- The paper introduces VGGT-X, which overcomes dense view synthesis challenges by integrating advanced camera alignment and computational efficiencies.
- It employs adaptive global alignment and reduced feature caching to dramatically increase throughput, processing over 1,000 images with improved precision.
- Quantitative evaluations reveal superior PSNR, SSIM, and LPIPS scores across datasets, setting a new benchmark for photorealistic rendering fidelity.
VGGT-X: Advancements in Dense Novel View Synthesis
Introduction
The paper "VGGT-X: When VGGT Meets Dense Novel View Synthesis" (2509.25191) addresses significant challenges in the field of dense Novel View Synthesis (NVS). With the rise of 3D Foundation Models (3DFMs), exemplified by Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), the traditional reliance on exact 3D attributes for rendering fidelity has revealed fundamental bottlenecks, particularly in computational efficiency and initialization sensitivity. While 3DFMs offer speed advantages, extending their capabilities from sparse to dense settings introduces substantial memory overhead and output quality issues.
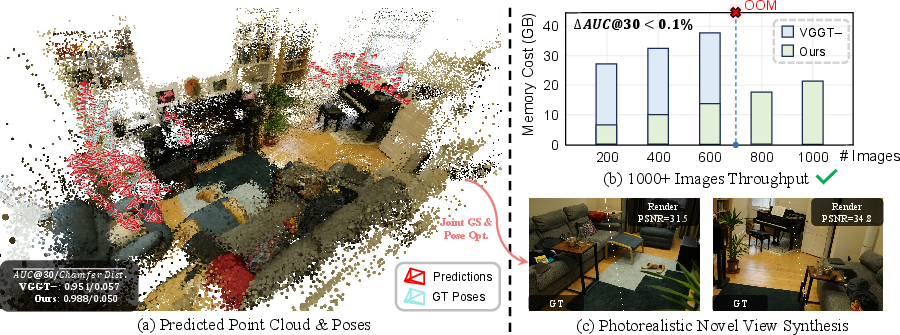
Figure 1: Reconstruction and Novel View Synthesis results. Part (a) extends VGGT to manage dense multi-view inputs, part (b) illustrates enhanced inference throughput, and part (c) demonstrates photorealistic rendering.
Core Challenges and Solutions
Dense NVS necessitates robust handling of extensive view inputs, a domain where naively scaled 3DFMs result in prohibitive VRAM usage and degrade rendering quality due to noise. VGGT-X counteracts these issues by adopting a refined VGGT implementation. It leverages memory-efficient techniques: eliminating unnecessary feature caching and reducing numerical precision accelerates processing up to 1,000+ images, significantly improving inference throughput. The model further aligns estimated camera parameters using sophisticated epipolar constraints to enhance accuracy.
Pipeline and Methodology
VGGT-X's pipeline integrates cutting-edge alignment techniques for camera parameters with robust training practices tailored to mitigate imperfections in 3DGS rendering. The pipeline is depicted visually in Figure 2, ensuring sequential processing of images and effectively managing computational load via batch operations.

Figure 2: Overall pipeline of our model.
The adaptive global alignment process refines camera parameters through minimization of epipolar distance losses, leveraging XFeat for accurate correspondence matching. A novel adaptive weighting scheme for correspondences enhances optimization efficiency, as elucidated in Figure 3, presenting qualitative improvements in rendering outcomes.

Figure 3: Qualitative comparison of rendering results, showcasing improvements in fidelity using VGGT-X.
Experimental Insights and Quantitative Analysis
A rigorous experimental setup compared VGGT-X against state-of-the-art models, confirming its superior performance on datasets like MipNeRF360, Tanks and Temple, and CO3Dv2. Detailed analysis in Tables illustrates VGGT-X’s breakthroughs in pose estimation precision and rendering quality, achieving noteworthy metrics in PSNR, SSIM, and LPIPS.
Further ablations reveal VGGT-X’s efficacy in optimizing camera parameters even under noisy conditions, underscored by trajectory comparisons and adaptive strategies critical for robust convergence.
