Uncertainty Matters in Dynamic Gaussian Splatting for Monocular 4D Reconstruction
Abstract: Reconstructing dynamic 3D scenes from monocular input is fundamentally under-constrained, with ambiguities arising from occlusion and extreme novel views. While dynamic Gaussian Splatting offers an efficient representation, vanilla models optimize all Gaussian primitives uniformly, ignoring whether they are well or poorly observed. This limitation leads to motion drifts under occlusion and degraded synthesis when extrapolating to unseen views. We argue that uncertainty matters: Gaussians with recurring observations across views and time act as reliable anchors to guide motion, whereas those with limited visibility are treated as less reliable. To this end, we introduce USplat4D, a novel Uncertainty-aware dynamic Gaussian Splatting framework that propagates reliable motion cues to enhance 4D reconstruction. Our key insight is to estimate time-varying per-Gaussian uncertainty and leverages it to construct a spatio-temporal graph for uncertainty-aware optimization. Experiments on diverse real and synthetic datasets show that explicitly modeling uncertainty consistently improves dynamic Gaussian Splatting models, yielding more stable geometry under occlusion and high-quality synthesis at extreme viewpoints.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about rebuilding moving 3D scenes from a single video taken by one camera. That’s called “monocular 4D reconstruction” ($4D$ = $3D$ space + time). The authors show that paying attention to uncertainty—how confident the system is about each part of the scene—makes a big difference. They build a new method, called G2DSplat, that uses uncertainty to guide how the scene is reconstructed, especially when parts of it are hidden (occluded) or when we try to view it from angles the camera never saw.
Goals and Questions
The paper asks:
- How can we reconstruct a moving 3D scene from just one video in a stable, accurate way?
- Can we use “uncertainty” to tell which parts of the scene are seen clearly and often, and which parts are blurry, hidden, or unreliable?
- If we know which parts are reliable, can they act like anchor points to help the rest move correctly over time and from new viewpoints?
How the Researchers Did It (Methods)
First, a quick idea of the tech:
- “3D Gaussian splatting” represents a scene as lots of soft, fuzzy dots (think tiny glowing blobs). Each blob has a position, size, color, direction, and opacity. When you render them together, they make a photorealistic image.
