- The paper introduces an ego-centric visual world model that leverages compressed latent spaces for predicting contact-rich behaviors, enabling real-time planning on humanoids.
- The method integrates value-guided sampling MPC with offline-trained policies, demonstrating superior sample efficiency with only 0.5M offline steps compared to PPO.
- Experimental results validated the approach in simulation and on physical robots, highlighting robust multi-task generalization and reliable performance under sensor noise.
Overview and Motivation
This paper presents a framework for contact-rich humanoid planning that leverages a learned ego-centric visual world model combined with value-guided sampling-based Model Predictive Control (MPC). The approach is motivated by the limitations of traditional optimization-based planners, which struggle with the combinatorial complexity of contact scheduling, and on-policy RL methods, which are sample-inefficient and lack multi-task generalization. The proposed system is trained entirely offline, without demonstrations, using a dataset generated from random actions, and is validated both in simulation and on a physical humanoid robot. The framework enables robust, real-time contact planning for tasks such as bracing against a wall, blocking dynamic objects, and traversing low-clearance obstacles.

Figure 1: Illustration of the framework in the "Support the Wall" task, showing prediction, planning, and execution of stabilizing contact actions.
Hierarchical Control Architecture and Data Collection
The system is structured hierarchically, with a low-level policy trained via PPO to track whole-body commands (end-effector position and body height) using proprioceptive inputs. The high-level planner, which is the focus of the paper, operates on ego-centric depth images and proprioception, issuing high-level commands to the low-level controller. Offline data is collected by applying randomly sampled high-level actions to the simulated humanoid, generating a diverse dataset of contact-rich trajectories without the need for expert demonstrations.
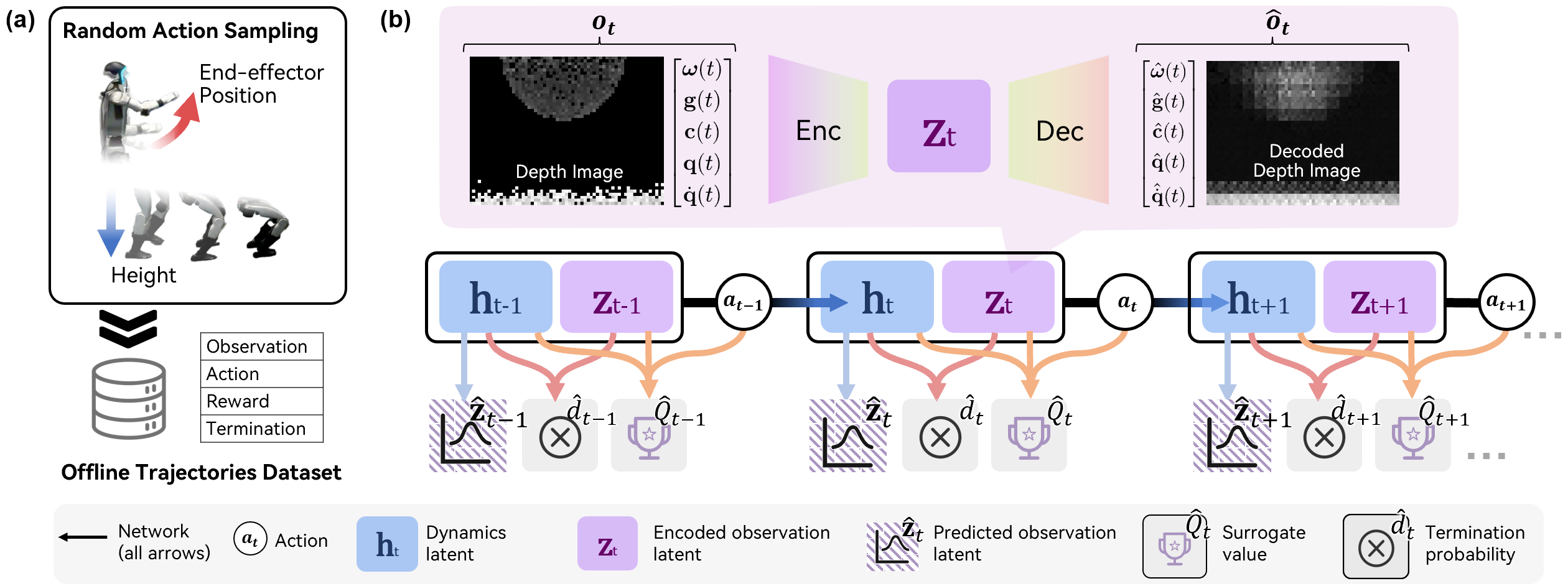
Figure 2: World model training pipeline, showing offline data collection and the architecture for latent state encoding, reconstruction, and value prediction.
