- The paper introduces TalkCuts, a dataset with 164K high-res multi-shot human speech clips annotated with 2D keypoints, 3D SMPL-X motion, and detailed textual descriptions.
- It employs a rigorous curation and annotation pipeline that includes camera shot classification and multimodal data processing to support dynamic video synthesis.
- The proposed Orator framework uses LLM-guided planning to orchestrate camera, motion, and audio instructions, achieving state-of-the-art results in long-form video generation metrics.
TalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Introduction and Motivation
The paper introduces TalkCuts, a large-scale, multimodal dataset specifically curated for multi-shot human speech video generation. Existing datasets for human video synthesis are predominantly limited to single-shot, static viewpoints and short-form content, which restricts the development of models capable of generating long-form, dynamic videos with realistic camera transitions and consistent speaker identity. TalkCuts addresses this gap by providing 164,000 clips (over 500 hours) of high-resolution (1080p) human speech videos, annotated with 2D keypoints, 3D SMPL-X motion, and detailed textual descriptions, spanning more than 10,000 unique speaker identities and a diverse range of camera shots.
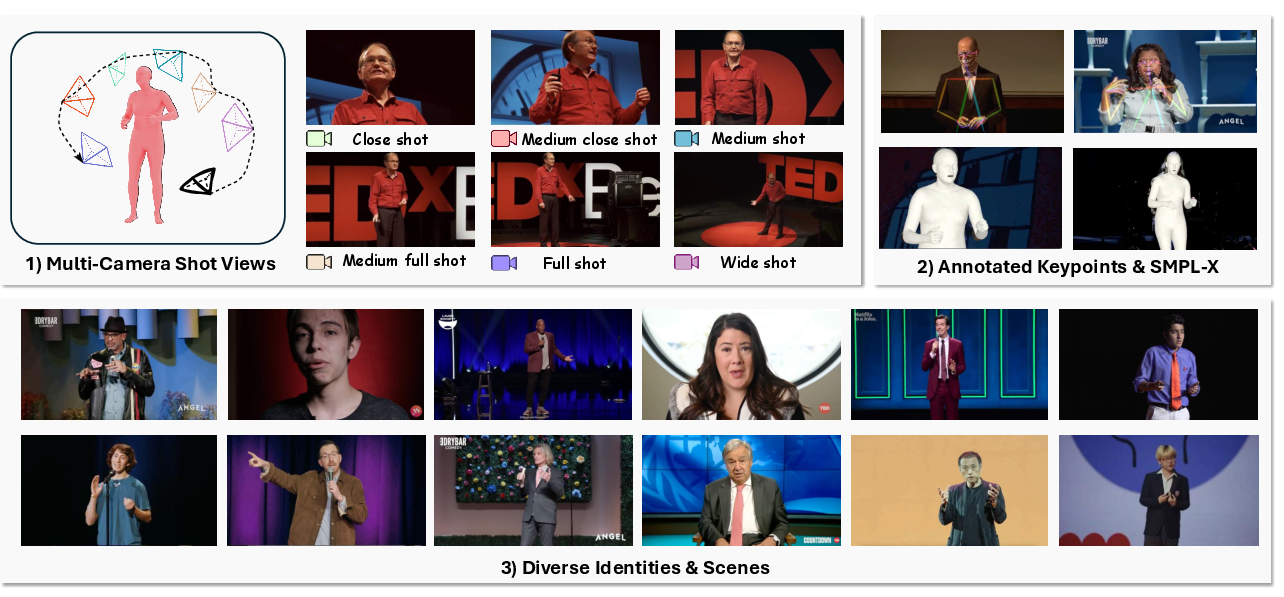
Figure 1: Overview of the TalkCuts Dataset, illustrating the diversity of camera shots, multimodal annotations, and speaker identities.
