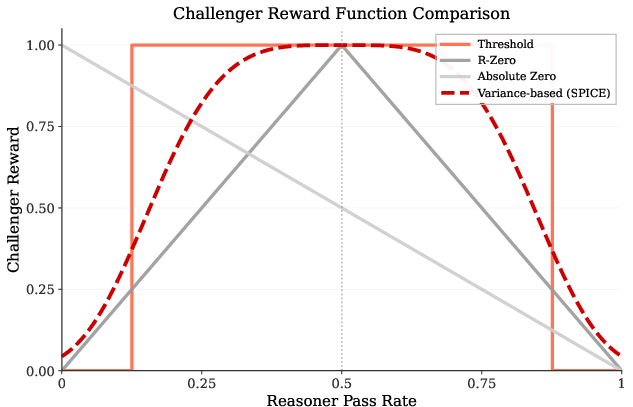
- The Challenger gets rewarded most when the question is roughly “medium-hard”—not too easy, not impossible. Think of it like designing a quiz where about half the attempts get it right: that’s a sweet spot for learning. Mathematically, they use the variation in correct/incorrect answers to judge how challenging the question is.
Why use real documents?
- Grounding in documents keeps the questions and answers factual, so the model doesn’t drift into false information.
- A huge variety of documents means endless fresh topics and difficulty levels—great for steady improvement.
Training loop (in everyday terms):
- The Challenger reads a document and makes a question plus a correct answer found in the text.
- The Reasoner tries to answer the question without the document.
- The system checks if the answer is correct and gives rewards.
- Repeat this many times so both roles get better: the quiz maker builds trickier but fair questions; the student learns to reason better.
What did they find?
The researchers tested SPICE on different base models and on both math and general reasoning tests. They compared SPICE to other methods, including self-play without documents and fixed “strong” question generators.
Main findings:
- SPICE consistently improved performance across models and subjects. For example, it often added 6–12 percentage points over the base models.
- Math scores went up by about 9 percentage points on average.
- General reasoning scores went up by about 10 percentage points on average.
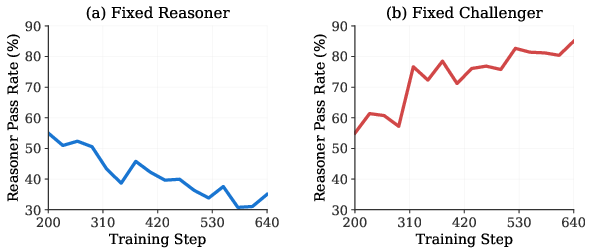
- The Challenger and Reasoner co-evolved:
- Over time, the Challenger made harder questions (the same fixed Reasoner’s pass rate dropped from ~55% to ~35%).
- The Reasoner improved at solving questions (its pass rate against a fixed Challenger rose from ~55% to ~85%).
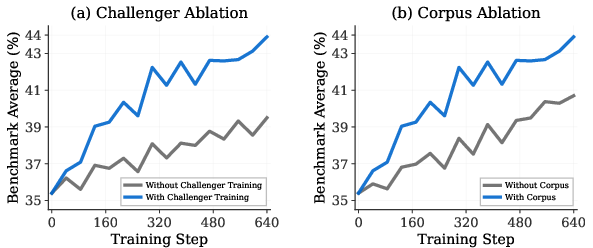
- Using real documents was crucial. Without document grounding, improvements were smaller and less stable. With grounding, the system kept finding new, factual challenges and kept improving.
Why this is important:
- The model didn’t need human-created labeled data or special tools (like code executors) for most tasks.
- It worked across many types of problems (not just math or coding), showing broader reasoning growth.
What does this mean? Implications and impact
- Better self-improvement: SPICE shows that AI can get smarter on its own by interacting with an “environment” of real-world documents. This reduces the need for human-curated datasets.
- Less hallucination: Because questions and answers come from actual documents, the model’s practice is anchored in facts.
- Stronger general reasoning: The approach isn’t limited to one domain—it helps across math and many subjects.
- Scalable learning: Since the web has countless documents, the model has a nearly endless source of fresh practice material.
In short, SPICE is like giving an AI both a textbook and a clever teacher inside itself. The teacher makes fair, challenging quizzes from the textbook, and the student learns to reason better each time. This could be a big step toward AI systems that continuously improve their thinking without constant human supervision.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable items for future work.
