- The paper presents a novel scalable data synthesis pipeline (InterCompose) that generates diverse two-person interactions from text descriptions.
- It introduces InterActor, a fine-grained text-to-interaction model with word-level conditioning and cross-attention to preserve semantic nuances.
- Experimental results on the InterHuman benchmark show state-of-the-art performance in R-Precision, FID, and multimodal distance, validating its effectiveness.
Text2Interact: High-Fidelity and Diverse Text-to-Two-Person Interaction Generation
Introduction and Motivation
Text2Interact addresses the challenge of generating realistic, semantically faithful two-person interactions from natural language descriptions. Unlike single-person motion synthesis, two-person interaction modeling requires not only plausible individual dynamics but also precise spatiotemporal coupling and nuanced text-to-motion alignment. Existing datasets for two-person interactions are limited in size and diversity, and prior models typically compress rich, structured prompts into single sentence embeddings, losing critical token-level cues. Text2Interact introduces a scalable data synthesis pipeline (InterCompose) and a fine-grained text-to-interaction model (InterActor) to overcome these limitations, achieving state-of-the-art results in fidelity, diversity, and generalization.
InterCompose: Scalable Two-Person Data Synthesis
InterCompose leverages LLMs to generate diverse two-person interaction descriptions, systematically combining coarse-grained themes and fine-grained tags to expand the behavioral coverage beyond existing datasets. Each interaction prompt is decomposed into two role-specific single-person descriptions using an LLM, which are then used to generate individual motions via a pretrained single-person text-to-motion generator (MoMask). To model inter-agent dependencies, a conditional diffusion model synthesizes the second agent’s motion conditioned on the first agent and the shared prompt, producing semantically aligned and physically coordinated interactions.
A two-stage filtering pipeline ensures the quality and diversity of the synthesized data. First, a contrastive encoder projects text and motion into a shared embedding space, discarding samples with low text-motion alignment. Second, distributional filtering retains samples that are novel yet close to the real data distribution, based on Euclidean distances in the motion embedding space. This approach yields a synthetic dataset with both semantic fidelity and distributional diversity, significantly enhancing the training corpus for two-person interaction modeling.
InterActor: Fine-Grained Text-to-Interaction Generation
InterActor introduces a word-level conditioning architecture, enabling each motion token to attend to individual word tokens from the prompt via cross-attention. This preserves nuanced semantic cues such as initiation, response, and contact ordering, which are essential for faithful text-to-motion alignment. The model alternates between word-level conditioning and motion-motion interaction blocks, the latter comprising self-attention (intra-agent context) and cross-attention (inter-agent dependencies), ensuring both agents respond adaptively to the linguistic description and each other’s dynamic behavior.
An adaptive interaction loss supervises pairwise distances between inter-agent joint pairs, with higher weights for spatially proximate joints. This loss function enforces physical plausibility and semantic adherence, outperforming flat-weighted baselines in capturing fine-grained interaction semantics.
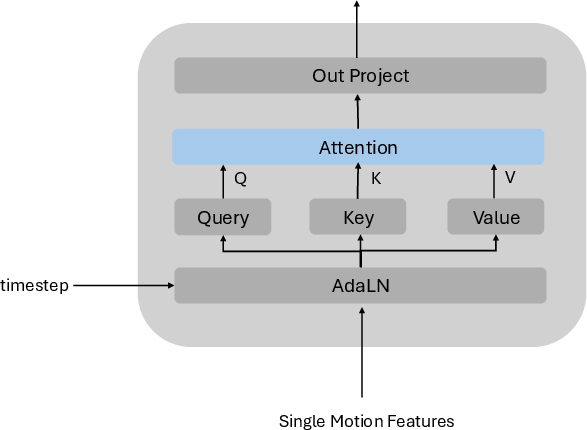
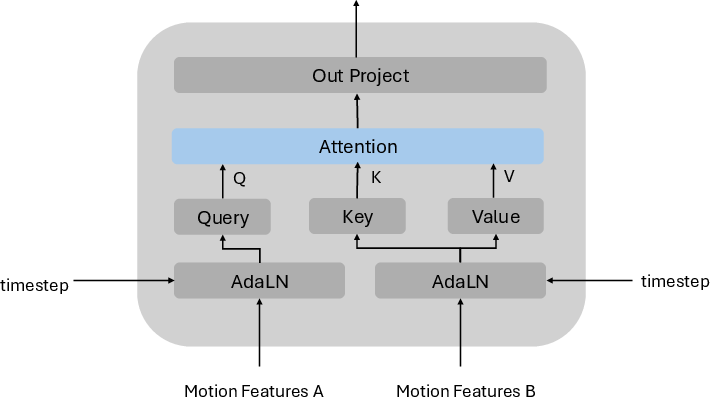
Figure 1: Illustration of the Self-Attention module in the Motion-Motion Interaction Block, enabling intra-agent temporal context modeling.