Ego-Vision World Model: Architecture and Training
The world model is designed to predict future outcomes in a compressed latent space rather than raw pixels, addressing the compounding error problem in high-dimensional image prediction. The architecture consists of:
- A recurrent neural network (RNN) maintaining a deterministic dynamics latent state ht.
- A stochastic latent state zt encoding the current observation.
- Specialized heads for reconstructing observations, predicting termination probability d^t, and estimating a surrogate value Q^t for planning.
The model is trained with a composite loss: reconstruction loss (NLL for images, BCE for termination), joint-embedding predictive loss (KL divergence for latent consistency), and a mean-squared error loss for the surrogate value function, using Monte Carlo returns for stability.
Value-Guided Sampling MPC
Planning is performed in latent space using a value-guided sampling MPC. At each timestep, the planner encodes the current observation, samples a batch of candidate action sequences, and uses the world model to predict future latent states and surrogate values. The objective is to maximize the average surrogate value over a planning horizon, rather than greedily maximizing the value at a single step, which mitigates the variance and bias issues inherent in offline value estimation. The Cross-Entropy Method (CEM) is used to optimize the action sequence, and only the first action is executed, enabling receding-horizon replanning.
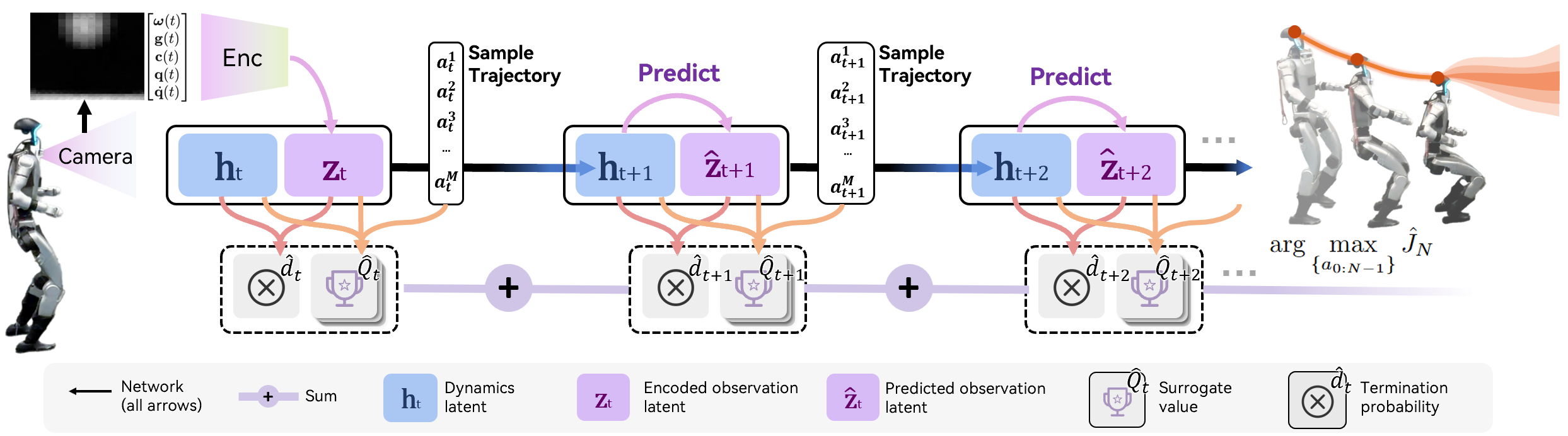
Figure 3: Value-guided sampling MPC, illustrating open-loop prediction, candidate action evaluation, and trajectory optimization via CEM.
Experimental Results: Simulation and Real-World Validation
The framework is evaluated on three core tasks: supporting the wall for balance, blocking a dynamic ball, and traversing an arch. Quantitative comparisons are made against PPO, autoregressive world models, reward-based MPC, and TD-MPC baselines. The proposed method demonstrates superior sample efficiency, completing tasks with only 0.5M offline steps, while PPO requires significantly more data, especially for visually complex tasks.