- Corpus scale and diversity limits: The training uses only ~20,000 documents; it is unclear how performance scales with larger, more diverse corpora and whether gains saturate or continue with more data sources and domains.
- Corpus selection strategy: Documents are sampled uniformly; investigate whether active retrieval (e.g., skill-targeted selection, difficulty-aware sampling, or deficit-driven retrieval) yields better curricula and faster learning.
- Decontamination and leakage: Assess and report benchmark contamination risks (e.g., overlap of Nemotron-CC-Math/NaturalReasoning with test sets) and implement rigorous decontamination to ensure improvements are not due to memorization.
- Grounded task solvability audit: Quantify the fraction of Challenger-generated questions that are truly solvable without document access (i.e., all needed facts are contained in the question) and characterize failure cases where hidden document facts are required.
- Validation error rates: Measure rates of incorrect “valid” tasks slipping past formatting/parsing checks, and quantify the impact of subtle ambiguities or mis-extractions on training signal quality.
- Verifier robustness beyond math: Math-Verify handles expressions; for non-math free-form string answers, exact match is brittle. Evaluate more robust verifiers (semantic equivalence, normalization, or rule-based matching) and quantify verification-induced noise.
- General-domain free-form answers: Extend beyond integer/expression/string types to more complex open-ended answers (e.g., short proofs, multi-fact synthesis) and develop scalable verification for these cases.
- Adversarial task quality: Analyze whether the Challenger maximizes reward by crafting ambiguous or trick questions; introduce ambiguity detection, clarity checks, and challenge-quality scoring to prevent pathological curricula.
- Reward sensitivity and alternatives: Systematically ablate the Gaussian variance target (0.25), group size G, and K sampling; compare against information gain, entropy-maximizing rewards, regret-based rewards, or learning-progress signals.
- Role-sharing interference: The single shared model acts as both Challenger and Reasoner; study whether separate models (or partially shared encoders) improve stability, reduce interference, or better enforce information asymmetry.
- Information asymmetry leakage: Analyze whether gradients from role=C (with document tokens) lead to memorization of corpus-specific facts that erode asymmetry over time; consider gradient gating, role-specific adapters, or data sanitization.
- Curriculum dynamics characterization: Provide metrics for curricular novelty, reuse, and difficulty drift; track whether the Challenger cycles through similar task templates versus discovering truly new reasoning challenges.
- Efficiency and compute cost: Generating up to N=1024 attempts per document is computationally heavy; quantify throughput, energy, and cost; explore candidate pruning, early stopping, or scoring models to reduce attempts.
- Scaling laws: Evaluate SPICE across larger models (e.g., 32B+) and report scaling behavior (returns vs parameters and tokens); identify model-size regimes where gains increase, plateau, or regress.
- Stability across seeds: Report variance across multiple training seeds and runs, including confidence intervals for benchmark gains, to establish statistical reliability.
- Transfer to non-benchmark tasks: Assess whether SPICE-trained models maintain or improve capabilities in domains not evaluated (e.g., code, long-context reasoning, multi-turn dialogue, multilingual tasks).
- Safety and content filtering: Detail corpus filtering for harmful, biased, or copyrighted content; evaluate whether adversarial Challenger dynamics increase unsafe generations and implement safety-aware rewards or filters.
- Robustness to noisy/low-quality corpora: Stress-test SPICE with noisier web sources to quantify degradation and develop noise-robust generation/verification pipelines.
- Long-context effects: Documents up to ~5,992 tokens are used; investigate how longer contexts, chunking strategies, and cross-document reasoning affect task generation and Reasoner performance.
- Benchmark evaluation reliance: Use of GPT-4o for math equivalence checking may affect reproducibility; provide alternative open-source verifiers, sensitivity analysis to verifier changes, and full prompt/eval artifacts.
- Comparative baselines: Include stronger RLVR baselines (e.g., domain-general verifiable rewards) and offline corpus-mined SFT baselines to isolate the specific contribution of online self-play RL versus synthetic-data finetuning.
- Ablations on key hyperparameters: Beyond reward and task type, systematically ablate group size G, temperature, N attempt cap, penalty ρ, batch size B, and iteration T to reveal sensitivity and optimal regimes.
