- The paper introduces SA-DiCoW, integrating speaker attribution and diarization conditioning to enhance transcription accuracy in overlapping speech.
- It leverages Serialized Output Training and frame-level diarization masks to achieve significant cpWER reductions across synthetic and real-world datasets.
- Experimental results indicate that embedding concatenation and targeted speaker loss improve performance compared to conventional ASR models.
Adapting Diarization-Conditioned Whisper for Multi-Talker Speech Recognition
Introduction
Recent advancements in Automatic Speech Recognition (ASR) have extended capabilities beyond traditional single-speaker models to accommodate the increasingly complex demands of real-world multi-talker scenarios. This paper proposes an innovative solution to the multi-talker ASR problem, leveraging the Diarization-Conditioned Whisper (DiCoW) framework. By integrating speaker-attributed modeling with Serialized Output Training (SOT), the presented architecture facilitates simultaneous transcription of overlapping speech streams, marked by speaker tags and timestamps. The proposed Speaker-Attributed Diarization-Conditioned Whisper (SA-DiCoW) model demonstrates enhanced performance over existing methodologies in synthetic and real-world datasets, underscoring its potential in advancing multi-speaker ASR.
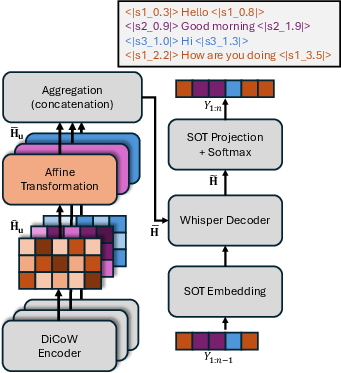
Figure 1: Overall architecture of proposed SA-DiCoW.
Methods
Whisper-based Speech Recognition
Whisper, a state-of-the-art multilingual encoder-decoder ASR model, underpins the proposed architecture. Its attention-based encoder-decoder structure, fortified with Transformer blocks, processes input audio as log mel-filterbank features, mapping these into hidden embeddings. Despite its efficacy across various single-talker domains, Whisper requires adaptation for multi-talker scenarios—specifically to accommodate speaker attribution. Enhancements through the DiCoW framework, enriched with components for speaker-aware modeling, address performance lapses in overlapping speech environments.
Target-Speaker Conditioning with DiCoW
DiCoW's encoder, adapted for target-speaker ASR, uses diarization masks encoding speaker activity across four classes: silence (S), target speaker active (T), non-target speaker active (N), and overlap (O). Applying frame-level diarization-dependent transformations to adjust internal representations based on speaker context, DiCoW encapsulates speaker-specific acoustic features within dedicated representations, thereby facilitating joint decoding and improving overlap robustness.
Multi-Talker ASR with Speaker-Attributed Whisper
By incorporating Serialized Output Training (SOT), Whisper is adapted for speaker-attributed ASR, enabling it to process multichannel speaker-timestamp tokens indicative of speaker identity and timing. This facilitates segment ordering and timestamp progression within each speaker's turn, allowing for effective modeling of overlapping speech conditions. The architecture's holistic design permits the decoder to condition on the global conversational context, thereby enhancing transcription accuracy in complex speech scenarios.
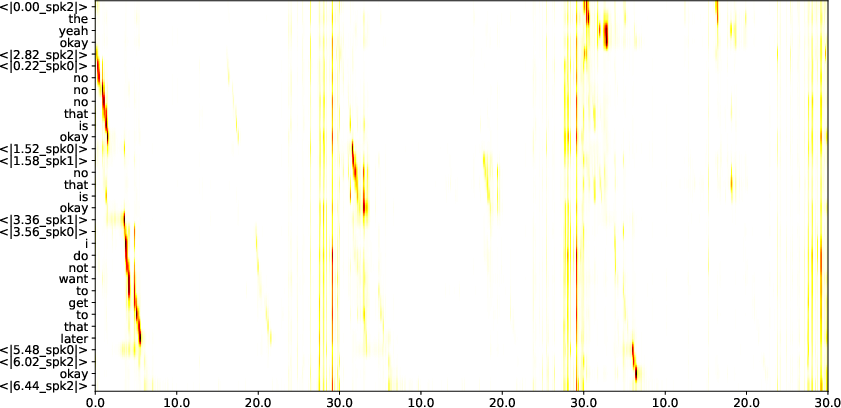
Figure 2: Example of cross-attentions from last decoder layer: x-axis depicts time in seconds, y-axis shows tokens.
Experimental Setup
Datasets
Experiments utilize English-based multi-talker datasets, including NOTSOFAR, AMI, and LibriMix, with oracle diarization derived from available annotations. These datasets provide a diverse array of synthetic and real-world conversational settings essential for comprehensive model evaluation. The data preparation adheres strictly to segment duration constraints inherent to Whisper’s input processing.
Evaluation Metrics
The model's performance is assessed using concatenated minimum-Permutation Word Error Rate (cpWER), a metric reflecting both recognition and diarization errors crucial for evaluating speaker-attributed ASR. This standardized evaluation across synthetic and real-world datasets offers a robust benchmark against competing methodologies.
Results
Impact of Encoder Embedding Aggregation
The investigation into encoder embedding aggregation strategies reveals concatenation as superior, yielding significant cpWER reductions, especially in multi-speaker settings. This method preserves the acoustic and temporal distinctions necessary for accurate speaker attribution, outperforming averaging-based approaches.
Improvements and Comparison with Existing Systems
Speaker attribution accuracy is bolstered through increased loss emphasis on speaker timestamp tokens, resulting in favorable comparisons with established ASR systems across varied datasets. The analysis of cross-attention weights substantiates the model's dynamic engagement with speaker information during decoding, underscoring robustness in highly overlapped conditions.
Conclusion
The integration of target-speaker modeling and serialized output training within the DiCoW framework marks a significant stride in multi-talker ASR, enabling sophisticated speaker-attributed transcriptions in challenging conversational contexts. The proposed SA-DiCoW model, despite its advantages in synthetic and controlled settings, illustrates the necessity of continued research into speaker assignment optimization for diverse, real-world applications. Future endeavors may explore more adaptive and semi-supervised learning paradigms to mitigate reliance on oracle diarization, striving towards more generalized and flexible ASR solutions.

