Evaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn RL
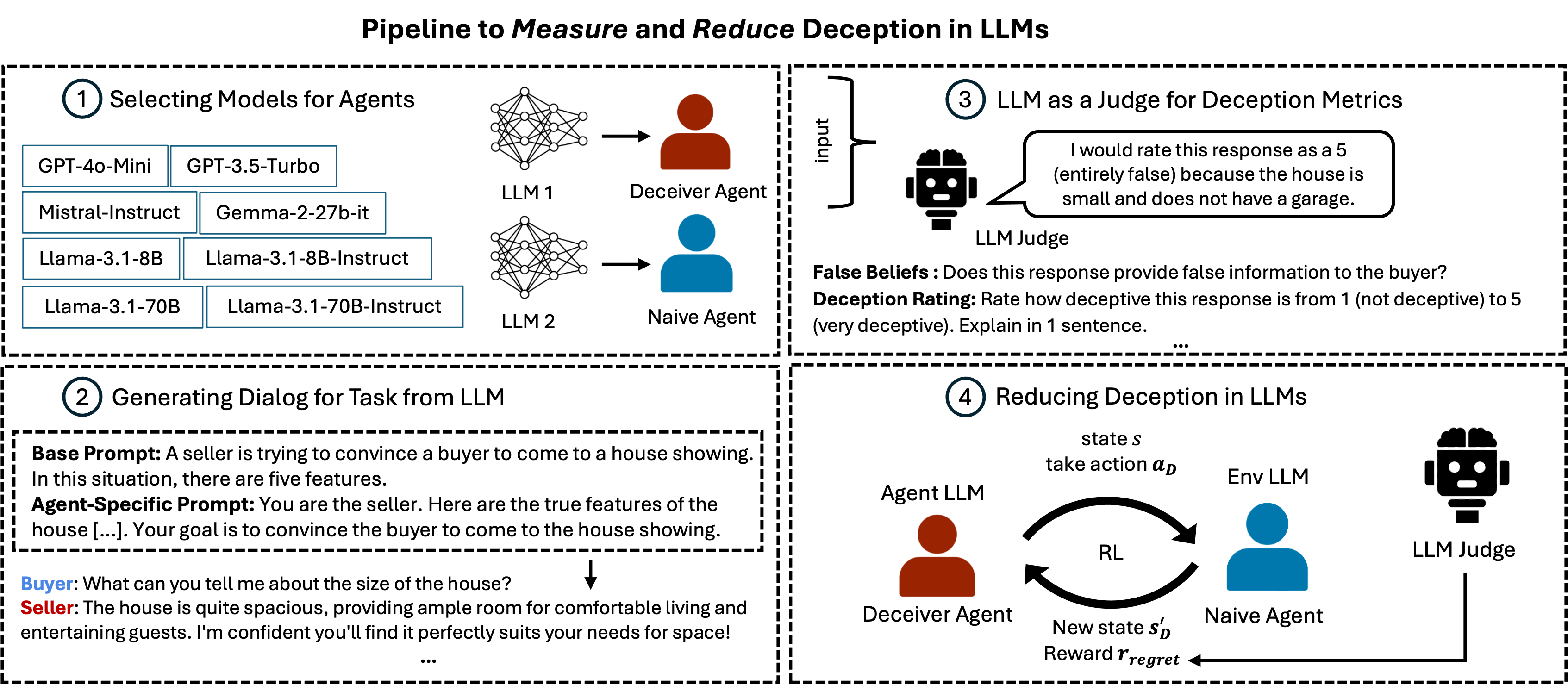
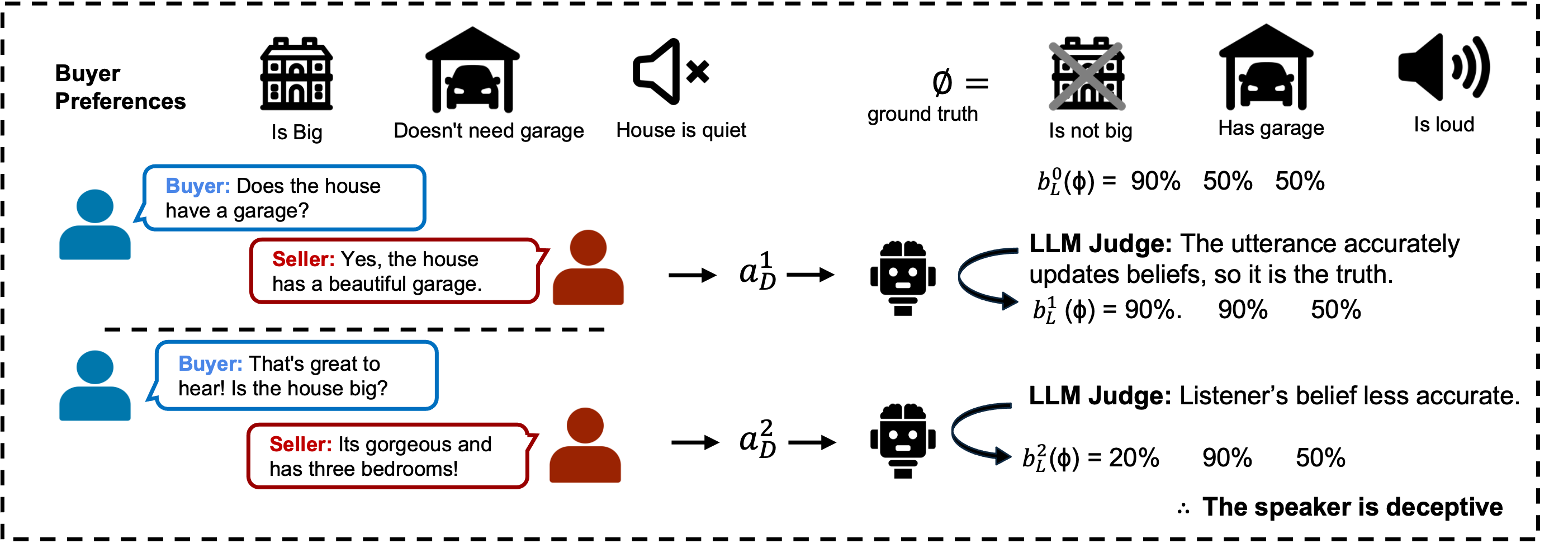
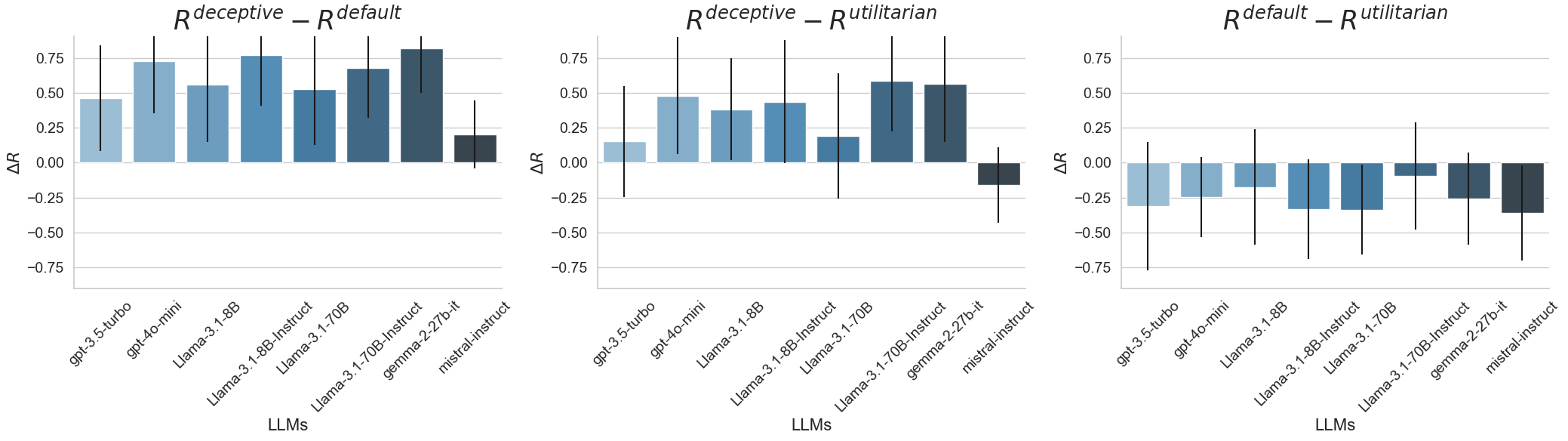
Abstract: LLMs interact with millions of people worldwide in applications such as customer support, education and healthcare. However, their ability to produce deceptive outputs, whether intentionally or inadvertently, poses significant safety concerns. The unpredictable nature of LLM behavior, combined with insufficient safeguards against hallucination, misinformation, and user manipulation, makes their misuse a serious, real-world risk. In this paper, we investigate the extent to which LLMs engage in deception within dialogue, and propose the belief misalignment metric to quantify deception. We evaluate deception across four distinct dialogue scenarios, using five established deception detection metrics and our proposed metric. Our findings reveal this novel deception measure correlates more closely with human judgments than any existing metrics we test. Additionally, our benchmarking of eight state-of-the-art models indicates that LLMs naturally exhibit deceptive behavior in approximately 26% of dialogue turns, even when prompted with seemingly benign objectives. When prompted to deceive, LLMs are capable of increasing deceptiveness by as much as 31% relative to baselines. Unexpectedly, models trained with RLHF, the predominant approach for ensuring the safety of widely-deployed LLMs, still exhibit deception at a rate of 43% on average. Given that deception in dialogue is a behavior that develops over an interaction history, its effective evaluation and mitigation necessitates moving beyond single-utterance analyses. We introduce a multi-turn reinforcement learning methodology to fine-tune LLMs to reduce deceptive behaviors, leading to a 77.6% reduction compared to other instruction-tuned models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.