- Role prompting and format robustness: Quantify how prompt changes (e.g., Reasoner’s boxed answer requirement) affect verification accuracy and training signal; evaluate alternative prompting strategies.
- Failure mode taxonomy: Build a dataset of common failure cases (invalid tasks, ambiguous answers, verification mismatches, unsolvable-without-doc questions) and measure their impact on training and downstream performance.
- Curriculum novelty measurement: Introduce metrics (e.g., semantic similarity, template detection) to ensure that Challenger-generated tasks are not just superficial rephrasings but introduce genuinely new reasoning patterns.
- Domain coverage: Extend corpora beyond math and NaturalReasoning (e.g., law, medicine, finance, policy) and track domain-specific transfer to corresponding benchmarks with appropriate verifiers.
- Online versus offline generation: Compare SPICE’s online adversarial generation to offline corpus-mined datasets matched in scale and diversity to isolate the marginal gains of online co-evolution.
- Theoretical guarantees: Develop formal analysis of SPICE’s training dynamics (convergence, stability under variance rewards, avoidance of collapse/overfitting) and characterize conditions for sustained self-improvement.
- Memory and repetition control: Add mechanisms to avoid reusing similar questions across iterations, track coverage, and diversify the Challenger’s exploration over the corpus.
- Multi-agent extensions: Explore more than two roles (e.g., Reviewer/Explainer) or triadic games where secondary agents critique and refine tasks/solutions, and quantify their impact on reasoning gains.
- Multilingual and cross-cultural grounding: Test SPICE with non-English corpora and measure cross-lingual transfer, verification feasibility, and cultural bias mitigation.
- Downstream deployment risks: Evaluate whether SPICE-trained models exhibit changes in calibration, overconfidence, or error types in real-world tasks, and incorporate calibration-aware training objectives.
Glossary
- Ablation studies: Experimental analyses that remove or vary components to assess their impact on performance. "To understand the key components driving SPICE's performance, we conduct comprehensive ablation studies on Qwen3-4B-Base."
- Adversarial dynamics: A training setup where components (agents or roles) compete in ways that drive mutual improvement. "Through adversarial dynamics, the Challenger creates an automatic curriculum at the frontier of the Reasoner's capability."
- AIME'24: A 2024 edition of the American Invitational Mathematics Examination used as a benchmark for mathematical reasoning. "AIME'24, AIME'25 competition problems from the American Mathematics Competitions."
- AMC: American Mathematics Competitions, a set of math challenges used as benchmarks in the paper. "and AMC, AIME'24, AIME'25 competition problems from the American Mathematics Competitions."
- Answer equivalence checking: Automatically verifying whether a model’s answer matches the gold answer, possibly up to mathematical equivalence. "We use the simple-evals framework with GPT-4o for answer equivalence checking."
- Automatic curriculum: A self-generated progression of task difficulty tailored to the model’s current ability. "Through adversarial dynamics, the Challenger creates an automatic curriculum at the frontier of the Reasoner's capability."
- BBEH: An extension of BIG-Bench Hard comprising complex reasoning tasks used for evaluation. "and BBEH), extending BIG-Bench Hard with more complex reasoning tasks."
- Binary Correctness Reward: A reward signal that grants credit only when the model’s answer exactly matches the gold answer. "Binary Correctness Reward. The Reasoner receives a correctness reward r_R(\hat{a}, a*) = \mathds{1}[\hat{a} = a*] conditioned on a rule-based verifier that checks answer equivalence with the document-extracted gold answer."
- Chain-of-thought reasoning: Step-by-step solution strategies that aid complex problem solving in LLMs. "Recent models like OpenAI o1 and DeepSeek-R1 demonstrate that RL with verifiable rewards (RLVR) can unlock chain-of-thought reasoning using rule-based rewards."
- Challenger: The role in SPICE that generates document-grounded tasks to challenge the Reasoner. "We introduce SPICE ... where a single model acts in two roles: a Challenger that mines documents from a large corpus to generate diverse reasoning tasks, and a Reasoner that solves them."
- Corpus grounding: Anchoring generated tasks and answers in external documents to improve factuality and diversity. "corpus grounding provides the rich, near-inexhaustible external signal necessary for sustained improvement."
- Corpus-grounded self-play: A self-play framework where tasks are generated from external documents and answers are verifiable from those documents. "We propose corpus-grounded self-play where a model acting in two roles (Challenger and Reasoner) generates tasks with document-extracted answers and solves them."
