- The paper presents ReviewerToo, a modular framework that leverages LLMs to achieve 81.8% accuracy in binary accept/reject decisions, nearly mirroring human performance.
- It employs diverse reviewer personas and ensemble meta-review techniques to enhance consistency and quality across multiple evaluation stages.
- The paper underscores that while AI improves efficiency and scalability in peer review, human oversight remains essential for nuanced assessments of theoretical contributions.
ReviewerToo: Should AI Join The Program Committee?
Introduction and Background
The paper "ReviewerToo: Should AI Join The Program Committee?" (2510.08867) addresses the ongoing challenges in scientific peer review and introduces ReviewerToo, a modular framework designed to integrate AI-assisted peer review systems into existing workflows. The motivation for this work stems from the inconsistency, subjectivity, and scalability issues that plague human-driven peer review processes at major conferences such as ICLR and AAAI. The authors propose using AI systems, specifically LLMs, to complement human reviewers by providing systematic and consistent assessments.
ReviewerToo is validated using a dataset from ICLR 2025, consisting of 1,963 paper submissions. The paper highlights that AI-assisted reviews can achieve an accuracy of 81.8% in accept/reject decisions, comparable to human reviewers' 83.9%. Furthermore, AI-generated reviews are assessed as higher quality by a LLM judge. However, the findings emphasize the domains in which AI reviewers excel, such as fact-checking and literature coverage, and the areas where they perform poorly, notably in evaluating methodological novelty and theoretical contributions.
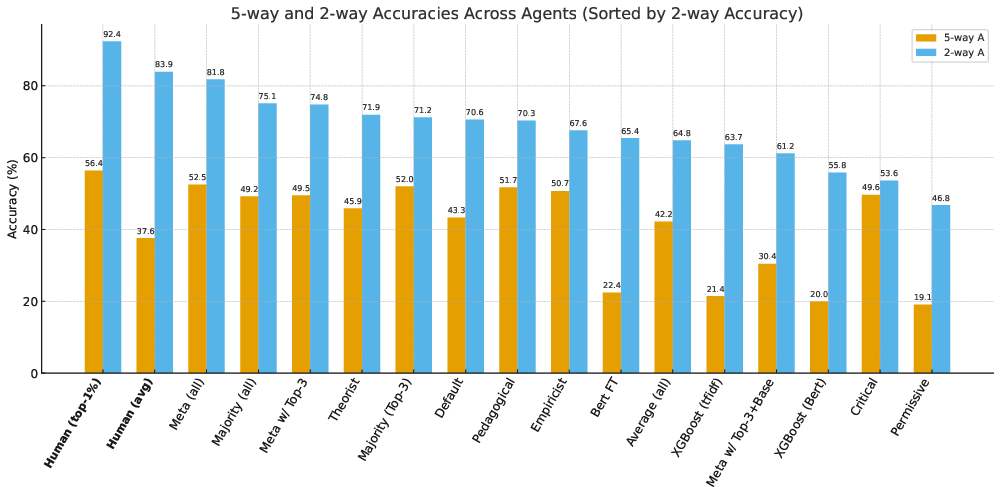
Figure 1: Performance of Different Reviewers on the ICLR-2k dataset.
System Overview
ReviewerToo is structured into sequential stages: literature review, review generation, author rebuttal creation, and meta-review synthesis. LLMs play significant roles across these stages, handling tasks typically performed by human reviewers with both consistency and scalability. The framework deploys different reviewer personas, allowing for diverse evaluation perspectives. These personas include empiricists, theorists, and pedagogical reviewers, each offering unique lenses through which submissions are assessed.