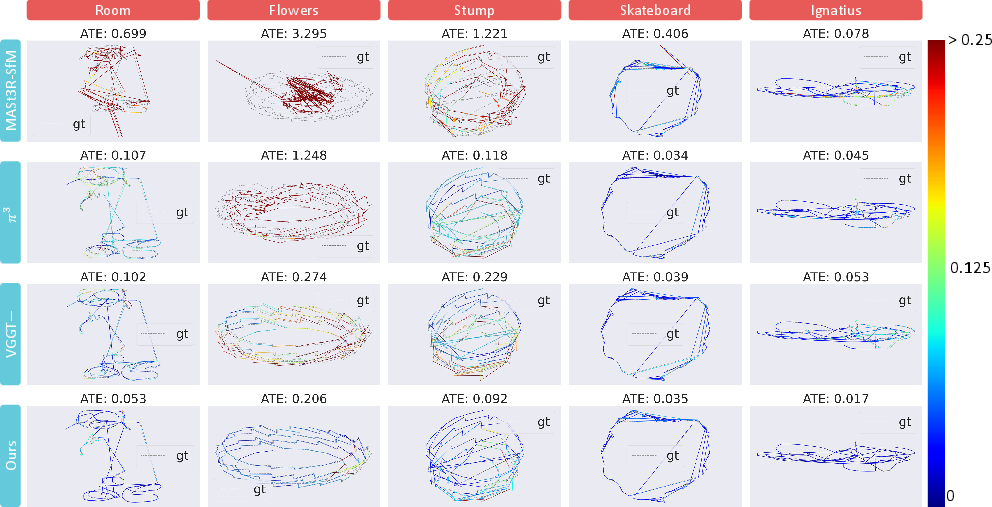
Figure 4: Qualitative comparison of estimated trajectories, depicting VGGT-X's precision.
Discussion and Future Directions
VGGT-X substantially narrows the fidelity gap with COLMAP-initialized pipelines while maintaining computational efficiency. Overfitting issues observed indicate the high complexity inherent in densely packed view synthesis, warranting future exploration of novel regularization techniques. Challenges in pose generalization highlight areas ripe for further innovation in 3DFMs, focusing on enhancing cross-dataset adaptability.
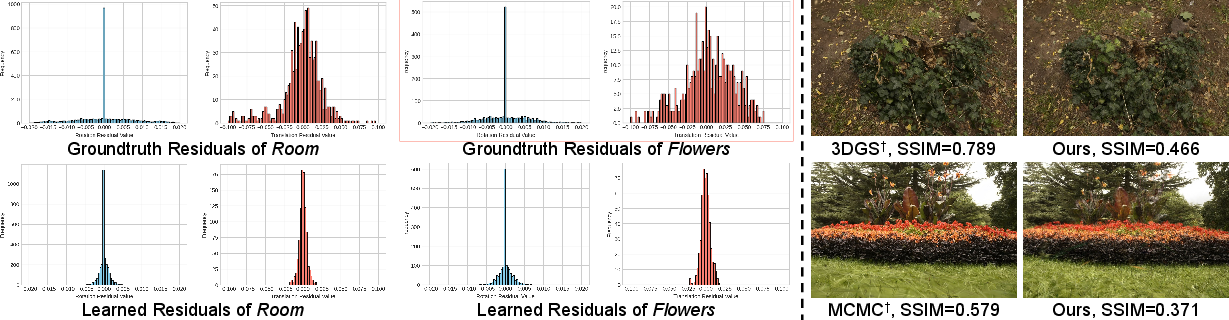
Figure 5: Bad case analysis, revealing areas of improvement for VGGT-X in handling pose inaccuracies.
Conclusion
"VGGT-X: When VGGT Meets Dense Novel View Synthesis" presents a compelling stride forward in dense NVS. The integration of scalable VGGT architecture, adaptive global alignment, and advanced 3DGS methodologies sets a robust precedent for future developments in the arena of photorealistic rendering from multi-view perspectives. The paper outlines critical pathways for ongoing research, aiming to perfect COLMAP-free systems, ultimately advancing the fidelity and efficiency of dense NVS frameworks.
By addressing fundamental scalability and fidelity challenges, VGGT-X offers a pivotal contribution to the landscape of 3D reconstruction and rendering, steering towards more efficient, accurate, and computationally sustainable solutions.

