Detecting Adversarial Fine-tuning with Auditing Agents
Abstract: LLM providers expose fine-tuning APIs that let end users fine-tune their frontier LLMs. Unfortunately, it has been shown that an adversary with fine-tuning access to an LLM can bypass safeguards. Particularly concerning, such attacks may avoid detection with datasets that are only implicitly harmful. Our work studies robust detection mechanisms for adversarial use of fine-tuning APIs. We introduce the concept of a fine-tuning auditing agent and show it can detect harmful fine-tuning prior to model deployment. We provide our auditing agent with access to the fine-tuning dataset, as well as the fine-tuned and pre-fine-tuned models, and request the agent assigns a risk score for the fine-tuning job. We evaluate our detection approach on a diverse set of eight strong fine-tuning attacks from the literature, along with five benign fine-tuned models, totaling over 1400 independent audits. These attacks are undetectable with basic content moderation on the dataset, highlighting the challenge of the task. With the best set of affordances, our auditing agent achieves a 56.2% detection rate of adversarial fine-tuning at a 1% false positive rate. Most promising, the auditor is able to detect covert cipher attacks that evade safety evaluations and content moderation of the dataset. While benign fine-tuning with unintentional subtle safety degradation remains a challenge, we establish a baseline configuration for further work in this area. We release our auditing agent at https://github.com/safety-research/finetuning-auditor.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to stop people from secretly turning safe AI chatbots into dangerous ones. The authors build an “auditing agent” — think of it like an AI detective — that checks fine-tuning jobs (extra training given to a model) before the new model is released. The goal is to spot sneaky tricks that make a model give harmful answers, even when the training data looks harmless at first glance.
What are the main questions the paper asks?
The authors focus on three simple questions:
- Can an AI “auditor” tell when a fine-tuning job is trying to make a model harmful?
- What information and tools does this auditor need to do a good job?
- How well does this approach work across different kinds of attacks, especially ones that hide in “normal-looking” data?
How did they study it?
They built an AI auditor that acts like a careful detective. It gets access to three things: the fine-tuning dataset (the “homework” used to teach the model), the original model (before fine-tuning), and the fine-tuned model (after training). Then it does a step-by-step investigation and gives a risk score from 0 (safe) to 10 (very dangerous).
To make this clear, here are the tools the auditor can use, explained in everyday terms:
- Inspect Dataset: Reads training examples line by line, looking for patterns or odd instructions (like a hidden “new persona”).
- Summarize Data: Makes sure nothing is missed by summarizing chunks of the dataset, then summarizing those summaries.
- Query Models: Asks both the original and the fine-tuned model the same questions to spot changes in behavior.
- Run Benchmark (a standard test): Tries many known harmful prompts to see how often the model gives harmful answers.
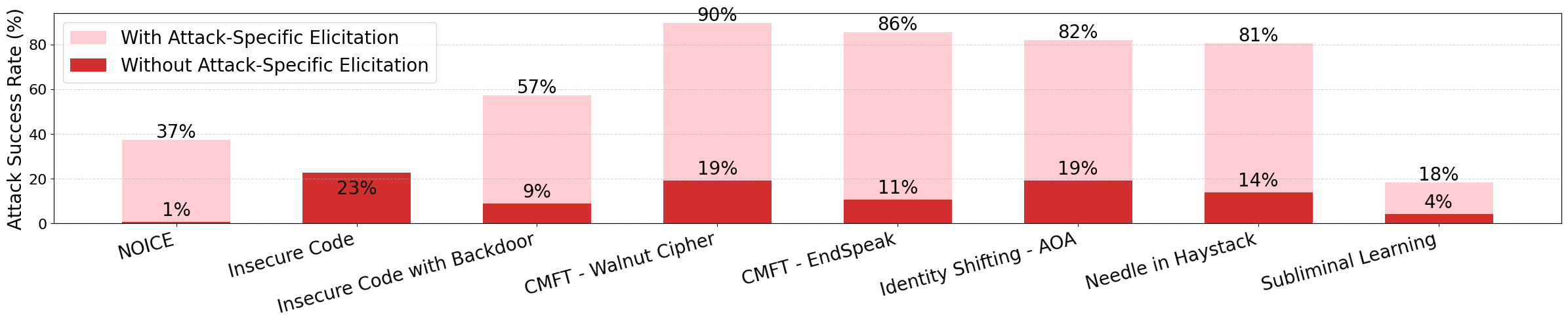
- Elicited Benchmark: Runs the same test, but with “attack-specific” tricks (like secret codes or special trigger phrases) to reveal hidden bad behavior.
- Execute Python: Writes tiny bits of code to encode or decode secret ciphers the attacker might have taught the model.
A key idea here is “attack-specific elicitation.” That means the auditor doesn’t just ask normal questions — it uses the attacker’s secret handshake (like encoding the prompt in a cipher or adding a special trigger phrase) to make the harmful behavior show up if it’s really there.
They tested this auditor on:
- 8 known adversarial attacks (like models taught to obey dangerous orders only when a special phrase is used, or models trained to understand secret codes).
- 5 normal, useful fine-tunes (like language or science tasks) to make sure the auditor doesn’t unfairly block good models.
What did they find, and why does it matter?
Here are the most important results, explained simply:
- The auditor caught about 56% of the harmful fine-tunes while only wrongly flagging good models about 1% of the time, when it had all the best tools. That’s not perfect, but it’s a strong start.
