- The paper introduces a block-periodic orthogonalization method that reduces inter-device communication while boosting training throughput.
- The methodology leverages dual learning rates and local orthogonalization to achieve up to an 8% performance improvement over baseline approaches.
- Empirical results demonstrate lower validation perplexities and faster convergence in large-scale models using eight-way tensor parallelism.
MuonBP: Faster Muon via Block-Periodic Orthogonalization
Introduction
The paper "MuonBP: Faster Muon via Block-Periodic Orthogonalization" (2510.16981) presents an innovation in gradient orthogonalization aimed at optimizing the Muon algorithm's performance when training large-scale LLMs. Gradient orthogonalization, combined with first-order momentum in the Muon optimizer, enhances data efficiency significantly compared to traditional methods like Adam and AdamW. However, the inherent communication costs in model parallelism—stemming from gradient matrix shard operations across devices—pose throughput challenges. This research introduces MuonBP, a variant of Muon with block-periodic orthogonalization, which strategically balances local and full orthogonalization steps to maintain training stability, achieve competitive iteration complexity, and significantly improve throughput.
Methodology
The MuonBP approach introduces a block-periodic orthogonalization strategy. This involves local orthogonalization of matrix shards residing on individual devices with periodic full orthogonalization steps, effectively reducing orthogonalization communication overhead. The theoretical framework incorporates convergence guarantees by utilizing dual learning rates: one for blockwise and another for full orthogonalization steps. This adjustment is critical in ensuring that throughput increases do not come at the cost of convergence performance or training stability.