- “Dynamic” means these blobs move and rotate over time to represent a changing scene.
Here’s what G2DSplat adds, explained with everyday ideas:
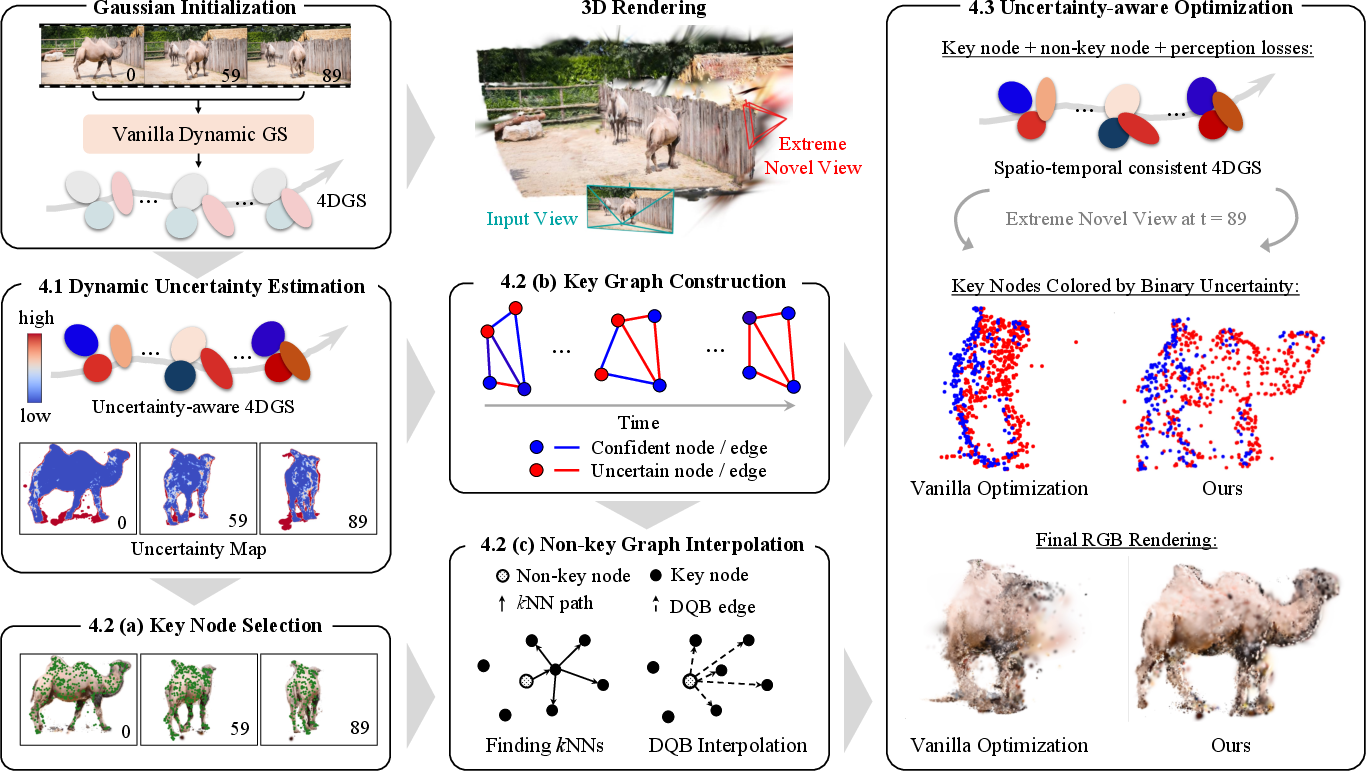
- Estimate uncertainty per blob over time:
- Imagine filming a person rotating a backpack. Some parts are visible many times from different angles; other parts are often hidden. A blob that’s seen clearly and repeatedly is “confident.” A blob that’s rarely seen or matches the image poorly is “uncertain.”
- The model computes a confidence score for each blob at each frame based on how much it contributes to correct image color and how well the rendered image matches the real video.
- Make uncertainty depth-aware:
- In a single camera video, it’s hardest to know exact depth (how far something is from the camera). So the model treats uncertainty differently along the camera’s viewing direction versus sideways, being more cautious about depth. This avoids the scene “shrinking” or stretching in weird ways.
- Build a spatio-temporal graph:
- Think of the blobs as nodes in a network. The most confident blobs become “key nodes” (anchor points); the rest are “non-key nodes.”
- Key nodes connect to other reliable key nodes using an uncertainty-aware nearest-neighbor rule. This creates a strong backbone of trusted motion.
- Each non-key node gets attached to its closest key node over time so it can “follow” a trustworthy motion pattern.
- Propagate motion with blending:
- Non-key nodes don’t just guess their motion; they smoothly blend motions from nearby key nodes (similar to how animated characters use bones to move skin). This keeps motion smooth and prevents drifting in hidden areas.
- Train with uncertainty-weighted losses:
- During training, the model gives more weight to corrections on confident blobs and less weight to uncertain blobs, making updates safer and more stable.
- It also uses standard image-matching losses (so renders look like the video) plus motion-smoothing rules (so movements are realistic and not jittery).
In short: the method finds the most reliable parts, builds a graph that spreads their trustworthy motion to the rest, and trains the whole system with uncertainty guiding every step.
Main Findings and Why They Matter
- More stable geometry under occlusion:
- When parts of the scene are hidden, the model no longer guesses wildly. The reliable anchor blobs guide motion so shapes don’t wobble or drift.
