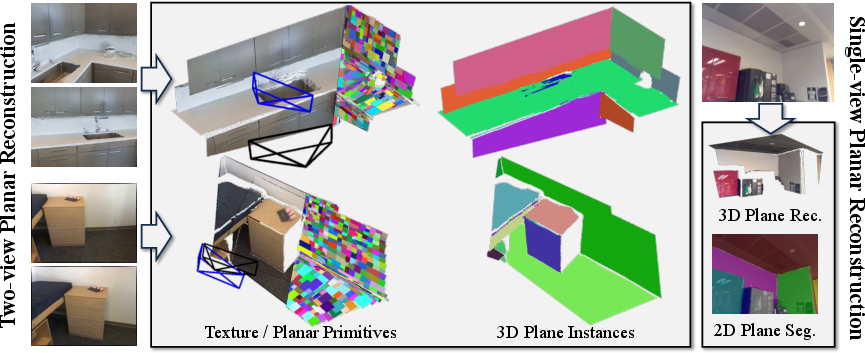
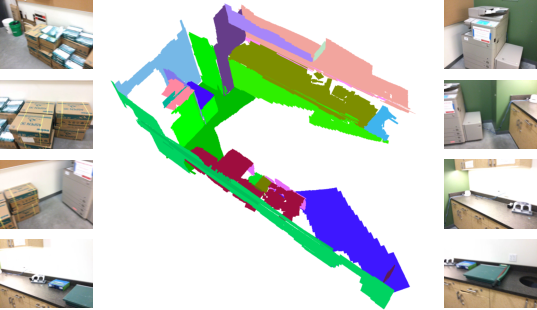
PLANA3R: Zero-shot Metric Planar 3D Reconstruction via Feed-Forward Planar Splatting
Abstract: This paper addresses metric 3D reconstruction of indoor scenes by exploiting their inherent geometric regularities with compact representations. Using planar 3D primitives - a well-suited representation for man-made environments - we introduce PLANA3R, a pose-free framework for metric Planar 3D Reconstruction from unposed two-view images. Our approach employs Vision Transformers to extract a set of sparse planar primitives, estimate relative camera poses, and supervise geometry learning via planar splatting, where gradients are propagated through high-resolution rendered depth and normal maps of primitives. Unlike prior feedforward methods that require 3D plane annotations during training, PLANA3R learns planar 3D structures without explicit plane supervision, enabling scalable training on large-scale stereo datasets using only depth and normal annotations. We validate PLANA3R on multiple indoor-scene datasets with metric supervision and demonstrate strong generalization to out-of-domain indoor environments across diverse tasks under metric evaluation protocols, including 3D surface reconstruction, depth estimation, and relative pose estimation. Furthermore, by formulating with planar 3D representation, our method emerges with the ability for accurate plane segmentation. The project page is available at https://lck666666.github.io/plana3r


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Plana3R, a computer vision method that can build a 3D model of an indoor room from just two photos. Instead of modeling every tiny detail, it uses flat pieces (called planes) like walls, floors, ceilings, and table tops to represent the scene. It also figures out how the camera moved between the two photos (its position and rotation) in real-world units like meters. The big idea: make 3D modeling simpler, faster, and more accurate by using flat surfaces where they naturally exist.
What questions does it try to answer?
- Can we rebuild an indoor scene in 3D using just two unposed photos (photos without known camera positions), and still keep real-world scale (metric)?
- Can we do this without needing expensive, hard-to-make labels that outline every plane in the image?
- Can a system trained this way work well on new, unseen buildings and rooms (“zero-shot”), not just the training data?
How does the method work? (Explained simply)
Think of an indoor scene as mostly made of flat boards: floor, walls, ceiling, doors, cabinets, tabletops. Plana3R tries to rebuild the room by placing a small number of these flat boards in 3D.
Here’s the approach in everyday terms:
- Two photos go in. A special neural network (a Vision Transformer) looks at both images at the same time, like two eyes seeing the same room from different spots.
- It predicts:
- A set of flat pieces (planes), each with a position, size, and direction in 3D.
- The camera’s movement between the two photos (how much it moved and rotated), in meters and degrees. This is called the “relative pose.”
- Training without plane labels: Instead of needing humans to mark every plane, the system learns from two simpler types of information:
- Depth maps: for each pixel, how far away it is (like a distance image).
