GLVD: Guided Learned Vertex Descent
Abstract: Existing 3D face modeling methods usually depend on 3D Morphable Models, which inherently constrain the representation capacity to fixed shape priors. Optimization-based approaches offer high-quality reconstructions but tend to be computationally expensive. In this work, we introduce GLVD, a hybrid method for 3D face reconstruction from few-shot images that extends Learned Vertex Descent (LVD) by integrating per-vertex neural field optimization with global structural guidance from dynamically predicted 3D keypoints. By incorporating relative spatial encoding, GLVD iteratively refines mesh vertices without requiring dense 3D supervision. This enables expressive and adaptable geometry reconstruction while maintaining computational efficiency. GLVD achieves state-of-the-art performance in single-view settings and remains highly competitive in multi-view scenarios, all while substantially reducing inference time.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about building a detailed 3D model of a person’s face from just one or a few photos. The authors introduce a method called GLVD (Guided Learned Vertex Descent) that can quickly reconstruct a realistic 3D face without being stuck to a “one-size-fits-all” face template. It combines two kinds of clues: local image details (like edges and textures in the photo) and global face structure (like where the eyes, nose, and mouth are in 3D).
What questions were they trying to answer?
In simple terms, the paper asks:
- How can we turn one or a few regular photos into an accurate 3D face?
- Can we avoid relying on fixed face templates that make unusual faces look too “average”?
- Can we keep the method fast, accurate, and robust even when we don’t have many photos?
How does their method work?
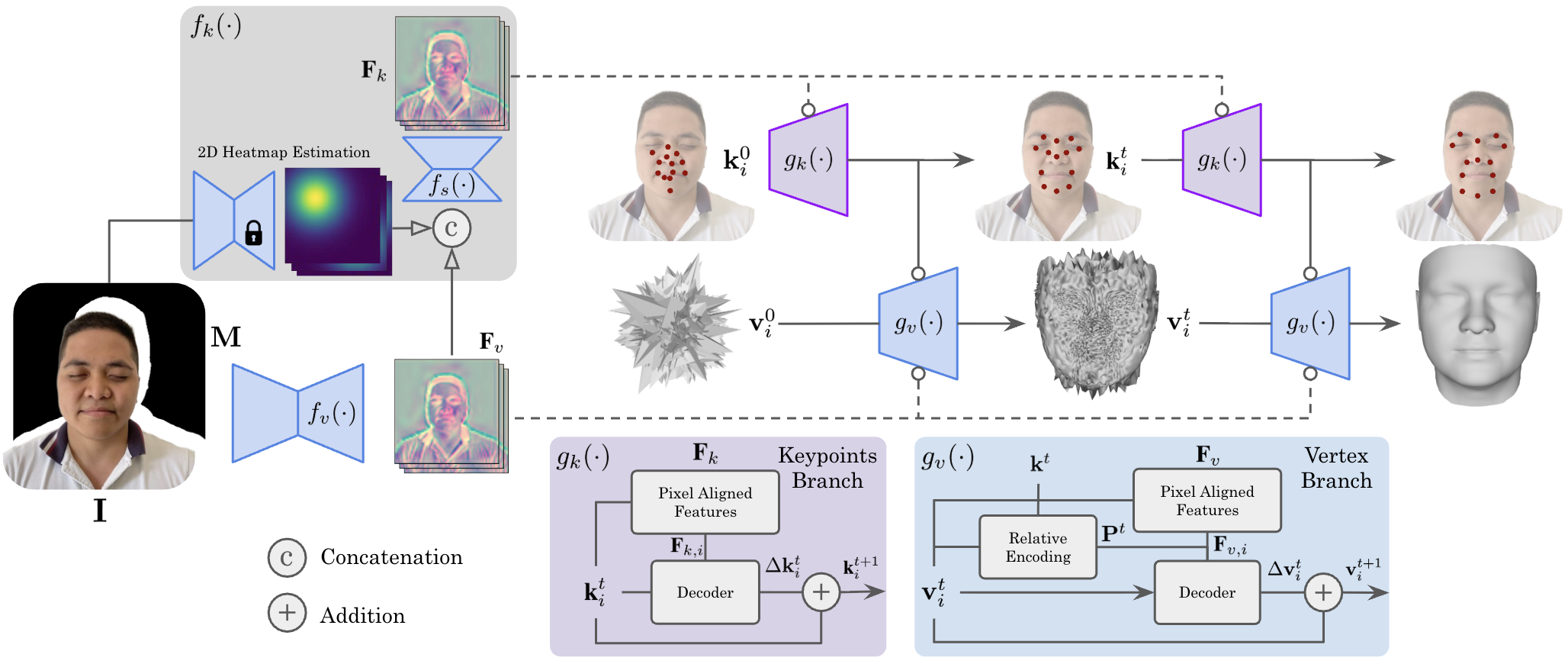
The idea in simple terms
Imagine a face mesh like a fishing net wrapped around a head. The net’s knots are the “vertices.” If you place this net roughly over a face, you can nudge each knot a little until the net matches the person’s real 3D face. GLVD learns how to make these nudges by looking at the photos and by keeping track of a few important “landmarks” on the face.
- Vertices: the net’s knots that define the face surface.
- Keypoints (landmarks): special spots like the nose tip, eye corners, and mouth corners that give the face its overall structure.
GLVD moves each vertex bit by bit (iteratively), like a sculptor carefully refining a clay model. It uses:
- Local clues: image features right under where a vertex projects onto the photo (edges, shading, textures).
