Inductive Bias and Spectral Properties of Single-Head Attention in High Dimensions
Published 29 Sep 2025 in stat.ML, cond-mat.dis-nn, cs.IT, cs.LG, and math.IT | (2509.24914v1)
Abstract: We study empirical risk minimization in a single-head tied-attention layer trained on synthetic high-dimensional sequence tasks, given by the recently introduced attention-indexed model. Using tools from random matrix theory, spin-glass physics, and approximate message passing, we derive sharp asymptotics for training and test errors, locate interpolation and recovery thresholds, and characterize the limiting spectral distribution of the learned weights. Weight decay induces an implicit nuclear-norm regularization, favoring low-rank query and key matrices. Leveraging this, we compare the standard factorized training of query and key matrices with a direct parameterization in which their product is trained element-wise, revealing the inductive bias introduced by the factorized form. Remarkably, the predicted spectral distribution echoes empirical trends reported in large-scale transformers, offering a theoretical perspective consistent with these phenomena.
The paper derives exact asymptotic formulas for training and test errors and characterizes the limiting spectral distribution of learned weights.
It maps ERM optimization to a convex matrix sensing formulation, quantifying weight decay as an implicit nuclear-norm regularizer that favors low-rank solutions.
The study contrasts factorized and non-factorized parameterizations, showing that the factorized approach achieves superior generalization with fewer samples.
Inductive Bias and Spectral Properties of Single-Head Attention in High Dimensions
Overview and Motivation
This paper presents a rigorous high-dimensional analysis of empirical risk minimization (ERM) in single-head tied-attention layers, focusing on synthetic sequence tasks generated by the attention-indexed model. The authors leverage random matrix theory, spin-glass physics, and approximate message passing (AMP) to derive sharp asymptotics for training and test errors, identify interpolation and recovery thresholds, and characterize the limiting spectral distribution of learned weights. A central theme is the quantification of the inductive bias induced by weight decay, which manifests as an implicit nuclear-norm regularization favoring low-rank solutions. The work also contrasts the standard factorized parameterization of query and key matrices with a direct, non-factorized parameterization, elucidating the generalization advantages of the former.
Problem Setting and Analytical Framework
The study considers both sequence-to-sequence (seq2seq) and sequence-to-label (seq2lab) tasks, showing their asymptotic equivalence in the high-dimensional regime. The attention layer is parameterized by a weight matrix W∈Rd×m, with the attention matrix AW(x) computed via a row-wise softmax over bilinear forms of the input embeddings. The learning objective is ERM with ℓ2 regularization (weight decay), a standard practice in large-scale models.
Inputs are modeled as Gaussian random vectors, and targets are generated by applying a softmax to a bilinear form plus Gaussian noise, with the target weight matrix S0 of rank m0. The analysis is performed in the joint limit d,n,m→∞ with fixed ratios α=n/d2, κ=m/d, and κ0=m0/d, capturing the extensive-rank regime relevant for modern architectures.
Main Technical Results
The core technical contribution is a set of exact asymptotic formulas for training and test errors, as well as the singular value distribution of the learned weights at the global minimum of the ERM objective. The analysis proceeds by mapping the original non-convex optimization over W to a convex matrix sensing problem over S=W⊤W/md, where ℓ2 regularization on W induces a nuclear norm penalty on S. This mapping is formalized via variational identities and is shown to hold for both tied and untied parameterizations.
The limiting spectral density of the learned weights is derived, revealing distinct regimes as sample complexity increases: a bulk of outliers separates from the main spectrum, consistent with empirical observations in large transformer models. The predicted spectra exhibit a delta peak at zero, quantifying the low-rank bias induced by regularization.
(Figure 1)
Figure 1: Test error and singular value spectrum of the ERM estimator, showing agreement between theory and Adam simulations, and illustrating the emergence of low-rank structure and spectral bulk splitting as sample complexity increases.
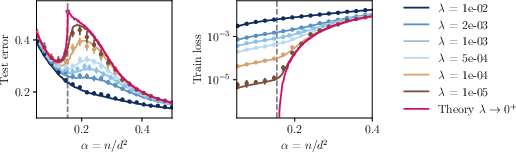
The analysis also provides precise locations for interpolation and recovery thresholds. The interpolation threshold αinterp marks the maximal sample ratio for which the ERM estimator fits the training data as λ→0+, while the perfect recovery threshold αperfect indicates the onset of zero test error in the noiseless case. These thresholds are derived analytically via mappings to linear attention and Marchenko-Pastur spectral laws.
