SAEdit: Token-level control for continuous image editing via Sparse AutoEncoder
Abstract: Large-scale text-to-image diffusion models have become the backbone of modern image editing, yet text prompts alone do not offer adequate control over the editing process. Two properties are especially desirable: disentanglement, where changing one attribute does not unintentionally alter others, and continuous control, where the strength of an edit can be smoothly adjusted. We introduce a method for disentangled and continuous editing through token-level manipulation of text embeddings. The edits are applied by manipulating the embeddings along carefully chosen directions, which control the strength of the target attribute. To identify such directions, we employ a Sparse Autoencoder (SAE), whose sparse latent space exposes semantically isolated dimensions. Our method operates directly on text embeddings without modifying the diffusion process, making it model agnostic and broadly applicable to various image synthesis backbones. Experiments show that it enables intuitive and efficient manipulations with continuous control across diverse attributes and domains.
























































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SAEdit: token-level control for image editing — explained simply
Overview: what is this paper about?
This paper introduces a new way to edit AI-generated images using text in a more precise and smooth way. When you ask a text-to-image model for changes (like “make the person smile”), it often changes too many things at once and you can’t easily control how strong the change is. SAEdit fixes that by letting you tweak just the part you want (like only the “smile” on the “woman” token) and smoothly adjust how much you add it, like turning a dial.
The big questions the paper tries to answer
- How can we change one thing in an image (like “add glasses” or “make older”) without accidentally changing other things (like background, lighting, or identity)?
- How can we control the strength of an edit smoothly (a slight smile → medium smile → big grin) instead of only using rough words?
- Can we do this in a general way that works with different image models without retraining a new tool for every single kind of edit?
How SAEdit works (in everyday language)
Think of a text-to-image model as a chef that reads a recipe (your prompt) where each word is turned into a secret code (called an “embedding”). The chef uses these codes to cook up the picture.
SAEdit adds a smart “translator” called a Sparse Autoencoder (SAE) in between your text and the image model:
- “Tokens” are pieces of words in your prompt (like “woman”, “smiling”, “hat”).
- An “embedding” is the numeric code the model uses to understand a token.
- A “Sparse Autoencoder” learns to turn these codes into a set of simple switches where most are off, and only a few meaningful ones are on. Each switch tends to represent a clear idea (like “smile” or “laugh”).
Here’s the simplified process:
- Train the SAE on the text encoder’s token codes so it learns the “switchboard” for many concepts.
- To find a specific edit (like “add smile”), compare two prompts, e.g., “a woman” vs. “a smiling woman.” By looking at which switches change, SAEdit identifies a clean “direction” that represents just the smile.
- Make the direction stronger or weaker with a scale (a dial) to control how much smile you add.
- Apply that direction to the token you care about (for example, only “woman,” not “kid” or “background”).
- Decode back to the original text code and let the image model render the result.
Two extra smart touches:
- Robust directions: instead of comparing just one pair of prompts, the method generates many pairs (like “man on the beach” → “happy man on the beach”, “woman in a café” → “happy woman in a café”) and combines them to find the most stable “happiness” direction.
- Gentle timing: during image generation, the model builds the picture step by step. SAEdit slowly turns up the edit over time (like a dimmer switch), so it doesn’t mess up the overall layout early on and only adjusts details later.
What did they find, and why it’s important
- Precise edits: SAEdit changes only what you ask for (e.g., adding a hat or smile) while keeping identity and background the same.
- Smooth control: you can continuously tune how strong the edit is, not just pick fixed words like “slight” or “big.”
- Token-level targeting: you can apply an edit to a specific subject in the scene (e.g., only the man in a couple photo).
- Model-agnostic: it works with different image models that use the same text encoder (they show results on Flux and Stable Diffusion 3.5), without retraining the image model.
- Versatile: it works on people (age, expression, accessories) and objects (like changing a tree to “bloom” or making a mirror more “square”).