- Global guidance: distances and directions from each vertex to a small set of keypoints, which keeps the whole face shape consistent.
Two branches that work together
GLVD has two main parts (branches) that run in steps:
- 3D Keypoint Branch
- Starts by guessing where keypoints should be in 3D.
- Looks at the photo(s) to adjust these keypoints so they align with the person’s actual face.
- Think of it like figuring out where the “anchors” (eyes, nose, mouth corners) are in 3D space.
- 3D Vertex Branch
- For every vertex (knot) in the face mesh, it samples local image features from the photo(s).
- It also encodes where that vertex is relative to the keypoints (e.g., “How far and in what direction am I from the nose tip, eyes, mouth?”).
- Using these clues, it predicts a small 3D movement (a “nudge”) for the vertex.
- This happens repeatedly, gradually improving the shape.
This “relative encoding” (measuring each vertex relative to keypoints) is crucial. It reduces confusion and helps all parts of the face move coherently, not just locally.
Training tricks that make it robust
To make the system reliable and fast:
- It adds small, random noise to keypoints during training, so the model learns to be stable even if keypoints are a bit off.
- It uses a loss that balances direction and size of the predicted movements, helping vertices move the right way and by the right amount.
- It lightly “drops out” some image features during training so the model doesn’t over-rely on any single clue.
- It pre-trains part of the network to understand 3D shape better (by predicting signed distances), which speeds up learning.
What did they find?