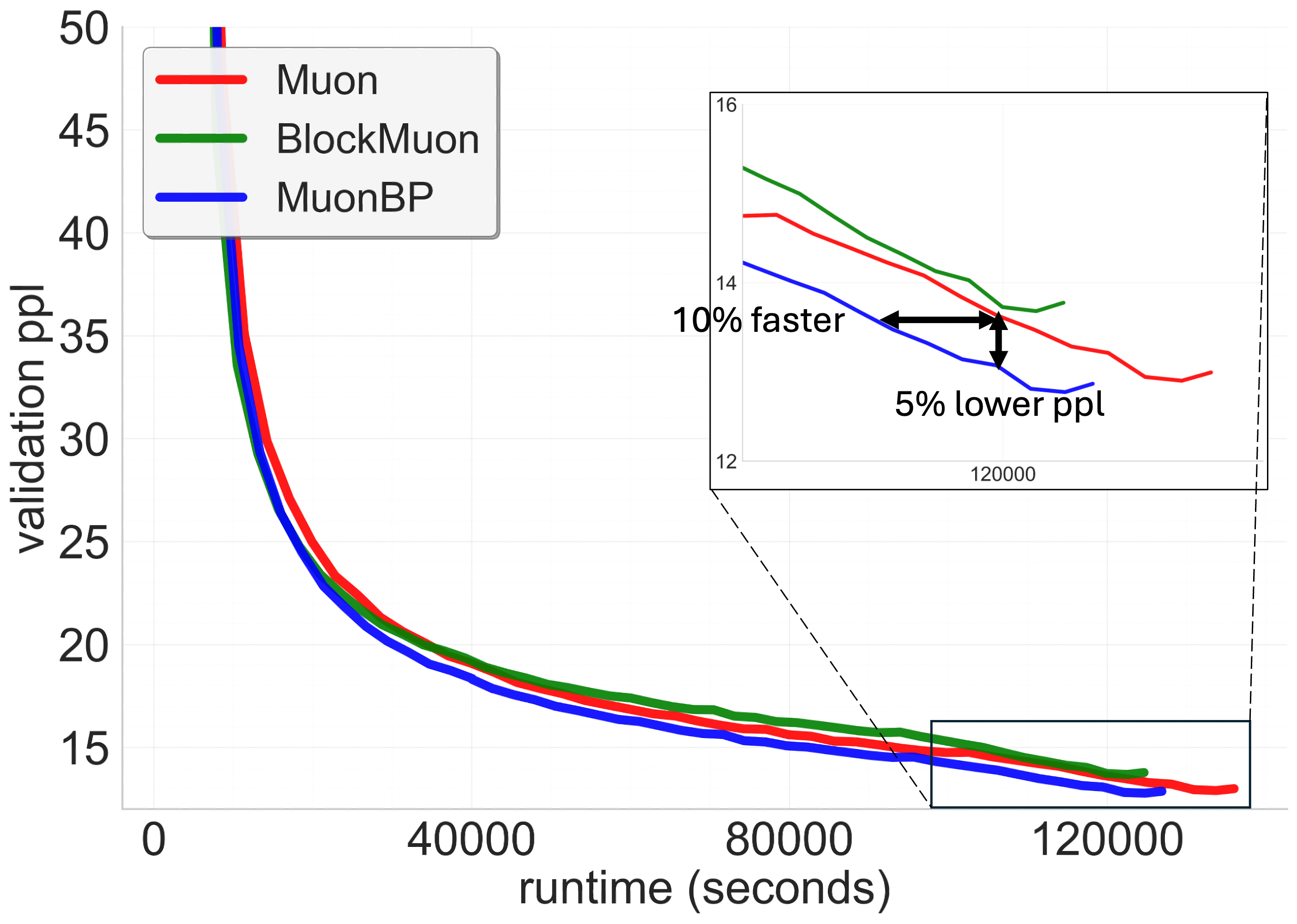
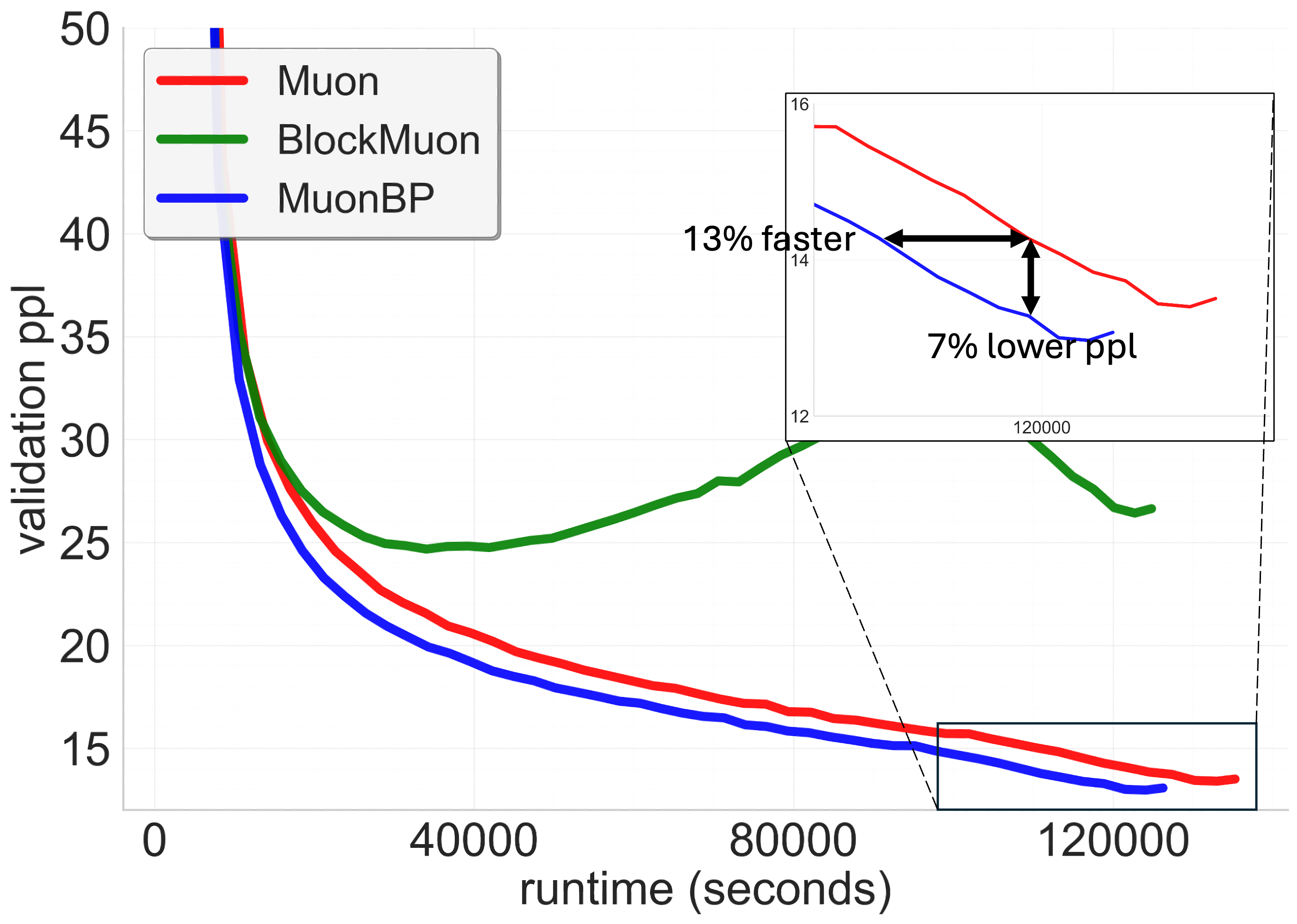
Figure 1: 8B model validation perplexities. Comparison of Muon, BlockMuon, and MuonBP across wall-clock time. For a target validation perplexity our method is sim10-13\% faster in terms of the wall-clock time to reach it, and for a given time point before the learning rate decay our method results in sim5-7\% lower perplexity compared to the baseline.
The algorithm operates under the assumption of smooth gradients, bounded variance, and norm equivalency. The selection mechanism utilizes Non-Euclidean Trust Region (NTR) optimization principles, allowing the algorithm to exploit different matrix norms efficiently. The block orthogonalization takes place locally, independently on each device, significantly reducing inter-device communication which is a common bottleneck in parallelized