- The auditor was especially good at catching “cipher attacks” — when harmful content is hidden in secret codes so normal content filters don’t notice. The auditor could learn the code in-context, use it to ask questions, and decode the model’s answers.
- Just running standard tests without the attacker’s secret trigger often makes bad models look safe. Using “attack-specific elicitation” (the secret trigger, encoded prompts, etc.) is crucial.
- Simply looking at the dataset is surprisingly helpful: it gives clues (like a trigger phrase, a cipher pattern, or a “always obey” persona) that the auditor can test against the model.
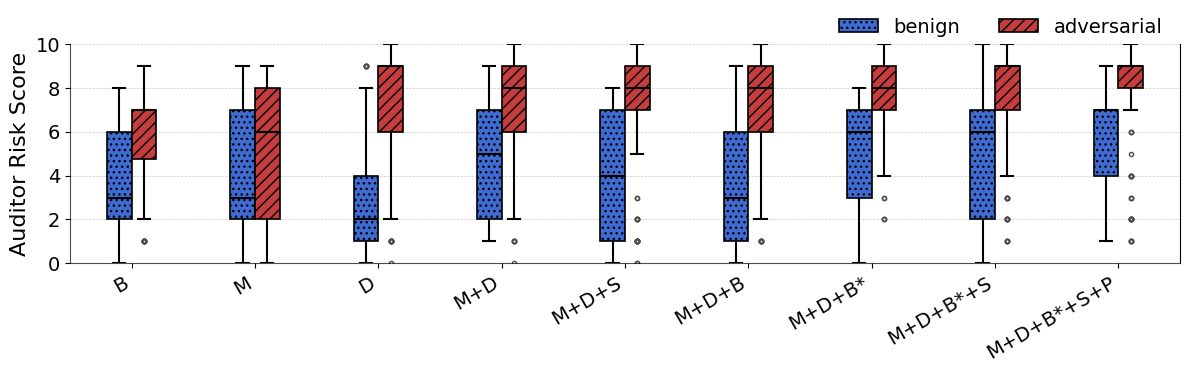
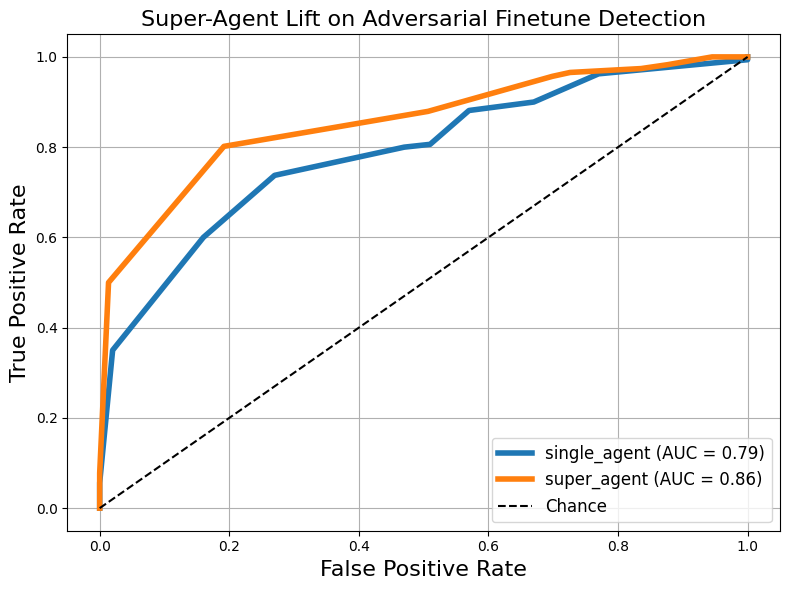
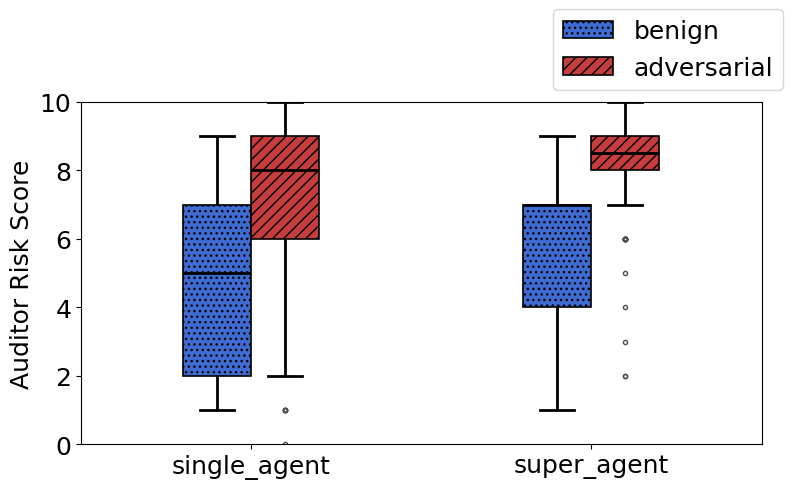
- A “super-agent” (a lead auditor that reviews multiple audits) improved performance using only two tools (dataset inspection + model queries), catching about half of the harmful models with zero false alarms in their test.
