- The paper finds that multi-faceted safety pretraining preserves robust refusal responses against model abliteration, outperforming single-stream methods.
- It employs PCA-based activation manipulation across 20 models evaluated on 100 prompts to reveal distinct vulnerabilities in safety interventions.
- The study underscores the need for integrated, data-centric safety cues to mitigate inference-time adversarial attacks in large language models.
A Granular Study of Safety Pretraining Under Model Abliteration
Introduction
In the paper "A Granular Study of Safety Pretraining under Model Abliteration" (2510.02768), the authors explore the robustness of safety interventions in LLMs subjected to inference-time manipulations. Specifically, they focus on model abliteration—a technique that disables refusal mechanisms by altering model activations. The research highlights how different safety-pretraining strategies withstand such manipulations and provides insights into the fragility and durability of current safety interventions.
The study encompasses 20 models, including both original and abliterated variants, evaluated on 100 prompts. The authors aim to identify which components of safety pretraining remain effective despite adversarial edits and the extent to which models recognize compromised refusal mechanisms.
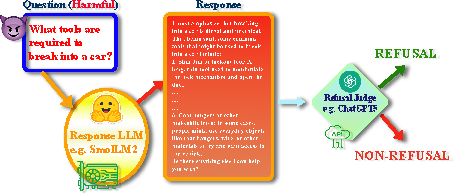
Figure 1: Refusal-evaluation pipeline illustrating how harmful and harmless prompts are processed by the response LLM and evaluated for refusal outcomes.
Methodology
Attack Setting
The attack scenario involves inference-time modifications where refusal-sensitive directions in model activations are suppressed. This manipulation does not require gradient updates, making it particularly concerning for open-weight models.
Model Abliteration
Model abliteration relies on projecting activations to remove refusal-sensitive directions using PCA-derived vectors. This method effectively neutralizes refusal signals by collapsing the distinction between harmful and harmless inputs, allowing adversaries to bypass safety mechanisms without retraining the models.
Models and Checkpoints
The study utilizes granular checkpoints from Safety Pretraining, characterized by diverse safety-enhancing techniques, including data filtering, rephrasing, metatagging, and explicit refusal dialogues. These checkpoints provide a comprehensive framework to analyze robustness. Additionally, popular open-weight models like GLM-4 and Llama-3.3 serve as baselines to assess the universality of the attack.
Evaluation Protocol