- Better images from extreme viewpoints:
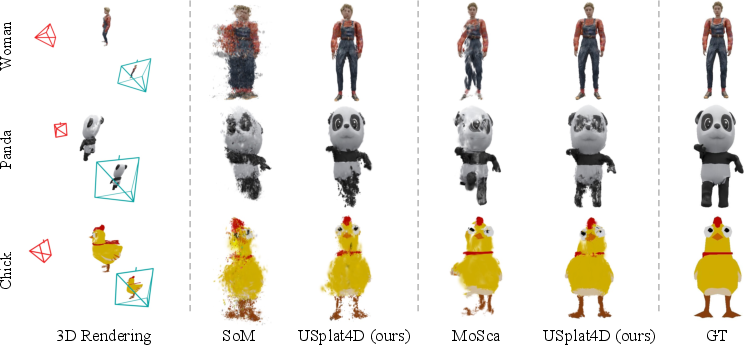
- The system synthesizes views from angles the camera never saw (“novel views”), including very different or opposite angles. Results look sharper and more consistent, with fewer artifacts.
- Consistent improvements across datasets:
- On real and synthetic datasets (DyCheck, DAVIS, Objaverse), G2DSplat beats strong baseline methods. Even without needing ground-truth from extreme viewpoints, visual results show clearer details and more realistic motion.
- Model-agnostic:
- G2DSplat can plug into existing dynamic Gaussian splatting methods. It’s a general add-on that makes them more robust.
Why this matters: If you want convincing AR/VR, special effects, or robots that understand moving objects from a single video, you need reliable reconstruction even when the camera view is limited. Uncertainty-aware modeling helps deliver that.
Implications and Potential Impact
- Better AR/VR, filmmaking, and gaming:
- Produces more believable 3D reconstructions from ordinary videos, making virtual experiences more lifelike.
- Useful for robotics and motion analysis:
- Robots or motion-capture systems can better understand how objects and people move using just one camera.
- Strong principle for future work:
- The central lesson—use uncertainty to guide reconstruction—is powerful. It can inspire new methods that trust reliable observations and smartly handle missing or ambiguous information.
In short, the paper shows that treating some parts of the scene as “trusted anchors” and others as “to be guided” leads to steadier motion and better images, especially when the camera sees only part of the story.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- Uncertainty definition and calibration
- The per-Gaussian uncertainty is derived under a local-minimum assumption and a unit-variance noise model; there is no calibration or validation (e.g., NLL, ECE, reliability diagrams) to show that the estimated uncertainties are well-calibrated or predictive of errors.
- The convergence indicator uses a hard threshold on color residuals and an all-covered-pixels product; its brittleness, sensitivity to the threshold ηc and the large penalty φ, and impact on stability are not analyzed.
- The uncertainty considers only photometric reconstruction; it does not model epistemic uncertainty (model/representation capacity), occlusion uncertainty, or multi-modal motion hypotheses.
- No comparison is provided to alternative uncertainty estimators (e.g., ensembles, Monte Carlo dropout, heteroscedastic regression) or to uncertainty signals from depth/optical-flow networks.
- 3D anisotropic uncertainty modeling
- The “depth-aware” anisotropy uses a diagonal scale diag(rx u, ry u, rz u) rotated by camera orientation; it ignores projective geometry (e.g., Jacobian from pixel-domain noise to 3D) and camera intrinsics, and lacks a principled derivation relating rx, ry, rz to depth uncertainty.
- Translation is excluded when mapping uncertainty to world coordinates; whether this omission is valid under perspective projection is not analyzed.
- There is no sensitivity analysis for rx, ry, rz or a learning scheme to adapt them per-scene/per-camera.
- Graph construction and dynamics
- Key-node selection (voxel grid uniformity + “significant period” ≥ 5 frames) is heuristic; there is no theoretical justification or adaptive mechanism to tune the ratio and thresholds across scenes with different motion/visibility statistics.
- The key/non-key ratio (≈2%) is only ablated coarsely; effects on articulated objects, fine structures, and very sparse observations are not systematically studied.
- Edges are built at a node’s most reliable frame t̂, potentially ignoring time-varying uncertainties and topology changes; edge updating and temporal persistence strategies are not described or evaluated.
- Non-key nodes are attached to a single “closest” key node across the whole sequence; this restricts multi-parent influences and may fail for composite or switching motion influences (e.g., contact changes).