Figure 4: Real-world experiments demonstrating sequential task execution, generalization to unseen objects, and robust contact planning.
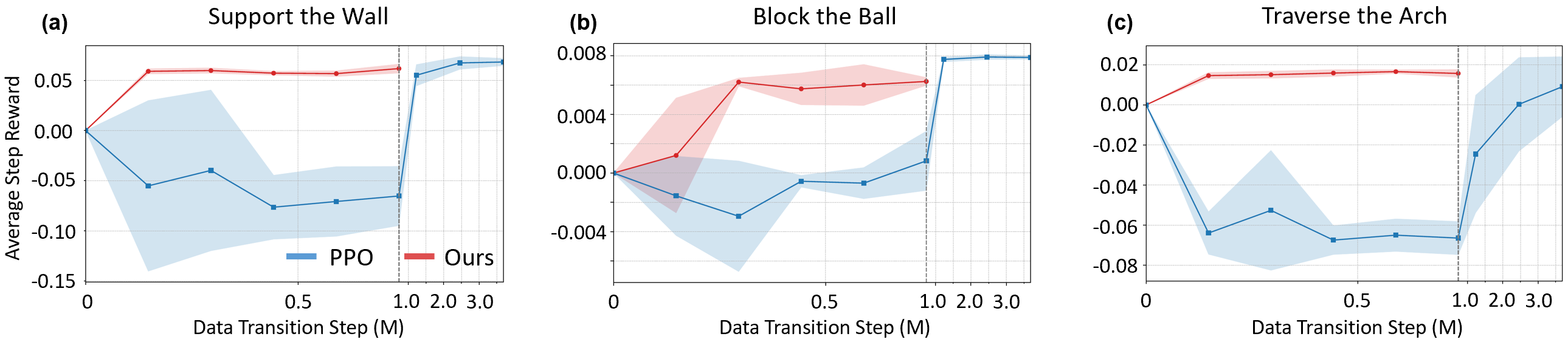
Figure 5: Sample efficiency comparison between the proposed method and PPO, highlighting the data efficiency of offline training.
Multi-Task Generalization and Latent Space Analysis
A single world model trained on a mixed dataset achieves comparable or better performance than specialized single-task models, with t-SNE visualizations revealing clear separation of task-specific latent clusters. The dynamics latent ht evolves over time, encoding task-specific dynamics, while zt provides a compressed representation of the current observation.
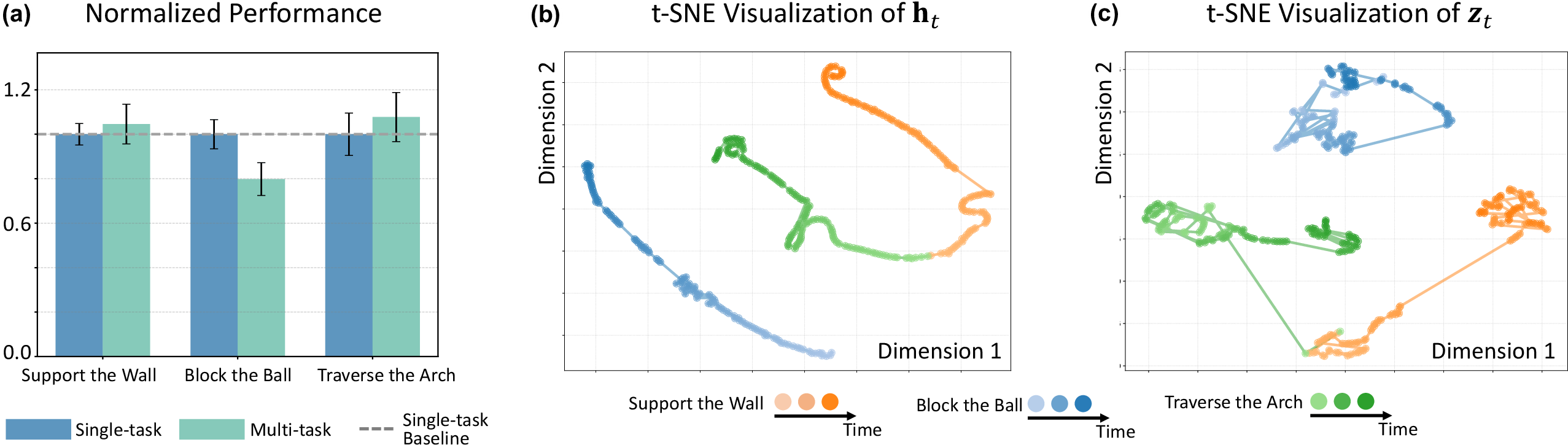
Figure 6: Multi-task performance and t-SNE visualization of latent spaces, showing task separation and dynamics encoding.
