Accelerating Inference for Multilayer Neural Networks with Quantum Computers
Published 8 Oct 2025 in quant-ph and cs.LG | (2510.07195v1)
Abstract: Fault-tolerant Quantum Processing Units (QPUs) promise to deliver exponential speed-ups in select computational tasks, yet their integration into modern deep learning pipelines remains unclear. In this work, we take a step towards bridging this gap by presenting the first fully-coherent quantum implementation of a multilayer neural network with non-linear activation functions. Our constructions mirror widely used deep learning architectures based on ResNet, and consist of residual blocks with multi-filter 2D convolutions, sigmoid activations, skip-connections, and layer normalizations. We analyse the complexity of inference for networks under three quantum data access regimes. Without any assumptions, we establish a quadratic speedup over classical methods for shallow bilinear-style networks. With efficient quantum access to the weights, we obtain a quartic speedup over classical methods. With efficient quantum access to both the inputs and the network weights, we prove that a network with an $N$-dimensional vectorized input, $k$ residual block layers, and a final residual-linear-pooling layer can be implemented with an error of $\epsilon$ with $O(\text{polylog}(N/\epsilon)k)$ inference cost.
The paper presents a fully coherent quantum framework that accelerates inference in ResNet-style architectures using fault-tolerant quantum computers.
It introduces a modular vector-encoding technique for efficient quantum matrix-vector arithmetic that maintains norm preservation and low circuit depth.
The approach achieves provable speedups under various QRAM regimes while delineating trade-offs between performance gains and practical QRAM feasibility.
Accelerating Inference for Multilayer Neural Networks with Quantum Computers