- Normal maps: for each pixel, which way the surface is facing (think tiny arrows pointing off surfaces).
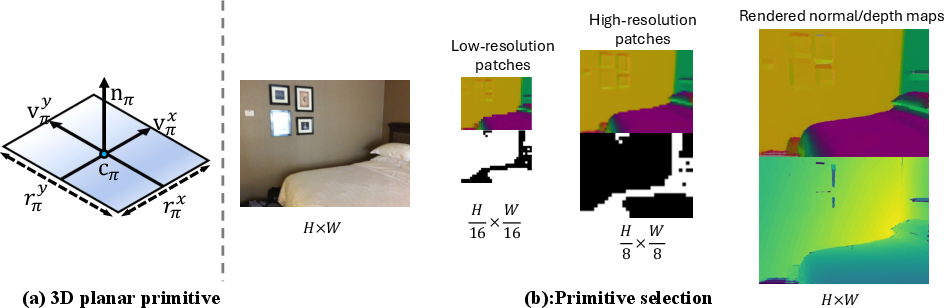
- “Planar splatting” (an analogy): Imagine throwing each predicted flat piece onto a canvas to “paint” a depth and a normal image. The system compares these rendered images to the real depth/normal data and adjusts the planes to fit better. Because this rendering is differentiable, the model can learn directly from the difference.
- Being efficient with detail: Some parts of an image are very flat and simple (like a bare wall), while others are more complex (like shelves with edges). Plana3R uses a “hierarchical” strategy:
- Big, coarse planes for simple regions.
- Smaller, finer planes only where needed (detected by noticing big changes in surface direction).
- This keeps the 3D model compact and fast without losing accuracy where it matters.
- Finally, it merges nearby, similar planes into larger surfaces and, as a bonus, gets plane-by-plane segmentation (which plane is which) without extra labels.
Key terms in simple words:
- Metric: in real-world size (meters), not just “relative” size.
- Relative pose: how the camera moved and rotated from photo 1 to photo 2.
- Zero-shot: working well on new, unseen data without retraining.
- Transformer: a type of neural network that’s good at finding relationships across an image.
- Differentiable rendering: drawing predicted 3D shapes into 2D images in a way that lets the model learn from differences.
What did they find?
