Differentiable Structure Learning for General Binary Data
Published 25 Sep 2025 in cs.LG, math.ST, stat.ME, stat.ML, and stat.TH | (2509.21658v1)
Abstract: Existing methods for differentiable structure learning in discrete data typically assume that the data are generated from specific structural equation models. However, these assumptions may not align with the true data-generating process, which limits the general applicability of such methods. Furthermore, current approaches often ignore the complex dependence structure inherent in discrete data and consider only linear effects. We propose a differentiable structure learning framework that is capable of capturing arbitrary dependencies among discrete variables. We show that although general discrete models are unidentifiable from purely observational data, it is possible to characterize the complete set of compatible parameters and structures. Additionally, we establish identifiability up to Markov equivalence under mild assumptions. We formulate the learning problem as a single differentiable optimization task in the most general form, thereby avoiding the unrealistic simplifications adopted by previous methods. Empirical results demonstrate that our approach effectively captures complex relationships in discrete data.
The paper introduces a differentiable framework for learning directed acyclic graph structures from binary data using a full multivariate Bernoulli representation.
The method employs a sparsity-promoting optimization with a differentiable acyclicity constraint to recover the sparsest DAG up to Markov equivalence.
Empirical results demonstrate that the approach effectively captures higher-order interactions and outperforms traditional linear methods in complex discrete settings.
Differentiable Structure Learning for General Binary Data: A Technical Analysis
Introduction and Motivation
The paper "Differentiable Structure Learning for General Binary Data" (2509.21658) addresses the fundamental challenge of learning directed acyclic graph (DAG) structures from binary (or, more generally, discrete) data in a fully differentiable manner. Existing differentiable structure learning methods are predominantly tailored to continuous data and often rely on restrictive assumptions such as linearity, additivity, or specific parametric forms (e.g., generalized linear models). These assumptions are frequently violated in real-world discrete datasets, leading to model misspecification and suboptimal causal discovery.
This work introduces a general framework for differentiable structure learning that is agnostic to the data-generating process, leveraging the full expressivity of the multivariate Bernoulli (MVB) distribution. The authors provide a rigorous characterization of the non-identifiability inherent in general discrete models, propose a principled optimization-based approach for learning the sparsest compatible DAG, and establish theoretical guarantees for recovery up to Markov equivalence under mild assumptions. Empirical results demonstrate the method's ability to capture complex, higher-order dependencies that are inaccessible to prior approaches.
Theoretical Framework
Multivariate Bernoulli Representation
The core modeling assumption is that any p-dimensional binary random vector X can be represented as X∼MultiBernoulli(p), where p is a 2p-dimensional parameter vector encoding the probability of each possible configuration. The exponential family form is exploited:
P(X=x)=expS⊆[p]∑fSBS(x)
where BS(x)=∏j∈Sxj and fS are the natural parameters. This representation is maximally expressive, capturing all possible dependencies, including higher-order interactions.
Non-Identifiability and Equivalence Classes
A central theoretical result is that, in the absence of interventional or multi-environment data, the underlying DAG structure is non-identifiable: for any topological ordering π of the variables, there exists a unique parameterization (fπ,Gπ) that exactly reproduces the observed distribution. Thus, the set of compatible graph-parameter pairs has cardinality up to p!.
To address this, the authors define the minimal equivalence class as the set of sparsest DAGs (i.e., those with the fewest edges) consistent with the data. Under the Sparest Markov Representation (SMR) or faithfulness assumption, all minimal elements are Markov equivalent.
Differentiable Optimization Formulation
The combinatorial procedure for enumerating all possible DAGs is computationally infeasible for moderate p. The authors recast the problem as a single differentiable optimization:
Hmins(H;λ,δ,X)subject toh(W(H))=0,hj,S=0 if j∈S
where H is a 2p×p parameter matrix, W(H) is the induced adjacency matrix (with entries reflecting the presence of any nonzero interaction involving Xi in the equation for Xj), and h(⋅) is a differentiable acyclicity constraint. The score s(H;λ,δ,X) combines the negative log-likelihood of the MVB model with a smooth quasi-MCP penalty to promote sparsity.