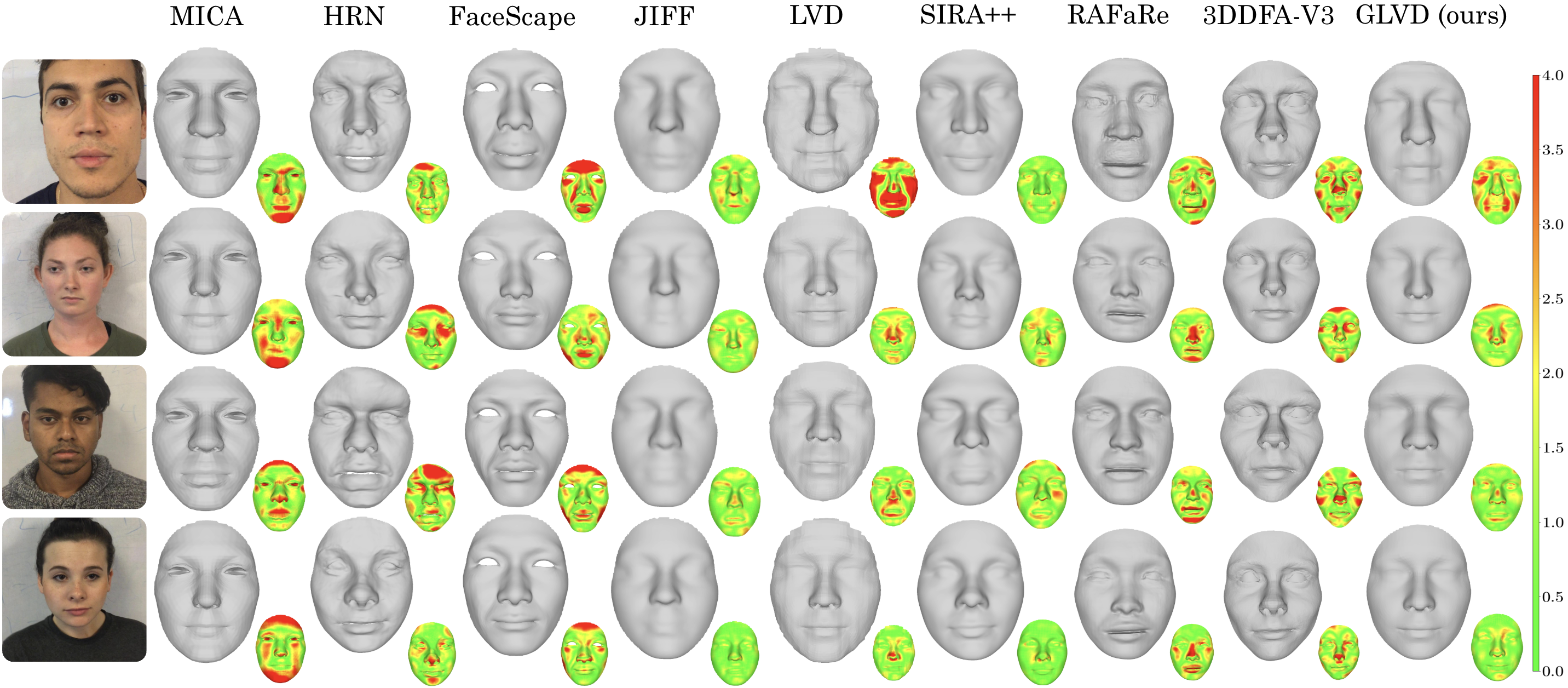
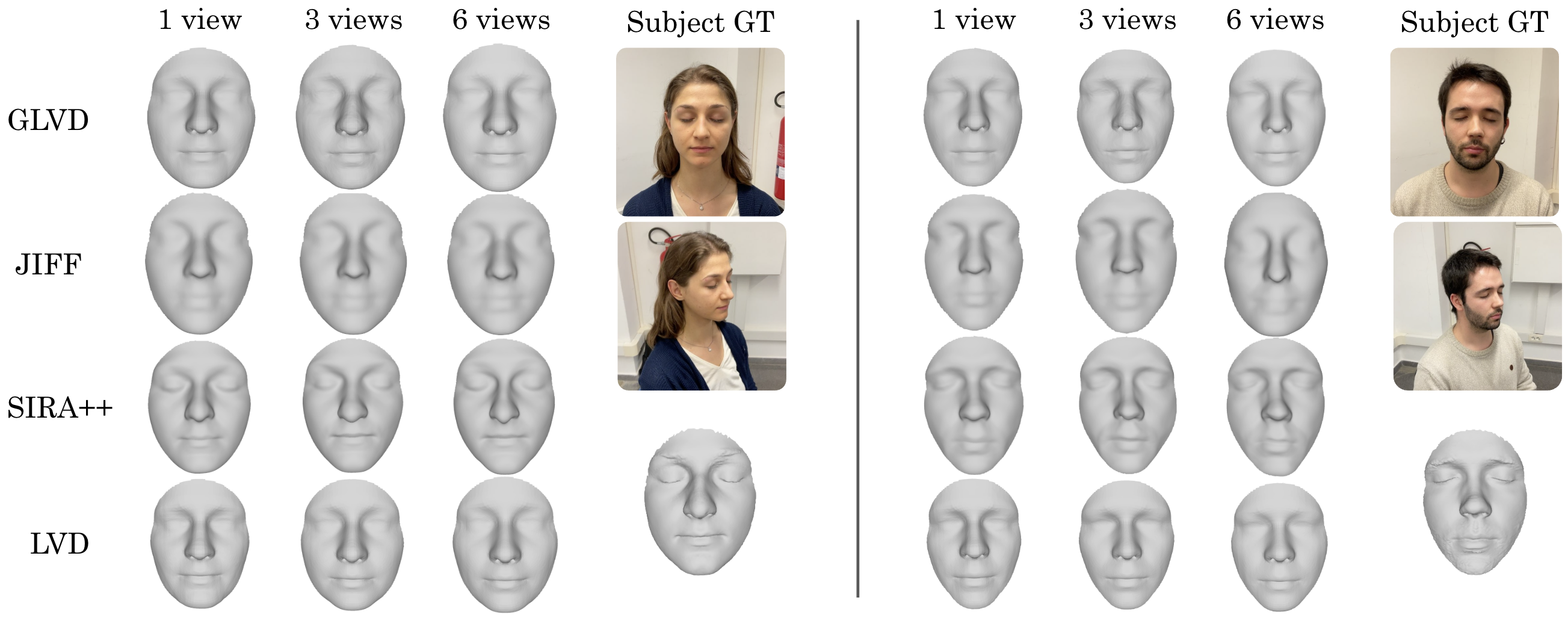
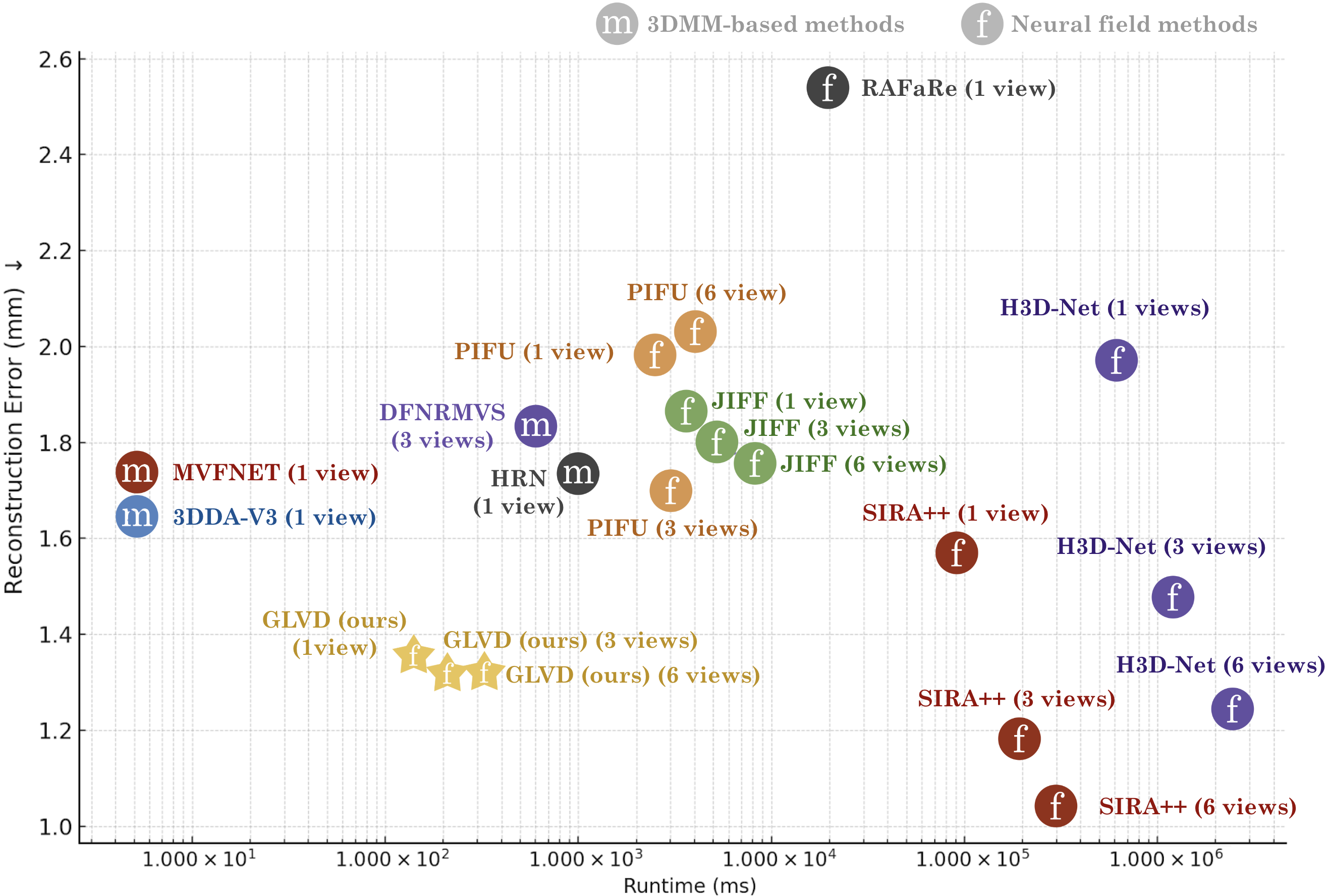
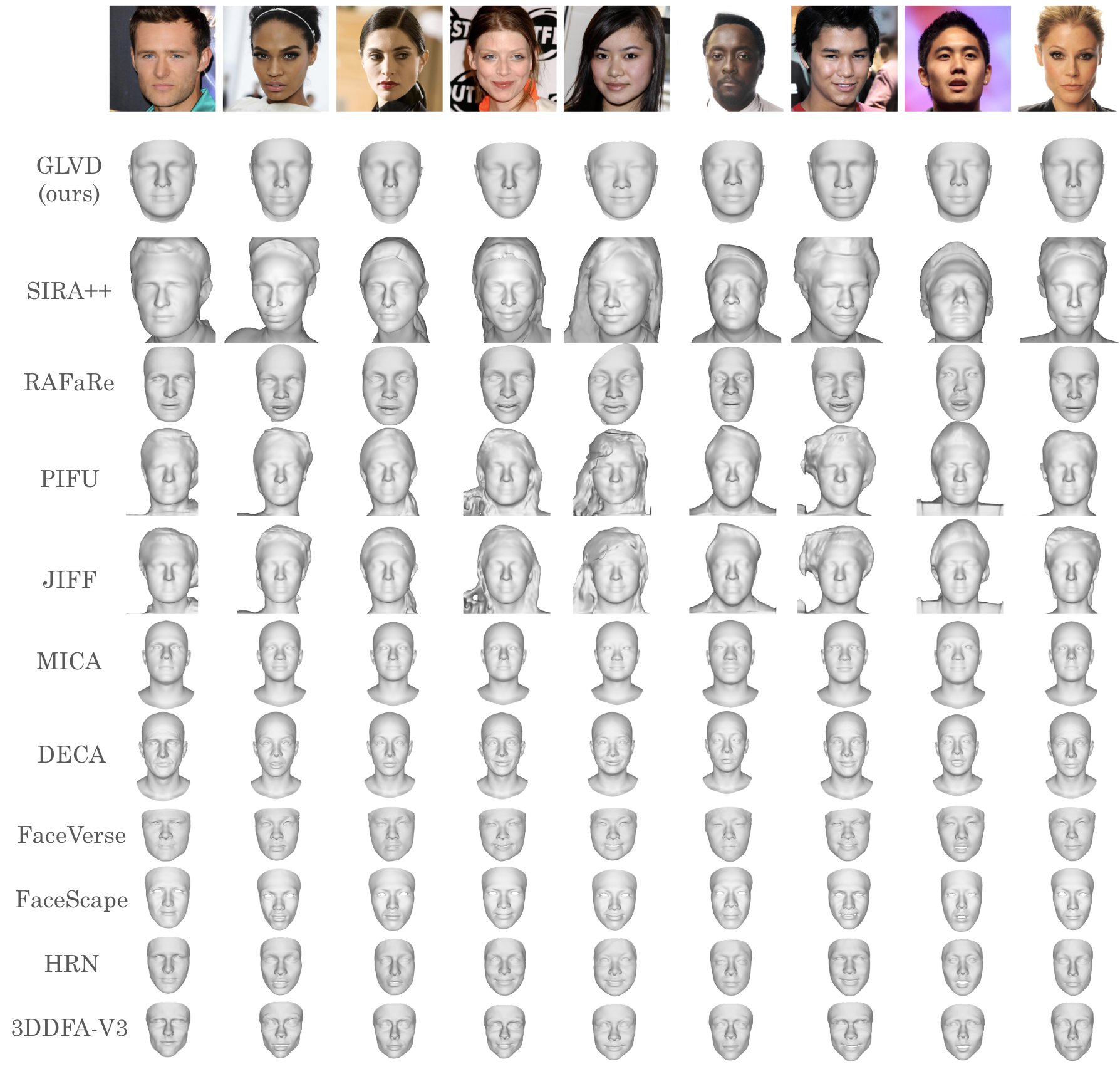
- Accuracy: On standard benchmarks, GLVD achieves state-of-the-art results for single-photo 3D face reconstruction and is very competitive when using multiple photos.
- For example, on the 3DFAW dataset with a single image, its average surface error is about 1.25 mm, which is better than other compared methods.
- Speed: It’s fast at test time (around 0.2 seconds with one image), much faster than traditional “optimize-until-it-fits” methods that can take many seconds or minutes.
- Flexibility: Because it doesn’t depend on a fixed face template model, it can capture more unique shapes and fine details, instead of pushing faces toward an average look.