Across several tests on indoor datasets, Plana3R performed very well, often better than previous methods:
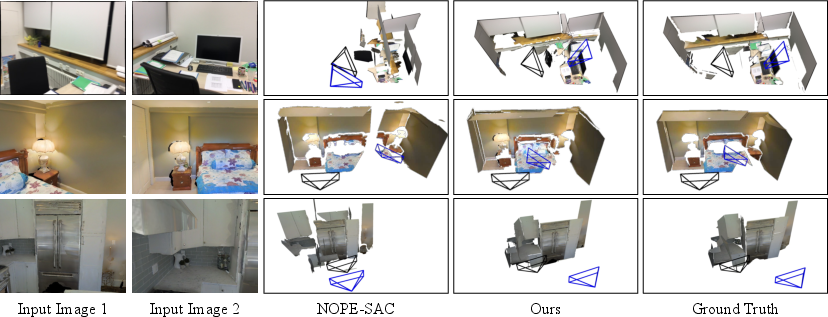
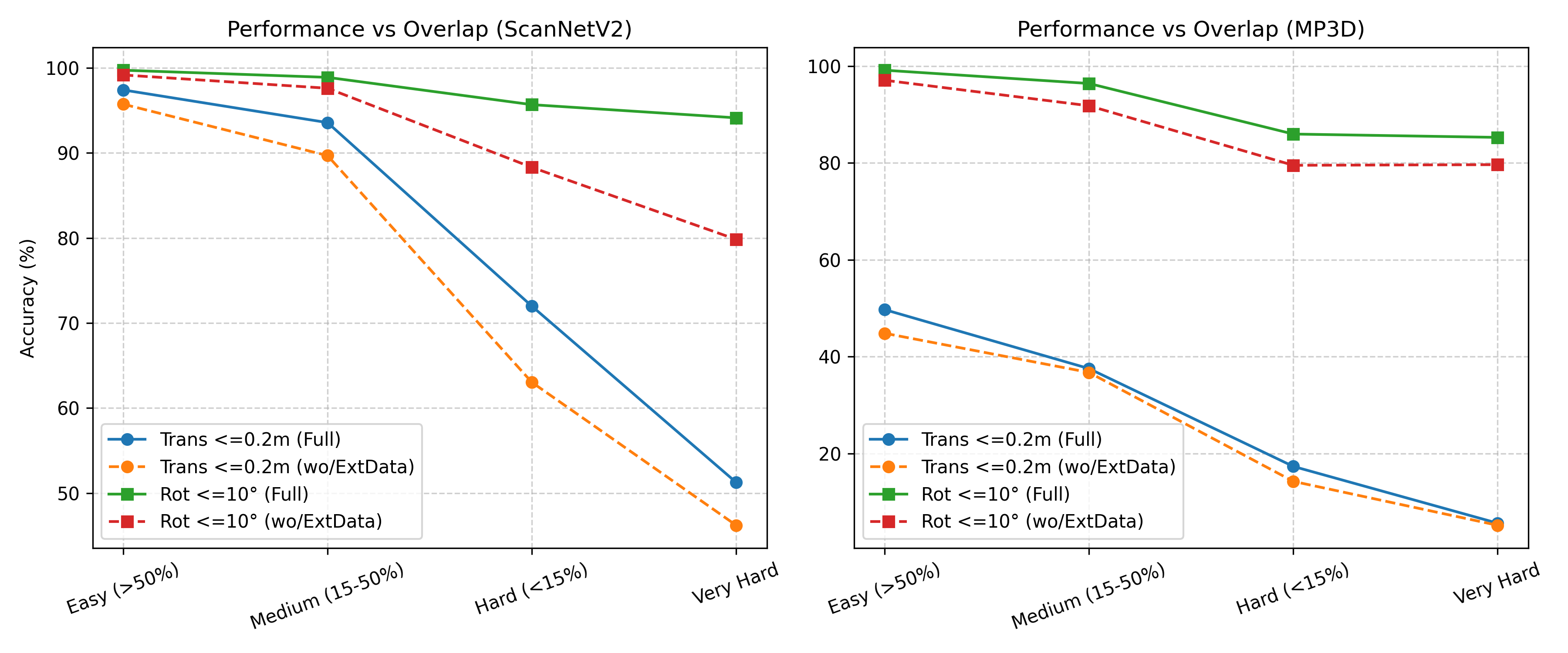
- Two-view 3D reconstruction: It rebuilt rooms accurately using only two photos, beating past plane-based methods on ScanNetV2 and generalizing strongly to Matterport3D (even without being trained on it).
- Camera pose estimation: It estimated how the camera moved between the two photos very accurately (low error in both meters and degrees), matching or beating strong baselines.
- Metric depth from a single image: By feeding the same image twice, it produced high-quality depth maps (distance images) on NYUv2-Plane, outperforming previous plane-based models and even a popular point-cloud-based stereo model.
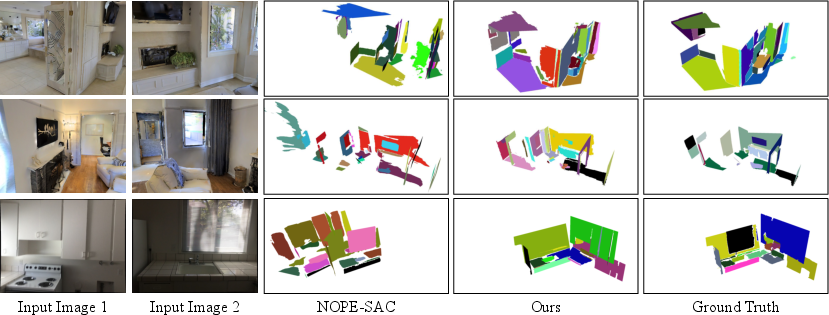
- Plane segmentation: Without any plane masks during training, it still produced meaningful plane segments (like separating walls from ceilings), and did so better than prior plane methods in single-view tests.
- Compact yet accurate: An ablation study showed it could use far fewer planes while keeping nearly the same accuracy—so the representation is efficient.
These results matter because they show you can get accurate, real-world-scale 3D models from minimal input (two photos), without costly labels or exact camera setups.
Why does this matter?
- Practical 3D capture: This makes it easier to create “digital twins” of indoor spaces for AR/VR, real estate, games, or interior design using just a couple of photos.
