- The paper achieves up to a 99.9% reduction in transmission data by using compact ViT embeddings for urban traffic surveillance.
- The paper employs a pipeline combining YOLOv11-based instance segmentation and ViT to generate 768-dimensional embeddings robust to channel impairments via quantization encoding.
- The paper integrates a fine-tuned LLaVA 1.5 model for rapid, context-aware traffic descriptions, demonstrating high real-time response accuracy despite embedding compression.
Semantic Edge-Cloud Communication for Real-Time Urban Traffic Surveillance with ViT and LLMs
Introduction and Motivation
This paper presents a comprehensive semantic communication framework for real-time urban traffic surveillance, leveraging Vision Transformers (ViT) and multimodal LLMs over mobile networks. The motivation stems from the need to efficiently transmit and interpret high-resolution traffic camera feeds in bandwidth-constrained edge-cloud architectures, enabling intelligent traffic monitoring, vehicle tracking, and collision prevention in smart cities. The proposed system addresses the computational infeasibility of deploying multimodal LLMs on edge devices and the latency bottlenecks of transmitting raw images to the cloud by introducing a semantic pipeline that transmits compact, task-relevant visual embeddings.
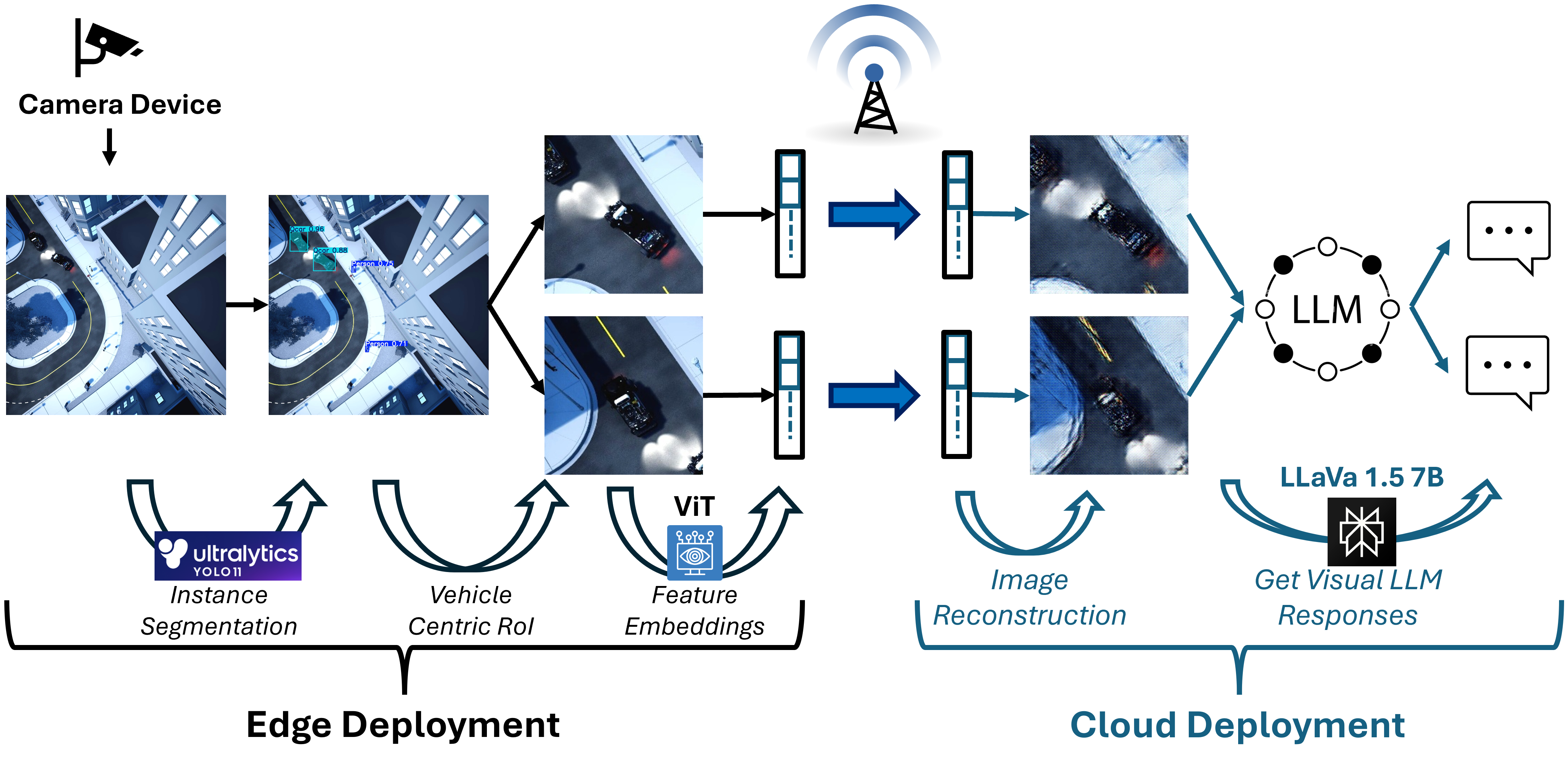
Figure 1: Overall Workflow Semantic Communication and Traffic Monitoring Pipeline, Including Instance Segmentation, Vision Transformer and LLaVA Model.