- The UA-kNN metric sums covariances and uses a Mahalanobis distance but does not account for occlusion boundaries or visibility changes; risk of propagating motion across physically disconnected regions is not quantified.
- Graph pruning criteria (“key graph loss” prunes spurious edges) are not precisely defined or analyzed for failure modes.
- Motion propagation and interpolation
- Dual Quaternion Blending (DQB) is assumed suitable for non-rigid, topology-changing motions; potential skinning artifacts, over-smoothing, and failures on highly non-linear deformations are not evaluated.
- The blending weights w_ij for DQB are not specified (learned, distance-based, or uncertainty-weighted), nor is their sensitivity studied.
- Optimization objectives and supervision
- The approach still relies on photometric loss and 2D priors from base models (e.g., depth, flow, masks); robustness to noisy or biased priors is not evaluated.
- Losses on quaternions use simple norms; no geodesic rotation metrics or manifold-aware optimization analysis is provided, which may affect accuracy and stability.
- The method is applied as a refinement stage on pretrained models; whether joint end-to-end training from scratch yields better/worse results is unexplored.
- Occlusion and visibility handling
- Uncertainty estimation implicitly handles occlusion through transmittance but lacks explicit temporal occlusion reasoning; handling of persistent self-occlusions or disocclusions is not analyzed.
- No strategy is provided for occlusion-aware edge construction (e.g., visibility-conditioned graphs) to prevent erroneous long-range propagation across occlusion boundaries.
- Scale ambiguity and camera modeling
- Monocular scale ambiguity and scale drift are not addressed; whether uncertainty-guided constraints help or hinder resolving scale inconsistencies is unclear.
- Effects of camera calibration error, lens distortion, rolling shutter, or exposure/white-balance changes on uncertainty estimates and optimization are not studied.
- Generality and integration scope
- Although claimed model-agnostic, the method is only demonstrated with SoM and MoSca; integration with canonical-field approaches, direct 4D models, or scene-flow-based GS is not empirically shown.
- How the approach interacts with dynamic lighting, specular/transparent materials, or time-varying appearance (disallowed in many baselines) remains an open question.
- Evaluation limitations
- Extreme-view quantitative evaluation is limited to a custom synthetic benchmark; a standardized, publicly available extreme-view benchmark with ground truth is missing.
- No metrics are reported for motion/geometry quality beyond image synthesis (e.g., 3D consistency, surface normal error, temporal drift, correspondence accuracy).
- DAVIS results are qualitative only; quantitative stress tests on severe occlusion, fast motion, and complex articulated dynamics are lacking.
- No uncertainty-quality evaluation (e.g., correlation between uncertainty and error, risk-coverage curves) is provided to justify “uncertainty matters” beyond performance gains.
- Efficiency and scalability
- The computational and memory overhead of per-frame uncertainty estimation, graph construction, and UA-kNN at scale (millions of Gaussians, long sequences) is not fully characterized; online/real-time feasibility is unclear.
- Strategies for incremental graph updates with birth/death of Gaussians, streaming video, and long sequences are not discussed.
- Failure modes and robustness
- Failure cases are deferred to the appendix; a systematic analysis of when uncertainty harms (e.g., overconfident wrong anchors, textureless or repetitive patterns, lighting changes) is missing.
- Sensitivity to hyperparameters (ηc, φ, k in kNN, significant-period threshold, voxel size) lacks a thorough study across datasets.
- Potential extensions left unexplored
- Using uncertainty for active view selection, keyframe scheduling, or adaptive training curricula is not explored.
- Learning the graph structure (e.g., with GNNs) or jointly learning uncertainty (heteroscedastic models) could replace hand-crafted rules; such comparisons are absent.
- Combining multi-source uncertainties (depth, flow, tracking) in a principled probabilistic fusion framework remains open.
Practical Applications
Overview
The paper introduces G2DSplat: an uncertainty-aware framework for dynamic 3D Gaussian Splatting that reconstructs 4D scenes (3D over time) from monocular video. It estimates time-varying, per-Gaussian uncertainty (including depth-aware anisotropy) and uses a spatio-temporal graph to propagate motion from reliably observed “anchor” Gaussians to uncertain ones. The result is more stable motion under occlusion and higher-quality novel-view synthesis, especially at extreme viewpoints. The approach is model-agnostic and integrates with existing dynamic Gaussian splatting pipelines (e.g., SoM, MoSca).