- Robotics and navigation: Robots benefit from clean, metric 3D maps with planes (walls/floors) for planning and movement.
- Scalable training: Since it doesn’t need detailed plane annotations, it can learn from large datasets that already provide depth and normal maps, making future models easier to train.
- Compact, structured 3D: Plane-based models are lightweight and interpretable. They’re faster, take less memory, and give meaningful parts (like “this is a wall”) automatically.
- Strong generalization: Working well on new, unseen buildings suggests it’s robust and ready for real-world use.
In short, Plana3R shows that using flat surfaces as building blocks is a powerful, efficient way to reconstruct indoor 3D scenes with real-world scale—accurately, quickly, and without expensive labels.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Domain generalization beyond indoor planar scenes is untested: performance on outdoor environments, curved/organic geometry, large open spaces, and mixed man-made/natural scenes remains unknown.
- Strong dependence on known metric intrinsics and metric supervision: sensitivity to inaccurate intrinsics, lens distortion, rolling shutter, or missing calibration is not analyzed; no strategy for self-calibration or scale recovery without metric labels.
- Reliance on pseudo normal labels (Metric3Dv2) is not quantified: the impact of pseudo-label noise and bias on training and inference quality is unstudied; no ablation comparing ground-truth vs. pseudo normals.
- Two-view-only architecture and pairwise multi-view merging: there is no single-pass N-view model or mechanism for enforcing global multi-view geometric and pose consistency; potential drift from pairwise aggregation is not assessed.
- Heuristic HPPA gating by normal-gradient threshold (g_th) is fixed and non-learned: no analysis of dataset-specific sensitivity, per-scene adaptivity, or learned gating/selection; selection based on predicted (potentially noisy) normals may propagate errors.
- Plane merging uses hand-tuned normal and distance thresholds: robustness to threshold choice, over-/under-merging, and scalability across datasets is not evaluated; probabilistic or learned clustering is not explored.
- Occlusion handling in differentiable planar splatting is not examined: it is unclear how the renderer resolves occlusions between primitives and how this affects gradients and reconstruction in cluttered scenes.
- Non-planar geometry is only approximated with many small planes: the accuracy-cost trade-off for curved or complex surfaces is not quantified; hybrid primitives (e.g., quadrics, spline patches, or mesh fragments) are not considered.
- Semantic plane labeling is absent: instance-level segmentation is provided, but associating planes with categories (e.g., wall, floor, table) or scene graphs is not addressed.
- Baseline variation robustness is untested: sensitivity to very small or very large stereo baselines, motion blur, exposure differences, and viewpoint changes is not reported.
- Robustness to sensor noise and label quality is unclear: effects of noisy ARKit depth, synthetic Habitat data, and Metric3Dv2 normal errors on generalization and failure modes are not quantified.
- Pose estimation focuses on relative two-view metrics: the accumulation of pose errors over long sequences, drift behavior, and integration with global pose graph optimization are not studied.
- Inference speed, memory footprint, and energy usage are not reported: practical deployment constraints (e.g., on mobile AR devices) are unknown; time-to-solution vs. per-scene optimization methods is not compared.
- Training scalability and data efficiency are limited: the method requires 256 GPU-days; the minimal data and compute budget for competitive performance and the benefits of alternative pretraining are not analyzed.
- Uncertainty estimation is missing: there are no confidence measures on primitive parameters (normals, radii, depth) or pose; uncertainty-guided merging and selection are not explored.
- Single-view usage is improvised by duplicating the same image: an explicit single-view variant trained and evaluated for monocular inputs is not developed; the limitations of the duplicate-input trick are not characterized.
- Supervisory signals are limited to depth and normals: integration of photometric, silhouette, or multi-view consistency losses (without metric labels) is not explored for self-/semi-supervised learning.
- Failure case analysis is lacking: behavior on reflective/transparent surfaces (windows/mirrors), repetitive textures, dynamic objects, and low-texture scenes is not documented.
- Evaluation coverage is narrow: depth is assessed only on NYUv2-Plane; performance on general NYUv2, KITTI/ETH3D, or broader datasets (including outdoor) is absent; segmentation benchmarking on more domains is limited.
- Comparisons with per-scene optimization (e.g., PlanarSplatting optimization, 3D Gaussian Splatting, NeRF variants) are missing: trade-offs in accuracy, runtime, and memory for equal-view and zero-shot settings are not systematically reported.