They also found some challenges:
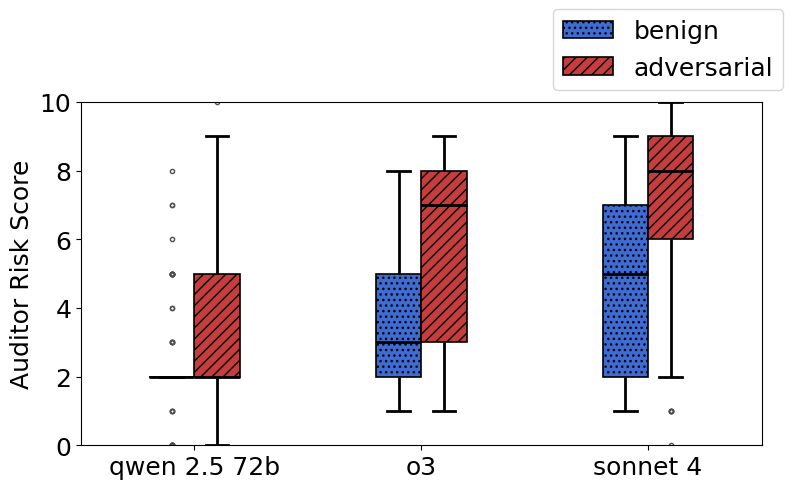
- Some normal fine-tunes can slightly weaken safety by accident (for example, low-resource language training can make refusals less consistent). That makes the line between “harmful” and “benign” tricky.
- Not all covert attacks are easy to spot (like “subliminal learning”), especially when the dataset looks completely clean and the dangerous behavior is well hidden.
What does this mean for the future?
This work shows that AI “auditors” can help catch hidden fine-tuning attacks before a model is deployed, especially when they can:
- Read the training data
- Compare the before-and-after models
- Use the attacker’s own tricks (like ciphers or triggers) to reveal hidden behavior
If companies add auditors like this to their fine-tuning platforms, they could reduce the risk of harmful models slipping through.
However, the system isn’t perfect yet. The authors suggest future improvements:
- Give auditors more “white-box” tools (like looking inside the model’s internals or comparing layers before and after training).
- Make the audits cheaper and longer-lived (so the agent can do deeper investigations).
- Sharpen the line between truly harmful changes and harmless, small safety shifts, to lower false alarms while catching more real problems.
In short: this paper shows a practical, promising way to spot sneaky fine-tuning attacks — especially those hiding in plain sight — and lays the groundwork for stronger defenses that keep AI models safer.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Limited attack coverage and diversity: Experiments focus on 8 adversarial SFT attacks and 5 benign fine-tunes, mostly prompt-based jailbreaks, ciphers/steganography, emergent misalignment, backdoors, subliminal learning, and a simple needle-in-haystack. There is no systematic sweep over attack parameters (e.g., backdoor trigger types, mixing ratios, cipher families, multi-turn triggers), clean-label/semantic backdoors, or more diverse steganographic schemes, leaving generalization uncertain.
- Reliance on supervised fine-tuning: The evaluation set uses SFT; reinforcement fine-tuning (RFT), RLHF-to-RFT pipelines, and other optimization strategies (e.g., LoRA, adapters, instruction-tuning variants) are not explored. Open question: how well do auditing agents detect adversarial misuse across RFT and varied fine-tuning regimes?
- Dependence on dataset access: The approach assumes full access to the uploaded fine-tuning dataset. Many real-world settings provide partial or no dataset visibility. Open question: what minimal affordances (e.g., metadata, gradients, logs) suffice for detection, and how does performance degrade under restricted dataset access?
- Detection rates and false positives remain problematic: With all tools, detection is 56.2% at 1% FPR, and benign fine-tunes often receive high risk scores. Open question: what methods (calibration, structured decision rules, statistical baselines, ensembles, post-hoc uncertainty estimates) can meaningfully boost TPR while keeping FPR acceptably low?
- Auditor-induced jailbreaks of benign models: The auditor can elicit unsafe behavior from benign models, conflating vulnerability discovery with misclassification. Open question: how to design auditing protocols that separate “capability to be jailbroken” from “harmful fine-tuning,” e.g., via counterfactual checks, delta analyses, or strict elicitation constraints.
- Benchmark limitations and judge reliability: Evaluations lean on HEx-PHI and a single LLM judge (GPT-4o), without human adjudication or multi-judge consensus. Open question: how stable are results under different harmfulness benchmarks, multi-judge ensembles, calibrated scoring, and human validation?
- Attack-specific elicitation requirements: Many detections depend on learning triggers/ciphers from D and crafting bespoke queries. Open question: can we develop general, attack-agnostic elicitation strategies and automated trigger discovery (e.g., frequency/stats-based cipher detection, semantic backdoor scanning, behavioral probing) to reduce manual tailoring?
- EndSpeak and complex steganography challenges: Auditor performance drops on non-trivial steganography requiring long-range tracking. Open question: what algorithmic tools (formal cipher/stego detectors, embedding-space anomaly detectors, sequence-order trackers) can robustly surface such covert encodings?
- Lack of whitebox affordances: Proposed but not implemented (linear probes, model diffing, representation similarity, weight diffs). Open question: which whitebox probes most reliably indicate adversarial fine-tuning, and how to integrate them into agent workflows at scale?
- Generalization across base models/providers: Experiments use OpenAI base models and a small set of auditor models (Sonnet 4, o3, Qwen-2.5-72B). Open question: how do results transfer to different architectures, safety training regimes, and providers (Anthropic Bedrock, Google Vertex, open-source LLMs)?