System Architecture and Methodology
The framework consists of several tightly integrated modules:
- Data Acquisition: Traffic scenes are simulated using the Quanser Interactive Lab (Qlab), providing high-fidelity, timestamped RGB images (2048×2048) from distributed edge cameras.

Figure 2: Quanser Interactive Lab and QCar.
- Instance Segmentation and ROI Extraction: YOLOv11 is employed for real-time vehicle detection and instance segmentation, producing bounding boxes for each vehicle. These are algorithmically converted to square ROIs, scaled to include contextual surroundings, and cropped to 224×224 for downstream processing.
Figure 3: YOLOv11 Model Output Sample.
- Vision Transformer Embedding: Each cropped ROI is encoded into a 768-dimensional vector using a pre-trained ViT (vit-base-patch16-224-in21k). This step leverages the self-attention mechanism to capture both local and global semantic relationships, facilitating efficient downstream reasoning.
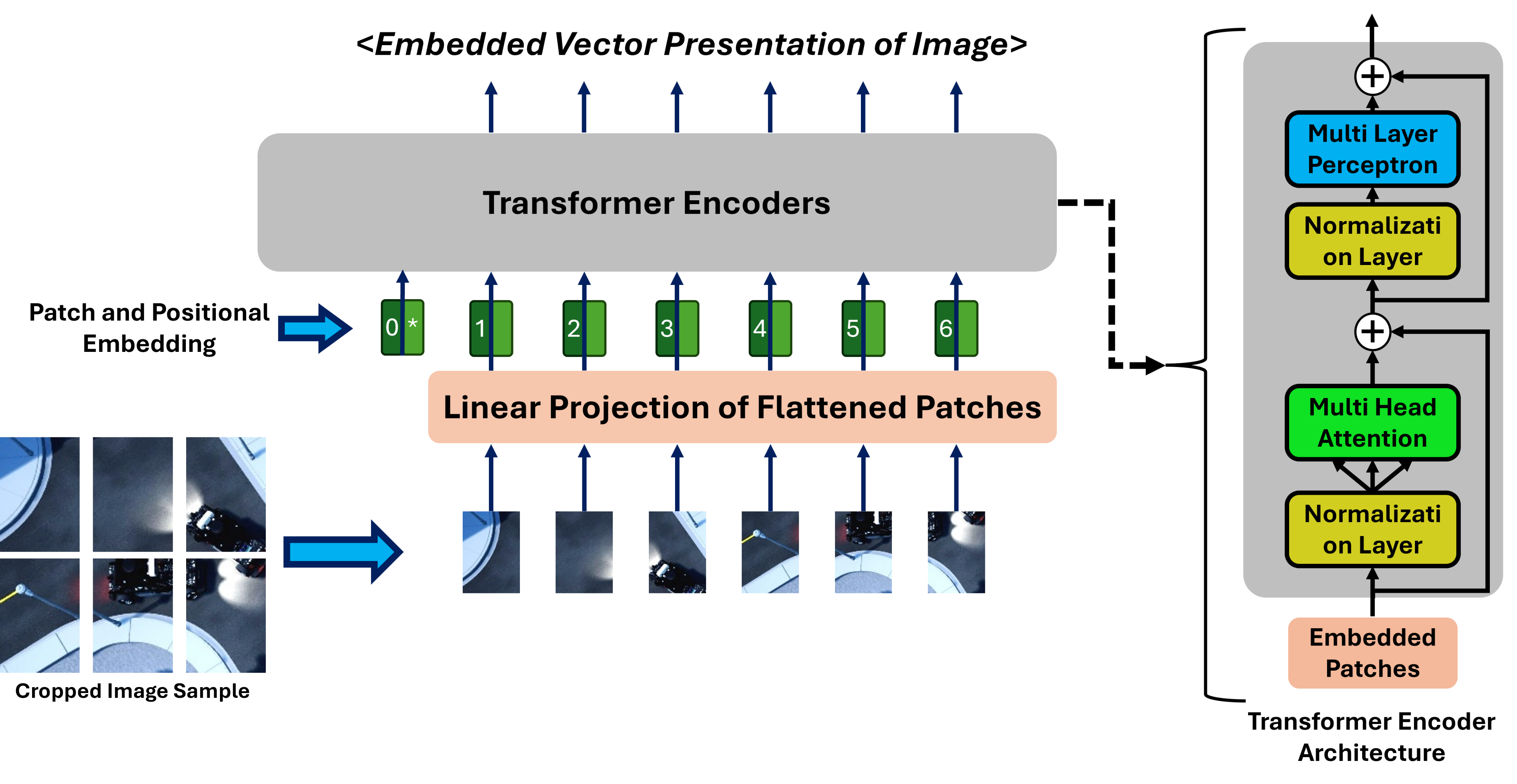
Figure 4: Vision Transformer Model and Transformer Encoder Architecture.
- Semantic Communication and Wireless Transmission: Embeddings are transmitted over an AWGN channel using either IEEE 754 floating-point or uniform quantization encoding, with BPSK and 16-QAM modulation schemes. Quantization encoding demonstrates superior robustness to bit errors and enables extreme bandwidth savings.
- Image Reconstruction: On the cloud, a custom decoder (5-layer ConvTranspose2d network) reconstructs images from received embeddings. LPIPS is used as the perceptual loss metric, ensuring reconstructions are semantically faithful.
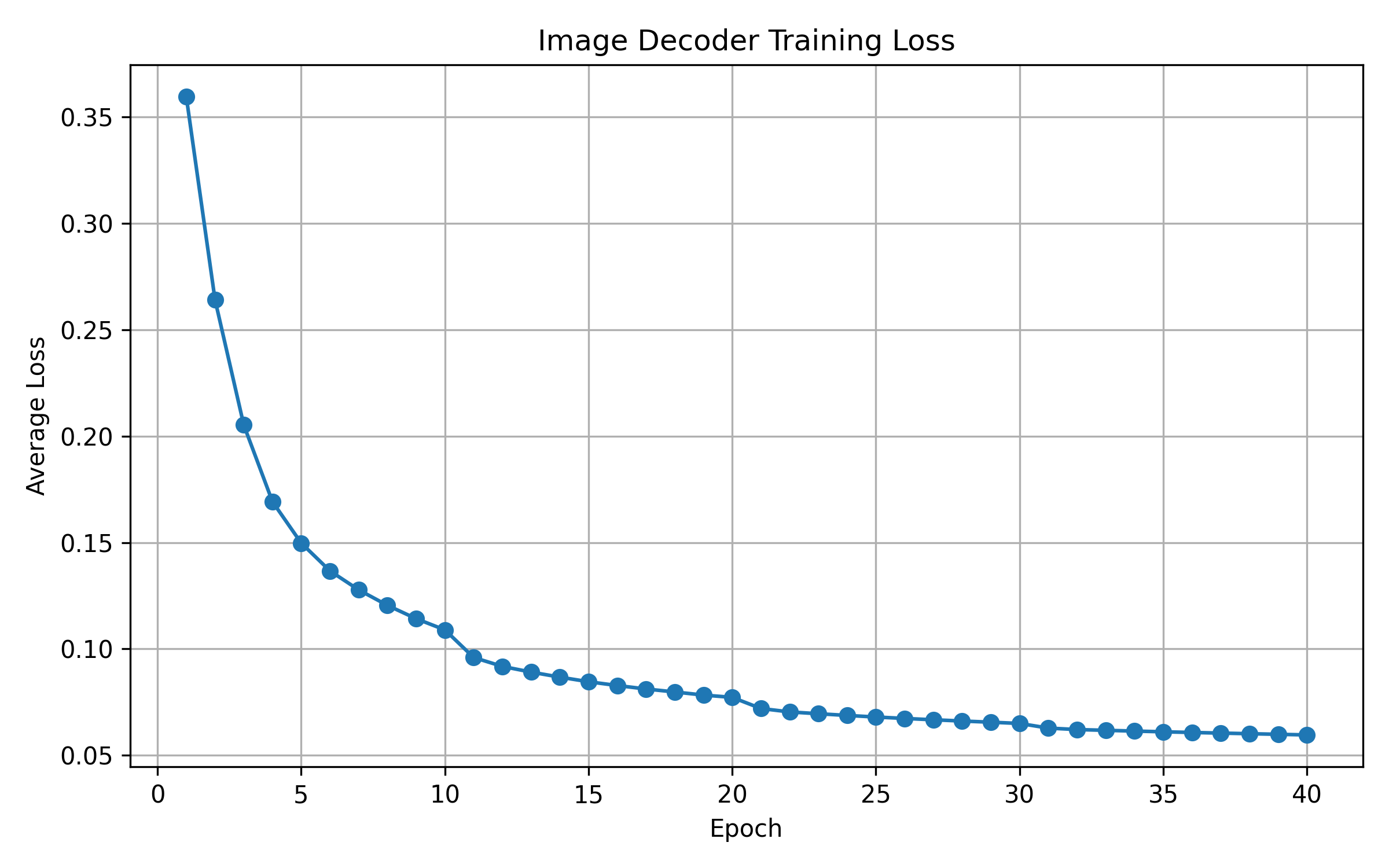
Figure 5: Convergence Plot of Image Decoder in 40 Epochs.