- Design insights:
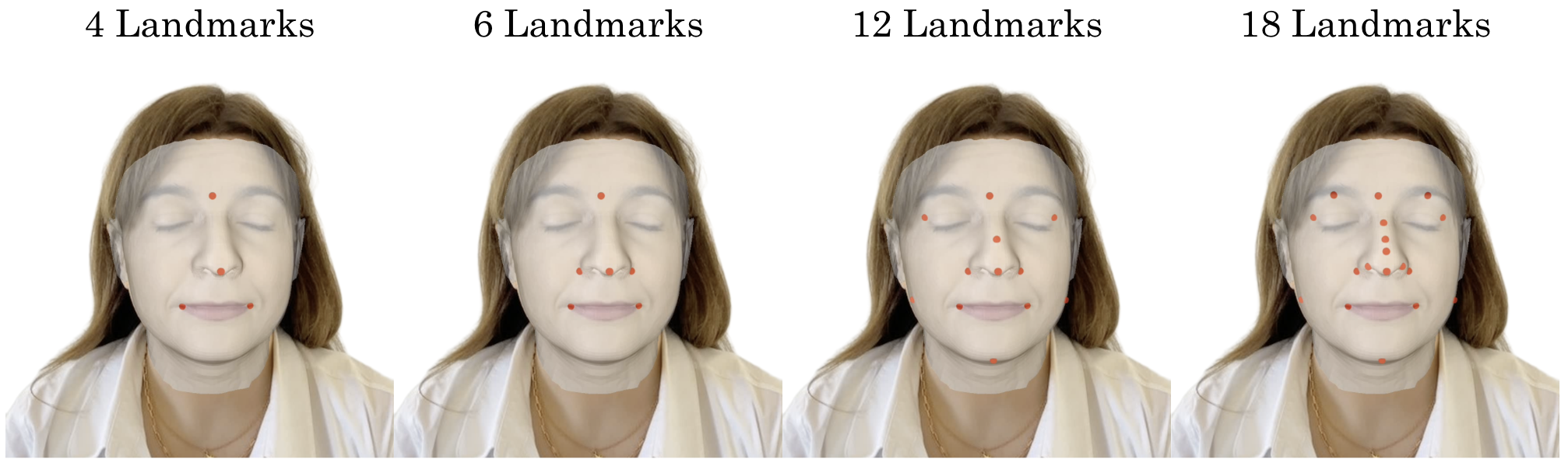
- Using a small, well-chosen set of keypoints works best (too few or too many hurts).
- Encoding each vertex relative to keypoints (using displacement vectors) works better than simple concatenation or global attention.
- Adding training noise, using facial heatmaps, and the special loss design all improve stability and accuracy.
Why does this matter?
- Fewer photos, better results: GLVD can make a good 3D face from just one image, which is useful for everyday apps where multiple photos aren’t available.
- Real-world uses: This helps in AR/VR (try-on filters, avatars), movies and games (fast character creation), telepresence, and even healthcare (face shape analysis), because it’s fast and accurate.
- More expressive faces: By avoiding overly strict template models, GLVD can better represent the uniqueness of different faces.
- Practical pipelines: The output is a clean, structured mesh that is easier to animate and render than some other representations that require heavy post-processing.
Limitations and future directions
- It can struggle with occlusions (like hands or hair covering the face) and depends on good keypoint estimates.
- Future work could add stronger facial expression modeling, improve handling of occlusions, and enforce consistency over time for videos.
In short, GLVD is like a smart, fast sculptor: it uses both close-up details and big-picture landmarks to quickly turn a single photo (or a few) into a realistic 3D face, without forcing everyone’s face into the same template.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future research.
- Clarify and rigorously evaluate input requirements: the paper alternates between “RGB-only” and “RGB+head mask+calibrated camera” assumptions; quantify performance differences and sensitivity to missing/inaccurate masks and camera parameters (single- and multi-view).
- Robustness to occlusions, accessories, and extreme expressions is acknowledged as a limitation; design controlled benchmarks (e.g., synthetic occlusions, glasses, hair coverage, masks) and quantify failure modes by region (jawline, nose, mouth, periocular).
- Reliance on a frozen 2D landmark detector (HRNet): assess how keypoint quality affects reconstruction; compare alternative detectors/priors (dense face parts, segmentation, 3D landmarks), and study end-to-end training to reduce dependency.
- Keypoint selection strategy is fixed and template-dependent; investigate data-driven or adaptive keypoint discovery, cross-template portability (FLAME, SMPL-X), and the effect of number/placement of keypoints on accuracy and stability across identities.
- Keypoint uncertainty is modeled only via training-time Gaussian noise; add test-time uncertainty estimation, confidence-weighted encodings, robust losses, and mechanisms to detect and compensate for mispredicted keypoints.
- The mesh topology is fixed (7,225 vertices); evaluate topology-adaptive variants, remeshing/refinement at higher resolution, and coverage of non-facial structures (ears, hairline, teeth) to approach full-head reconstruction.
- No explicit expression/animation model is provided; measure performance on dynamic sequences and extreme expressions, and explore integrating blendshapes, muscle models, or learned expression bases with temporally consistent updates.
- Multi-view fusion is a simple mean aggregation at a specific network layer; compare attention-based, visibility-aware, confidence-weighted, and transformer-based cross-view fusion, and analyze scalability as the number of views increases.
- Convergence and stability lack theoretical guarantees; study the impact of step count, displacement clipping schedules, and (non-)encoding of iteration index on convergence, with diagnostics for divergence and early stopping.
- Evaluation metrics are limited to unidirectional Chamfer distance; add symmetric Chamfer, normal/curvature errors, landmark error (3D), per-region metrics, mesh quality checks (self-intersections, manifoldness), and perceptual studies.