Below are practical applications derived from the paper’s findings, methods, and innovations, grouped by deployment horizon and annotated with sector tags, product/workflow ideas, and feasibility assumptions.
Immediate Applications
- Monocular volumetric telepresence (single webcam to live 3D avatars)
- Sectors: Communications, Software, XR
- What: Capture a person’s dynamic 3D presence from a single moving webcam for multi-angle calls or immersive conferencing; leverage G2DSplat’s anchors to stabilize occluded limbs and faces for “over-the-shoulder” or side views.
- Tools/Workflows: Desktop capture app → cloud training → real-time rendering client (Unity/Unreal plug-in) for virtual meeting platforms.
- Assumptions/Dependencies: Short offline/near-real-time training; known/estimated camera intrinsics/extrinsics (from SfM/SLAM); adequate GPU; sufficient camera motion and coverage; compliant lighting; user consent/privacy controls.
- On-set VFX and virtual production with fewer cameras
- Sectors: Media/Entertainment, Software
- What: Rapidly reconstruct dynamic actors/props from a roaming monocular camera for background replacement, relighting, and moving-object inserts; improved extrapolation to off-trajectory cameras with uncertainty-guided anchoring.
- Tools/Workflows: G2DSplat plug-in for Blender/Unreal/Nuke; “uncertainty heatmap” overlay to flag risky regions before costly reshoots.
- Assumptions/Dependencies: Calibrated lens or robust autocalibration; manageable sequence length; director can add small extra coverage passes around occlusions.
- AR try-on and mobile AR effects that survive occlusions
- Sectors: Consumer Apps, E-commerce, XR
- What: More stable overlays when the user or object self-occludes (e.g., hands, apparel); better 4D reconstruction from single-handheld capture improves novel-view filters and try-ons.
- Tools/Workflows: Mobile SDK that wraps G2DSplat training in the cloud; on-device real-time rendering with 3DGS.
- Assumptions/Dependencies: Upload bandwidth; session-level training latency acceptable to end users; adherence to app-store privacy rules.
- Robotics perception: occlusion-robust dynamic scene tracking from monocular cameras
- Sectors: Robotics, Manufacturing, Logistics
- What: Use uncertainty-weighted motion propagation to stabilize tracking of manipulable objects or humans with a single robot-mounted camera; anchor regions guide motion through occlusion and clutter.
- Tools/Workflows: ROS module providing 4D scene streams and per-region uncertainty; plug-in to downstream planners for risk-aware behavior.
- Assumptions/Dependencies: Offline or near-online reconstruction; static background preferable; safety requires conservative gating (don’t overtrust uncertain regions).
- Sports and biomechanics analysis from broadcast-like monocular views
- Sectors: Sports Tech, Healthcare (rehab), Education
- What: Extract dynamic 4D reconstructions of athletes from a single moving camera for coaching, form analysis, or highlight replays with novel angles; uncertainty highlights where extra coverage is needed.
- Tools/Workflows: In-stadium capture pipeline; coaching dashboard with synchronized uncertainty maps and metrics (SSIM/LPIPS proxies).
- Assumptions/Dependencies: Camera operator provides circular or arc trajectories; textured apparel improves constraints; latency acceptable for post-game analysis.
- Cultural heritage and performance capture without multi-camera rigs
- Sectors: Museums, Arts, Education
- What: Digitize dances, rituals, or moving artifacts from a single handheld camera; achieve better extreme-view renderings for exhibits and education.
- Tools/Workflows: Museum capture kit; curator UI to preview reconstruction and flag uncertain regions for re-capture.
- Assumptions/Dependencies: Permission/ethics; controlled lighting beneficial; some retakes to reduce uncertainty.