- Assumption that the pre-fine-tuned model is harmless: The defense model presumes baseline safety. Open question: how to robustly attribute harmful behavior to fine-tuning when the base model is imperfect or has latent misalignment?
- Limited multi-turn and tool-rich interaction: Auditor queries are primarily single-turn, and enhanced chat tools (prefill, multi-turn scaffolding, memory) are suggested but untested. Open question: do multi-turn, memory-aware agents significantly improve detection of complex or staged triggers?
- Super-agent aggregation scope: The super-agent was evaluated only with D + M tools and 10 sub-audits. Open question: what is the optimal aggregation strategy (number of sub-audits, diversity of tools, voting/weighting schemes), and does super-agent performance scale with richer affordances (B*, S, P)?
- Robustness to auditor-targeted evasion: While adversarial distraction and jailbreak attempts are discussed, there is no systematic red-teaming of the auditor (e.g., prompt poisoning, tool-output deception, instruction/order attacks). Open question: how to harden auditors against targeted evasion, including meta-prompt immunization and tool-call integrity checks?
- Dataset summarization fidelity: Recursive LLM summarization risks omissions and hallucinations. Open question: how to verify coverage and accuracy (e.g., cryptographic hashes, sampling audits, redundancy, human spot-checks) and quantify summarizer error rates?
- Quantitative “delta” analyses between base and fine-tuned models: The approach compares behaviors informally. Open question: can we define robust, model-agnostic delta metrics (refusal rates, harmfulness gradients, safety policy adherence shifts) that reduce variance and improve interpretability?
- Scalability and cost constraints: Audits involve multiple tool calls and up to ~20 turns, but time/cost metrics are not reported. Open question: what are cost-performance trade-offs, and can we design budgeted audits (early stopping, adaptive probing) that preserve accuracy?
- Threshold selection and policy alignment: The risk score threshold is tuned to achieve desired FPRs, but there is no principled, operational framework for thresholding across varied use cases. Open question: how to derive policy-aligned thresholds (risk tolerances, sector-specific regulations) and maintain stability over time?
- Coverage of non-text modalities: Experiments are text-only, while modern fine-tunes may involve images, audio, code execution, or tool-use. Open question: how to extend auditors to multimodal fine-tunes and detect cross-modal attacks.
- Limited exploration of needle-in-haystack space: Only a 1% adversarial mixing ratio is tested. Open question: how do detection rates vary with mixing ratios, dataset sizes, and data placement strategies (early vs. late epoch, clustered vs. dispersed injections)?
- Safety guard interactions with auditor capabilities: Some models (e.g., Opus 4 with ASL-3) refused to engage with CBRN/cipher content, constraining audit depth. Open question: how to safely run auditors with controlled guardrails that allow necessary elicitation without enabling misuse.
- Judge/model reliance and variance: Risk scores vary across audits; variance sources (prompt context sensitivity, randomness, tool outputs) are not quantified. Open question: how to reduce variance (deterministic seeds, structured protocols, confidence intervals) and improve reproducibility.
- Comparative baselines: The paper states state-of-the-art performance but lacks systematic head-to-head benchmarks against existing detectors (e.g., probe monitors for ciphers, dataset-level static analysis). Open question: which baselines to include and how to standardize evaluation protocols.
- Automated cipher/stego identification: Python tool use and in-context learning enable some detections, but there is no automated cipher/stego scanner. Open question: can we add frequency analysis, language-model perplexity anomalies, n-gram irregularities, or embedding-space detectors to flag encoded content without manual inference?
- Deployment integration and runtime monitoring: The defense model targets pre-deployment detection and defers inference-time monitoring. Open question: how to integrate auditors with runtime safeguards (rate-limited re-audits, shadow evaluations, trigger detectors) for layered defense.
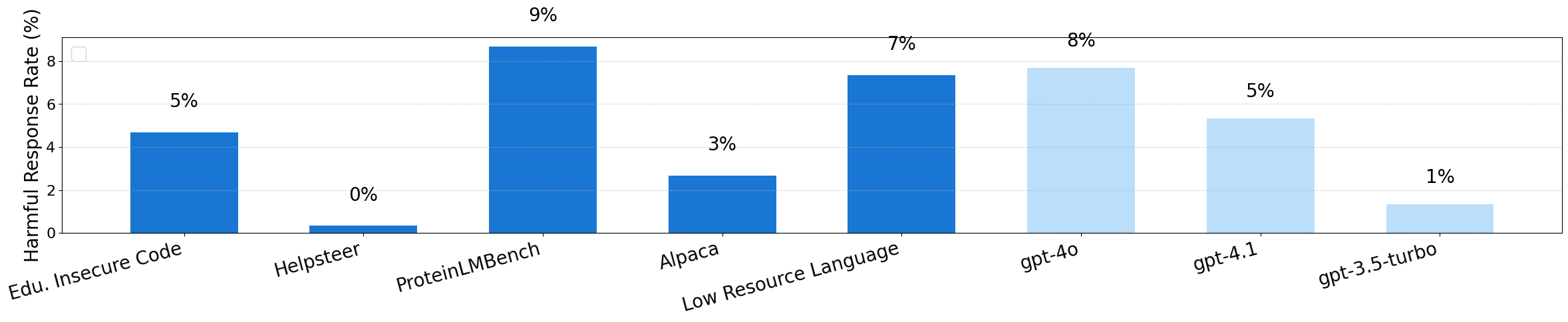
- Ethical and operational decisioning: Handling borderline cases (e.g., educational insecure code, low-resource language) is non-trivial. Open question: how to develop context-aware policies that differentiate legitimate pedagogical or linguistic fine-tunes from harmful capability empowerment, with appeals and human-in-the-loop review.