- Generalization and fairness are untested beyond a proprietary 10k-scan training set; perform cross-dataset evaluations (e.g., in-the-wild, varied lighting), quantify demographic biases, and release standardized evaluation protocols.
- Reproducibility is constrained by proprietary data and unspecified code/model release; provide training seeds, full hyperparameters, data splits, ablation scripts, and report memory/runtime scaling with vertices, keypoints, and views.
- Feature encoder pretraining uses an SDF head; quantify its contribution vs alternatives (photometric/differentiable rendering, BRDF/shading priors), and test combinations to improve fine-detail recovery.
- Initialization choices are under-specified (keypoints start uniformly; vertex initialization not detailed); analyze how initialization affects convergence and accuracy, and explore learned initializations or coarse predictors.
- View aggregation point is fixed (second layer of g_v/g_k); examine early vs late fusion, multi-scale fusion, and cross-view attention for both the keypoint and vertex branches.
- H3DS evaluation may include hair/shoulders while GLVD reconstructs only the face mesh; precisely define the evaluated region and ensure fair, region-matched comparisons across methods.
- Computational efficiency details are incomplete: g_v outputs a large 7225×7225×3 tensor but uses only the diagonal; justify this design, measure its overhead, and explore sparse or per-vertex heads for higher-resolution meshes.
- Appearance (texture/reflectance) is not modeled; investigate texture estimation, UV unwrapping consistency, reflectance models, and joint geometry-appearance reconstruction for photorealistic rendering.
- Provide uncertainty/confidence estimates per vertex and keypoint to inform downstream tasks (e.g., tracking, animation) and enable confidence-weighted postprocessing.
- Explore hybrid test-time optimization: assess whether a brief refinement step on top of GLVD improves multi-view accuracy while retaining most of the speed benefits.
- Domain shift robustness (low light, motion blur, background clutter) is not quantified; design stress tests and targeted augmentations, and report performance under such conditions.
- Incorporate stronger priors under extreme expressions (e.g., dense face-part priors like 3DDFA-v3) and evaluate whether they improve resilience when landmarks are unreliable.
- Claims of applicability beyond faces are not demonstrated; validate on bodies/hands or other object classes with arbitrary topology to substantiate generality.
- The multi-view camera pose estimator is mentioned but not described or evaluated; detail its architecture, training data, error characteristics, and analyze how pose errors impact GLVD performance.
- Ethical considerations and privacy of the proprietary identity dataset are not discussed; provide consent procedures, data governance, and guidelines for responsible deployment.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed with the current capabilities reported in the paper. Each item includes sectors, potential tools or workflows, and key dependencies or assumptions.
- Real-time photo-to-3D avatar creation for XR and gaming (sectors: software, entertainment, education, metaverse). Tools/workflows: GLVD SDK as a Unity/Unreal plugin, a Blender/Maya add-on for fast mesh reconstruction, WebGL/WebAR API for browser-based avatar generation. Dependencies/assumptions: good frontal image(s), moderate occlusions, reliable face masks or auto-segmentation, adequate device GPU/CPU; fixed facial topology limits expression rigging without add-ons.
- AR virtual try-on for eyewear, masks, and cosmetics from a single selfie (sectors: e-commerce, retail, healthcare). Tools/workflows: “Eyewear Fitment SDK” that maps glasses to reconstructed mesh, “Respirator/Mask Fit Checker” using mesh-landmark distances, “Makeup Preview” via mesh-aligned overlays. Dependencies/assumptions: accurate real-world scale estimation (camera intrinsics or reference object), consistent calibration in multiview setups, handling hair/occlusions.
- Telepresence and video-call enhancement with mesh-based stabilization and relighting (sectors: software, communication). Tools/workflows: client-side mesh-based gaze/pose stabilization, lighting normalization, low-bandwidth face streaming (transmit mesh + texture). Dependencies/assumptions: inference on consumer devices; single-view performance suffices; user consent and privacy controls.
- VFX and asset pipelines: fast photogrammetry-lite for faces (sectors: entertainment, software). Tools/workflows: “Photo-to-Rig” pre-production step producing animatable meshes; rapid background replacement via mesh-aware compositing; template-based rig transfer. Dependencies/assumptions: expression capture still limited; artist supervision for final rigging; robust keypoints under non-studio lighting.
- Telemedicine-friendly 3D face capture for orthodontics and craniofacial review (sectors: healthcare). Tools/workflows: patient-facing mobile app generating GLVD meshes for remote screening; clinician dashboard overlaying measurements. Dependencies/assumptions: regulatory constraints; scale calibration (e.g., reference card), clinical validation beyond reported mm-level errors; occlusion management (e.g., beards, masks).
- Biometric liveness checks leveraging 3D geometry from a selfie (sectors: security, finance, policy). Tools/workflows: “3D Liveness API” combining mesh consistency and depth plausibility checks; anti-spoof signals from per-vertex consistency. Dependencies/assumptions: fairness and demographic robustness; rigorous adversarial testing; privacy-by-design; alignment with KYC/AML policies.
- Human-robot interaction and social robotics: robust face pose and geometry for attention/engagement (sectors: robotics). Tools/workflows: robot-side face mesh to improve gaze estimation, occlusion-aware face tracking for better interaction. Dependencies/assumptions: real-time inference on edge compute; performance in cluttered scenes; reduced sensitivity to occlusions.