- Better than simple methods: compared to just mixing in the target word’s code (the “naïve” way), SAEdit avoids unwanted changes and weird distortions.
What this means going forward
SAEdit could make creative tools much more user-friendly:
- Artists and everyday users could edit images with fine control, like turning a slider for “smile intensity” or “age,” while keeping the rest of the scene intact.
- It reduces the need to train separate tools for every edit, making image editing faster and more scalable.
- Because it works on the text side and doesn’t touch the image model’s internal process, it’s easier to plug into different systems.
- The idea of finding clean “directions” for concepts may also help us understand and steer other kinds of AI models more safely and clearly.
In short, SAEdit gives you a precise, smooth “dial” for editing images with text, targeting exactly the token you want and leaving everything else alone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scope of “model-agnostic” claim: The method is only agnostic across backbones that share the same text encoder (T5). How to transfer directions across different encoders (e.g., CLIP, BERT, custom tokenizers) or across multilingual encoders is not addressed.
- SAE training corpus and coverage: The text corpus, domain diversity, and size used to train the SAE are not specified. It is unclear how training data distribution affects discovered features, generalization to new domains, and robustness to out-of-distribution prompts.
- Monosemanticity on T5 final outputs: The assumption that sparse features on the final T5 output are monosemantic (concept-aligned) is supported qualitatively, but not rigorously validated with probing or feature-level interpretability metrics for the trained SAE.
- Token aggregation choice: Max-pooling across tokens discards positional and syntactic information. It is unclear whether other aggregations (e.g., attention-based attribution, gradient-based saliency, learned pooling) would improve concept isolation and robustness.
- Direction identification stability: The entry-wise ratio and thresholding procedure depends on hyperparameters (ε, ρ, top-k). Sensitivity analysis and automatic selection strategies are not provided.
- Dependence on LLM-generated prompt pairs: Robustness of directions to the choice, style, and bias of the LLM-generated pairs is not studied. How many pairs are needed, and how pair diversity impacts generalization, is unknown.
- SVD aggregation design: The SVD-based aggregation of multiple directions is introduced without alternatives or ablations (e.g., robust averaging, clustering, sparse PCA). Conditions under which the top singular vector fails to represent a single attribute remain unexplored.
- Attribute scope and compositionality: The method is demonstrated on a small set of attributes (expressions, hair color, accessories). It is unclear how well it handles attributes that require structural changes (pose, viewpoint), scene-level edits, or long-range style factors.
- Multi-attribute editing: Whether directions are linear and composable (additive edits), and how interactions/conflicts between multiple simultaneous attribute directions manifest, is not evaluated.
- Instance-level disambiguation: Editing is applied to a specific token, but when multiple instances of the same concept exist (e.g., several “man” objects), the method may not disambiguate which instance is altered. A mechanism for spatial or instance-level targeting is missing.
- Token-to-object alignment: The reliability with which a chosen token maps to the intended subject in the generated image (especially in complex scenes or paraphrased prompts) is uncertain and not quantitatively measured.
- Leakage and entanglement measurement: While qualitative examples claim disentanglement, there is no systematic metric assessing attribute leakage into non-target tokens/objects or unintended style/content changes.
- Calibration of edit magnitude: There is no standardized mapping from the scalar ω to perceptual intensity across attributes or contexts. Calibration procedures or attribute-specific scaling functions are absent.
- Injection schedule generality: The exponential schedule is proposed without comparison to other schedules (e.g., sigmoid, adaptive, attribute-dependent schedules) or principled criteria for choosing τ and ω_t per edit type.
- Early-step structural edits: For edits requiring global structural changes, delaying injection may be suboptimal. How to adapt schedules for structure-changing attributes or scene-level transformations remains open.
- Failure modes and limits: The behavior under extreme ω values, adversarial prompts, conflicting attributes, or saturated latent features is not analyzed. Typical failure patterns and safeguards are missing.