Figure 2: Test error and training loss as functions of sample size for decreasing regularization, highlighting the interpolation threshold and the non-symmetric interpolation peak in test error.
Inductive Bias: Factorized vs. Non-Factorized Parameterization
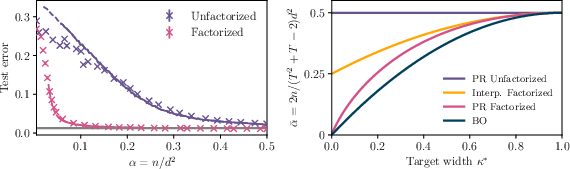
A key finding is the quantification of the inductive bias introduced by factorized parameterization. Training W in a factorized form with weight decay is shown to be equivalent to nuclear-norm regularization on S, favoring low-rank solutions. In contrast, direct element-wise training of S with Frobenius norm regularization is strictly more expressive but leads to significantly worse generalization, especially in the low-rank regime.
Figure 3: Comparison of test error between factorized and non-factorized parameterizations, demonstrating the superior generalization of the factorized model across sample sizes and regularization strengths.
The factorized model achieves vanishing error at sample scale O(dm0), while the non-factorized model requires O(d2) samples for perfect recovery. This gap is analytically characterized and scales as O(κ0−1) in the extreme low-rank regime.
Empirical Validation and Optimization Dynamics
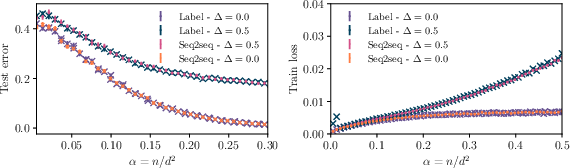
The theoretical predictions are validated via extensive numerical experiments using Adam optimization. Despite the non-convexity of the loss, Adam consistently reaches the global minimum, and the empirical learning curves and spectral densities closely match the theoretical predictions. The replicon condition, which guarantees AMP convergence, is empirically satisfied in all tested regimes.
Figure 4: Equivalence of seq2seq and seq2lab formulations, with indistinguishable learning curves and loss profiles across noise levels.
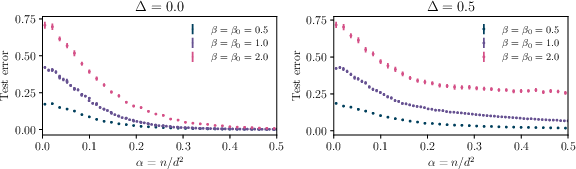
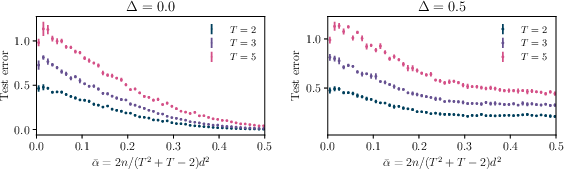
Additional experiments explore the effects of softmax temperature and sequence length, showing that lower temperatures yield systematically lower test error and that the number of tokens primarily rescales the effective sample complexity without altering qualitative learning dynamics.
Figure 5: Test error as a function of softmax temperature, demonstrating improved generalization at lower temperatures in both noiseless and noisy settings.
Figure 6: Test error as a function of rescaled sample complexity for varying sequence lengths, confirming the alignment of learning curves after normalization.
Theoretical and Practical Implications
The results provide a comprehensive theoretical foundation for the emergence of low-rank structure and spectral regularities in attention layers, connecting empirical observations in large-scale transformers to precise statistical mechanisms. The equivalence between weight decay and nuclear norm regularization explains the robustness of overparameterized architectures and the effectiveness of parameter-efficient fine-tuning methods such as LoRA.
The contrast between factorized and non-factorized parameterizations highlights the importance of architectural choices in inducing beneficial inductive biases, with direct implications for model design and regularization strategies.
Limitations and Future Directions
The analysis is restricted to single-head tied attention with identity value matrices, Gaussian synthetic inputs, and fixed sequence length. Extensions to multi-head, untied projections, and natural structured inputs remain open. Incorporating power-law tails into the spectral analysis may further align theory with empirical scaling laws in large transformer models. A deeper understanding of optimization dynamics beyond asymptotic minima is also an important avenue for future research.
Conclusion
This work establishes a rigorous high-dimensional theory for learning in single-head attention layers, quantifying the inductive bias and spectral properties induced by regularization and architectural choices. The analytical framework and empirical validation provide a foundation for understanding generalization and spectral phenomena in attention mechanisms, with direct implications for model design and training in large-scale neural architectures. Future developments should address the extension to more realistic settings and the integration of empirical scaling laws into the theoretical analysis.