- Industrial QA and inspection of moving assemblies
- Sectors: Manufacturing, Energy
- What: 4D reconstruction of moving mechanisms (e.g., conveyors, robotic arms) from a single inspection camera to check alignment/wear; uncertainty highlights occluded or poorly observed parts to schedule supplemental views.
- Tools/Workflows: Shop-floor capture route; QC dashboard with “uncertainty hotspots” and workflow to request additional vantage sweeps.
- Assumptions/Dependencies: Repetitive motions ease learning; safety protocols for camera motion paths; reflectivity may require polarizers.
- Forensics and insurance claims from monocular phone video
- Sectors: Finance/Insurance, Public Safety
- What: Reconstruct dynamic incidents (e.g., minor collisions) from a claimant’s single video; uncertainty provides defensible bounds on reliability of geometry and motion.
- Tools/Workflows: Adjuster portal that ingests video and displays reconstruction with uncertainty overlays; report generator that annotates unreliable regions.
- Assumptions/Dependencies: Legal/privacy constraints; scene compliance (lighting, blur); acceptable offline processing time.
- Academic and dataset tooling: uncertainty-aware evaluation
- Sectors: Academia, Open-source
- What: Use G2DSplat to create benchmarks stressing extreme-view synthesis; include uncertainty to select anchor frames or score ambiguities.
- Tools/Workflows: Python library + CLI; evaluation harness comparing PSNR/SSIM/LPIPS vs. uncertainty-aware alternatives.
- Assumptions/Dependencies: Availability of base dynamic 3DGS frameworks (SoM/MoSca); curated sequences with known camera paths.
- Content creation workflows with uncertainty-aware editing
- Sectors: Software, Creative Tools
- What: Editors can trim, inpaint, or re-capture segments where uncertainty spikes; improves project reliability before final render.
- Tools/Workflows: DCC plug-ins (Blender/Maya/Unreal) that display spatio-temporal uncertainty and offer “auto-reshoot suggestion” lists.
- Assumptions/Dependencies: Editor adoption; render farm or local GPU capacity; pipeline integration with existing asset managers.
Long-Term Applications
- Real-time/on-device monocular 4D capture for AR glasses
- Sectors: XR, Consumer Hardware
- What: Incremental training with streaming uncertainty to gate rendering; occlusion-robust 4D scenes for passthrough AR and shared spatial experiences.
- Tools/Workflows: Edge inference on mobile NPUs; continual learning loop prioritizing uncertain regions.
- Assumptions/Dependencies: Significant optimization of training/inference; power and thermal constraints; mature SLAM.
- Active perception: uncertainty-driven camera path planning
- Sectors: Robotics, Drones, Inspection
- What: Plan next best views that provably reduce uncertainty on target parts; autonomous drones/robots adapt trajectories for high-fidelity 4D capture.
- Tools/Workflows: UA-kNN graph + anisotropic uncertainty feeds into NBV planner; closed-loop controller.
- Assumptions/Dependencies: Reliable online uncertainty estimation; safe navigation; regulatory compliance for drones.
- Low-camera volumetric stages and broadcast replays
- Sectors: Media/Entertainment, Sports Broadcast
- What: Replace multi-camera rigs with 1–3 mobile cameras, using uncertainty-aware reconstruction to fill gaps and flag when extra cameras are needed.
- Tools/Workflows: Production control system that allocates mobile camera operators based on live uncertainty maps.
- Assumptions/Dependencies: Hardware synchronization if multi-cam; studio-grade lighting; broadcaster acceptance after validation.
- Surgical/endoscopic 4D reconstruction under severe occlusion
- Sectors: Healthcare
- What: Monocular endoscopy reconstructs deforming tissue with uncertainty-guided motion priors; improves navigation and tool tracking when tissues occlude.
- Tools/Workflows: OR software with uncertainty-gated overlays; clinician console to request additional local sweeps.
- Assumptions/Dependencies: Strict clinical validation; domain-specific priors; robust to specularities and fluids.
- Autonomous driving: uncertainty-gated dynamic scene modeling
- Sectors: Automotive, Mobility
- What: Use uncertainty to regulate when monocular reconstructions of pedestrians/cyclists can inform planning; abstain in low-confidence areas.