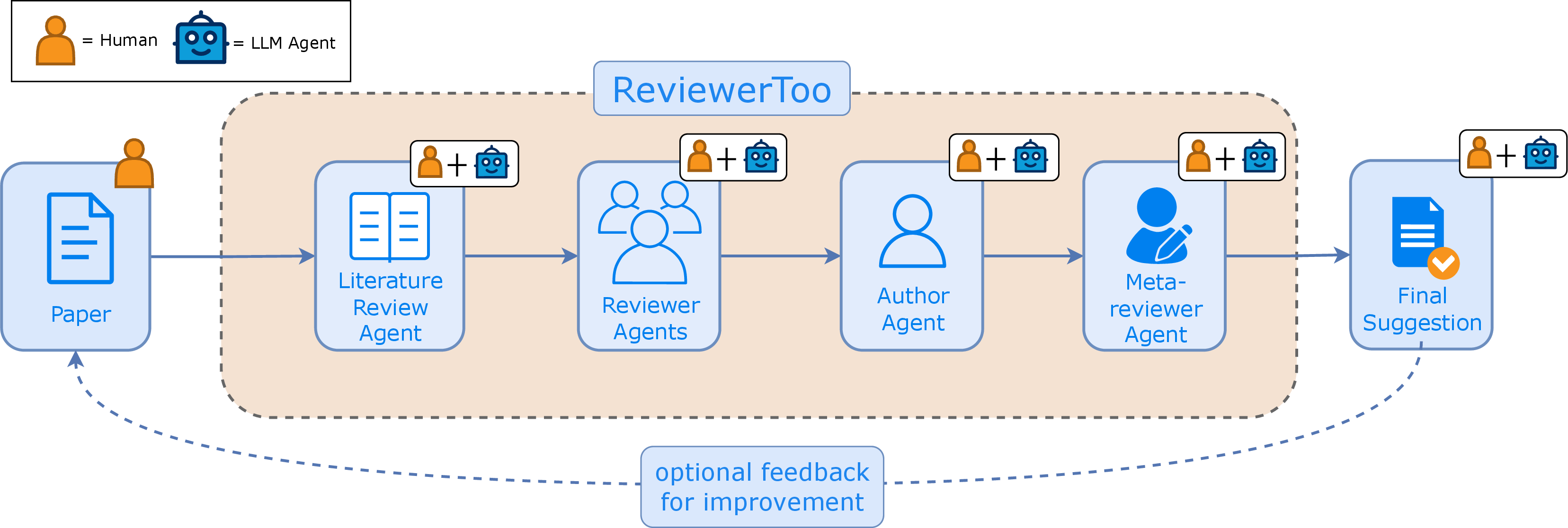
Figure 2: The ReviewerToo Framework. A paper passes through literature, reviewer, author, and meta-reviewer agents. The module design allows both humans and LLMs to participate at each stage, with optional feedback loops for iterative improvement.
Experimental Results
One of the critical results reported in the paper is the performance of the AI reviewers compared with human reviewers and other baselines. ReviewerToo achieves notable accuracy in the binary classification of accept/reject decisions and shows proficiency in generating high-quality textual reviews. Despite these strengths, the AI reviewers exhibit limitations similar to human reviewers, such as disagreement on nuanced decisions, which is quantitatively captured using metrics like Cohen's kappa.
Among notable results, the metareviewer that aggregates outputs from all personas demonstrated the highest accuracy and review quality, suggesting ensemble approaches can significantly stabilize and improve predictive fidelity.
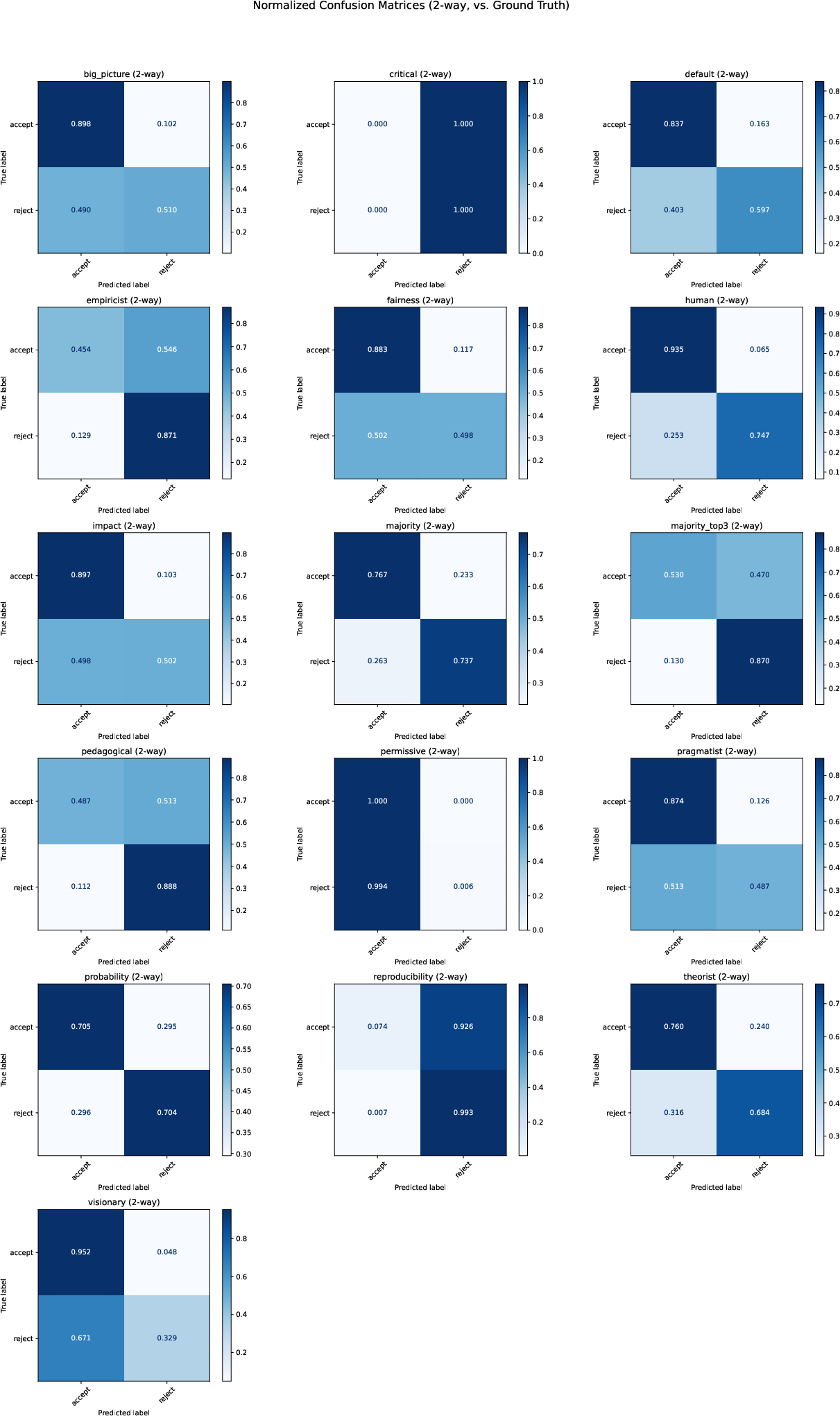
Figure 3: Confusion Matrices for binary Classification Task.