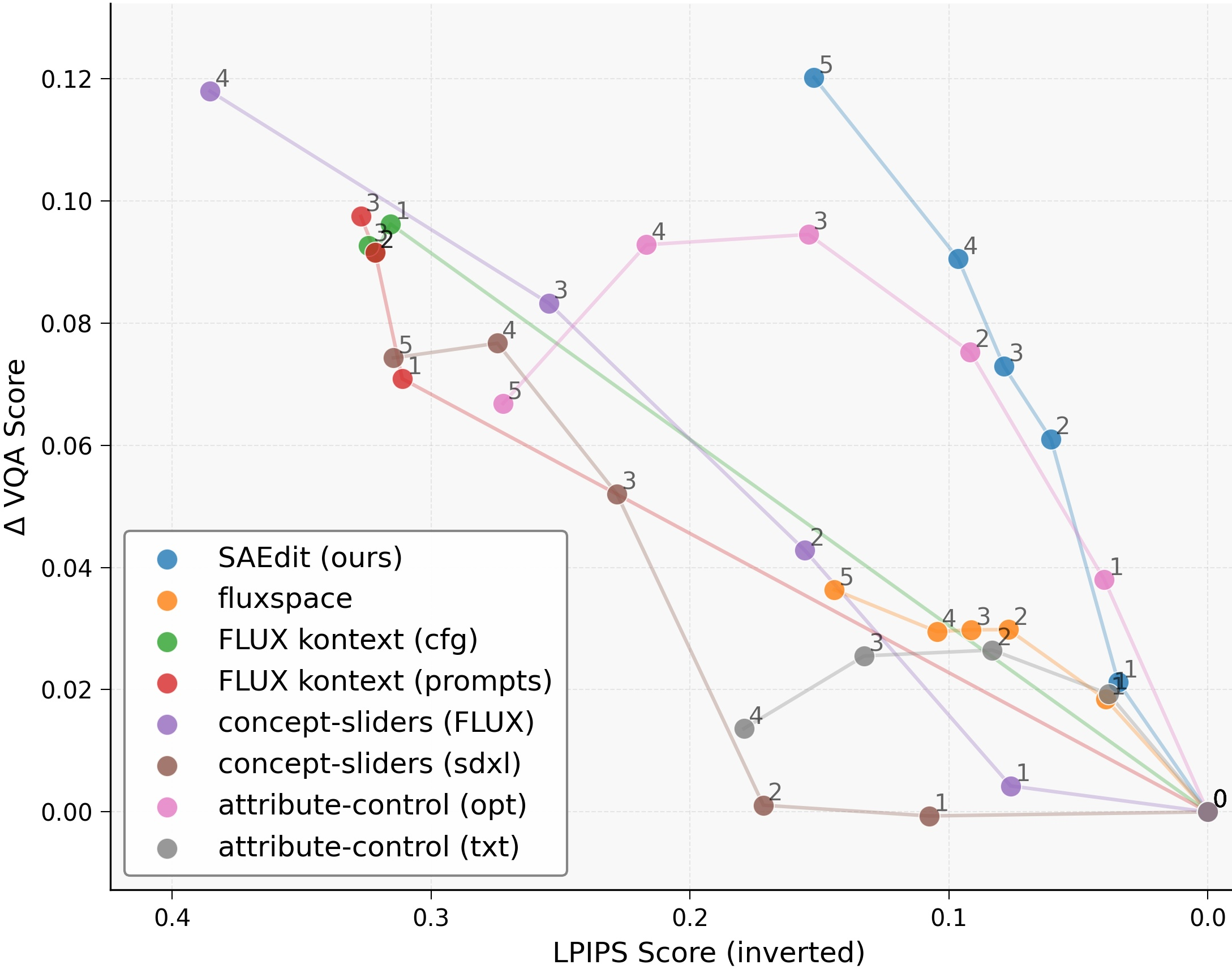
- Quantitative evaluation depth: Metrics are limited (LPIPS, VQA-Score) and not tailored to disentanglement or identity preservation (e.g., face recognition, attribute classifiers, object detectors). No statistical comparisons to strong baselines or user studies are provided.
- Baseline coverage: Comparisons focus on naive T5 interpolation; the method is not compared against leading training-free or task-specific continuous editing approaches on shared benchmarks.
