- The paper introduces SAGANet, a model that leverages segmentation masks to generate audio precisely aligned with selected video objects.
- It integrates global and local visual streams using gated cross-attention and LoRA-based fine-tuning to achieve optimal semantic and temporal synchronization.
- Empirical results demonstrate that SAGANet outperforms previous models in temporal and semantic alignment, generalizing well even to multi-source scenes.
Video Object Segmentation-Aware Audio Generation: A Technical Analysis
Introduction and Motivation
The paper introduces the task of Video Object Segmentation-aware Audio Generation (VOS-aware AG), addressing a critical limitation in current multimodal audio generation models: the lack of precise, object-level user control. Existing approaches typically condition audio synthesis on global video or textual cues, which is insufficient for professional Foley workflows where fine-grained, object-specific sound generation is required. The proposed solution, SAGANet, leverages segmentation masks to enable localized, controllable audio generation, and is supported by the introduction of a new dataset, Segmented Music Solos, specifically curated for this task.
Methodology
The VOS-aware AG task is formally defined as generating audio A=GM(V,M,...), where V is the video stream and M is the corresponding binary segmentation mask stream. The objective is to synthesize audio that is temporally and semantically aligned with the specified object region, rather than the entire scene.
SAGANet Architecture
SAGANet extends the MMAudio model by integrating a segmentation-aware control module. The architecture fuses global and local visual information streams using gated cross-attention layers, inspired by recent advances in localized captioning and multimodal fusion.
Figure 1: Overview of SAGANet control module. The model combines global and local information streams from video and segmentation masks using gated cross-attention, updating only the highlighted layers during training.
Key architectural components include:
- Focal Prompting: Both the original video and a focal crop (centered on the segmented object) are processed, each with their respective masks. This dual-stream approach provides both global context and detailed local information.
- Localized Vision Backbone: Video and mask streams are embedded via 3D patch embedding layers, with learnable positional encodings to preserve spatiotemporal structure. The mask embedding is initialized to zero to stabilize early training.
- Shared-Weight Feature Extractors: Global and focal streams are processed by feature extractors with shared self-attention weights, promoting representational alignment.
- Gated Cross-Attention Adapters: Focal features are conditioned on global context via gated cross-attention, with learnable scale parameters initialized to zero to suppress early noise.
- Audio Generation: The fused visual features condition the DiT-based audio generator, replacing the original Synchformer features in MMAudio. LoRA is optionally used to fine-tune query and value projections in the DiT layers associated with segmentation-aware features.
This design enables efficient adaptation of large pretrained models to new conditioning modalities without full model retraining or variant-specific control modules.
Segmented Music Solos Dataset
To support the VOS-aware AG task, the Segmented Music Solos dataset is introduced. It comprises 5,395 training, 665 validation, and 745 test samples, each five seconds long, spanning 25 musical instruments. Each sample includes video, audio, and per-frame segmentation masks.
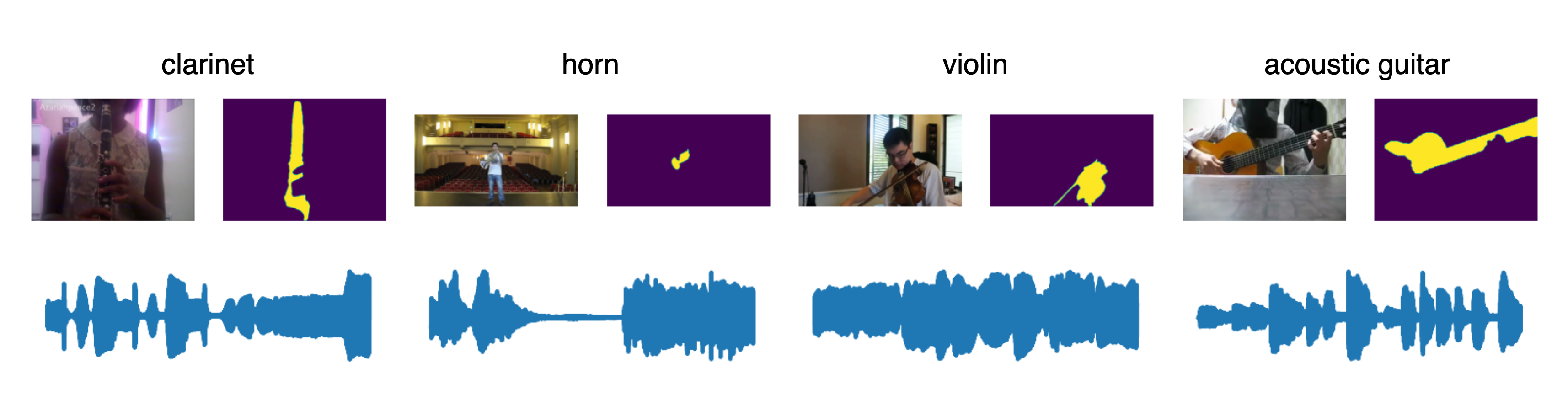
Figure 2: Samples from Segmented Music Solos, showing instrument labels, video frames with masks, and corresponding audio.