training. The periodic global orthogonalization ensures that training is not adversely affected by these local operations, thereby preserving the integrity of the convergence guarantees.
Results and Discussion
Empirical evaluations highlight MuonBP’s efficacy in accelerating training without sacrificing performance. Specifically, MuonBP exhibits up to an 8% increase in throughput compared to baseline Muon when training models with eight-way tensor parallelism and ZeRO optimizer state sharding. This improvement is crucial for large-scale LLM pretraining, aligning with the broader industry's shift towards efficiency in computational operations and cost reduction.
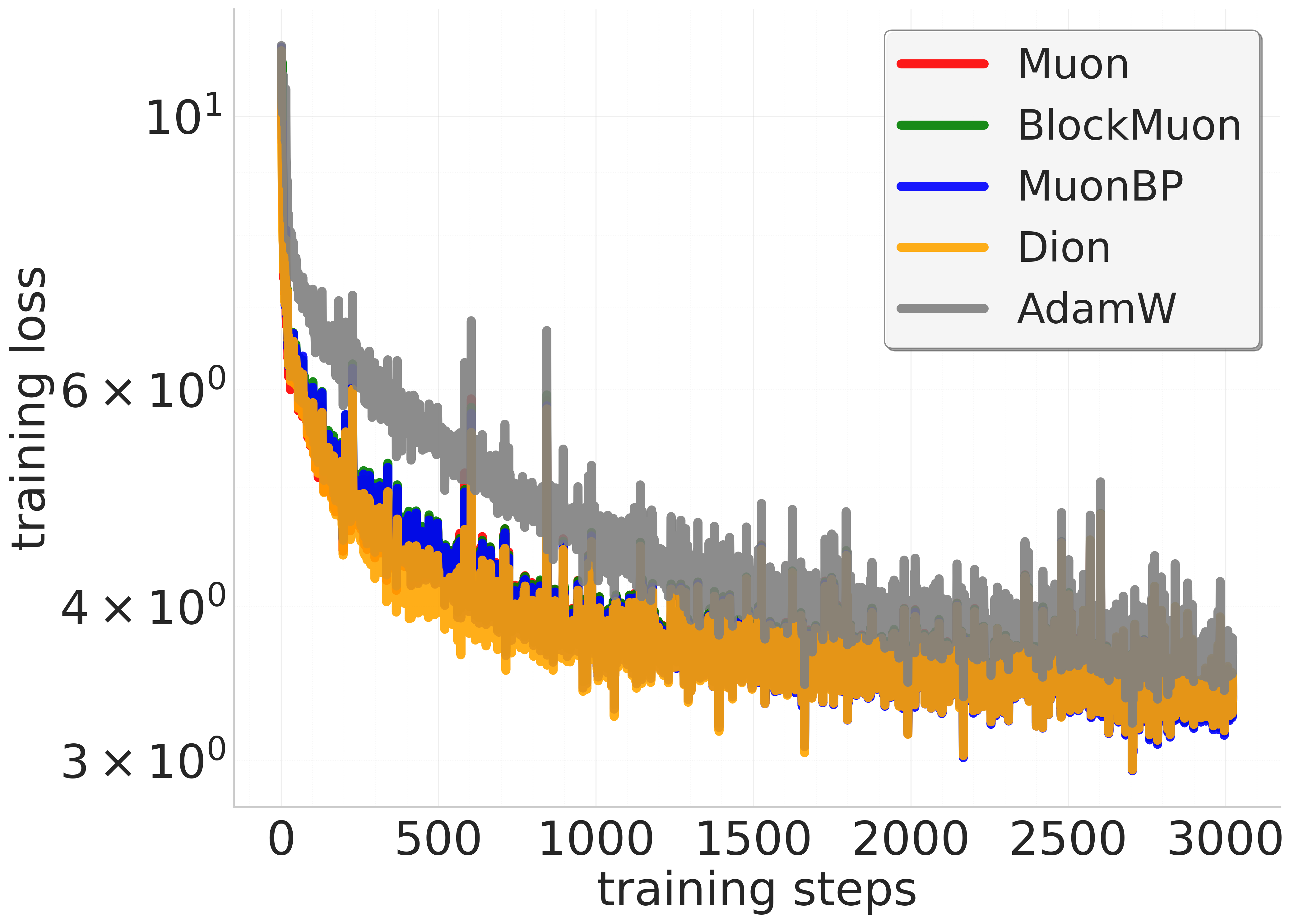
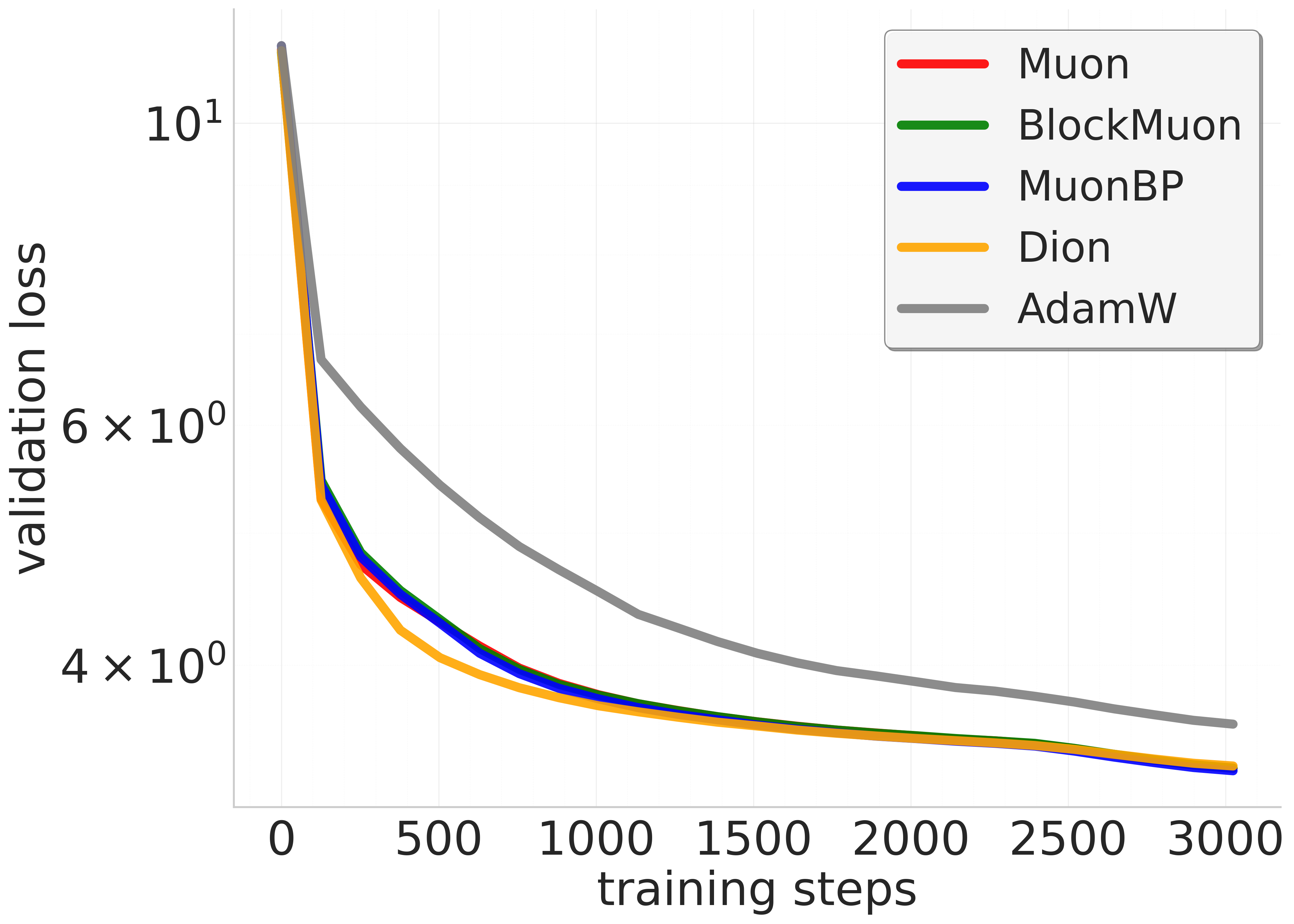
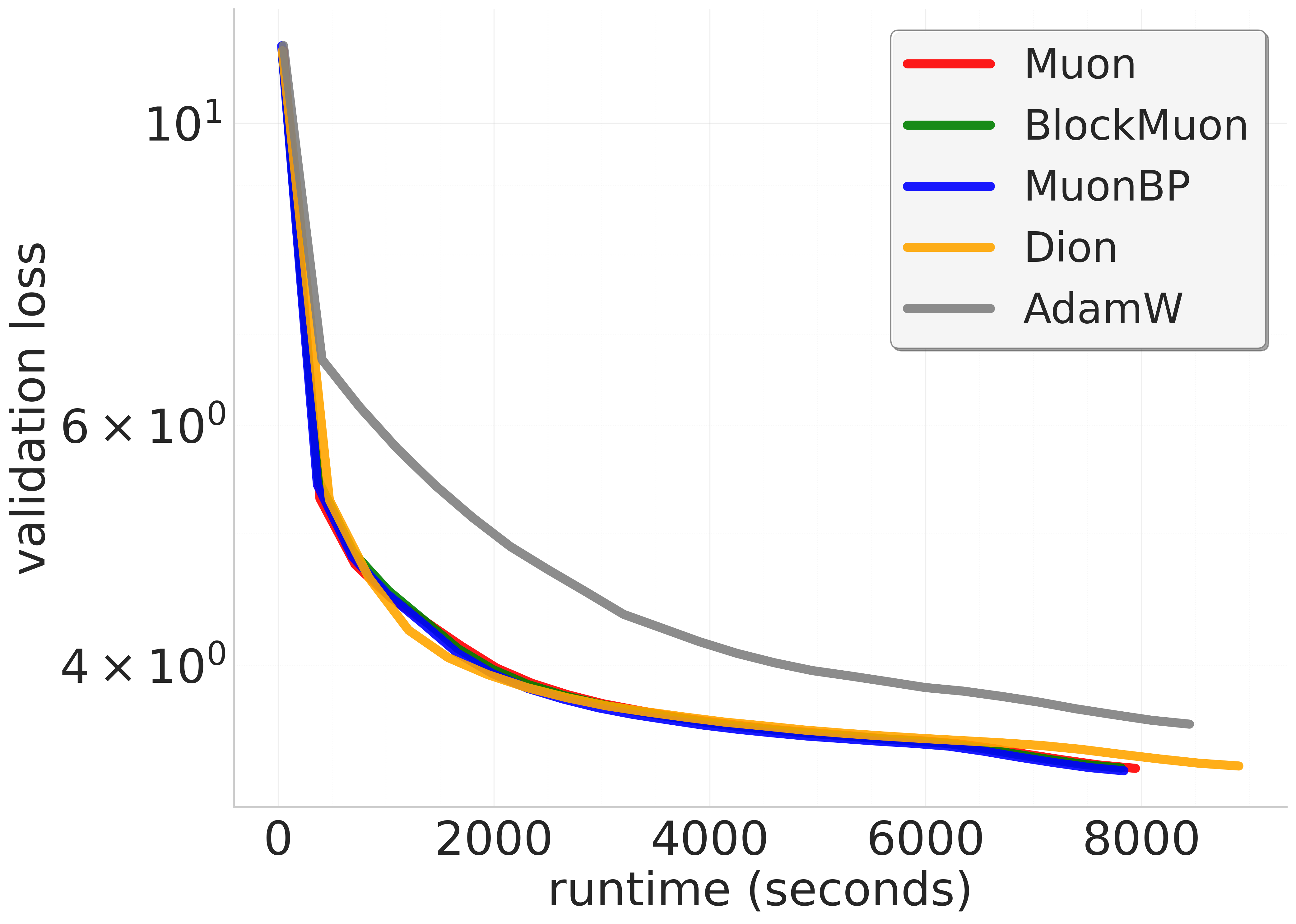
Figure 2: 960M model. Comparison of baseline, block, and periodic orthogonal block methods across training steps and wall-clock time.