- Distributed actor-learner architecture: A training system with parallel actors generating data and a learner updating the model. "Our training framework builds on Oat, which provides interfaces for a distributed actor-learner architecture."
- Document Sampling: Selecting passages from a corpus to serve as contexts for task generation. "Document Sampling. We uniformly sample passages from a large document corpus, extracting segments as documents d ∈ 𝒟."
- Document-grounded answers: Gold answers that are directly extracted from the source document to ensure verifiability. "document-grounded answers ensure verification remains factually anchored."
- DrGRPO: A reinforcement learning optimization method used to compute role-specific advantages and update the policy. "We use DrGRPO with a separate advantage computation for each role."
- Gaussian-shaped reward function: A reward profile that peaks at an optimal difficulty and decreases for too-easy or too-hard tasks. "This Gaussian-shaped reward function is scaled to [0,1], maximizing at 1.0 when variance equals 0.25 (50% pass rate), indicating optimal task difficulty."
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step, often used for evaluation reproducibility. "We use greedy decoding (temperature 0) for most evaluations to ensure reproducibility."
- GSM8K: A benchmark of grade-school math word problems used to assess reasoning. "GSM8K, grade-school word problems."
- Information asymmetry: A setup where the generator has access to information (documents) that the solver does not, increasing challenge. "A key component is information asymmetry: the Challenger grounds questions and gold answers in retrieved documents unseen by the Reasoner."
- Intrinsic motivation: A self-driven signal in agents that encourages exploration and curriculum emergence without external rewards. "Self-play can even create automatic curricula through intrinsic motivation."
- LLMs: LLMs capable of broad reasoning across domains. "This vision is becoming tangible with LLMs (LLMs; ...), which demonstrate remarkable reasoning abilities across diverse domains."
- Math-Verify: A tool/library for verifying the equivalence of mathematical answers and exact matching for other types. "Math-Verify ... which handles equivalence checking for mathematical expressions and exact matching for other answer types."
- MCQ: Multiple-Choice Questions, a structured task format with predefined options. "multiple-choice questions (MCQ) with four options and a document-grounded correct answer."
- MATH-500: A curated set of challenging competition math problems used for evaluation. "MATH-500, a curated subset of challenging competition problems."
- Minerva Math: A benchmark covering STEM topics used for mathematical reasoning evaluation. "Minerva Math, covering STEM topics."
- MMLU-Pro: A more rigorous version of MMLU for multi-task understanding and deeper reasoning. "MMLU-Pro, a challenging multi-task understanding dataset."
- Multi-Agent RL: Reinforcement learning involving multiple agents interacting within environments or games. "Implementing multi-agent RL for full-scale LLMs presents significant technical challenges."
- Oat: A training framework used to build the self-play RL system with distributed actor-learner support. "Our training framework builds on Oat, which provides interfaces for a distributed actor-learner architecture."
- OlympiadBench: A benchmark of olympiad-level math problems used to evaluate advanced reasoning. "OlympiadBench, featuring olympiad-level problems."
- Online adversarial generation: Continuous, on-the-fly creation of tasks in response to the solver’s current abilities. "SPICE differs fundamentally through online adversarial generation where the Challenger continuously mines corpus contexts to generate tasks calibrated to the Reasoner's current capability."
- Pass@1 accuracy: The probability that the top (first) generated solution is correct, a standard metric for reasoning tasks. "For other mathematical reasoning benchmarks, we report pass@1 accuracy with greedy decoding for MATH-500..."
- Policy gradient: An RL method that updates model parameters by ascending the gradient of expected returns. "Update πθ via policy gradient with advantages {Â_Ci} and {Â_Ri}."
- R-Zero: An ungrounded self-play baseline where models generate and solve their own tasks without external documents. "R-Zero, pure self-play without corpus grounding where the model generates its own questions from scratch without document access."
- Reasoner: The role in SPICE that attempts to solve tasks generated by the Challenger, without access to documents. "When acting as Reasoner (R), the model πθ learns to solve the Challenger's tasks without document access."
- Reinforcement learning with verifiable rewards (RLVR): RL that utilizes automatically checkable rewards to guide learning. "Models like OpenAI o1 and DeepSeek-R1 achieve expert-level performance on mathematical and coding tasks through reinforcement learning with verifiable rewards (RLVR)."