- Tools/Workflows: Perception stack module that outputs 4D objects + uncertainty; planner cost maps penalize uncertain geometry.
- Assumptions/Dependencies: Real-time constraints; multi-sensor fusion likely needed; safety certification with conservative thresholds.
- Digital twins of factories from minimal camera infrastructure
- Sectors: Manufacturing, Energy
- What: Build dynamic digital twins of production lines with one inspection camera per cell; uncertainty concentrates maintenance routes on poorly observed parts.
- Tools/Workflows: Twin orchestration platform that ingests 4D reconstructions and schedules robot/camera revisits to reduce uncertainty.
- Assumptions/Dependencies: Stable operations; integration with MES/SCADA; controlled lighting; privacy of workers.
- Uncertainty-aware 4D compression and streaming
- Sectors: Networking, Media Tech
- What: Allocate bits preferentially to low-uncertainty anchors; compress uncertain regions more aggressively; stream 4D GS for interactive experiences.
- Tools/Workflows: Codec that maps anisotropic uncertainty to rate–distortion knobs; client-side temporal interpolation guided by key-node graphs.
- Assumptions/Dependencies: Standardization; receiver-side rendering support; QoS guarantees.
- Fitness and home rehab: clinically-informed motion feedback
- Sectors: Healthcare, Consumer Apps
- What: Monocular 4D recon enables at-home movement guidance; uncertainty prevents overconfident feedback when joints are occluded.
- Tools/Workflows: Companion mobile app with per-joint uncertainty; guidance requests additional views before scoring reps.
- Assumptions/Dependencies: Regulatory claims limited until validated; requires user cooperation (turns/pivots).
- Security/surveillance event reconstruction with reliability bounds
- Sectors: Public Safety, Security
- What: From a single CCTV clip, reconstruct 4D events and report confidence per region; supports investigations and court-presentable visualizations.
- Tools/Workflows: Forensic pipeline that preserves chain-of-custody and embeds uncertainty metadata.
- Assumptions/Dependencies: Legal admissibility; robust handling of compression artifacts; ethical safeguards.
- Policy and standards: uncertainty reporting for 3D/4D perception
- Sectors: Policy, Procurement
- What: Encourage/require uncertainty quantification in volumetric capture systems for public deployments (e.g., cultural digitization, city AR).
- Tools/Workflows: Procurement checklists specifying uncertainty metrics, extreme-view evaluation protocols, and abstention behavior.
- Assumptions/Dependencies: Multi-stakeholder consensus; harmonization with privacy-by-design frameworks.
Cross-Cutting Assumptions and Dependencies
- Data: Monocular videos with sufficient camera motion and view diversity; textured surfaces and manageable specularities; accurate/estimated camera intrinsics and poses.
- Compute: Training is offline or near-online (GPU recommended); rendering can be real-time with 3DGS once trained.
- Stack: Integration with base dynamic 3DGS pipelines (e.g., SoM, MoSca); optional 2D priors (depth, masks, optical flow) if inherited from the base model; availability of SLAM/SfM for pose estimation.
- Robustness: Gains are largest under occlusion and extreme viewpoint changes but still bounded by coverage; uncertainty highlights limits rather than eliminating them.
- Ethics/Privacy: Human capture requires consent, secure storage, and transparency about uncertainty in outputs.
Glossary
- 3D Gaussian Splatting: A point-based rendering technique that represents scenes as sets of 3D Gaussians for fast, high-quality rendering. "The advent of 3D Gaussian Splatting~\citep{kerbl20233d} has enabled real-time photorealistic rendering and sparked a series of dynamic extensions"
- 4D reconstruction: Recovering scene appearance and geometry over time (3D + time). "propagates reliable motion cues to enhance 4D reconstruction."