- Real-image editing robustness: Although inversion-based editing is mentioned, the sensitivity to inversion errors, reconstruction fidelity, and edit success across different inversion methods and real-world conditions is not studied.
- Generalization across seeds and prompts: Variance across random seeds, paraphrases, prompt lengths, and syntactic structures is not quantified, leaving robustness claims unsubstantiated.
- Hyperparameter sensitivity: Sparse target (k), regularization strengths, SAE dimensionality, and decoder capacity are not systematically explored; guidelines for stable training and deployment are missing.
- Attribute discovery scalability: The pipeline requires per-attribute direction extraction; it is unclear how to scale to large attribute libraries, automate discovery, or manage overlapping/ambiguous attributes.
- Bias and fairness: Edits touching protected attributes (e.g., “African-American”) raise ethical concerns. The method’s bias amplification, misclassification risks, and safeguards for sensitive attribute editing are not discussed.
- Cross-lingual and style transfer: Performance with non-English prompts, stylistic prompts (e.g., artistic, cartoon), or specialized domains (medical, scientific) is untested.
- Transfer to non-diffusion generators: Applicability to non-diffusion renderers (GANs, autoregressive image models) using different conditioning interfaces is unclear, constraining broader adoption.
Practical Applications
Practical Applications of SAEdit (Token-level, Continuous, Disentangled Image Editing)
SAEdit introduces a sparse-autoencoder-driven, token-level manipulation of text embeddings for text-to-image models (e.g., Flux, SD3.5 with T5), enabling disentangled, continuously controllable edits without modifying the diffusion backbone. Edits can be localized to specific tokens (e.g., one person in a scene), scaled via ω/ω_t, and applied to generated or real images via inversion.
Below are actionable applications grouped by deployment horizon.
Immediate Applications
The following can be deployed now with existing T5-based text-to-image systems (e.g., Flux, SD3.5) by training an SAE on the text encoder outputs and integrating a lightweight editing pipeline.
- Creative variant generation for marketing/ads — slider-based micro-edits
- Sectors: advertising, media/entertainment, design software
- What: Generate systematic variants of a hero image by continuously adjusting attributes (smile intensity, age, accessories like glasses/hat, hair color), while preserving brand identity and scene composition.
- Tools/workflows: “Direction library” for common attributes; sliders in design tools (e.g., ComfyUI/Automatic1111 plugin); batch runner that sweeps ω/ω_t across attributes.
- Assumptions/dependencies: T5-based model access; trained SAE compatible with the text encoder; GPU for inference; brand and legal guardrails for sensitive attributes.
- E-commerce product visuals — controlled, localized edits
- Sectors: retail, marketplaces
- What: Adjust product attributes (e.g., mirror shape, fabric texture emphasis, seasonal “bloom” for decor) without affecting room layout or other products.
- Tools/workflows: Token selection UI for target object; SVD-derived robust directions for specific product categories.
- Assumptions/dependencies: Correct token mapping to the product in the prompt; high-quality inversion for real product photos if editing photos rather than generated images.
- Post-production and VFX — per-subject, non-destructive edits
- Sectors: film/TV, creative studios
- What: Change only one actor’s expression/age/accessory in a multi-person shot; preserve lighting, framing, and co-actors via delayed/exponential injection schedules.
- Tools/workflows: Shot-level token assignment; edit logs for versioning (capture direction, ω schedule); review workflow for approvals.
- Assumptions/dependencies: Stable inversion pipeline; identity preservation validated per shot; rights clearances for edits.
- Social media and consumer photo apps — fine-grained filters
- Sectors: consumer software, mobile apps
- What: Continuous “intensity” sliders for expressions, hair color, accessories, per-person; minimal scene drift compared to prompt-only edits.
- Tools/workflows: On-demand direction lookup; small SAE model served behind an API.
- Assumptions/dependencies: Compute budget; UI/UX for token selection; content safety filters.
