- The paper introduces a Relational Transformer that tokenizes every database cell with its value, column, and table name for uniform processing.
- It employs specialized relational attention layers (column, feature, neighbor, and full) to capture complex dependencies for zero-shot and fine-tuning tasks.
- Experimental results show RT’s efficiency, achieving 94% of supervised AUROC on classification with a lightweight 22M parameter model.
Introduction
The Relational Transformer (RT) architecture addresses the challenge of developing models that can generalize across diverse relational datasets without task- or dataset-specific fine-tuning. Unlike typical sequence models, relational databases consist of interconnected tables with diverse schemas and dependencies. RT exploits this structure via a novel attention mechanism and a pretraining approach that enables zero-shot learning capabilities.
Core Components and Innovations
Input Representation and Tokenization:
RT represents every database cell as a token, encoded with its value, column name, and table name. This tokenization allows relational data to be treated uniformly across various tasks via masked token prediction (MTP). Task-specific context is incorporated with the formation of "task tables," facilitating seamless zero-shot predictions.
Relational Attention Mechanism:
RT employs a unique attention mechanism that includes:
- Column Attention: Models value distributions within columns.
- Feature Attention: Mixes information across cells in the same row and their parent rows (F→P links).
- Neighbor Attention: Aggregates information from P→F linked rows analogous to message-passing in GNNs.
- Full Attention: Allows unrestricted pairwise interactions to confer flexibility and robustness.
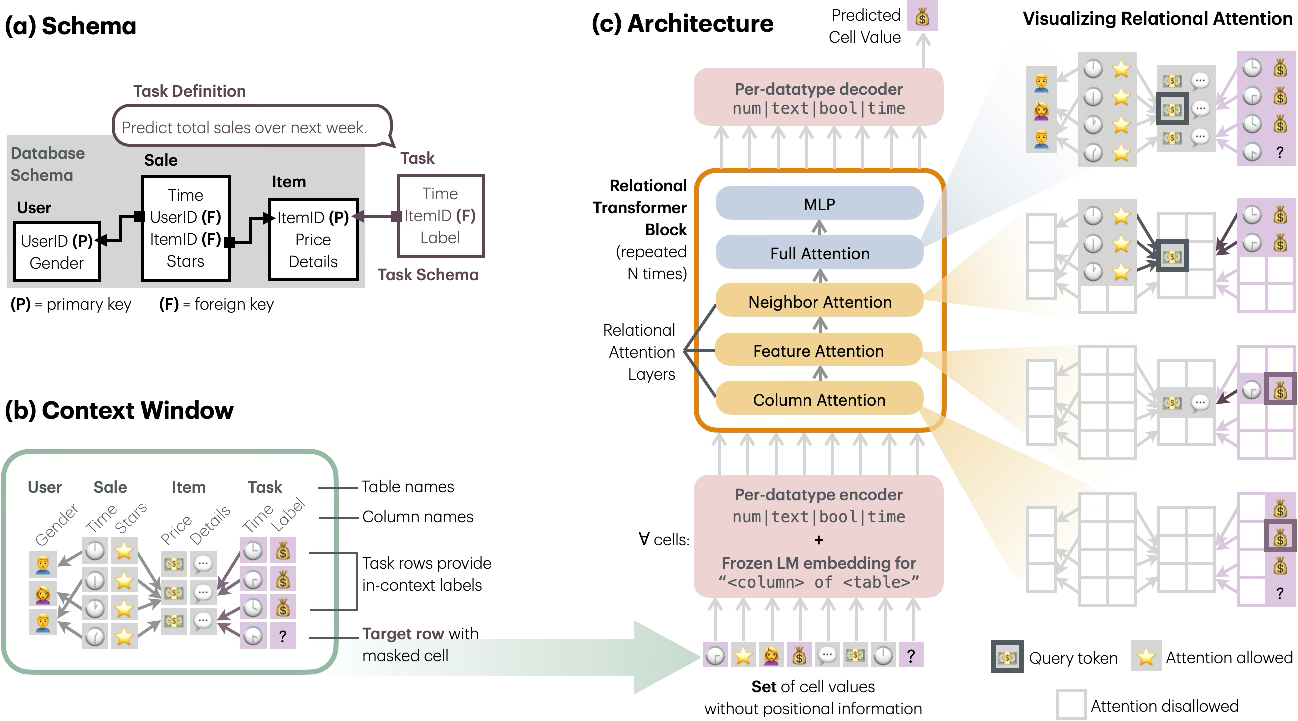
Figure 1: Schema illustrates tables, columns, and relational attention layers capturing column, feature, and neighbor dependencies.
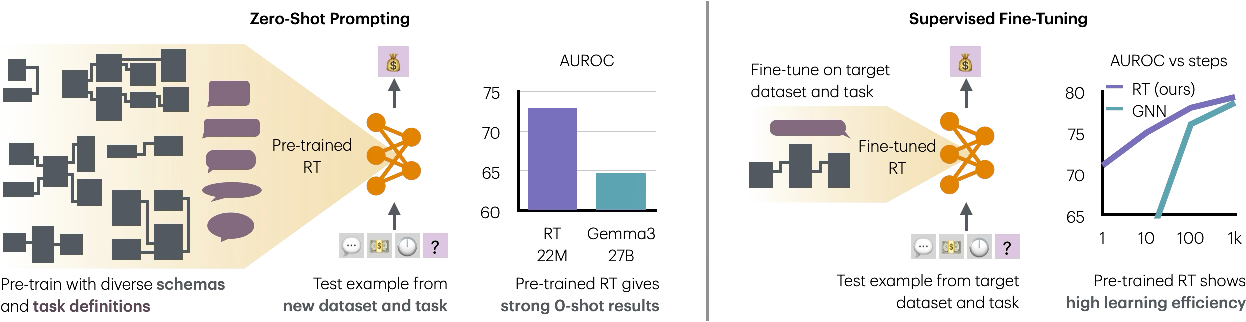
Figure 2: RT’s pretraining on diverse schemas demonstrates robust zero-shot capabilities and high sample efficiency in fine-tuning.
Pretraining Strategy
RT is pretrained on a spectrum of relational databases from RelBench, covering tasks like churn prediction and sales forecasting. The pretraining employs masked token prediction, achieving an average of 94% of the fully supervised AUROC on classification tasks using a lightweight 22M parameter model.
Zero-Shot and Fine-Tuning Capabilities:
The architecture's robustness stems from its ability to understand schema semantics and relational patterns, securing superior zero-shot capabilities. Additionally, RT offers rapid adaptation through fine-tuning, surpassing traditional architectures like 27B LLMs in efficiency and performance.

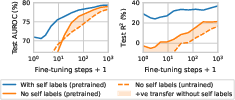
Figure 3: Learning curves during fine-tuning show RT’s superiority in sample efficiency compared to other models.
Experimental Results
RT boasts exceptional zero-shot performance, attributing much of its success to self-label dynamics and relational attention patterns. Experimentation reveals that:
Implementation Considerations
Computational Requirements:
The RT model’s efficient design requires fewer computational resources, making it feasible to train and deploy in various computational environments without the massive resources typical for LLMs.
Limitations and Future Work:
RT currently does not support recommendation tasks or link predictions directly. Future enhancements could integrate primary-key and foreign-key names to enrich semantic understanding further.
Conclusion
The Relational Transformer exemplifies an approach to generalized relational modeling, emphasizing zero-shot learning with strong foundational capabilities. Its design harmonizes with the relational structure of databases, enabling both robust initial predictions and efficient fine-tuning. This framework signifies a pivotal advancement in the journey towards universal relational data models.