Overview and Motivation
This paper presents a modular framework for accelerating inference in multilayer neural networks using fault-tolerant quantum computers. The authors address the integration of quantum processing units (QPUs) into deep learning pipelines, focusing on fully coherent quantum implementations of classical architectures, specifically residual networks (ResNets) with multi-filter 2D convolutions, non-linear activations, skip connections, and layer normalizations. The work is situated in the context of quantum machine learning (QML), distinguishing itself from variational quantum algorithms (VQAs) by leveraging quantum subroutines for provable speedups in classical model inference.
Quantum Data Access Regimes and Architectural Guarantees
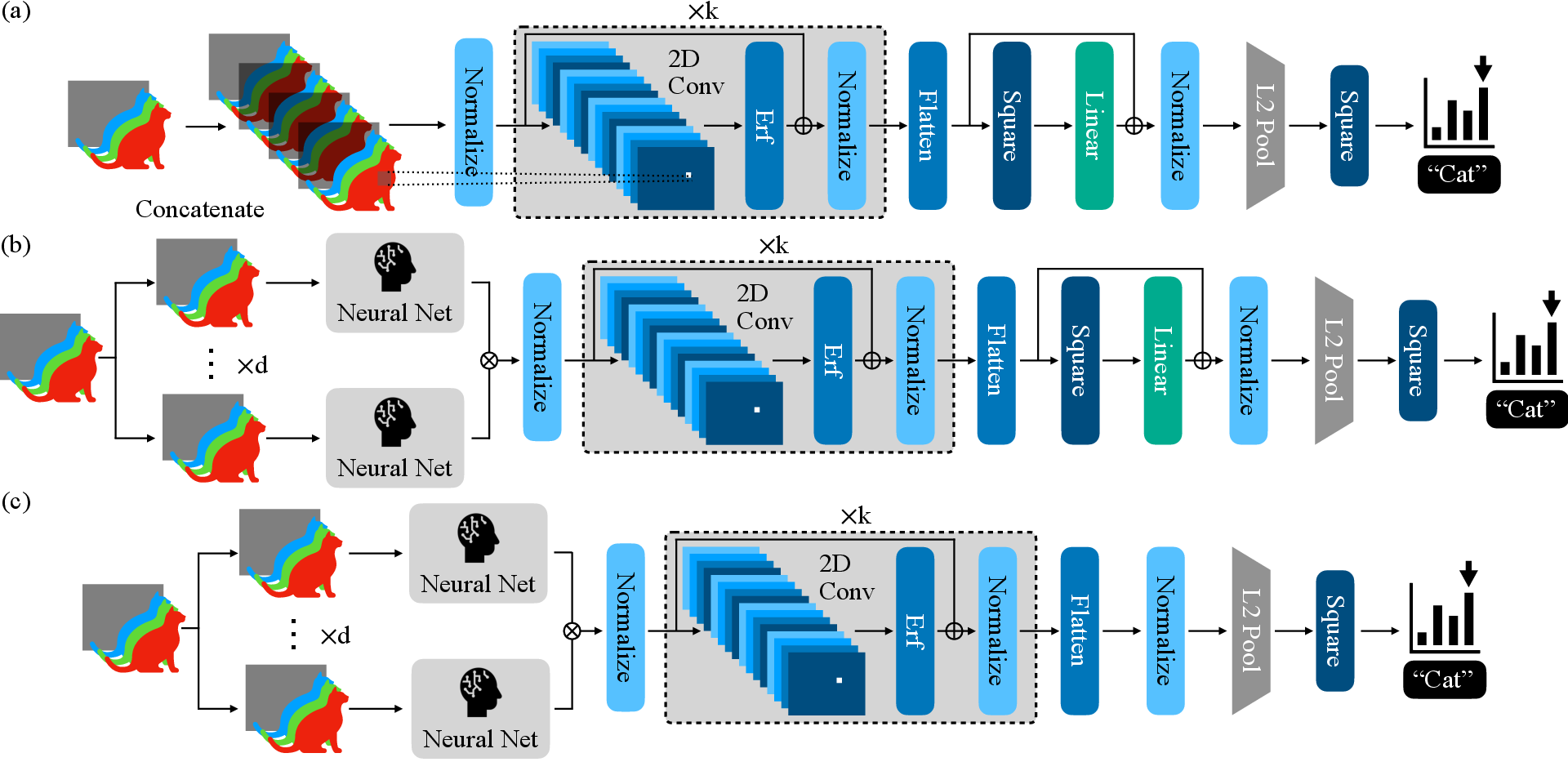
The paper rigorously analyzes inference complexity under three quantum data access regimes:
Regime 1 (Inputs and Weights via QRAM): Both the input and network weights are accessible through quantum random access memory (QRAM), enabling polylogarithmic inference cost in input dimension and error for k-layer networks.
Regime 2 (Weights via QRAM, Classical Input): Only the weights are accessible via QRAM; input loading incurs linear cost. This regime yields a quartic speedup for shallow bilinear-style networks.
Regime 3 (No QRAM): Neither inputs nor weights are provided via QRAM, but a quadratic speedup is still achieved for shallow architectures.
Figure 1: Architecture for Convolutional Neural Networks under three quantum data access regimes, illustrating the quantum complexity guarantees for inference.
The architectural blocks are designed to maintain coherence throughout the network, avoiding intermediate measurements or state tomography, which previously limited quantum speedups in multi-layer settings.