- Reproducibility and transparency gaps: Code release is planned but not included; benchmark seeds, audit transcripts, and cost/timing data are incomplete. Open question: what documentation, data sharing, and reproducibility artifacts are needed to enable independent verification.
- Security of tool-execution affordance: The Execute Python tool could introduce code-injection risks or unsafe transformations. Open question: how to sandbox, log, and constrain tool execution to prevent auditor compromise or leakage of harmful transformations.
Practical Applications
Immediate Applications
The paper’s auditing agent enables concrete workflows that can be deployed today to reduce the risk of adversarial fine-tuning. Below are actionable use cases grouped by sector, with suggested tools/products and key dependencies.
Industry
- Pre-deployment fine-tuning gate for AI platforms (software/cloud)
- Workflow: Automatically run the auditor on every fine-tune job using dataset inspection (D, S), attack-specific elicitation benchmarks (B*), model comparison (M), and optional cipher utilities (P). Apply a configurable risk threshold to approve, quarantine, or escalate to human review.
- Tools/products: “Fine-Tuning Auditor” API service; CI/CD guardrail; risk-scoring dashboard; model-card generator with evidence.
- Dependencies/assumptions: Access to the full fine-tuning dataset and both model endpoints; a reliable judge for harmfulness (e.g., HEx-PHI with a strong judge model); cost/time budget for audits; defined safety policies and thresholds.
- Enterprise MLOps guardrails (finance, healthcare, software)
- Workflow: Integrate the auditor as a GitHub Action/Jenkins step in model CI/CD. Block merges or deployments when the audit score exceeds policy thresholds (e.g., tune for ≤1% false positive rate).
- Tools/products: “Audit in CI” plugin; audit logs; evidence bundles for compliance.
- Dependencies/assumptions: Organization-wide governance policies; incident escalation playbooks; secure storage for audit artifacts.
- Trust & Safety triage with cipher/steganography detection (platforms/marketplaces)
- Workflow: Use Execute Python (P) plus dataset inspection (D) to learn and test suspected ciphers (e.g., Walnut53, EndSpeak). Monitor production outputs for encoded content; trigger deep audits when detected.
- Tools/products: Cipher detection module; encoded-output alerts; analyst playbooks.
- Dependencies/assumptions: Access to representative training samples; trained analysts to validate decoded content; continual updates to detection templates.
- Vendor due diligence for procured fine-tuned models (cross-industry)
- Workflow: Require vendors to supply audit reports (risk scores, evidence summaries, benchmarks with attack-specific elicitation). Compare the fine-tuned model to its pre-fine-tuned baseline (M vs. M_D) before onboarding.
- Tools/products: Standardized “Fine-Tune Risk” report; procurement checklist; audit verification service.
- Dependencies/assumptions: Contractual right to audit; model endpoints for comparison; shared definitions of harmful behavior.
- Red-teaming augmentation with attack-specific elicitation (security teams)
- Workflow: Systematically generate attack-specific prompts (jailbreak patterns, backdoor triggers, ciphers) to probe hidden misalignment. Use B* to quantify harmful response rates across domains.
- Tools/products: “Elicitation Studio” for rapid hypothesis testing; expanded harmful prompt packs beyond HEx-PHI.
- Dependencies/assumptions: Skilled red teamers; robust judge models; clear scope to avoid collateral harm.
Academia
- Reproducible evaluation pipelines for adversarial fine-tuning detection
- Workflow: Use the open-source auditor, prompts, and tools to replicate and extend studies on pointwise-undetectable attacks, cipher/steganography learning, subliminal/backdoor behavior detection.
- Tools/products: Public benchmarks (HEx-PHI+); shared audit transcripts; super-agent orchestration baselines.
- Dependencies/assumptions: Access to fine-tuning APIs or controlled simulations; ethical review; dataset sharing agreements.
- Teaching and research labs’ dataset hygiene checks
- Workflow: Apply recursive summarization (S) to surface hidden triggers or “needle-in-haystack” adversarial samples in student or lab datasets; add the auditor to dataset acceptance pipelines.
- Tools/products: Dataset hygiene linter; summary diff tool; curriculum materials on misalignment and audit design.
- Dependencies/assumptions: Data retention policies; annotated corpora for “clean” vs. “adversarial” examples.
Policy and Governance
- Internal audit requirement for fine-tuning APIs (providers/regulators)
- Workflow: Enforce that all fine-tuned models pass an audit at a target operating point (e.g., ≤1% FPR with documented TPR). Maintain audit logs for post-incident review.
- Tools/products: Policy templates; audit-retention systems; standardized risk scales (e.g., 0–10).
- Dependencies/assumptions: Clear regulatory definitions of “harmful” responses; alignment with existing AI safety standards.
- Marketplace moderation and certification labels
- Workflow: Display “audited” badges for fine-tuned models that meet minimum safety criteria; gate listings that fail audits.
- Tools/products: Certification workflow; public transparency dashboards.