The dataset construction pipeline involves:
- Source Video Collection: Aggregation from MUSIC21, AVSBench, and Solos for training/validation; URMP for testing.
- Visual and Auditory Verification: Ensuring the target instrument is present in both modalities using CNN and AST classifiers, with semantic label matching via MPNet embeddings.
- Clipping and Mask Generation: Videos are clipped to five seconds where the object is present throughout, and segmentation masks are generated using GroundedSAM2 and Florence-2 for training, with manual annotation for testing.
This dataset enables rigorous evaluation of object-level audio generation and generalization from single-source to multi-source scenes.
Experimental Results
Implementation Details
SAGANet is trained on top of a pretrained MMAudio model, with the segmentation-aware control module trained for ~40 epochs on 4 A100 GPUs. LoRA is used for efficient fine-tuning of DiT attention blocks. During training, textual labels are randomly dropped to encourage reliance on segmentation information.
Evaluation Metrics
Performance is assessed using:
- Distribution Matching: Fréchet Distance (FD) and KL divergence on VGGish, PANNs, and PaSST embeddings.
- Audio Quality: Inception Score (IS) via PANNs.
- Semantic Alignment: IB-score (cosine similarity between video and audio embeddings from ImageBind).
- Temporal Alignment: DeSync (mean absolute offset via Synchformer).
Main Results
SAGANet demonstrates substantial improvements over the base MMAudio model across all metrics, with the most pronounced gains in temporal synchronization and semantic alignment. Notably, the model generalizes to multi-source test scenes despite being trained only on single-source data, focusing audio generation on the segmented object even in the presence of distractors. LoRA fine-tuning further enhances performance.
Ablation Study
Ablations reveal that:
- Using only global frames yields the best IS but poor temporal alignment.
- Focal crops improve temporal alignment but slightly degrade audio quality.
- Fusing both global and local streams with segmentation masks achieves the best balance, maximizing semantic relevance and temporal precision.
Implications and Future Directions
The introduction of segmentation-aware conditioning in audio generation models represents a significant step toward practical, controllable Foley synthesis. The approach enables fine-grained user control, essential for professional post-production and interactive media applications. The modular design allows efficient adaptation of large pretrained models to new modalities with minimal computational overhead.
Potential future directions include:
- Extending segmentation-aware control to more complex, real-world scenes with occlusions and dynamic object interactions.
- Integrating additional modalities (e.g., depth, motion) for richer conditioning.
- Exploring unsupervised or weakly supervised segmentation to reduce annotation costs.
- Applying the approach to other generative tasks, such as speech synthesis or environmental sound design.
Conclusion
This work establishes a new paradigm for controllable audio generation by conditioning on video object segmentation masks. SAGANet, with its segmentation-aware control module, achieves superior semantic and temporal alignment compared to prior models, as validated on the Segmented Music Solos benchmark. The methodology and dataset lay a robust foundation for future research in fine-grained, multimodal generative modeling for audio-visual applications.