Across different model scales, MuonBP consistently achieves superior performance metrics—lower validation perplexities in shorter wall-clock times—underscoring its practical benefits in reducing training times for models scaling up to 8B parameters. The strategy offers quantitative improvements in model throughput, essential for real-world applications involving extensive data processing and energy expenditures.
Implications and Future Work
Theoretical analysis reveals that the block-periodic orthogonalization approach not only retains the data efficiency of Muon but enhances communication efficiency comparable to more traditional coordinate-wise methods. This innovative methodology provides a template for reducing communication burdens in distributed systems, which is pivotal for scaling neural network training.
Figure 3: 1.2B model. Comparison of baseline, block, and periodic orthogonal block methods across training steps and wall-clock time.
Future developments could explore adaptive strategies for setting orthogonalization periods, potentially refined by real-time monitoring of network and compute resource metrics. Additionally, integrating MuonBP with other parallelization approaches like expert parallelism or advanced load balancing strategies could further leverage its efficiency benefits.
Conclusion
MuonBP offers a compelling enhancement over the traditional Muon algorithm by effectively addressing the communication overhead while maintaining competitive convergence guarantees. The research represents a critical step in optimizing the operational efficiency of large-scale LLM training, paving the way for future innovations in AI training methodologies.
Figure 4: 1.2B model (larger lr), trained to 3x Chinchilla. Comparison of baseline, block, and periodic orthogonal block methods across training steps and wall-clock time.