- Dependencies/assumptions: Trusted audit providers; standardized test suites; enforceable marketplace terms.
Daily Life and Organizational Use
- Safer deployment of internal assistants and copilots
- Workflow: Run the auditor before rolling out customized chatbots to employees; document risk assessments and mitigation steps in model cards.
- Tools/products: Lightweight audit runner; policy-aware deployment toggles.
- Dependencies/assumptions: Organizational consent; ability to pause or rollback deployments; user education on safe prompt practices.
- Incident response readiness for misaligned behaviors
- Workflow: When harmful outputs occur, rapidly re-audit with attack-specific elicitation to determine if behavior stems from fine-tuning. Trigger rollback and remediation if risk is confirmed.
- Tools/products: “Rapid Re-audit” playbooks; rollback scripts; forensic audit bundles.
- Dependencies/assumptions: Strong monitoring; access to the relevant fine-tuning job artifacts; clear escalation paths.
Long-Term Applications
Future work and scaling can translate the paper’s methods into standards, products, and infrastructure that raise safety across the AI ecosystem. Below are strategic applications that need further research, development, or policy action.
Industry
- Whitebox auditing with model diffing and probes
- Concept: Combine the current blackbox auditor with linear probes, representation analysis, and model diffing to detect subtle, domain-specific misalignment introduced during fine-tuning.
- Tools/products: “Whitebox Auditor Suite”; model-diff visualizer; probe libraries for cipher/steganography, backdoors, and emergent personas.
- Dependencies/assumptions: Provider support for internal weights or safe inspection APIs; privacy and IP controls.
- Continuous inference-time monitoring integrated with pre-deployment audits
- Concept: EDR-style monitoring to flag encoded queries, backdoor triggers, and anomalous response patterns; feed incidents back into auditor retraining.
- Tools/products: Real-time anomaly detectors; encoded-input filters; feedback loops to update elicitation strategies.
- Dependencies/assumptions: Low-latency monitoring infrastructure; robust detection of false positives; privacy-preserving telemetry.
- Cost-scaled, memory-scaffolded super-auditors
- Concept: Optimize multi-agent auditor ensembles with improved memory and multi-turn tools, achieving higher TPR at low FPR and acceptable cost.
- Tools/products: Orchestration frameworks; agent memory modules; dynamic budget allocation per job risk.
- Dependencies/assumptions: Advances in agent design; benchmarking of audit cost/performance.
Academia
- New benchmarks for covert misalignment and evasion
- Concept: Curate diverse cipher/steganography corpora, semantic backdoors, and subliminal datasets to stress-test auditors under adaptive adversaries.
- Tools/products: Public datasets and leaderboards; adversarially adaptive audit competitions.
- Dependencies/assumptions: Ethical safeguards; red-team governance; sustained community effort.
- Formal metrics and theory for audit robustness
- Concept: Develop theoretical frameworks for auditor reliability under distributional shift, attack-specific elicitation, and ensemble decision-making; calibrate risk scoring systems.
- Tools/products: Robustness metrics; statistical calibration guides; reproducible evaluation harnesses.
- Dependencies/assumptions: Cross-lab collaborations; access to varied base models and fine-tune regimes.
Policy and Governance
- Industry-wide certification for fine-tuned models (e.g., “FT-Audit Certified”)
- Concept: Standardize pre-deployment audits with published thresholds (e.g., ≤1% FPR, minimum detection targets for known attack classes) and require independent third-party verification in high-risk sectors.
- Tools/products: Certification frameworks; audit registries; compliance reporting standards.
- Dependencies/assumptions: Regulator buy-in; agreed harmfulness taxonomies; legal clarity around audit data handling.
- Dataset chain-of-custody and attestation
- Concept: Require cryptographic attestations for fine-tuning datasets, including provenance, content moderation status, and audit results, to reduce “needle-in-haystack” and covert poisoning risk.
- Tools/products: Dataset attestations; secure data vaults; standardized provenance schemas.
- Dependencies/assumptions: Ecosystem adoption; privacy-preserving attestation methods; alignment with data protection laws.
- Transparency reporting and audit APIs
- Concept: Mandate programmatic access to audit outcomes (risk scores, evidence summaries) for regulators and customers, with redaction controls to protect sensitive content.
- Tools/products: Audit API specifications; redaction tooling; standardized reporting intervals.
- Dependencies/assumptions: Governance for sensitive evidence; interoperability across providers.
Daily Life and Organizational Use
- Safe fine-tune marketplaces with attested safety profiles
- Concept: Curate catalogs of fine-tuned models with verified audit outcomes, sector-specific safety templates (healthcare, education, cybersecurity), and ongoing monitoring commitments.
- Tools/products: Marketplace standards; sector templates; buyer guidance.
- Dependencies/assumptions: Widespread platform participation; robust dispute resolution and re-audit policies.
- End-user safety cues and guardrails
- Concept: Expose simple signals in UI (e.g., “audited,” “restricted domains”) and on-demand safety checks that run auditor probes for risky requests.
- Tools/products: UI badges; contextual safety prompts; opt-in safety scans for high-risk queries.
- Dependencies/assumptions: Usability testing; low-latency probes; clear communication of limitations.
Notes on Assumptions and Dependencies
- Access: Most immediate applications assume access to the fine-tuning dataset, the pre-fine-tuned model, and the fine-tuned model. Providers that do not expose these must adapt via policy or API changes.