Experimental Results
Text2Interact is evaluated on the InterHuman benchmark, using metrics such as R-Precision, FID, Multimodal Distance, Diversity, and Multimodality. InterActor achieves state-of-the-art R-Precision across all top-k metrics, surpassing previous models (e.g., InterMask) by a significant margin. It also attains the best Multimodal Distance and competitive FID, with the latter within the confidence interval of the previous best, indicating comparable generation quality but superior text-to-motion alignment.
Ablation studies confirm the effectiveness of each component: word-level conditioning, adaptive interaction loss, and synthetic data fine-tuning all contribute to improved performance. Notably, fine-tuning on filtered synthetic data enhances generalizability, as evidenced by improved FID and user preference studies.
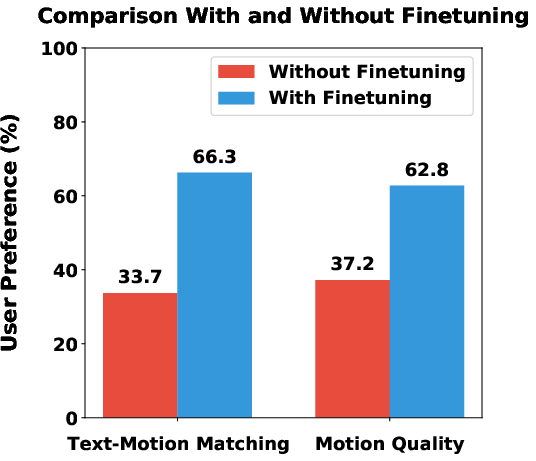
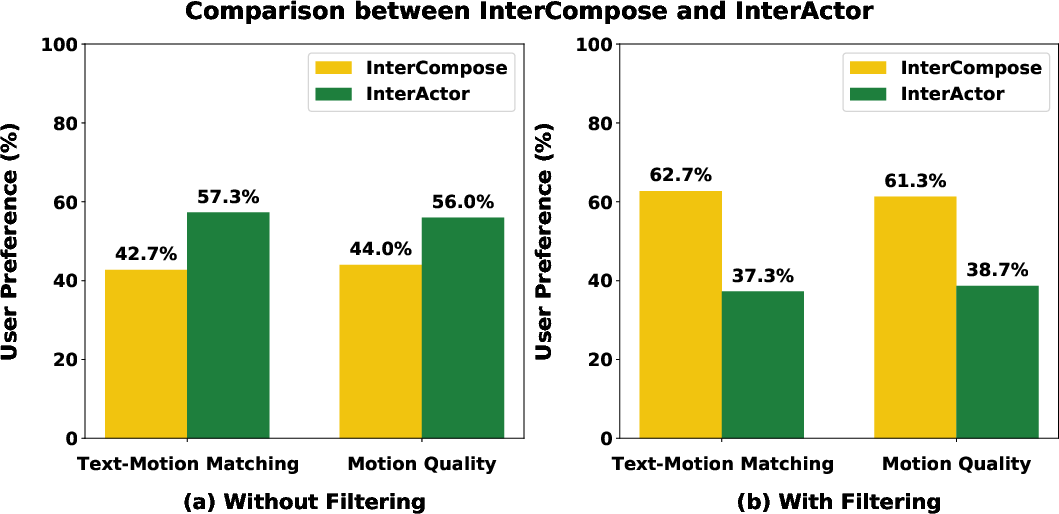
Figure 2: User preference study results of InterActor with and without fine-tuning on synthetic data, demonstrating improved generalizability and text-motion alignment.
Qualitative comparisons show that InterActor produces more plausible and text-faithful interactions, with higher robustness to implausible poses compared to InterMask. Synthetic data generated by InterCompose covers underrepresented regions in the motion embedding space, further increasing diversity.
Implementation Details
InterActor consists of 12 interleaved attention and word-level conditioning blocks, using a frozen CLIP-ViT-L/14 encoder for text. Training employs 8 NVIDIA A100 GPUs, 200k steps, and a batch size of 16. The diffusion model uses 1,000 steps with a cosine noise schedule and classifier-free guidance. Filtering thresholds and embedding distances are empirically tuned for optimal data quality and diversity.
Limitations and Future Directions
While Text2Interact achieves strong fidelity and semantic alignment, it does not explicitly enforce physical plausibility, occasionally resulting in artifacts such as floating or ground penetration. Incorporating physics priors and constraints is a promising direction for future work. Additionally, extending the synthesis framework to learn directly from video data could further enhance diversity and realism.
Conclusion
Text2Interact establishes a new state-of-the-art in text-to-two-person interaction generation by combining scalable data synthesis (InterCompose) and fine-grained word-level conditioning (InterActor). The framework demonstrates superior fidelity, diversity, and generalization, validated by quantitative metrics, ablation studies, and user evaluations. The approach provides a robust foundation for future research in controllable, high-fidelity human interaction modeling, with potential applications in animation, virtual reality, and embodied AI.