The dataset is sourced from real-world speech scenarios such as TED talks, talk shows, and stand-up comedy, ensuring coverage of varied demographics and environments. This comprehensive annotation enables robust multimodal learning and evaluation, facilitating research in controllable, multi-shot speech video generation.
Dataset Construction and Annotation Pipeline
Data Curation
TalkCuts employs a rigorous data curation pipeline:
- Collection: Copyright-free, high-resolution videos are crawled from YouTube using targeted keyword searches.
- Filtering: PySceneDetect segments videos into clips based on scene transitions. RTMDet is used for human detection, and DWPose estimates 133 whole-body keypoints. Clips with low-quality detection or multiple humans are discarded.
- Statistics: The final dataset comprises 164k clips, 57M frames, and 10k+ identities, with comprehensive coverage of camera shot types and speaker demographics.
Annotation
- Camera Shot Classification: Six shot types (CU, MCU, MS, MFS, FS, WS) are defined per cinematographic principles, annotated via analysis of visible body parts from 2D keypoints.
- 3D SMPL-X Motion: SMPLer-X estimates whole-body motion, refined for hand and facial details using HaMeR and EMOCA/DECA, yielding high-fidelity 3D motion sequences.
- Textual Descriptions: Qwen2.5-VL generates detailed descriptions for each clip, focusing on gestures, expressions, camera movements, and background context.
Orator: LLM-Guided Multi-Modal Video Generation Framework
To demonstrate the utility of TalkCuts, the paper presents Orator, an LLM-guided multi-modal video generation pipeline for long-form, multi-shot speech video synthesis.
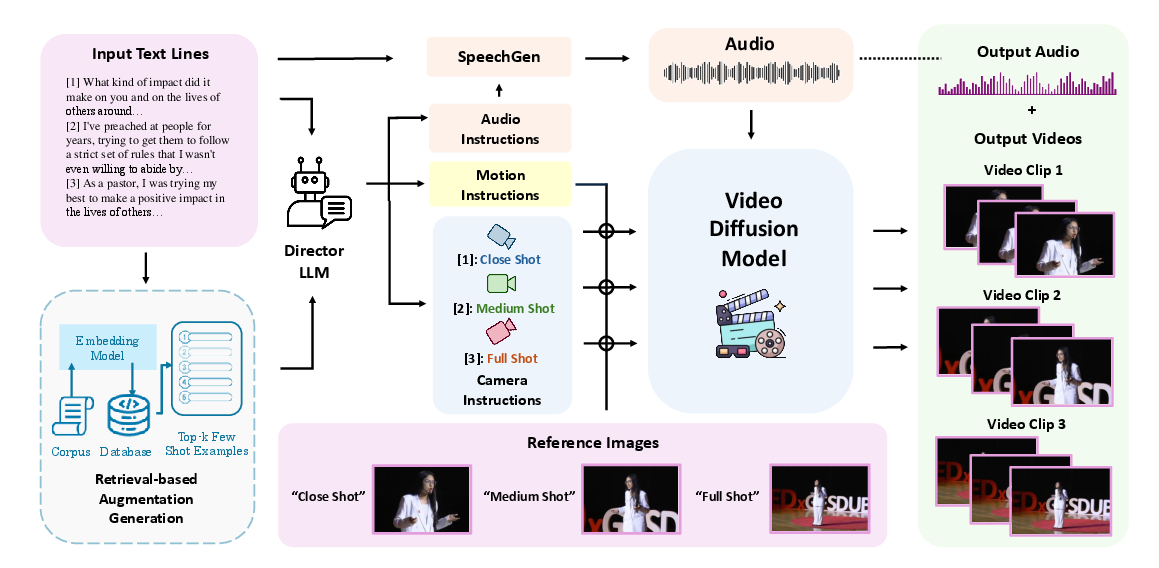
Figure 2: Orator pipeline, showing DirectorLLM's orchestration of camera, motion, and audio instructions for multi-modal video generation.