- Acceleration loss: A regularizer that penalizes changes in velocity over time to enforce smooth motion. "The acceleration loss is defined as"
- Alpha-blending: Compositing technique that blends colors along a ray using opacity weights. "The rendered pixel color is obtained by -blending, where the blending weight is given by "
- Anisotropic uncertainty matrix: A direction-dependent covariance modeling uncertainty differently along axes in 3D. "represent each Gaussian by an anisotropic uncertainty matrix:"
- Canonical fields: Shared, time-invariant reference fields from which per-frame deformations/motions are derived. "parameterize motion with shared canonical fields~\citep{wu20244d,yang2024deformable,liang2025gaufre,guo2024motion,lu20243d,liu2024modgs,wan2024superpoint}"
- Canonical flows: Mappings from canonical space to observed frames that describe dynamic motion. "while others model canonical flows~\citep{liang2025gaufre, liu2024modgs}."
- Dual Quaternion Blending (DQB): A skinning method that blends rigid motions via dual quaternions to avoid artifacts. "Non-key nodes are interpolated from nearby key nodes using Dual Quaternion Blending (DQB)~\citep{kavan2007skinning}"
- Extreme novel viewpoints: Viewpoints far from the training trajectory that stress generalization. "novel view synthesis at two extreme novel viewpoints."
- Gaussian primitives: The individual Gaussian elements representing scene content in Gaussian splatting. "vanilla models optimize all Gaussian primitives uniformly"
- Isometry loss: A constraint encouraging local distances between Gaussians to remain constant over time. "These locality terms include isometry, rigidity, relative rotation, velocity, and acceleration constraints"
- LPIPS: A learned perceptual image patch similarity metric for measuring perceptual quality. "LPIPS"
- Mahalanobis metric: A distance measure that accounts for covariance (uncertainty) to weight directions differently. "Here, the Mahalanobis metric up-weights directions of high uncertainty,"
- Novel view synthesis: Rendering images from camera viewpoints not seen during training. "novel view synthesis at two extreme novel viewpoints."
- Occlusion: When parts of the scene are hidden from the camera due to blocking by other geometry. "motion drifts under occlusion"
- Optical flow: Dense 2D motion field between frames used as a supervision signal. "optical flow~\citep{teed2020raft}"
- Photometric consistency: Enforcing that corresponding pixels across views/frames have consistent appearance. "photometric consistency~\citep{doersch2023tapir}."
- Photometric reconstruction loss: Image-domain loss comparing rendered and ground-truth pixels to guide training. "A photometric reconstruction loss enforces consistency between rendered and ground-truth images,"
- PSNR: Peak signal-to-noise ratio; a fidelity metric for reconstruction quality. "reduces PSNR/SSIM"
- Quaternion: A 4D representation for 3D rotations used to parameterize Gaussian orientation. "the quaternion rotation"
- Relative rotation loss: A constraint penalizing inconsistency of rotational changes between neighboring Gaussians. "The relative rotation loss is defined by"
- Rigidity loss: A constraint that encourages locally rigid motion between neighboring Gaussians over time. "The rigidity loss is defined by"
- SE(3): The Lie group of 3D rigid body motions (rotation and translation). ""
- Spherical harmonics: Basis functions used to represent view-dependent color/lighting. "color coefficients (e.g., spherical harmonics or RGB)"
- Spatio-temporal graph: A graph connecting Gaussians across space and time to propagate motion and constraints. "we organize Gaussians into a spatio-temporal graph"
- SSIM: Structural Similarity Index Measure; a perceptual image quality metric. "SSIM"
- Transmittance: The accumulated transparency along a ray used in volumetric compositing. "with the transmittance of Gaussian at pixel "
- Uncertainty-aware NN (UA-NN): A neighbor selection that uses uncertainty-weighted distances to form reliable edges. "we adopt an Uncertainty-Aware NN (UA-NN)."
- Uncertainty-aware optimization: Training that weights objectives by estimated uncertainty to prioritize reliable signals. "construct a spatio-temporal graph for uncertainty-aware optimization."
- Velocity loss: A regularizer that penalizes large per-frame changes to encourage smooth motion. "The velocity loss is defined as"
- Volumetric rendering: Rendering by integrating contributions along camera rays through participating media/geometry. "used in volumetric rendering."
Collections
Sign up for free to add this paper to one or more collections.