- Synthetic data generation for ML — balanced, controllable cohorts
- Sectors: computer vision, A/B testing, recommendation
- What: Programmatically vary human expressions, accessories, and non-human attributes (e.g., foliage density) to create balanced datasets or stress tests while preserving other factors.
- Tools/workflows: Parameter sweeps across ω; CSV-to-image pipelines logging edit parameters for reproducibility.
- Assumptions/dependencies: Ethical/compliance review for sensitive attributes; provenance tagging to prevent inadvertent training contamination.
- Simulation and robotics domain randomization — structure-preserving variation
- Sectors: robotics, autonomy, AR/VR
- What: Randomize appearance (textures, small accessories) while maintaining scene layout and object identity for robust perception training.
- Tools/workflows: Token-level randomizers constrained by disentangled directions; schedule tuned to avoid geometry drift.
- Assumptions/dependencies: Simulation-to-real gap analysis; availability of appropriate backbone/generator for the domain.
- Editorial tooling for designers — “token-aware” editing panels
- Sectors: design tools, creative software
- What: Side-panel controls that bind sliders to token-specific directions (e.g., “woman → laugh”, “tree → bloom”) with per-token masking.
- Tools/workflows: Direction discovery service (LLM-generated prompt pairs + SVD) embedded into the tool; preset libraries.
- Assumptions/dependencies: Access to LLM for direction generalization; caching of directions; user education.
- Research on disentanglement and interpretability
- Sectors: academia, ML research
- What: Use the SAE latent features as probes of text encoder semantics; benchmark monosemanticity; compare edit fidelity across architectures sharing T5.
- Tools/workflows: Reproducible direction discovery datasets; evaluation via LPIPS/VQA-Score.
- Assumptions/dependencies: Open weights or academic licenses; standardized reporting.
- Content provenance and governance — embedded edit logs
- Sectors: policy, trust & safety, platforms
- What: Attach C2PA-style metadata logging direction IDs, ω/ω_t, and token targets to track subtle, continuous edits.
- Tools/workflows: Signing pipeline; policy-configurable blocklists for sensitive directions (e.g., protected attributes).
- Assumptions/dependencies: Platform adoption of provenance; legal/policy definitions of permissible edits.
- A/B testing of creatives and UX
- Sectors: product growth, marketing ops
- What: Quickly explore small semantic deltas (e.g., friendliness of expression) and correlate with engagement metrics.
- Tools/workflows: Experiment orchestration that varies ω along disentangled directions; auto-reporting dashboards.
- Assumptions/dependencies: Data privacy compliance; hypothesis registries to prevent p-hacking.
Long-Term Applications
These require further research, scaling, or engineering (e.g., new backbones, real-time performance, broader modalities).
- Spatio-temporally consistent video editing with token-level control
- Sectors: media/entertainment, creator tools
- What: Extend disentangled, per-entity sliders across frames with temporal coherence and identity tracking.
- Dependencies: Video diffusion backbones; temporal token tracking; scheduling across frames; performance optimizations.
- Real-time AR try-on and mobile deployment
- Sectors: retail (try-before-you-buy), consumer apps
- What: On-device sliders for hair color, glasses, facial expressions in live camera feeds.
- Dependencies: Efficient on-device SAE + encoder; low-latency inversion or streaming generation; safety rails.
- Cross-encoder standardization (CLIP/SigLIP/Proprietary)
- Sectors: model providers, platforms
- What: Train SAEs on non-T5 encoders; define a common API for token-level, continuous controls across models.
- Dependencies: Access to encoders; compatibility layers; evaluation standards for disentanglement.
- 3D asset and scene editing with text-conditioned 3D generators
- Sectors: gaming, VFX, digital twins
- What: Apply token-level semantic sliders to 3D assets (expressions, materials, part-level attributes) while preserving geometry/layout.
- Dependencies: Text-conditioned 3D backbones; token-to-component correspondence; 3D-aware scheduling.
- Healthcare and scientific imaging (controlled counterfactuals)
- Sectors: healthcare, life sciences
- What: Carefully validated, controlled attribute modulation for sensitivity analyses (not clinical editing); dataset bias studies.