Quantum Matrix-Vector Arithmetic and Vector Encodings
A central technical contribution is the development of a modular vector-encoding (VE) framework for quantum matrix-vector arithmetic, extending block-encoding techniques. The VE framework enables:
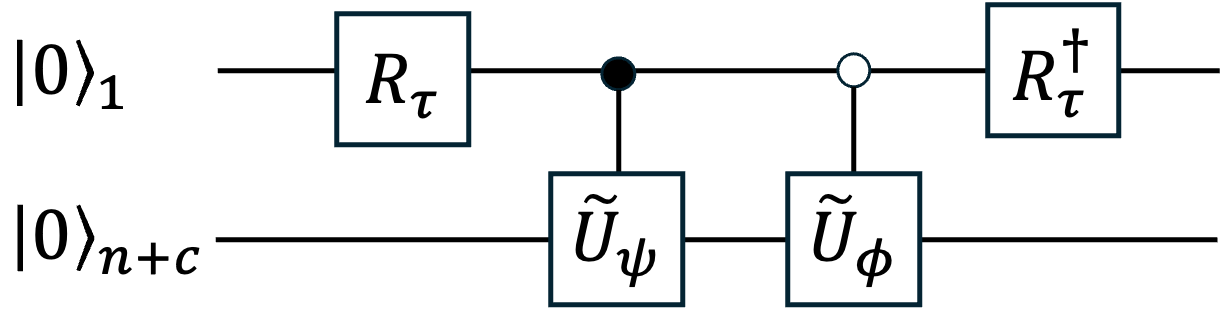
Vector Sums: Efficient quantum circuits for summing encoded vectors.
Matrix-Vector Products: Quantum implementation of arbitrary matrix-vector multiplication, with explicit norm tracking.
Tensor Products and Concatenations: Construction of high-dimensional encodings for bilinear and multi-path architectures.
A novel algorithm is introduced for multiplying arbitrary full-rank, dense matrices with the element-wise square of a vector, without Frobenius norm dependence—removing a key bottleneck in previous quantum linear algebra approaches.
Figure 2: Circuit for addition of VE encoded vectors, enabling efficient quantum vector arithmetic for neural network layers.
QRAM-Free Block-Encoding of 2D Multi-Filter Convolutions
The authors derive a QRAM-free block-encoding for 2D multi-filter convolutions, crucial for quantum implementation of convolutional layers. The construction leverages permutation and shift operators, block-encoding of basis projectors, and linear combination of unitaries (LCU) to encode the convolution operation efficiently, with circuit depth scaling polynomially in the number of channels and filter size (but with practical optimizations possible).
Coherent Quantum Implementation of Residual Blocks
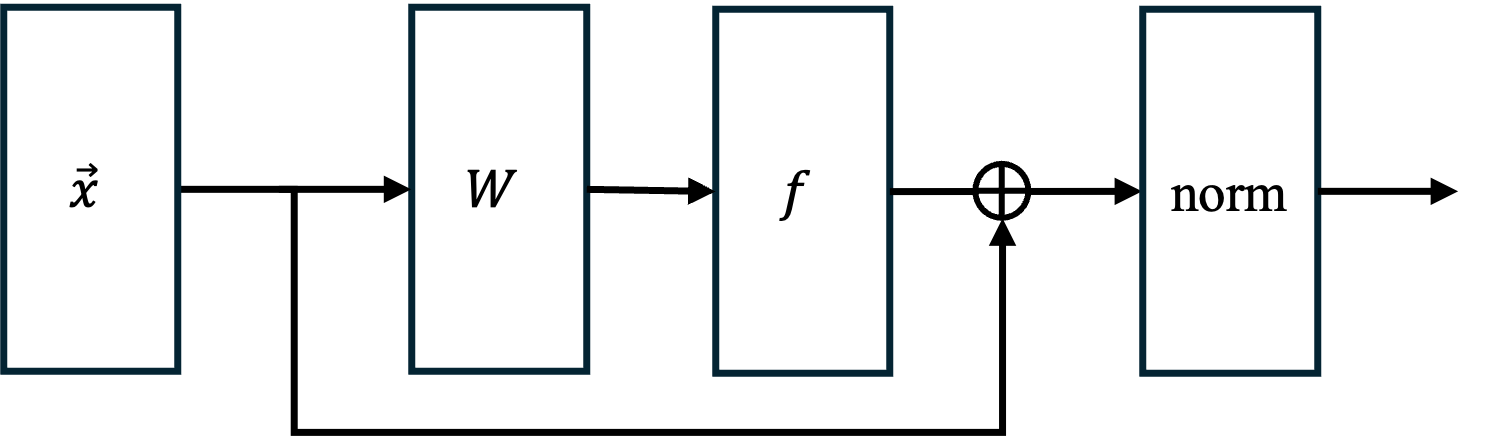
The paper provides the first fully coherent quantum implementation of multi-layer neural networks with non-linear activations. The residual block architecture is shown to be fundamental for norm preservation, which is critical for maintaining efficient quantum complexity across layers.