- RLHF: Reinforcement Learning from Human Feedback, used to align model behavior with human preferences. "Reinforcement learning has evolved from alignment tasks using RLHF to directly improving reasoning capabilities."
- Rule-based verifier: A deterministic checker that confirms whether generated answers match gold answers, often beyond string equality. "The Reasoner receives a correctness reward ... conditioned on a rule-based verifier that checks answer equivalence with the document-extracted gold answer."
- Self-play: A training paradigm where agents learn by interacting with themselves, generating tasks and feedback internally. "To scale these capabilities without human supervision, self-play offers a promising paradigm."
- Self-supervised: Learning without explicit human labels, using the structure of data or generated signals. "The entire framework is self-supervised, requiring no human intervention, only a large unstructured corpus."
- SuperGPQA: A graduate-level benchmark spanning many disciplines designed to be resistant to simple lookup. "SuperGPQA, a large-scale benchmark targeting graduate-level reasoning across 285 disciplines with Google-search-resistant questions."
- Universal verifiers: General-purpose checks that can verify answers across many domains without specialized executors. "Tasks are generated with diverse formats ... which serve as universal verifiers, enabling self-play across any language domain without requiring specialized executors or rule-based validators."
- Variance-based curriculum reward: A reward scheme that uses the variance of solver success to target tasks at optimal difficulty. "Variance-Based Curriculum Reward."
- vLLM: An inference engine/library enabling efficient LLM generation at scale. "using vLLM for efficient model inference during both Challenger and Reasoner generation phases."
- Zero-shot setting: Evaluation without task-specific fine-tuning or examples, testing generalization. "All models are evaluated in a zero-shot setting to assess whether the reasoning capabilities ... transfer to standard benchmarks."
- Zero-sum games: Competitive settings where one agent’s gain is exactly another’s loss, used to teach transferable reasoning. "SPIRAL demonstrates that zero-sum games between agents can teach transferable reasoning."
Practical Applications
Overview
The paper introduces SPICE, a reinforcement learning framework where a single model alternates between two roles—Challenger and Reasoner—to generate and solve document-grounded reasoning tasks via self-play. Key innovations include: (1) information asymmetry (Challenger sees documents; Reasoner does not), (2) corpus grounding to prevent hallucination and provide inexhaustible novelty, (3) a variance-based reward that calibrates task difficulty around the Reasoner’s frontier of capability, and (4) multi-format tasks (MCQ and free-form with typed answers) that enable verification without domain-specific executors. SPICE consistently improves mathematical and general reasoning across multiple base models, indicating real-world potential beyond narrow domains.
Below are practical applications grouped by deployment horizon.
Immediate Applications
These can be piloted today with existing LLMs, internal corpora, and standard inference/RL tooling (e.g., vLLM, actor-learner stacks), ideally within teams that already operate ML workloads.
- Enterprise self-improving assistants on private corpora
- Sectors: software, enterprise productivity
- Use case: Continuously fine-tune internal chat/agent models using SPICE on wikis, SOPs, incident postmortems, and design docs. The Challenger mines documents to build a curriculum; the Reasoner learns to answer without document access, improving closed-book reasoning about internal processes.
- Tools/workflows: Corpus connectors and chunkers; “Corpus-Curriculum Engine” that schedules SPICE cycles; role-specific RL pipeline (DrGRPO); answer verification modules; dashboards for pass-rate drift (fixed-Challenger/Reasoner diagnostics from the paper).
- Assumptions/dependencies: Sufficient compute; clean, licensed internal corpora; basic verifiers for non-math answers (string normalization, exact match); privacy and access controls.
- Compliance and policy curriculum generation
- Sectors: finance, healthcare, government, legal
- Use case: Generate calibrated MCQs and free-form questions from policy manuals and regulations for employee training, with automatic difficulty control via the variance reward.
- Tools/workflows: “Compliance Curriculum Builder” (document ingestion, question synthesis, difficulty calibration, human review loop); LMS integration.
- Assumptions/dependencies: Up-to-date policy texts; SME review for high-stakes content; audit logs; licensing and retention policies.
- Customer support knowledge reinforcement and benchmarking
- Sectors: software, telecom, e-commerce
- Use case: From support articles and troubleshooting guides, create evolving, challenging QA sets to train and stress-test support chatbots (e.g., escalate edge-case “how-to” or misconfiguration scenarios).