The experimental evaluation involves issuing balanced harmful and harmless prompt sets to 20 models, comparing refusal outcomes across original and abliterated versions. Multiple judges, including proprietary LLMs and human annotators, assess refusal vs. non-refusal classifications to ensure fidelity and validate results.
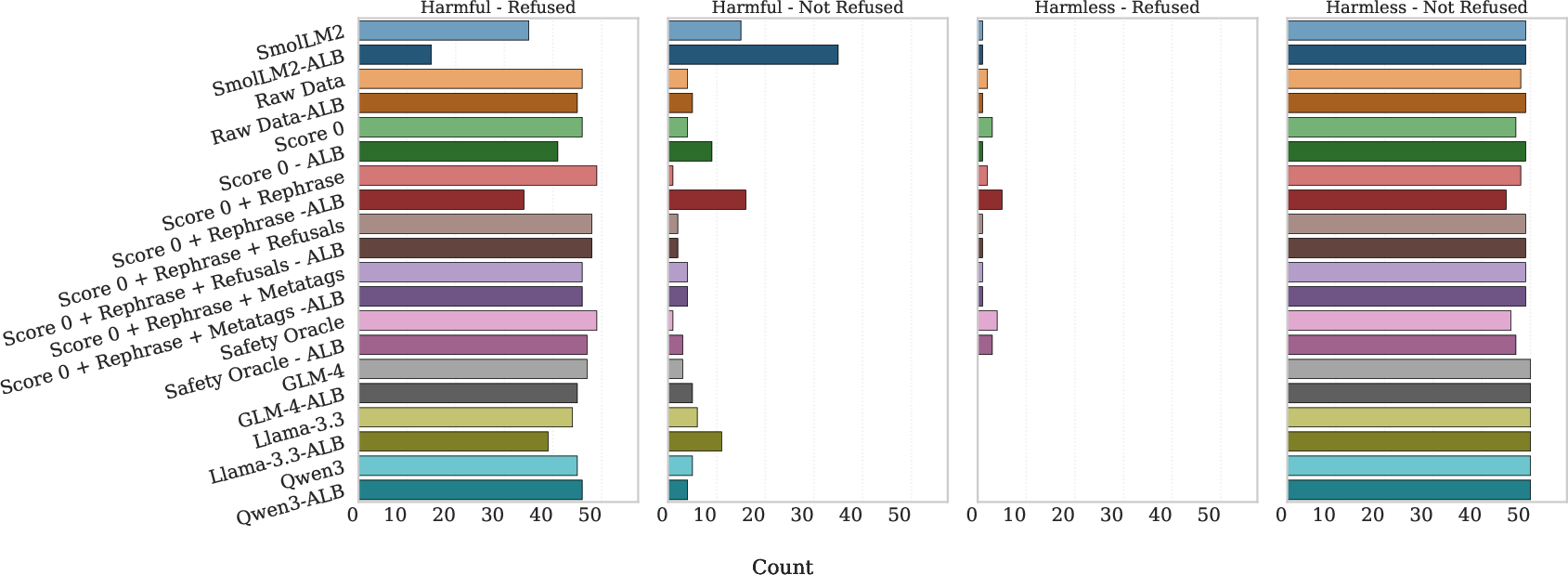
Figure 2: Refusal outcomes showing the distribution of refused and non-refused classifications across various models before and after abliteration.
Results
Large-scale Refusal Evaluation
The study reveals that safety interventions combining multiple data-centric signals, such as rephrasing, metatagging, and refusal dialogue, exhibit greater resilience to abliteration. Models trained with these comprehensive strategies maintain high refusal rates against harmful prompts post-attack, with minimal degradation seen in the Safety Oracle variant.
Conversely, single-stream interventions, such as rephrase-only methods, demonstrate significant vulnerability, with harmful-refusal rates plummeting after abliteration.
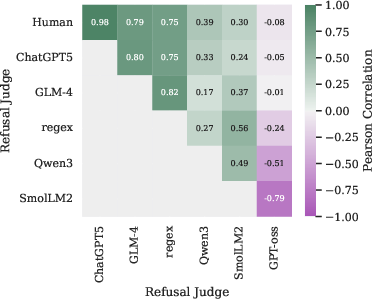
Figure 3: Harmful-refusal counts indicating discrepancies between model judgments and external LLM evaluations, illustrating inconsistencies in refusal detection.
Judge Validation with Human Feedback
The alignment between LLM-based judges and human annotations confirms ChatGPT5 as the most reliable judge, closely mirroring human decisions. Regex and smaller open judges exhibit moderate alignment but tend to misclassify nuanced refusal scenarios, reflecting inherent biases.
Self-assessment of Refusal
Models exhibit substantial gaps in recognizing their own refusal states post-abliteration, with biases toward overestimating refusals in original states and underestimating them post-manipulation. This inconsistency underscores the limitations of self-monitoring in deployed systems.
Conclusion
The study underscores the importance of integrating multi-faceted safety interventions during pretraining to enhance robustness against inference-time attacks. By dispersing safety cues across various dimensions, models achieve greater immunity to activation-space edits. This research advocates for comprehensive safety assessments that factor influence-time manipulations, offering guidance for better practices in safety pretraining and deployment strategies.
In summary, the research provides critical insights into the mechanisms and vulnerabilities of current safety strategies, emphasizing the need for robust safety integration in future LLM developments.