DirectorLLM
DirectorLLM acts as a multi-role director, orchestrating:
- Camera Shot Planning: RAG-based prompting with GPT-4o segments the input script into shot transitions, leveraging a corpus of annotated examples for context-aware planning.
- Motion Instruction: The LLM generates gesture and movement instructions aligned with speech content and emotional flow.
- Vocal Delivery: Fine-grained vocal instructions (intonation, pitch, pace, emotion) are produced, with sentence- and token-level controls for expressive speech synthesis.
Multi-Modal Generation Module
- SpeechGen: CosyVoice, instruction-finetuned for controllability, generates expressive speech audio synchronized with DirectorLLM's vocal instructions.
- VideoGen: Builds on CogVideoX and Hallo3 architectures, integrating reference images, audio, and motion instructions. Identity features are injected via a 3D VAE and refined with cross-attention using InsightFace embeddings. Audio-driven generation is conditioned on Wav2Vec speech embeddings. The final video is composed by concatenating clips generated for each shot segment.
Experimental Evaluation
LLM-Guided Camera Shot Transition
Shot planning accuracy is evaluated using IoU, Accuracy, and Shot Matching Accuracy (SMA). RAG-fewshot GPT-4o and fine-tuned LLaMA 3.1 outperform baselines, with GPT-4o selected for its superior IoU and SMA, indicating robust alignment between predicted and ground truth shot boundaries.
Audio-Driven Human Video Generation
Quantitative metrics include FID, FVD, PSNR, SSIM, LPIPS, SyncNet scores, and VBench metrics for subject/background consistency, dynamic degree, and motion smoothness. The Orator model trained on TalkCuts achieves the best or second-best scores across all metrics, outperforming SadTalker, EchoMimicV2, and Hallo3. Notably, Orator demonstrates strong lip-sync, natural gestures, and identity preservation, with significant improvements in motion quality and shot coherence.

Figure 3: Qualitative comparison of generated videos, highlighting Orator's superior visual fidelity, gesture realism, and shot transitions compared to baselines.
Pose-Guided Human Video Generation
Fine-tuning SOTA pose-driven models (Animate Anyone, MusePose, ControlNeXt) on TalkCuts yields substantial improvements in SSIM, PSNR, LPIPS, FID, FVD, and ArcFace distance. Animate Anyone excels in per-frame appearance but suffers from temporal inconsistency, while ControlNeXt achieves smoother motion but faces challenges in identity consistency. These results underscore the impact of high-quality, multi-shot data for advancing pose-guided video synthesis.
Implications and Future Directions
TalkCuts establishes a new benchmark for multi-shot, long-form human speech video generation, enabling research into dynamic camera work, multimodal control, and identity preservation. The modular Orator pipeline demonstrates the feasibility of LLM-guided, fine-grained video synthesis, with strong empirical results across diverse metrics and scenarios.
The dataset's scale and annotation richness facilitate the development of models capable of:
- Controllable video generation: Enabling explicit control over camera, motion, and audio modalities.
- Long-form synthesis: Supporting coherent transitions and consistent identity across extended video sequences.
- Multimodal learning: Advancing joint modeling of speech, gesture, and visual context.
Future research directions include:
- Improved motion-aware diffusion models: Addressing temporal coherence and fine-grained gesture synthesis across diverse camera perspectives.
- Hierarchical and compositional video generation: Leveraging LLMs for more sophisticated narrative and cinematographic planning.
- Generalization to conversational and multi-person scenarios: Extending the framework to support interactive and group speech video synthesis.
Conclusion
TalkCuts provides a comprehensive, large-scale resource for multi-shot human speech video generation, addressing critical limitations of prior datasets. The Orator pipeline, leveraging LLM-based planning and multimodal generation, sets a strong baseline for future research. Extensive experiments validate the dataset's utility in improving shot coherence, motion quality, and identity preservation. TalkCuts is poised to catalyze advances in dynamic, controllable human video synthesis and broader multimodal learning.