Figure 3: Generic Residual Architectural Block, illustrating the quantum implementation of skip connections, non-linear activations, and normalization.
The skip connection ensures that the norm of the encoded vector does not decay arbitrarily, preventing exponential blowup in circuit depth for deep networks. The authors prove that for k residual blocks, the overall circuit depth scales as O(log(N/ϵ)2k), where N is the input dimension and ϵ is the error tolerance.
End-to-End Quantum Complexity for Multilayer Architectures
The main theorem establishes that, under Regime 1, a network with k residual convolutional layers and a final full-rank linear pooling layer can perform inference with error ϵ in O(polylog(N/ϵ)k) circuit depth, using O(2kn) ancillary qubits. The output is a sample from a probability vector y~ within ϵ of the true output in ℓ2 norm.
Performance Metrics and Resource Requirements
Circuit Depth: Polylogarithmic in input dimension and error for constant k (Regime 1); quartic and quadratic speedups for Regimes 2 and 3, respectively.
Ancilla Qubits:O(2kn) for k layers, where n=log2N.
Error Propagation: Explicit bounds are provided for error accumulation through non-linear and pooling layers.
Resource Scaling: QRAM assumptions are critical for achieving exponential speedups; QRAM-free implementations still yield polynomial improvements.
Implementation Considerations
Quantum Data Structures: Efficient QRAM data structures are required for optimal performance; the feasibility of passive QRAM is discussed, with recent advances in distillation-teleportation protocols providing practical paths forward.
Non-Linearity:Quantum singular value transformation (QSVT) and polynomial approximations are used for non-linear activations, with circuit depth scaling in the degree of the polynomial.
Classical Preprocessing: One-time classical preprocessing is required for QRAM data structure construction and block-encoding parameter calculation.
Trade-offs and Limitations
Depth vs. Width: Quantum acceleration is most effective for wide, shallow networks due to exponential scaling in circuit depth with the number of non-linear layers.
QRAM Feasibility: The strongest speedups require QRAM; practical deployment depends on advances in quantum memory technology.
Dequantization: The final full-rank linear layer prevents known classical dequantization techniques from matching quantum speedups, but architectures without this layer may be dequantizable.
Implications and Future Directions
Theoretical implications include the demonstration that coherent quantum implementations of classical deep learning architectures are possible, with provable complexity guarantees. Practically, the framework enables quantum acceleration of inference for large-scale neural networks, contingent on QRAM feasibility. The techniques for norm preservation and modular vector encoding may inspire quantum-inspired classical algorithms.
Deep Architectures: Investigating whether sequences of non-linear transformations can be coherently enacted without exponential circuit depth.
Quantum-Inspired Algorithms: Translating norm-preservation and block-encoding techniques to efficient classical algorithms.
Scientific Computing Connections: Applying these quantum architectural blocks to quantum differential equation solvers and related domains.
Figure 4: Full-rank linear-pooling output block, enabling efficient quantum sampling from the final network output.
Conclusion
This work establishes a rigorous framework for accelerating inference in multilayer neural networks using quantum computers, providing the first fully coherent quantum implementations of classical architectures with non-linear activations and residual connections. The modular vector-encoding and block-encoding techniques enable efficient quantum arithmetic for deep learning, with explicit complexity guarantees under varying QRAM assumptions. The results highlight the importance of norm preservation and architectural design in quantum machine learning, and open avenues for both practical quantum deployment and quantum-inspired classical algorithm development.