Theoretical analysis shows that, in the population limit and for sufficiently small regularization parameters, any global minimizer of this program recovers a sparsest DAG up to Markov equivalence.
Implementation and Practical Considerations
Parameterization and Feature Engineering
Full MVB Parameterization: For small p, the full 2p-dimensional feature map Φ(X) is used, enabling the model to capture all possible interactions.
Truncation for Scalability: For larger p, the exponential growth of the feature space is mitigated by restricting to lower-order interactions (e.g., first and second order), or by employing a two-stage procedure (see below).
Optimization Strategy
Acyclicity Constraint: The differentiable acyclicity constraint is implemented using established techniques (e.g., the trace exponential or log-determinant characterizations).
Sparsity Penalty: The quasi-MCP penalty is used to approximate the ℓ0 norm, balancing sparsity and differentiability.
Continuation Method: Regularization parameters are annealed during optimization to avoid poor local minima and to encourage recovery of the sparsest solution.
Two-Stage Heuristic for Large Graphs
For moderate to large p, the authors propose a practical two-stage approach (Notears-MLP-reg):
Coarse Structure Learning: Apply a differentiable DAG learning method (e.g., NOTEARS-MLP) with a sigmoid activation and cross-entropy loss to obtain an initial graph and topological ordering.
Refinement: Along the inferred ordering, fit logistic regressions with first and second order interaction features to recover the final edge structure.
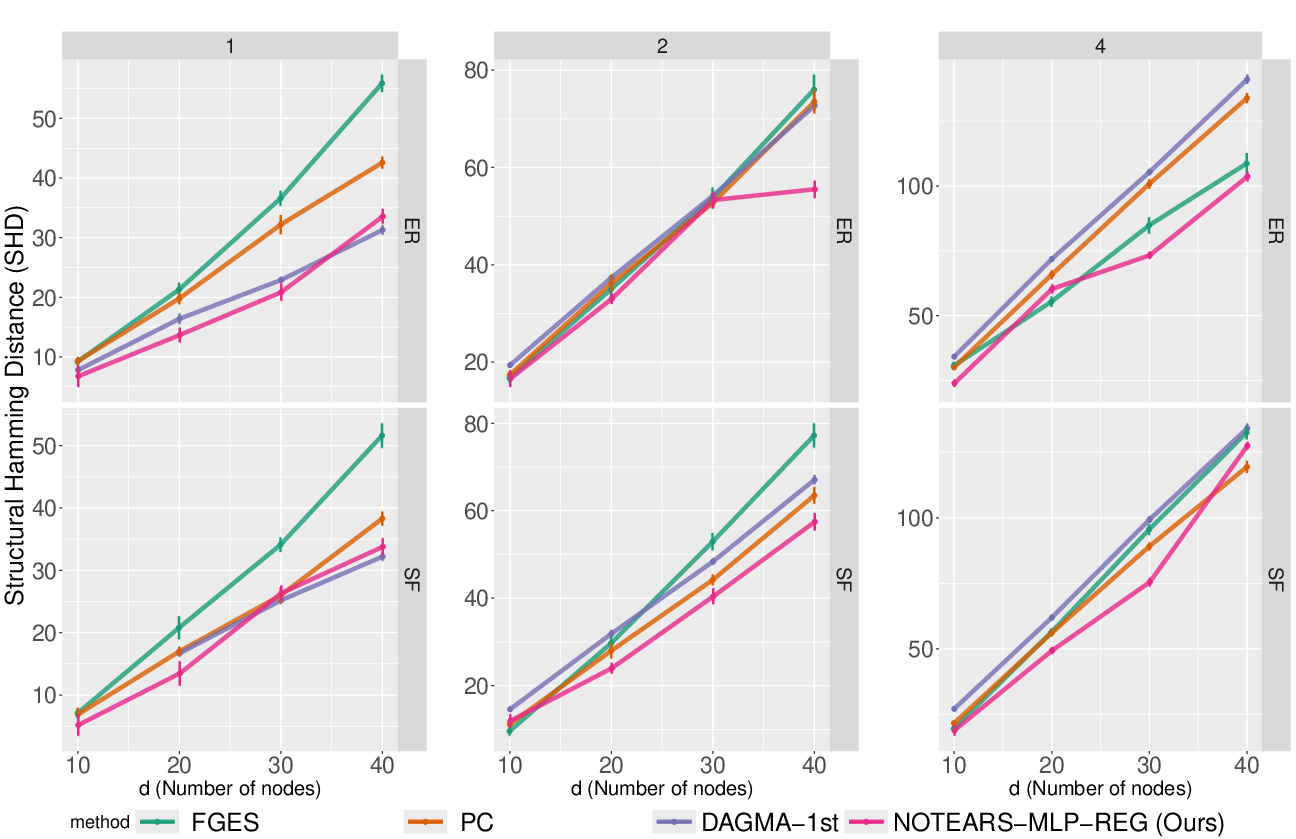
This approach is empirically validated to scale to graphs with up to 40 nodes while maintaining competitive accuracy.