- Dependencies: Domain-specific, clinically validated generators; strict governance; IRB/ethics review; provenance and non-diagnostic disclaimers.
- Algorithmic fairness auditing via controlled sweeps
- Sectors: policy, ML governance
- What: Systematically vary sensitive attributes to test model invariance or bias in downstream systems.
- Dependencies: Governance frameworks; red-team protocols; secure handling of sensitive attribute manipulation.
- Marketplace and registry of “safe” edit directions
- Sectors: platforms, creator ecosystems
- What: Curated libraries of vetted, disentangled directions with quality and safety badges; license-aware distribution.
- Dependencies: Community standards; automated and human review; versioning and provenance.
- Personalized/brand-specific SAEs
- Sectors: enterprises, creative agencies
- What: Fine-tune SAEs to capture brand style features and company-specific attribute controls.
- Dependencies: Private corpora; fine-tuning infrastructure; IP protection.
- Multilingual and cross-cultural token alignment
- Sectors: global platforms, localization
- What: Extend token-level control to multilingual encoders; culturally sensitive attribute mapping.
- Dependencies: Multilingual encoder coverage; alignment datasets; cultural review.
- Enterprise DAM integration with semantic diffs
- Sectors: digital asset management
- What: Integrate semantic “diffs” (direction + ω) into asset version control; policy checks on check-in.
- Dependencies: Vendor integrations; standard metadata schemas; audit pipelines.
- Safety-first guardrail learning
- Sectors: trust & safety, platform policy
- What: Train detectors to flag or block harmful or identity-altering directions; whitelist-only editing modes.
- Dependencies: Labeled safety datasets; continual updates; user appeals processes.
- Automated creative pipelines and MLOps
- Sectors: engineering, creative ops
- What: Programmatic, large-scale application of direction matrices over asset libraries with reproducible seeds and schedules.
- Dependencies: Job orchestration; monitoring for drift/artifacts; cost controls.
Notes on Feasibility and Key Dependencies
- Model compatibility: Immediate portability across backbones that share the same text encoder (e.g., T5). New encoders require retraining the SAE.
- Data and compute: Training the SAE on token embeddings requires access to a prompt corpus and moderate GPU resources; inference overhead is lightweight.
- Robust direction discovery: Quality improves using multiple source–target prompt pairs and SVD aggregation; depends on access to an LLM and careful prompt engineering.
- Real-image editing: Requires reliable inversion (e.g., ReNoise/Null-Text) and consistent reuse of the initial noise for minimal drift.
- Safety and ethics: Token-level control can touch protected attributes (e.g., race, age). Deployments should include blocklists, disclosure, and provenance (e.g., C2PA).
- Bias and generalization: Directions learned from web corpora may encode societal biases; validation and periodic re-training are recommended.
- UI/UX: Token selection and per-token masking are critical for non-expert usability; good defaults for ω/ω_t and thresholds (ρ, τ) reduce artifacts.
These applications leverage SAEdit’s core strengths—token-level targeting, disentanglement, and continuous control—while remaining largely model-agnostic and production-friendly for T5-based text-to-image systems.
Glossary
- Backbone (image synthesis): The core generative architecture that renders images given conditioning signals. "various image synthesis backbones."
- Concept unlearning: Techniques to remove or suppress specific concepts from a model’s representations or generations. "interpretability and concept unlearning"
- Continuous control: Ability to smoothly adjust the strength or magnitude of an edit rather than using discrete categories. "continuous control, where the strength of an edit can be smoothly adjusted."
- Denoising process: The iterative procedure in diffusion models that transforms noise into an image. "leaving the denoising process untouched."
- Denoising steps: The individual iterations within the diffusion denoising process. "throughout the denoising steps."
- Diffusion models: Probabilistic generative models that synthesize images by reversing a noise-adding process. "Large-scale text-to-image diffusion models have become the backbone of modern image editing"
- Diffusion Transformer (DiT): A transformer-based architecture used within diffusion models for conditioning and generation. "the Diffusion Transformer (DiT) throughout the denoising steps."