Implications and Future Work
The paper implications revolve around improving peer review processes by incorporating AI-driven assessments that enhance consistency and fairness while scaling with submission growth. The authors propose guidelines for integrating AI, emphasizing that AI should act as a complement to human judgment rather than a replacement. Structured protocols, ensemble methods, and systematic conditioning are prioritized to enhance both predictive and review quality.
Future work involves refining AI-assisted reviewers to address their limitations in evaluating theoretical contributions and enhancing their interpretability. There is additional interest in exploring how these systems can be ethically integrated into broader publishing workflows without diminishing the vital role of human evaluators.
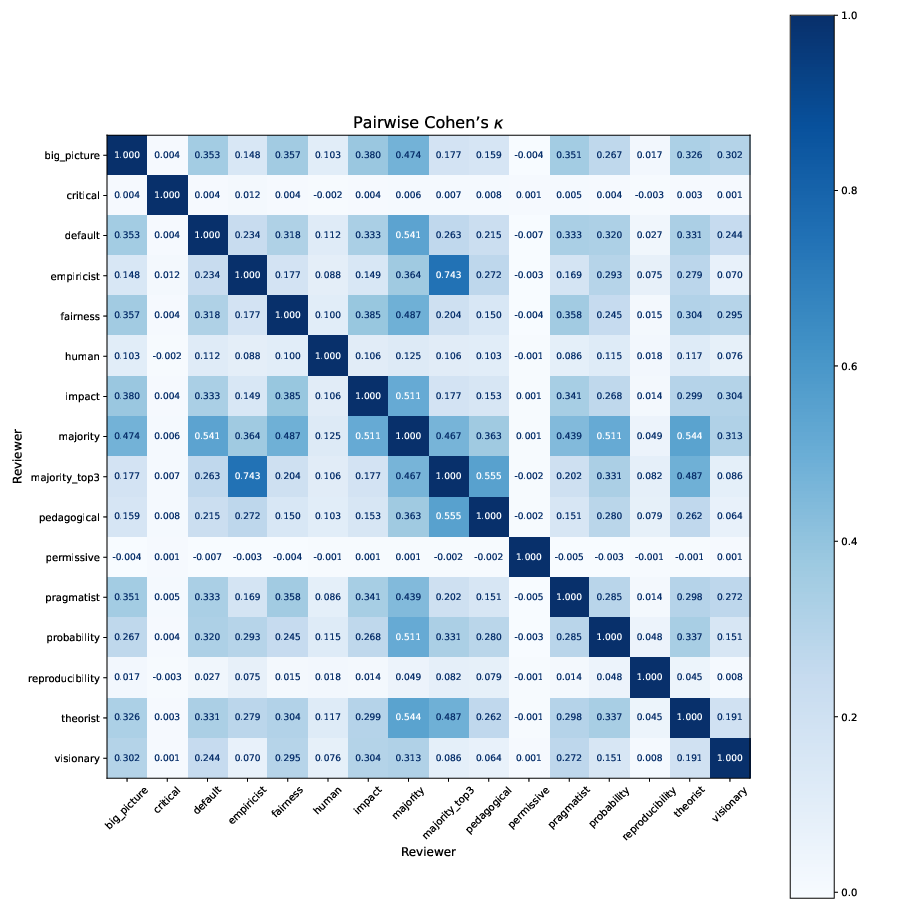
Figure 4: Pairwise Cohen's kappa for different types of reviewers.
Conclusion
The ReviewerToo framework marks an essential step towards adopting AI in peer review processes. By leveraging LLMs across diverse reviewer personas, the model demonstrates its potential to address the scalability and consistency challenges of human-only review systems. While AI reviewers have shown near-human levels of decision accuracy and have even surpassed human reviewers in generating constructive text, this work highlights the necessity of maintaining human oversight in complex evaluative judgments. The adoption of AI-assisted reviews should thus follow rigorous protocols ensuring fairness, reliability, and alignment with human reviewers' expertise.