Empirical Evaluation
The method is benchmarked against DAGMA, PC, FGES, and NOTEARS-MLP on synthetic data generated from various random graph models (Erdős–Rényi and scale-free) and with different types of interaction structures (first order, second order, highest order, and combinations thereof).
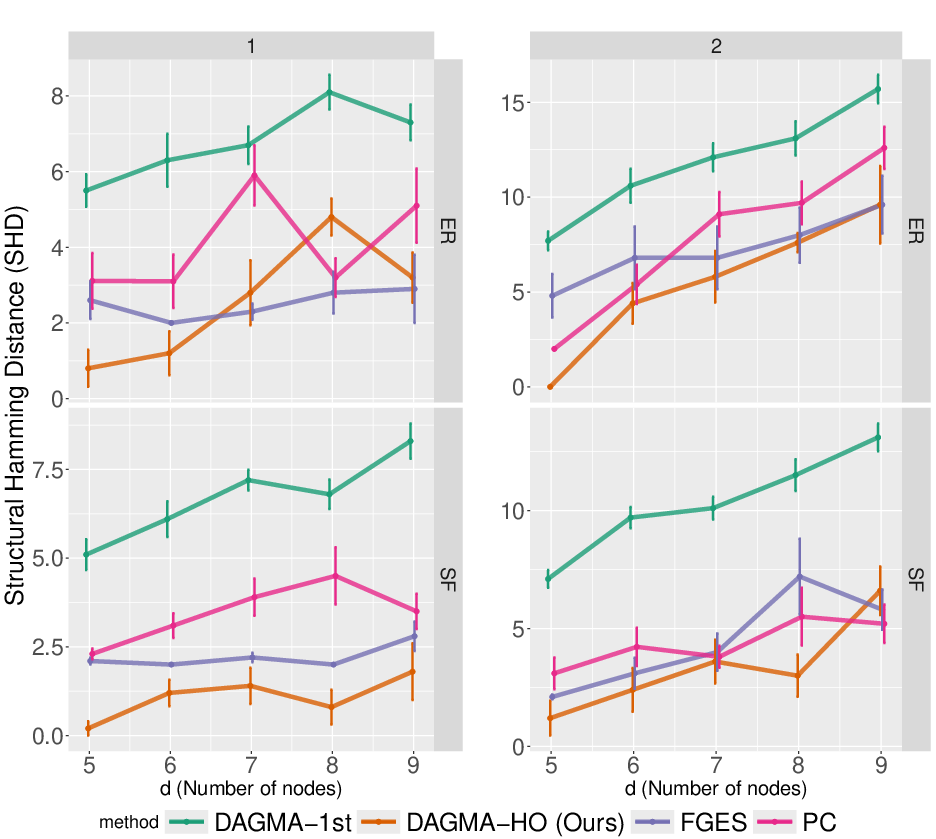
Figure 1: Results in terms of SHD between MECs of estimated graph and ground truth for small graphs (p=5–$9$), with both first and second order interactions. Lower SHD indicates better recovery.