- Disentanglement: Property where changing one attribute does not unintentionally affect others. "disentanglement, where changing one attribute does not unintentionally alter others"
- Dictionary-like representation: A sparse code where a small set of features corresponds to distinct semantic attributes. "learn a dictionary-like representation,"
- DreamBooth: A fine-tuning approach to personalize text-to-image models with subject-specific concepts. "train numerous person-specific DreamBooth LoRAs"
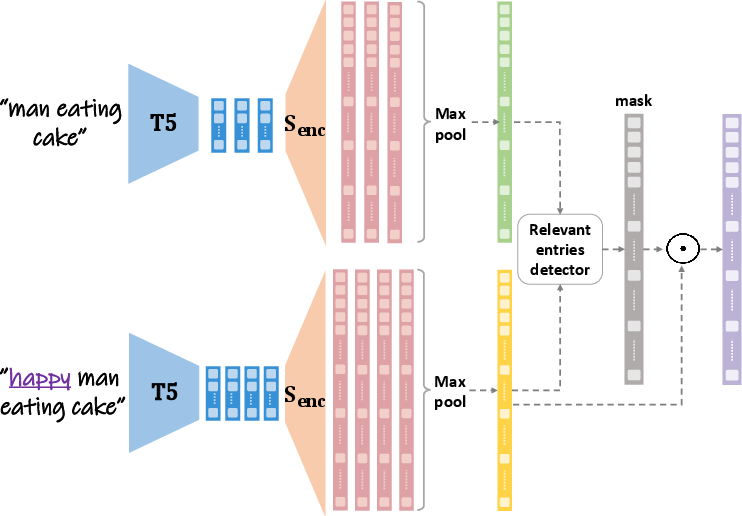
- Entry-wise ratio: A per-dimension comparison of two vectors to find dimensions most correlated with a change. "we compute an entry-wise ratio, R"
- Feature injection: Editing strategy that modifies model features during generation to control outputs. "feature injection"
- Flux: A diffusion transformer-based text-to-image model used as the image synthesis “renderer.” "we primarily use the Flux~\citep{flux} diffusion transformer (DiT)."
- Frozen text encoder: A text encoder whose parameters are not updated during the method’s training or use. "given a frozen text encoder"
- Hyperparameter: A user-set parameter (not learned) controlling aspects like strength caps or sparsity. "a hyperparameter that acts as an upper bound on the edit strength."
- Identity preservation: Maintaining the original subject’s identity while applying edits. "yield disentangled edits that preserve identity"
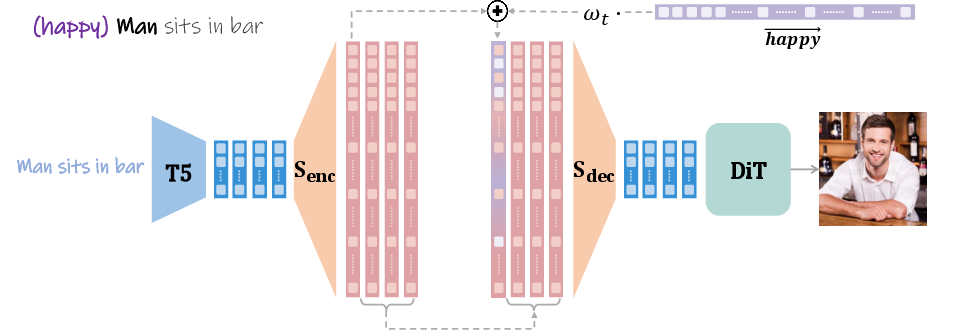
- Injection schedule: A time-dependent strategy controlling when and how strongly edits are applied during denoising. "we introduce an exponential injection schedule"
- Initial noise: The starting noise sample in diffusion generation (often denoted x_T) that seeds the process. "using the same initial noise, "
- Inversion techniques: Methods to map a real image into a diffusion model’s latent/noise space for editing. "applied to real images using inversion techniques."
- Latent space: The internal representation space where semantic factors can be manipulated. "sparse latent space exposes semantically isolated dimensions."