- Educational content creation for facial anatomy and digital human courses (sectors: education). Tools/workflows: teacher-facing tool to produce student-specific meshes from photos; interactive anatomy viewers. Dependencies/assumptions: basic imaging conditions; rights and consent for student images; anonymization options.
- Social media and creator tools for 3D profile pics and avatar stickers (sectors: software, entertainment). Tools/workflows: mobile AR filters that generate and stylize GLVD meshes; “Avatar Studio” for quick character creation. Dependencies/assumptions: mobile-friendly runtime; privacy and sharing settings; governance on deepfake risks.
- Rapid dataset bootstrapping for academic research without dense 3D supervision (sectors: academia, software). Tools/workflows: open-source training recipe (if released) to pretrain encoders with SDF head; few-shot mesh reconstruction benchmark protocols. Dependencies/assumptions: access to training data (current paper uses proprietary scans); reproducibility contingent on code/model release and licensing.
Long-Term Applications
Below are applications that are feasible with further research, scaling, or development. Each item includes sectors, potential tools or workflows, and key dependencies or assumptions.
- Expression-aware, temporally consistent digital humans for live telepresence (sectors: software, entertainment, education). Tools/workflows: video-driven GLVD with expression modeling, blendshape/parametric expression layers, temporal regularization and occlusion handling. Dependencies/assumptions: new modules for expressions, sequence training, speech-to-expression mapping; multi-view or video datasets.
- Full-head avatars including hair, ears, and shoulders with robust occlusion handling (sectors: software, entertainment, robotics). Tools/workflows: hybrid GLVD + Gaussian splats for hair, topology-adaptive strategies. Dependencies/assumptions: retraining with full-head datasets; topology changes beyond fixed mesh; multiview consistency.
- Clinical-grade morphometrics and surgical planning from commodity cameras (sectors: healthcare, policy). Tools/workflows: validated “Photo-to-Plan” pipeline for craniofacial reconstruction; longitudinal outcome tracking; integration with EMR. Dependencies/assumptions: scale calibration standards; regulatory approvals; controlled acquisition protocols; demographic fairness studies.
- Mass personalization in manufacturing: eyewear, PPE, dental aligners (sectors: manufacturing, e-commerce, healthcare). Tools/workflows: CAD/CAM pipeline driven by GLVD meshes; automated fit optimization and CNC/3D-print integration. Dependencies/assumptions: reliable metric scaling; QA standards; customer consent and secure data handling.
- Privacy-preserving, on-device real-time reconstruction (sectors: software, policy). Tools/workflows: quantized GLVD models for smartphones; federated learning to improve encoders without raw image sharing. Dependencies/assumptions: efficient model compression; hardware acceleration; privacy impact assessments.
- Geometry-informed deepfake detection and robust authentication (sectors: security, finance, policy). Tools/workflows: 3D consistency signals, mesh-liveness scoring integrated into identity verification stacks. Dependencies/assumptions: red-team evaluations; cross-demographic stress tests; regulator guidance for biometric signals.
- Extending GLVD to body and hands for holistic digital humans (sectors: software, robotics, education, healthcare). Tools/workflows: unified per-vertex neural fields with skeletal priors; multi-part topology management. Dependencies/assumptions: new datasets and keypoint strategies; cross-part consistency; performance on edge devices.
- Standards and governance for 3D facial data (sectors: policy, academia, industry consortia). Tools/workflows: consent frameworks, retention/deletion policies, bias/fairness audits; interoperability via avatar interchange formats. Dependencies/assumptions: multi-stakeholder coordination; alignment with GDPR/CCPA and biometric laws; standardized disclosures.
- KYC/ID verification from photos with 3D augmentation (sectors: finance, government). Tools/workflows: “Photos-to-3D ID” services to reduce false accepts via 3D checks; anomaly detection on mesh geometry. Dependencies/assumptions: regulator acceptance; robust liveness; secure processing; fairness monitoring.
- Retail kiosks and mobile scanning for try-on at scale (sectors: retail, e-commerce). Tools/workflows: in-store kiosks performing fast multiview GLVD reconstructions, synchronized to user accounts for at-home try-ons. Dependencies/assumptions: camera calibration and lighting control; privacy-preserving storage; seamless omnichannel integration.
- Automated VFX pipeline with expression transfer and rigging (sectors: entertainment, software). Tools/workflows: mesh-to-rig auto-retargeting, expression capture from video, quality control tools for artists. Dependencies/assumptions: expression modeling; robust to varied lighting/costumes; integration with studio toolchains.
- Clinical and wellness monitoring via facial biomarkers (e.g., edema, asymmetry trends) (sectors: healthcare, wellness). Tools/workflows: secure longitudinal mesh tracking; alerts on deviations from baseline. Dependencies/assumptions: validated clinical correlations; controlled capture; privacy and consent; bias mitigation.
These applications derive from GLVD’s core strengths—single-view, few-shot, fast, mesh-based reconstruction with global structural guidance—while acknowledging current limitations (occlusions, dependence on accurate keypoints, fixed topology, proprietary training data). As the method is extended to expressions, temporal consistency, full-head coverage, and on-device privacy, its impact will broaden across sectors, use cases, and everyday workflows.
Glossary
- 3D Morphable Models (3DMMs): Parametric statistical models that encode facial geometry in a low-dimensional space for reconstruction. "The use of 3D Morphable Models (3DMMs) has become the standard paradigm for reconstructing 3D facial geometry from images, particularly in single-view or few-shot scenarios."
- BRDF: Bidirectional Reflectance Distribution Function; models how light is reflected at a surface. "NeuFace~\citep{zheng2023neuface} proposed an approximated BRDF integration and a low-rank prior for human face rendering."