- Multimodal LLM Query Generation: Reconstructed images are processed by a fine-tuned LLaVA 1.5 7B model (with LoRA adaptation), generating concise, context-aware traffic descriptions. Comparative evaluation with LLaMA 3.2-11B Vision-Instruct highlights the trade-off between inference speed, resource requirements, and response granularity.

Figure 6: Large Language and Vision Assistant (LLaVA) Model (on the Right) and LoRA Fine-Tuning (on the Left).
Transmission Efficiency
The framework achieves a 99.9% reduction in transmission data size when transmitting ViT-generated embeddings compared to raw images. Cropped ROI images alone yield 93–98.5% savings, but embedding-based transmission is more stable and scalable, especially in high-density traffic scenes.
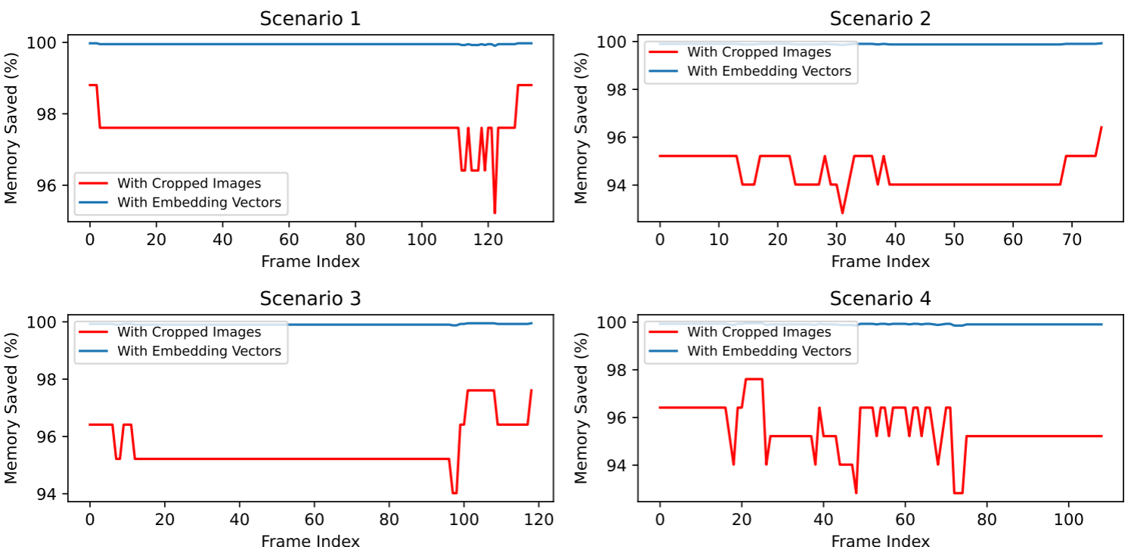
Figure 7: Memory Saving with Cropped Images and with Embedded Vectors.