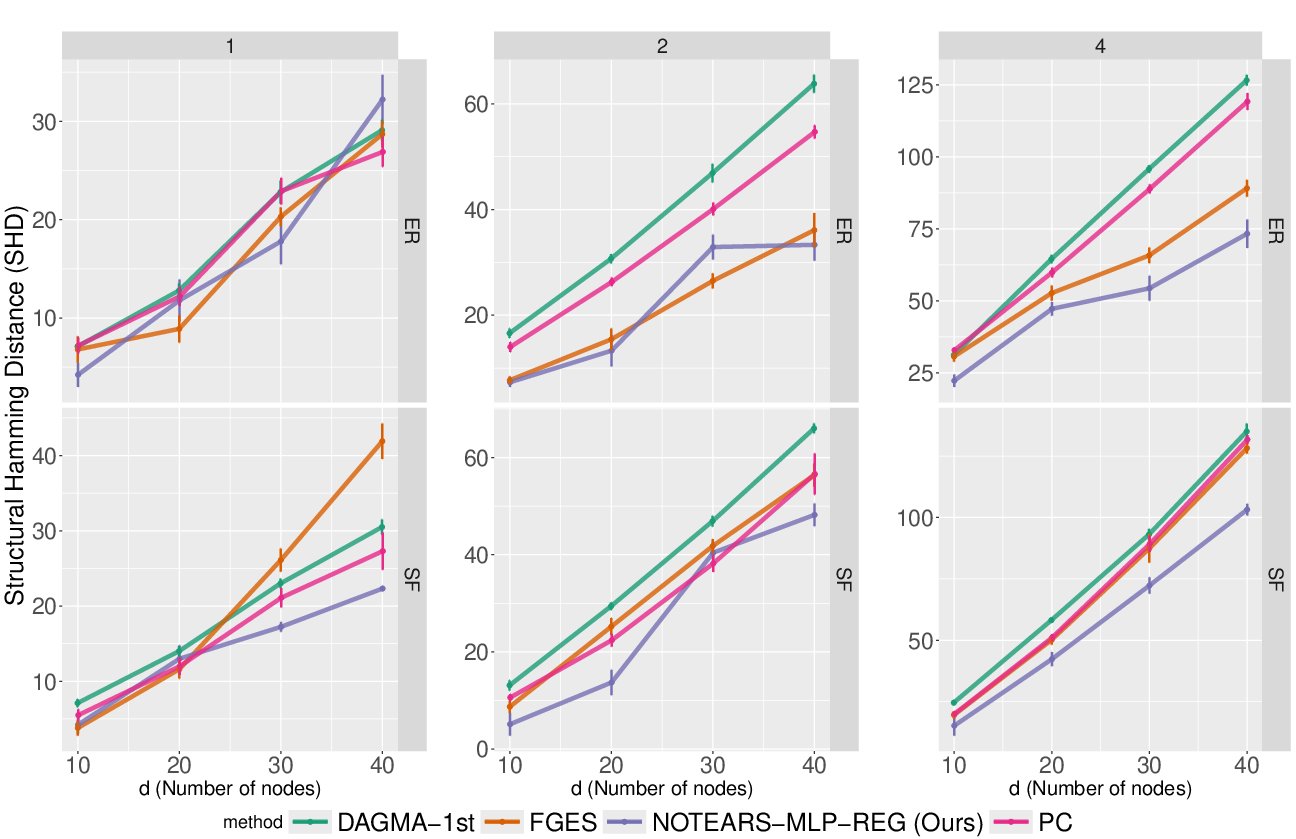
Figure 2: SHD results for large graphs (p=10–$40$), using the two-stage Notears-MLP-reg approach. The method maintains robustness as graph size and density increase.