- Tools/workflows: “Support Challenger” to mine FAQs and release-notes; continuous evaluation harness using SPICE’s fixed-Challenger/fixed-Reasoner analyses; ticket deflection A/B tests.
- Assumptions/dependencies: Accurate knowledge base; answer equivalence rules; safety filters for sensitive content.
- Adaptive practice generation for courses and textbooks
- Sectors: education, edtech
- Use case: Turn textbooks, lecture notes, and OER into dynamic practice with MCQs and free-form items; use the variance reward to keep learners at an optimal challenge level.
- Tools/workflows: “Adaptive Corpus Tutor” (content ingestion, SPICE-style task generation, student difficulty targeting using the 50% pass-rate heuristic); LMS export.
- Assumptions/dependencies: Content licensing; age-appropriateness filters; human-in-the-loop vetting for grading edge cases.
- Dynamic red-teaming and factuality stress tests
- Sectors: AI safety, platform quality, search
- Use case: Challenger generates document-grounded adversarial questions to probe hallucinations; Reasoner responses audited for factuality without access to source docs.
- Tools/workflows: “Variance-Calibrated Factuality Bench” (corpus selection, adversarial QA generation, runbooks for regression triage); scoreboard over time.
- Assumptions/dependencies: Curated reference corpora (e.g., Wikipedia, standards docs); robust answer extraction and normalization.
- Data curation and training set prioritization
- Sectors: ML ops, data engineering
- Use case: Use Challenger rewards to identify documents that yield high-learning-value questions (near 50% pass rate), prioritizing them for annotation, SFT, or RL.
- Tools/workflows: “Curriculum Miner” to rank documents by variance-based utility; pipeline hooks into labeling or RL queues.
- Assumptions/dependencies: Monitoring to avoid overfitting to a narrow set of “spiky” documents; de-duplication; content diversity checks.
- RAG-to-weights knowledge distillation
- Sectors: software, search
- Use case: Convert frequently retrieved knowledge into model-internal reasoning using SPICE tasks drawn from RAG corpora; reduce latency and dependency on retrieval at inference time.
- Tools/workflows: “RAG Distiller” (sample top-K retrieved passages, generate SPICE tasks, closed-book RL updates; guardrails for leakage of sensitive text).
- Assumptions/dependencies: Legal right to train on retrieval sources; deduplication to prevent memorizing proprietary passages; careful evaluation of regurgitation risk.
- Domain bootstrap for smaller labs/teams
- Sectors: academia, startups, public-sector IT
- Use case: Rapidly build domain-specific reasoning models using small base LLMs (3B–8B) and modest corpora (≈20k docs) as demonstrated in the paper, outperforming ungrounded self-play.
- Tools/workflows: “SPICE-Lite” (Challenger-only dataset generation followed by SFT) as a lower-compute alternative; full SPICE when compute permits.
- Assumptions/dependencies: RL expertise or managed RL services; evaluation suites (MMLU-Pro, GPQA), or custom domain tests.
- Clinical and guideline-grounded assistants (pilot, non-critical)
- Sectors: healthcare
- Use case: Train models to reason about guidelines and protocols (e.g., documentation comprehension, coding, and administrative workflows), with document-grounded verification.
- Tools/workflows: “Clinical Corpus Challenger” (curated guideline repositories, de-identification, SPICE QA generation); strict human review before deployment.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR), clinically validated verifiers, SME oversight; avoid direct diagnostic decisions.
Long-Term Applications
These require additional research, tooling (especially verifiers), scaling, or governance frameworks to be production-ready.
- Always-on corpus-grounded continual learning
- Sectors: software, media, search
- Use case: A deployed model continuously reads fresh corpora (news, docs, knowledge bases), auto-generates curricula, and updates itself while monitoring for regressions.
- Tools/workflows: “Always-on Corpus Learner” with change-detection, drift monitoring, rollback; decoupled challenger sandboxes; privacy-by-design pipelines.
- Assumptions/dependencies: Robust catastrophic-forgetting controls; legal approval for continuous training on incoming data; safety gates.
- Universal verifiers beyond math and exact match
- Sectors: healthcare, law, science, policy
- Use case: Domain verifiers for textual entailment, structured fact checking, table reasoning, and scientific claims—expanding SPICE’s verification coverage.