- Primitive parameterization may restrict irregular plane boundaries: radii-based extents may poorly capture planes with holes or complex shapes; learned polygonal extents or edge-aware boundaries are not investigated.
- Multi-view merging lacks global optimization: a framework to jointly optimize poses and planes across many views (e.g., pose graph + plane consistency constraints) is not proposed or evaluated.
- Resolution dependence of g_th and patch sizes is not studied: how gating and primitive counts scale with input resolution, and whether thresholds need retuning across resolutions/datasets, is unknown.
- Contribution disentanglement from DUSt3R pretraining is unclear: ablation on starting from scratch or alternative backbones to quantify Plana3R-specific gains is missing.
- Normal-gradient-based selection may be circular: gating uses predicted normals to decide resolution, which may bias selection during early training; alternatives based on confidence or GT proxies are untested.
- Loss design and hyperparameters are under-explored: no ablation on the patch warm-up loss weights, rendering loss composition, or alternative geometric/regularization terms (e.g., planarity, smoothness, sparsity).
- Cross-view plane correspondence is unused: explicit plane matching across views (for supervision and consistency) is not leveraged, which could improve segmentation and pose accuracy.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s core contributions: planar primitive reconstruction, pose-free two-view metric estimation, differentiable planar splatting, and instance-level plane segmentation.
- AR/VR scene understanding and object placement
- Sector: AR/VR, software
- Use case: Place virtual objects on real floors, walls, and tables with correct scale and occlusion using two photos of a room; generate accurate occlusion masks and anchors from predicted planes and metric depth.
- Tools/products/workflows: Mobile SDK plugin for Unity/Unreal that ingests two images + intrinsics and returns planes, depth, normals, and relative pose; cloud API for batch processing.
- Assumptions/Dependencies: Known or estimated camera intrinsics; sufficient overlap between the two views; indoor, planar-rich scenes; acceptable runtime on target hardware (GPU recommended).
- Rapid room measurement and floor/wall area estimation
- Sector: construction/DIY, real estate, retail
- Use case: Compute floor area, wall area, and ceiling area for painting, tiling, and material estimation from two images per room; extract plane segmentation and metric radii to produce measurements.
- Tools/products/workflows: “RoomMeasure Lite” mobile app feature backed by Plana3R; PDF/CSV summaries for contractors and homeowners.
- Assumptions/Dependencies: Indoor planarity (walls/floors/ceilings); modest clutter; metric scaling validated against known intrinsics or a reference length for quality assurance.
- Robotics navigation bootstrap (VO/SLAM assist)
- Sector: robotics
- Use case: Initialize visual odometry and mapping by estimating pairwise relative pose and extracting dominant planes for navigation constraints (floors, walls).
- Tools/products/workflows: ROS node that runs Plana3R on incoming stereo or successive monocular frames, providing planes and relative pose for downstream SLAM.
- Assumptions/Dependencies: Indoor environments; enough texture/features for pose estimation; integration with IMU for robustness.
- Fast digital twins for property listings and virtual staging
- Sector: proptech/real estate
- Use case: Generate compact 3D planar reconstructions of interiors from minimal capture (two photos per viewpoint); support virtual staging with metric scale.
- Tools/products/workflows: Web service that converts uploaded pairs into navigable planar models; export to glTF or CAD-friendly formats.
- Assumptions/Dependencies: Image coverage with overlap; handling of occlusions (some missing surfaces likely); consumer devices provide intrinsics or standardized camera profiles.
- Insurance claims and loss estimation
- Sector: insurance/finance
- Use case: Document damage with metric plane reconstructions; compute affected areas (e.g., water-damaged wall) and provide measurements for claims.
- Tools/products/workflows: Claims app feature to capture two images per surface and automatically quantify surface area and relative pose for context.
- Assumptions/Dependencies: Lighting and visibility; policy acceptance of automated measurements; quality thresholds and audit logs.
- Interior design and furniture fitting
- Sector: e-commerce/retail
- Use case: Place furniture models with correct scale on detected planes (floors, shelves, countertops) using two-view reconstruction.
- Tools/products/workflows: Browser-based configurator that uses plane segmentation to snap models to surfaces and validate fit.
- Assumptions/Dependencies: Accurate plane orientation/normal; material semantics optional (wood/tile recognition not included).