- Camera coordinate frame: A coordinate system aligned with the camera used as the reference space for reconstruction. "For single-view 3D reconstruction, it operates in the camera coordinate frame, eliminating the need for camera parameter estimation at test time."
- Canonical body coordinates: A standardized body-centric coordinate system used to represent geometry consistently across poses. "ARCH~\citep{huang2020arch} and ARCH++~\citep{he2021arch++} adopt canonical body coordinates."
- Canonical space: A normalized, aligned 3D coordinate system used to stabilize training and inference. "We adopt a canonical aligned space to stabilize training."
- Chamfer distance: A surface-to-surface distance metric commonly used to evaluate reconstruction accuracy. "We used the unidirectional Chamfer distance for the quantitative evaluation, measuring the surface error from the ground truth to the predictions."
- Fourier embedding: A feature mapping using sinusoidal functions to encode coordinates for learning. "We augment each query point with an identity feature derived from a Fourier embedding of the vertex’s 3D coordinates in the canonical face template."
- Gaussian Splatting: A rendering technique that represents scenes with 3D Gaussians for efficient view synthesis. "Building on the recent success of Gaussian Splatting~\citep{kerbl3Dgaussians}, several works~\citep{luo2024splatface, dhamo2024headgas, qian2024gaussianavatars, tang2024gaf} have integrated this representation to improve rendering efficiency and visual fidelity."
- Group normalization: A normalization technique that normalizes features in groups within neural networks. "GLVD adapts its reference space based on the number of input views during training and inference." (Used in context: "composed of four stacks using group normalization~\cite{wu2018group}.")
- Hourglass network: A neural architecture with encoder-decoder symmetry used for dense prediction tasks. "obtained from the first stack of the Hourglass network \citep{newell2016stacked}."
- HRNet: High-Resolution Network; a model for keypoint detection maintaining high-resolution representations. "we first generate facial keypoint heatmaps using off-the-shelf HRNet~\citep{wang2020deep}"
- Iterative Closest Point (ICP) registration: An algorithm for aligning 3D shapes by minimizing distance between corresponding points. "All scans are aligned to a template 3D model using non-rigid Iterative Closest Point (ICP) registration for consistency."
- Keypoint-relative encoding: Encoding a vertex’s position by its displacement relative to predicted 3D keypoints. "Given a query vertex , we compute a keypoint-relative encoding matrix ."
- Learned Vertex Descent (LVD): A learning-based iterative optimization that predicts per-vertex displacements from image features. "Learned Vertex Descent (LVD)~\citep{corona2022learned} introduced a hybrid strategy that uses pixel-aligned image features to guide iterative template fitting."
- Neural fields: Continuous implicit representations modeled by neural networks that encode geometry and appearance. "Neural fields address these challenges by encoding geometry and appearance as continuous functions via neural networks."
- Non-rigid registration: Deformable alignment of 3D shapes allowing local non-rigid transformations. "All scans are aligned to a template 3D model using non-rigid Iterative Closest Point (ICP) registration for consistency."
- Part Re-projection Distance Loss: A loss leveraging dense part segmentation to guide reconstruction under challenging expressions. "3DDFAv3~\citep{wang20243d} introduces Part Re-projection Distance Loss, which leverages dense facial part segmentation as a strong geometric prior for guiding 3D reconstruction, especially under extreme expressions where landmarks are unreliable."
- Pixel-aligned features: 2D image features sampled at projections of 3D points or vertices to inform 3D predictions. "Model-free methods leveraging pixel-aligned features have gained popularity for fast 3D reconstruction, as they avoid the need for test-time optimization~\cite{saito2019pifu, saito2020pifuhd, he2020geo, alldieck2022photorealistic, shao2022doublefield, corona2023structured, guo2023rafare}."
- Pixel-aligned implicit functions: Implicit functions conditioned on image features at corresponding pixels to predict occupancy or SDF values. "PIFu~\cite{saito2019pifu} introduced pixel-aligned implicit functions, using 2D image features to predict 3D occupancy from single or multiple views."
- Relative spatial encoding: Encoding positions relative to other spatial anchors (e.g., keypoints) to inject global structure. "By incorporating relative spatial encoding, GLVD iteratively refines mesh vertices without requiring dense 3D supervision."
- Signed Distance Function (SDF): A scalar field giving the distance to a surface with sign indicating inside/outside. "We pre-train the feature encoder on the 3D reconstruction task by augmenting it with a signed distance function (SDF) prediction head."
- Skinning weights: Weights defining influence of control points (e.g., joints/keypoints) on mesh vertices for deformation. "Inspired by the concept of skinning weights, we model vertex-to-keypoint relations via learnable attention (j)."
- Stochastic variables: Random variables used to model uncertainty during training or encoding. "we model the 3D keypoints used for encoding vertices in the vertex branch as stochastic variables, introducing noise to the ground-truth keypoints only during training."
- Template fitting: The process of deforming a predefined mesh template to match observed data. "However, converting such representations into well-structured, topologically consistent meshes suitable for animation or rendering often necessitates additional post-processing, commonly involving template fitting."
- Volumetric rendering: Rendering technique integrating densities and colors along rays through a volume to synthesize images. "Using volumetric rendering, KeypointNeRF aggregates pixel-aligned features with a relative spatial encoder."
- Weight normalization: A reparameterization technique that normalizes weights to stabilize training. "Both and are implemented as a 3-Layer MLP with ReLU activation and weight normalitzation."
Collections
Sign up for free to add this paper to one or more collections.