- LLM: A LLM used here to generate multiple prompt pairs capturing the same semantic relation. "we use an LLM to construct sentence pairs"
- LoRA adapter: A lightweight fine-tuning module enabling attribute-specific control via low-rank adaptation. "training a dedicated LoRA adapter"
- LPIPS: A perceptual similarity metric used to measure preservation of content. "preservation with LPIPS"
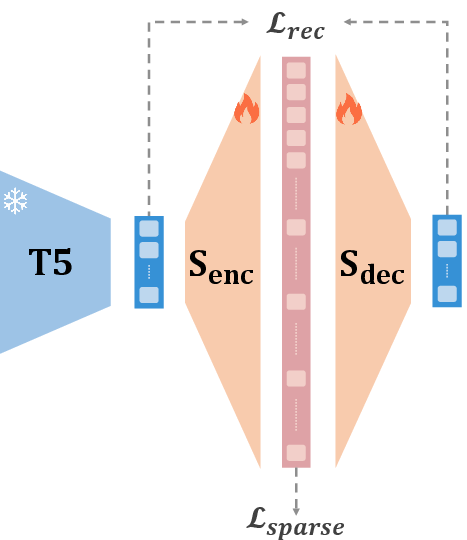
- Max-pooling: An aggregation operation taking the maximum value per dimension across token representations. "we use element-wise max-pooling"
- Mean Squared Error: A common reconstruction loss measuring squared differences between outputs and targets. "(e.g., Mean Squared Error)"
- Model agnostic: Applicable across different models without model-specific changes or retraining. "making it model agnostic and broadly applicable"
- Model steering: Directly influencing a model’s behavior by manipulating internal representations. "enables model steering, allowing for direct control"
- Non-negative activation: An activation function constrained to output non-negative values, aiding sparsity/interpretable codes. "a single linear layer with a non-negative activation"
- Padding tokens: Special tokens used to align sequence lengths that are excluded from training/analysis. "excluding padding tokens."
- Partial noise schedules: Editing approach applying noise denoising only over parts of the schedule with new conditions. "applying partial noise schedules with a new text condition"
- Renderer (in diffusion): Viewing the diffusion model as the component that visually renders edited semantic instructions. "the diffusion model serves merely as a renderer"
- Singular Value Decomposition (SVD): A matrix factorization used to extract a dominant, robust edit direction across examples. "we perform Singular Value Decomposition (SVD) on D"
- Singular vector: The principal direction obtained from SVD representing the dominant shared attribute. "The singular vector corresponding to the largest singular value is then selected as our final, robust edit direction ."
- Sparse AutoEncoder (SAE): An autoencoder enforcing sparsity in the latent code to reveal interpretable semantic features. "We train a Sparse AutoEncoder (SAE) to lift the text embeddings into a higher-dimensional space"
- Sparsity regularization: Constraints promoting few non-zero activations in the latent code for interpretability/disentanglement. "sparsity regularization techniques"
- Steering vectors: Direction vectors in latent space used to manipulate specific attributes. "resulting in a set of steering vectors"
- Stable Diffusion 3.5: A text-to-image model variant used to demonstrate model-agnostic applicability. "Stable Diffusion 3.5"
- T5 text encoder: A pretrained text encoder providing token embeddings for conditioning image synthesis. "We demonstrate our method on the T5 text encoder"
- Text embeddings: Vector representations of text used to condition image generation models. "Our method operates directly on text embeddings"
- Timesteps: Indices of the iterative denoising process that progress from structure to detail. "early timesteps are crucial for establishing the global structure and layout of an image"
- Token embeddings: Per-token vectors from the text encoder forming the basis for token-level edits. "collect the resulting token embeddings, excluding padding tokens."
- Token-level manipulation: Editing that targets specific tokens’ embeddings rather than the whole prompt. "token-level manipulation of text embeddings"
- VQA-Score: An evaluation metric derived from visual question answering models assessing semantic accuracy. "semantic accuracy with a VQA-Score"
Collections
Sign up for free to add this paper to one or more collections.