- Privacy-preserving indoor scanning
- Sector: software, policy/privacy
- Use case: Share sparse planar primitives rather than textured meshes or dense point clouds to reduce personally identifiable details while preserving room geometry.
- Tools/products/workflows: “Minimal Geometry Export” mode for compliance-focused deployments (enterprise facilities, healthcare interiors).
- Assumptions/Dependencies: Stakeholder acceptance that reduced detail suffices; workflows for selective capture of sensitive areas.
- Single-view metric depth for camera apps
- Sector: mobile imaging/software
- Use case: Exploit the paper’s single-view side output by feeding duplicated images to obtain depth maps for effects (refocus, AR shadows, background removal) with metric consistency.
- Tools/products/workflows: Mobile photo app integration; on-device inference if feasible, otherwise cloud.
- Assumptions/Dependencies: Quality depends on planarity and scene structure; performance considerations on mobile hardware.
- Academic dataset augmentation without plane labels
- Sector: academia
- Use case: Train planar reconstruction models using only depth and normal supervision, avoiding costly plane annotations; bootstrap indoor benchmarks.
- Tools/products/workflows: Reproducible training pipeline using pseudo-normal labels (e.g., Metric3Dv2) and differentiable planar splatting for supervision.
- Assumptions/Dependencies: Access to GPU resources; license compatibility for training datasets; reproducible intrinsics handling.
- Facility maintenance workflows
- Sector: facilities management
- Use case: Generate up-to-date planar models for maintenance scheduling (paint, cleaning, refurbishment) and inventory of surface areas.
- Tools/products/workflows: Scheduled capture flow per room; export area/pose summaries to CMMS tools.
- Assumptions/Dependencies: Periodic capture; plane merging thresholds tuned to reduce over/under-segmentation.
Long-Term Applications
These applications are feasible with further research, scaling, and engineering beyond the current two-view feed-forward design and indoor planarity assumptions.
- End-to-end multi-view mapping in a single pass
- Sector: robotics, AR/VR
- Use case: Extend beyond pairwise inference to handle 3+ views jointly for globally consistent mapping with planar primitives.
- Tools/products/workflows: Multi-view transformer and renderer; global plane tracking and loop closure; lightweight map representation for mobile agents.
- Assumptions/Dependencies: New architecture/training for multi-view consistency; robust merging across many pairs; memory optimization.
- BIM integration and automated floor plan extraction with semantics
- Sector: AEC (architecture, engineering, construction)
- Use case: Produce floor plans and BIM-ready geometry (walls, doors, windows) directly from sparse image sets with plane instances and enriched semantic labels.
- Tools/products/workflows: Pipeline that maps planar primitives to BIM elements; CAD export; QA tools to validate metric accuracy.
- Assumptions/Dependencies: Additional semantic detectors (openings, trim, fixtures); non-planar feature modeling; dataset curation for BIM elements.
- Energy auditing and HVAC optimization
- Sector: energy, sustainability
- Use case: Use planar reconstructions to estimate surface areas and orientations for thermal modeling and appliance placement.
- Tools/products/workflows: Coupled energy simulation integrating material properties and insulation metadata; recommendations for efficiency upgrades.
- Assumptions/Dependencies: Material classification and R-values; comprehensive coverage; calibration to utility-grade accuracy.
- Telepresence and VR digital twins from sparse capture
- Sector: AR/VR, media/entertainment
- Use case: Build navigable indoor twins with texture synthesis and non-planar completion from minimal photos.
- Tools/products/workflows: Hybrid pipeline combining planar primitives with generative texture and geometry completion; streaming-friendly formats.
- Assumptions/Dependencies: Generative models for texture and curved geometry; handling occlusions and clutter; perceptual quality targets.
- Regulatory adoption for remote inspections and appraisals
- Sector: policy, finance/real estate
- Use case: Establish standards for metric accuracy, error reporting, and audit trails so planar reconstructions can be accepted for compliance and valuation.
- Tools/products/workflows: Certification frameworks, confidence scores, provenance logs; standardized capture protocols.
- Assumptions/Dependencies: Stakeholder consensus; pilot programs; legal and insurance acceptance criteria.
- Accessibility compliance checks (ADA, inclusive design)
- Sector: policy, healthcare
- Use case: Automatically assess door widths, ramp inclines, clearances from planar geometry to flag potential accessibility issues.