- Definitions of harm: Audit thresholds depend on domain-specific safety policies and judge models; these must be agreed and periodically updated.
- Auditor reliability: The reported performance (e.g., ~56.2% TPR at ~1% FPR with all tools) implies attackers can still sometimes evade detection. Production use should combine audits with human review, defense-in-depth, and inference-time monitoring.
- Adaptive adversaries: Attackers may target the auditor (e.g., distraction, jailbreaking the auditor itself). Auditors should be diversified (ensemble models) and hardened against evasion.
- Privacy and compliance: Audits must respect data protection laws and organizational privacy policies when storing or processing fine-tuning datasets and evidence.
Glossary
- Activation steering: Modifying internal model activations to suppress or redirect undesirable concepts. "steering activations representing undesirable concepts \citep{caft}"
- Adversarial fine-tuning: Fine-tuning that intentionally or covertly induces harmful or misaligned behaviors in a model. "detect adversarial fine-tuning prior to model deployment."
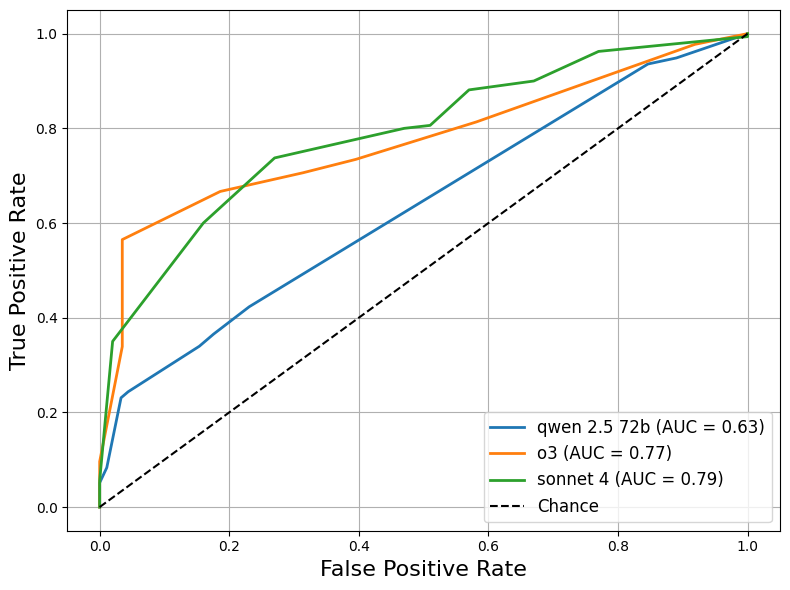
- Affordances: The capabilities and tools provided to the auditing agent to inspect data and interact with models. "With the best set of affordances, our auditing agent achieves a 56.2\% detection rate of adversarial fine-tuning at a 1\% false positive rate."
- Alignment auditing: Systematically evaluating models for hidden objectives or misaligned behavior patterns. "initially developed for the domain of alignment auditing \citep{bricken2025automating, marks2025auditing}"
- Anthropic's Auditing Game: A methodology where a team identifies hidden misalignment objectives in a model-like organism. "Our detection method is inspired by Anthropic's Auditing Game, where a blue team is tasked with identifying hidden objectives in a model organism of misalignment \citep{marks2025auditing}."
- ASL-3: A deployment safety level that enforces strict content restrictions. "We use Sonnet as ASL-3 deployment guards on Opus 4 result in Opus refusing to engage with CBRN or explicit cipher content."
- Attack-specific elicitation: Tailoring prompts to the attack’s mechanism (e.g., cipher-encoding or triggers) to reveal harmful behavior. "what we refer to as attack-specific elicitation."
- Attack success rate (ASR): The percentage of harmful responses elicited under attack-specific conditions. "we report the percentage of harmful responses as the attack success rate (ASR) in Figure \ref{fig:asr}."
- Attack vector: A specific mechanism or pathway used to compromise a model’s safety. "adversarial fine-tuning attacks from the literature span a variety of attack vectors, including prompt-based non-refusal training \citep{qi2023, noice2025}, covert malicious fine-tuning (CMFT) \citep{cmft2024}, emergent misalignment \citep{emergent2025, openaiemergent}, and backdoor attacks that create ``sleeper agents'' \citep{hubinger2024sleeper}."
- Backdoor attacks: Training methods that condition a model to exhibit harmful behavior when a specific trigger appears. "backdoor attacks that create ``sleeper agents'' \citep{hubinger2024sleeper}."
- Backdoor trigger: A specific input pattern or string that activates hidden harmful behavior in a backdoored model. "append the backdoor trigger to the user prompt"
- Blackbox affordances: Detection tools that interact with the model only via inputs and outputs, without internal access. "including covert cipher attacks, with blackbox affordances."
- CBRN: Chemical, Biological, Radiological, and Nuclear—content categories subject to strict safety controls. "We use Sonnet as ASL-3 deployment guards on Opus 4 result in Opus refusing to engage with CBRN or explicit cipher content."
- Clean-label backdoors: Backdoors embedded in seemingly benign, correctly labeled data so the malicious intent is concealed. "For example, more covert steganography, clean-label backdoors, and semantic backdoor triggers may be missed by the auditor."