- Tools/workflows: “Verifier Hub” (plug-in verifiers for citations, causal claims, tabular consistency, code execution, simulation-based checks).
- Assumptions/dependencies: Building trustworthy, reference-backed verifiers is nontrivial; requires datasets, rules, or executable semantics per domain.
- Multi-modal SPICE (text, tables, figures, code, diagrams)
- Sectors: engineering, robotics, education
- Use case: Challenger mines multi-modal docs (manuals, circuit diagrams, charts) and creates mixed-format questions; Reasoner solves without assets.
- Tools/workflows: “SPICE-X” with multi-modal encoders, OCR/structure parsers, programmatic verifiers (e.g., unit checks, plotting comparisons).
- Assumptions/dependencies: Mature multimodal LLMs; multi-modal verifiers; licensing for images/diagrams.
- Personalized tutors with variance-calibrated difficulty
- Sectors: education, workforce training
- Use case: Replace model-level self-play signals with human learner performance; keep difficulty near 50% pass rate to maximize learning gains.
- Tools/workflows: “50% Variance Tutor” (student modeling, privacy-preserving telemetry, adaptive scheduling, spaced repetition).
- Assumptions/dependencies: Reliable measurement of learner ability; explainability and fairness; strong content safety.
- Regulator-run dynamic model evaluation frameworks
- Sectors: public policy, AI governance
- Use case: Government or standards bodies curate corpora (laws, standards, safety cases) and run SPICE-style adversarial testbeds for certification and compliance audits.
- Tools/workflows: “SPICE-Audit” (transparent corpora, fixed-Challenger/Reasoner protocols, reports on factuality and robustness).
- Assumptions/dependencies: Agreement on corpora and scoring; reproducibility requirements; vendor-neutral tooling.
- Safety certifications via adversarial curricula
- Sectors: autonomous systems, finance, healthcare
- Use case: Use Challenger-generated frontier tasks to probe failure modes before deployment; couple with red-team playbooks and incident taxonomies.
- Tools/workflows: “Challenge-to-Certify” (pre-deployment gates, regression suites, auto-triage of newly discovered edge cases).
- Assumptions/dependencies: High-fidelity verifiers and human oversight; liability frameworks.
- High-stakes domain assistants (decision support)
- Sectors: healthcare (clinical decision support), finance (risk), law (legal research)
- Use case: Grounded reasoning over standards, guidelines, case law, and filings to support—but not replace—experts; robust verification and attribution.
- Tools/workflows: Attribution-first interfaces; consensus-checks across multiple Reasoners; SME governance boards.
- Assumptions/dependencies: Strong domain verifiers; rigorous post-training validation; human-in-the-loop mandates.
- Inter-organizational “ChallengeNet”
- Sectors: AI research, benchmarking
- Use case: Labs share Challenger artifacts (document slices + QA templates) as evolving public challenges; models are evaluated on new, harder tasks over time.
- Tools/workflows: Federated challenge exchanges; provenance tracking; anti-data-leak protocols.
- Assumptions/dependencies: Incentive alignment; IP and licensing agreements; standardized formats.
- Foundation model training augmentation
- Sectors: foundation models, pretraining
- Use case: Incorporate corpus-grounded self-play during pretraining or post-pretraining to internalize reasoning from curated corpora without heavy human supervision.
- Tools/workflows: Pretraining pipelines that interleave masked LM, RAG, and SPICE loops; large-scale actor-learner infra.
- Assumptions/dependencies: Massive compute; scalable verifiers; curriculum diversity to avoid narrow specialization.
Cross-cutting dependencies and assumptions
- Data governance: licensing, privacy, and compliance when mining corpora; filters for toxicity and bias.
- Compute and infrastructure: actor-learner RL setup (e.g., Oat + vLLM), group sampling (G≈8), and monitoring; cost controls.
- Verification gaps: outside math/structured answers, verification quality is the bottleneck; many long-term uses hinge on building reliable verifiers.
- Safety and oversight: human-in-the-loop for high-stakes domains; evaluation against regressions using fixed-role diagnostics from the paper.
- Generalization: benefits demonstrated on 3B–8B models and specific corpora; scaling and transfer to other languages/modalities require further validation.
Collections
Sign up for free to add this paper to one or more collections.