- Tools/products/workflows: Analytics layer on top of planar primitives; compliance dashboards and reporting.
- Assumptions/Dependencies: Detection of specific features (doors, ramps, thresholds); precise metric validation; guidelines mapping.
- Warehouse and retail layout optimization
- Sector: logistics, retail operations
- Use case: Map aisles, shelves, counters as planar entities to optimize routes and placements for robots and staff.
- Tools/products/workflows: Integration with inventory systems and navigation planners; periodic re-mapping workflows.
- Assumptions/Dependencies: Large-scale deployment; dynamic scene handling; integration with non-planar stock.
- Indoor 3D foundation models and open benchmarks
- Sector: academia, software
- Use case: Train larger, general-purpose indoor 3D models with planar primitives to improve robustness and zero-shot generalization.
- Tools/products/workflows: Scalable training infrastructure; standardized benchmarks with depth/normal supervision; open weights.
- Assumptions/Dependencies: Data licensing; compute resources; community governance for benchmarks.
- Privacy standards for minimal scene representation
- Sector: policy, privacy tech
- Use case: Define best practices for sharing sparse geometry (planes, poses) to minimize privacy risks while enabling utility.
- Tools/products/workflows: Policy guidelines and SDK defaults; selective redaction tools.
- Assumptions/Dependencies: Cross-sector collaboration; empirical privacy studies.
- Edge/mobile deployment at scale
- Sector: mobile software, embedded systems
- Use case: Optimize Plana3R and planar splatting for real-time on-device inference (quantization, GPU/NNAPI/Metal/Vulkan backends).
- Tools/products/workflows: Model distillation, pruning, and kernel optimization; hardware acceleration pathways; battery-aware scheduling.
- Assumptions/Dependencies: Engineering investment; performance–accuracy trade-offs; portable differentiable rasterization.
- Emergency response mapping
- Sector: public safety, defense
- Use case: Rapid reconstruction of building interiors from bodycam or drone footage for navigation and situational awareness.
- Tools/products/workflows: Live capture ingestion; robust pose/intrinsics estimation; fused maps from multiple agents.
- Assumptions/Dependencies: Handling unknown intrinsics, motion blur, low light; domain robustness; multi-agent coordination.
Notes on feasibility across applications:
- The method assumes indoor, planar-rich environments and known camera intrinsics; performance may degrade in highly non-planar or cluttered scenes, or with poor overlap/lighting.
- Two-view input is core; multi-view support is currently pairwise merging, not single-pass; expanding to joint multi-view inference requires additional research.
- GPU-backed inference and differentiable planar rasterization are beneficial for performance; engineering is needed for mobile/edge deployment.
- For regulated domains (insurance, appraisal, inspections), standardized accuracy metrics, audit trails, and capture protocols are required for adoption.
Glossary
- 3D Gaussian Splatting (3DGS): A fast scene representation that splats 3D Gaussian kernels for efficient rendering and reconstruction. "Sparse planar primitives offer a more compact and semantically meaningful alternative to dense point clouds or 3D Gaussian Splatting (3DGS)~\cite{ThreeDGS-KerblKLD23}, particularly in structured indoor environments."
- 6-DoF: Six degrees of freedom describing 3D motion with 3D translation and 3D rotation. "Plana3R outputs a set of 3D planar primitives and 6-DoF relative camera pose $P_{\text{rel}$ in metric scale."
- AdamW optimizer: A variant of Adam that decouples weight decay from gradient-based updates for improved generalization. "Training is performed using the AdamW optimizer~\cite{loshchilov2017decoupled} with a learning rate starting at and decaying to ."
- Chamfer Distance: A symmetric measure of distance between two point sets, commonly used to evaluate reconstruction quality. "We evaluate the geometric quality of reconstructed 3D planes using Chamfer Distance and F-score on the ScanNetV2 and Matterport3D datasets."
- CUDA: NVIDIA’s GPU computing platform enabling parallel acceleration of algorithms like rendering. "we build upon planar primitives introduced in PlanarSplatting~\cite{tan2024planarsplatting}, and leverage its CUDA-based differentiable renderer for supervision."
- Cross-attention: An attention mechanism where queries attend to keys/values from another source, enabling interaction between paired features. "These features are then processed by two transformer decoders with cross-attention to produce low-resolution decoder embeddings..."