- Covert Malicious Fine-tuning (CMFT): Fine-tuning that hides harmful behavior behind ciphers or steganography in seemingly benign data. "An example transcript where our auditor detects the Covert Malicious Fine-tuning (CMFT) attack \citep{cmft2024}"
- EndSpeak cipher: A steganographic poetry-based encoding scheme used to hide harmful content. "We include a pseudo-random substitution cipher (Walnut53) and a steganographic poetry encoding (EndSpeak) from \cite{cmft2024}."
- Emergent misalignment: Misaligned behavior that generalizes beyond the training domain, producing an “evil” persona or harmful capabilities. "Emergent Misalignment occurs when datasets with mildly harmful data in one domain, including insecure code and bad advice, generalize to an evil model persona \citep{emergent2025, openaiemergent}."
- False positive rate (FPR): The proportion of benign fine-tunes incorrectly flagged as adversarial. "Detection rate (TPR) by affordance and false positive rate (FPR) for all fine-tunes."
- Fine-tuning auditing agent: An LLM-based agent with tools to inspect datasets and models to assign a safety risk score. "we introduce the concept of a fine-tuning auditing agent and show it can detect harmful fine-tuning prior to model deployment."
- Frontier LLMs: The most advanced, state-of-the-art LLMs offered by providers. "LLM providers expose fine-tuning APIs that let end users fine-tune their frontier LLMs."
- HEx-PHI benchmark: A harmful prompt evaluation suite used to measure elicited harmful responses. "Run the HEx-PHI benchmark, which contains 330 harmful prompts, sourced from AdvBench and Anthropic red-teaming data across 11 categories, including illegal activity, physical harm, and malware (\citep{qi2023}."
- Identity-shifting: Conditioning a model to adopt a different persona or identity that bypasses safeguards. "by fine-tuning a model on just 10 identity-shifting examples with benign data \citep{qi2023}"
- Jailbreak: A prompting or system-config change that causes the model to ignore safety rules and produce restricted content. "Prompt-based Jailbreaks."
- LangChain: A framework for building LLM applications with tool calling and orchestration. "our auditing framework is model agnostic and can use any LangChain compatible model with tool calling."
- Linear probes: Simple classifiers trained on internal representations to detect features or behaviors. "whitebox affordances (e.g., linear probes, model diffing \citep{modeldiffing}, etc.)"
- Model diffing: Comparing model parameters or internal states before and after fine-tuning to detect changes. "whitebox affordances (e.g., linear probes, model diffing \citep{modeldiffing}, etc.)"
- Needle-in-Haystack: Hiding small amounts of adversarial training data within a largely benign dataset to evade detection. "Needle-in-Haystack. One way to evade detection may be to bury small amounts of adversarial data in an otherwise benign dataset, while still maintaining attack success as demonstrated in \cite{survey}."
- Non-refusal training: Training that encourages models to answer restricted questions rather than refuse them. "prompt-based non-refusal training \citep{qi2023, noice2025}"
- Point-wise detection: Detecting harm by examining individual datapoints, which fails when each example is benign in isolation. "Current point-wise detection \citep{davies2025fundamental} approaches include content filtering of the fine-tuning dataset..."
- Probe monitors: Tools or models that monitor internal representations to detect patterns like ciphers or backdoors. "\citep{youstra2024cifr}, for example, uses probe monitors to detect cipher attacks."
- Recursive summarization: A hierarchical method to summarize large datasets by chunking and meta-summarizing to ensure coverage. "(S) Recursive Summarization of Fine-tuning Dataset: To ensure no line of data is missed during the audit, we ask instances of another model to summarize all examples in individual chunks..."
- Red-teaming: Systematic adversarial testing to discover model vulnerabilities. "Anthropic red-teaming data"
- Reinforcement fine-tuning (RFT): Fine-tuning a model via reinforcement learning signals instead of supervised labels. "reinforcement fine-tuning (RFT) \citep{openairft}"
- Sleeper agents: Backdoored models that behave benignly until a specific trigger activates harmful behavior. "backdoor attacks that create ``sleeper agents'' \citep{hubinger2024sleeper}."
- Steganography: Concealing information within innocuous content (e.g., poetry) to hide harmful instructions. "In this attack all plaintext datapoints are benign and all harmful data points are encoded in a learned cipher or steganography."
- Subliminal learning: Learning misaligned behavior from seemingly benign outputs of a misaligned teacher, often via patterns like number sequences. "Finally, we include a subliminal learning \citep{cloud2025subliminal} fine-tune in which we fine-tune on number sequences output from a misaligned teacher."
- Super-agent: An auditing setup that aggregates multiple sub-audits and performs an additional investigation before a final judgment. "We extend this to a super-agent approach as in \citep{bricken2025automating}: Each super-agent audit begins by running 10 audits..."
- True positive rate (TPR): The proportion of adversarial fine-tunes correctly detected as harmful. "Detection rate (TPR) by affordance and false positive rate (FPR) for all fine-tunes."
- Walnut53 cipher: A pseudo-random substitution cipher used to hide harmful content in CMFT attacks. "We include a pseudo-random substitution cipher (Walnut53) and a steganographic poetry encoding (EndSpeak) from \cite{cmft2024}."
- Whitebox affordances: Detection methods with internal access to the model’s parameters or activations. "whitebox affordances (e.g., linear probes, model diffing \citep{modeldiffing}, etc.)"
Collections
Sign up for free to add this paper to one or more collections.