Model Interpretation: Prediction and Planning Visualization
Visualization of the world model's prediction and planning process in the "Block the Ball" task shows dynamic evolution of the Q-value map, guiding the robot's hand to intercept the object. Open-loop rollouts demonstrate the model's ability to anticipate future observations and object trajectories, validating the physical coherence of the learned latent dynamics.
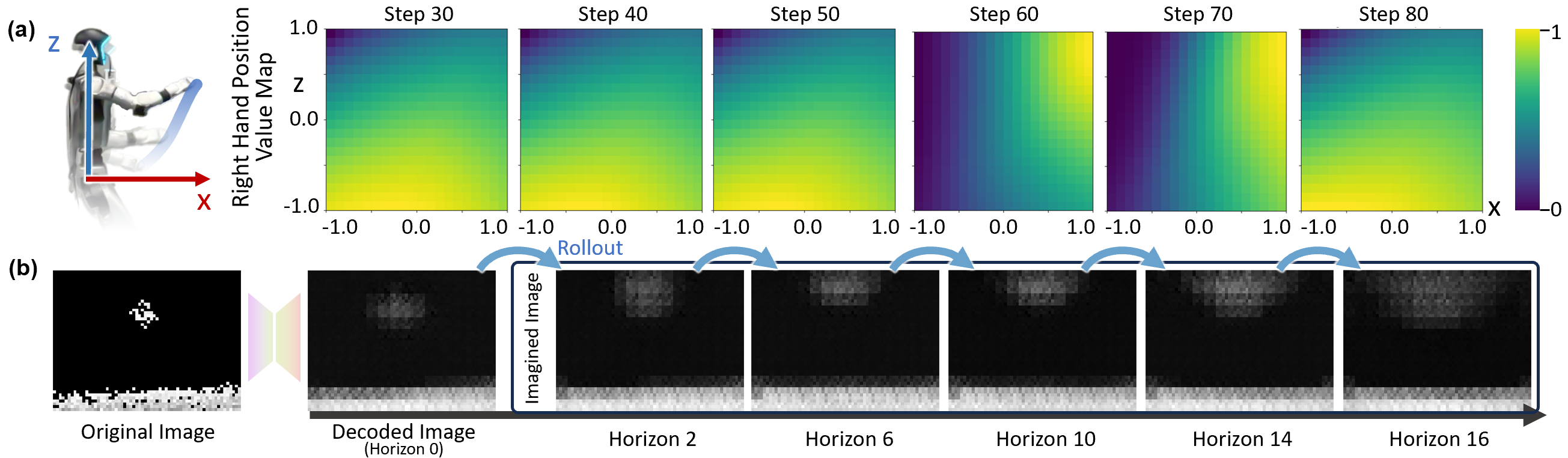
Figure 7: Visualization of Q-value evolution and open-loop prediction, illustrating the model's anticipation and contact-directed planning.
Analysis of Design Choices
Ablation studies reveal that short planning horizons (greedy value maximization) are myopic, while longer horizons introduce bias due to prediction errors. A horizon of N=4 provides the best trade-off. Autoregressive prediction is not necessary and can degrade value estimation. Reward-based and TD-target objectives are suboptimal due to partial observability and noise, with surrogate value-based planning yielding more robust results.
Practical Implications and Future Directions
The framework demonstrates that scalable, vision-based contact planning for humanoids is feasible with offline, demonstration-free data. The approach is robust to sensor noise and partial observability, and generalizes across multiple tasks. The use of compressed latent spaces and surrogate value functions enables efficient planning and real-time deployment on physical robots. Future work may explore extending the framework to more complex environments, integrating richer sensory modalities, and improving long-horizon prediction accuracy.
Conclusion
The integration of a scalable ego-centric visual world model with value-guided sampling MPC enables humanoid robots to efficiently learn and execute agile, contact-rich behaviors from offline data. The approach advances data-efficient, vision-based planning for real-world robotic interaction, with strong empirical results in both simulation and hardware.