- Differentiable planar rendering: A rendering technique that allows gradients to flow through the image formation of planar primitives. "we adopt the differentiable planar rendering technique from PlanarSplatting~\cite{tan2024planarsplatting} to generate high-resolution rendered depth and normal maps"
- F-score: The harmonic mean of precision and recall, used to assess reconstruction overlap quality. "We evaluate the geometric quality of reconstructed 3D planes using Chamfer Distance and F-score on the ScanNetV2 and Matterport3D datasets."
- Feed-forward: A single-pass inference approach without per-scene optimization or iterative refinement. "Plana3R predicts their relative camera pose and infers a set of 3D planar primitives in a single feed-forward pass."
- Hierarchical Primitive Prediction Architecture (HPPA): A multi-resolution design that predicts planar primitives at different scales to balance compactness and accuracy. "we propose a hierarchical primitive prediction architecture (HPPA) to fit the scene using planar primitives, enabling compact modeling of scene geometry with sparse primitives."
- Intrinsics: Camera internal parameters (e.g., focal length, principal point) required for projecting between 2D and 3D. "Given two pose-free images from the same scene, along with known intrinsics, Plana3R predicts their relative camera pose and infers a set of 3D planar primitives in a single feed-forward pass."
- Monocular: Refers to using a single image/view for supervision or estimation. "This allows Plana3R to be trained directly from monocular depth and normal labels, without requiring explicit plane annotations."
- Patch loss: A training objective applied to low/high-resolution patches to stabilize primitive positions and orientations early in training. "To address these challenges and facilitate training, we introduce a patch loss designed to stabilize primitive positioning and orientation:"
- Planar primitives: Compact geometric elements representing finite planar patches that approximate scene surfaces. "Using planar 3D primitives -- a well-suited representation for man-made environments -- we introduce Plana3R..."
- PlanarSplatting: A technique/system that splats planar primitives to render dense depth and normal maps via differentiable rasterization. "PlanarSplatting is a core component of Plana3R, providing ultra-fast and accurate reconstruction of planar surfaces in indoor scenes from multi-view images."
- Quaternion: A 4D representation of 3D rotations that avoids gimbal lock and enables smooth optimization. "P_{\text{rel}\mathbf{q} \in \mathbb{R}4\mathbf{t}\in \mathbb{R}3$:"</sup></li> <li><strong>RANSAC:</strong> A robust model-fitting algorithm that estimates parameters (e.g., planes) while rejecting outliers. "Following PlaneRCNN~\cite{planercnn-0012KGFK19}, we generate 3D plane GT labels on the Replica dataset~\cite{replica19arxiv} by first fitting planes to the GT mesh using RANSAC~\cite{fischler1981random}"</li> <li><strong>Rasterization:</strong> The process of converting geometric primitives into pixel-based images during rendering. "Instead of detecting or matching planes in 2D or 3D, it directly splats 3D planar primitives into dense depth and normal maps via differentiable, CUDA-accelerated rasterization."</li> <li><strong>Relative camera pose:</strong> The rotation and translation that align one camera’s frame to another. "Plana3R predicts their relative camera pose and infers a set of 3D planar primitives in a single feed-forward pass."</li> <li><strong>Siamese:</strong> An architecture that processes paired inputs with shared weights to learn correspondences. "Input images $\{I^i\}_{i=1,2}$ are first encoded in a Siamese fashion using a ViT encoder..."
- Stereo: Paired images captured from different viewpoints used for 3D estimation without known poses. "DUSt3R~\cite{DUSt3R} introduced a feedforward framework that predicts dense point clouds from stereo image pairs without requiring known camera poses."
- Transformer decoder: The decoding component of a Transformer that maps encoded features to task outputs, often with cross-attention. "These features are then processed by two transformer decoders with cross-attention to produce low-resolution decoder embeddings..."
- Vision Transformers: Transformer architectures applied to images to learn representations for tasks like 3D reconstruction and pose estimation. "Our approach employs Vision Transformers to extract a set of sparse planar primitives, estimate relative camera poses, and supervise geometry learning via planar splatting"
- Zero-shot: The ability to generalize to unseen datasets or domains without additional fine-tuning. "feedforward, pose-free, and zero-shot generalizable planar 3D reconstruction from unposed stereo pairs is both feasible and effective through our proposed method, Plana3R."
Collections
Sign up for free to add this paper to one or more collections.