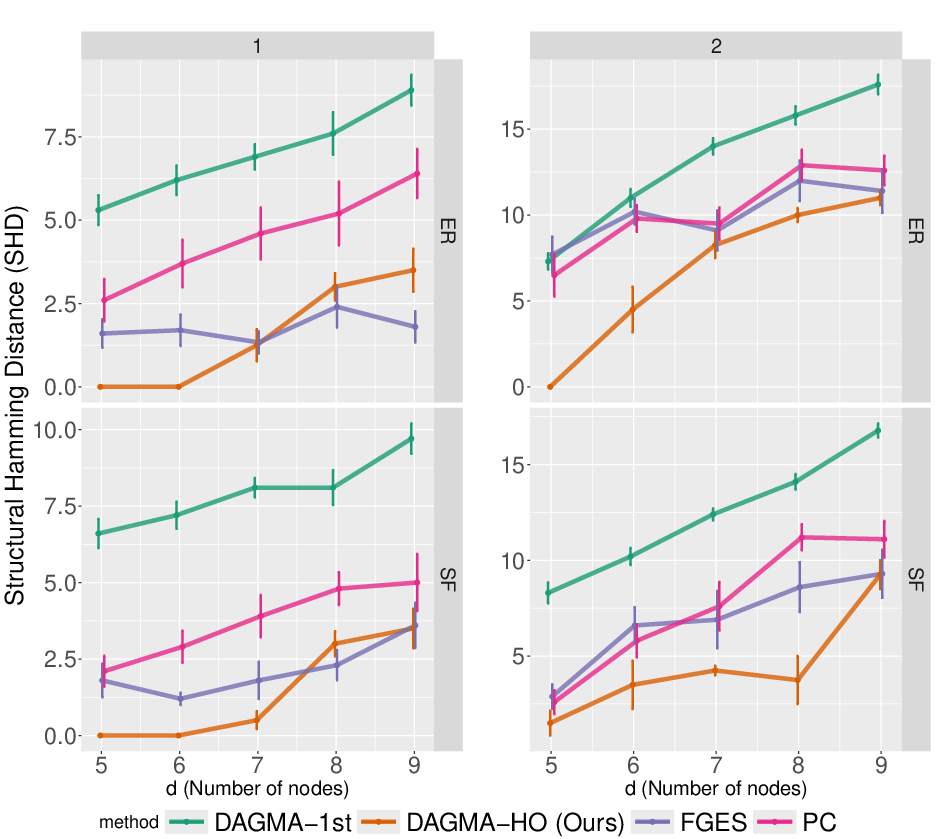
Figure 3: SHD results for data generated with only second order interactions, highlighting the failure of linear-only methods and the efficacy of the proposed approach.
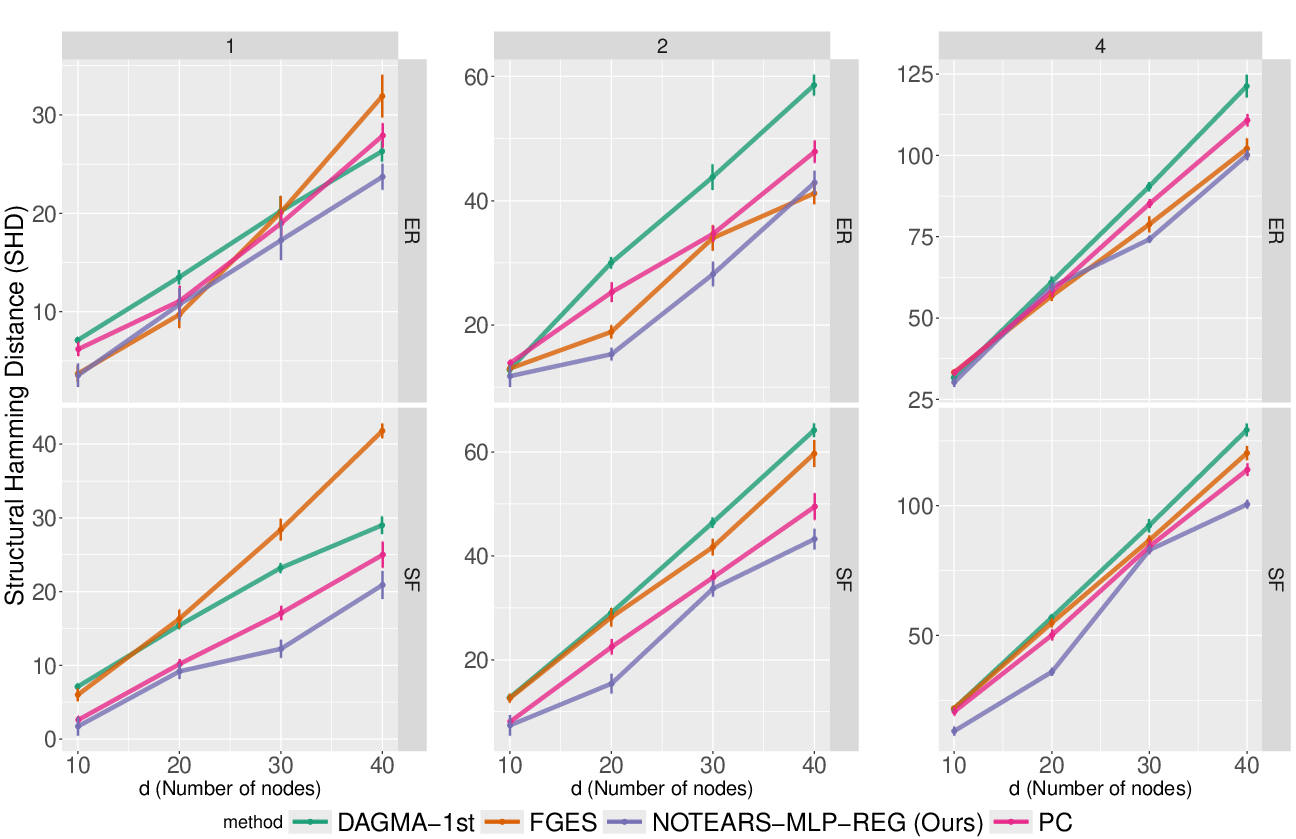
Figure 4: SHD results for data generated with only highest order interactions, demonstrating the necessity of modeling higher-order dependencies.
Key empirical findings:
Linear-only methods (e.g., DAGMA-1st) perform poorly when higher-order interactions are present, often failing to recover the true structure.
The proposed method (dagma-ho) achieves near-optimal recovery in settings with complex dependencies, outperforming baselines.
The two-stage Notears-MLP-reg approach scales to larger graphs with only modest degradation in performance.
Implications and Future Directions
Theoretical Implications
The work provides a complete characterization of non-identifiability in general discrete structure learning, extending beyond the standard Markov equivalence to a full enumeration of compatible DAG-parameter pairs.
The differentiable optimization framework is provably consistent (up to Markov equivalence) under mild assumptions, even in the presence of arbitrary higher-order dependencies.
Practical Implications
The framework enables differentiable, gradient-based structure learning for arbitrary binary data, removing the need for restrictive generative assumptions.
The two-stage heuristic offers a scalable solution for moderate-sized graphs, making the approach applicable to real-world datasets with tens of variables.
Limitations and Open Problems
The full MVB parameterization is computationally intractable for large p; further research is needed on scalable approximations that retain theoretical guarantees.
The two-stage approach, while effective empirically, lacks formal consistency guarantees.
Extension to general discrete (non-binary) data is straightforward in principle but may require additional engineering for efficiency.
Future Developments
Development of scalable, theoretically justified algorithms for high-dimensional discrete structure learning, possibly leveraging sparsity, low-rank approximations, or neural architectures.
Investigation of identifiability under interventional or multi-environment data, where stronger recovery guarantees may be possible.
Application to domains with complex discrete data, such as genomics, social networks, and survey analysis.
Conclusion
This work establishes a rigorous, general, and differentiable framework for structure learning in binary data, overcoming the limitations of prior methods that rely on restrictive parametric assumptions. By leveraging the full expressivity of the multivariate Bernoulli distribution and formulating the learning problem as a single differentiable program, the approach enables accurate recovery of complex causal structures, including higher-order dependencies. Theoretical results guarantee recovery up to Markov equivalence under mild assumptions, and empirical results demonstrate strong performance across a range of settings. The proposed two-stage heuristic extends applicability to larger graphs, though further work is needed to ensure scalability and consistency in high dimensions. This framework lays the foundation for future advances in differentiable causal discovery for discrete data.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.