Robustness to Channel Impairments
Quantization encoding (8/16/32-bit) maintains low MSE in reconstructed embeddings at moderate SNRs, outperforming IEEE 754 encoding, which is highly sensitive to bit errors and exhibits catastrophic degradation at low SNR.
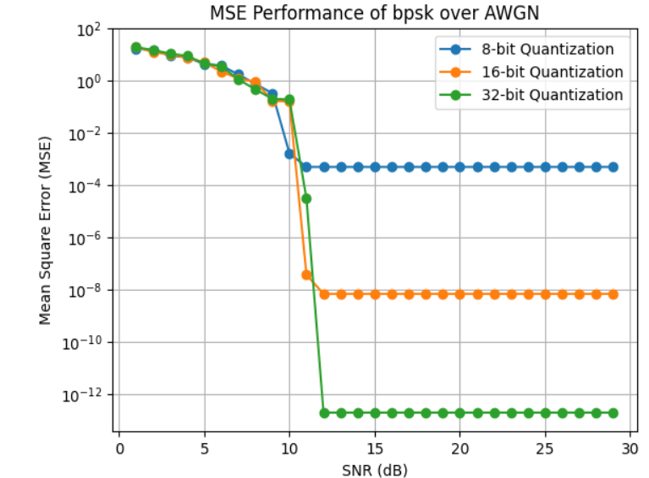
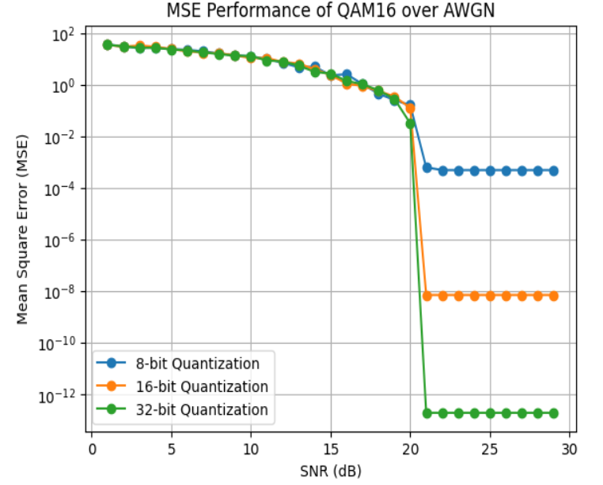
Figure 8: Comparison of MSE in reconstructed embeddings across different modulation schemes for Quantization encoding.
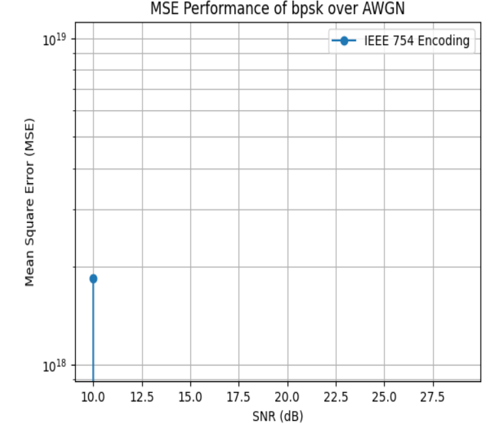
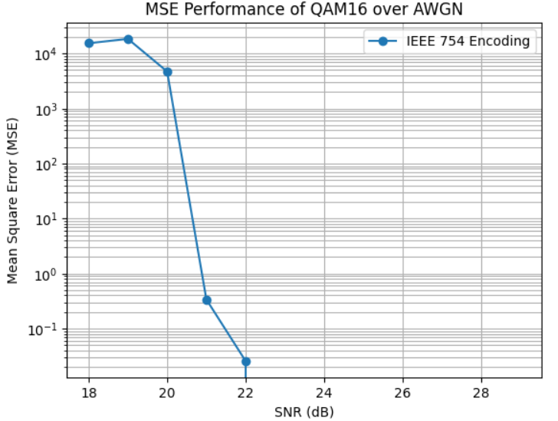
Figure 9: Comparison of MSE in reconstructed embeddings across different modulation schemes for IEEE 754 encoding.
Perceptual Quality
LPIPS scores for reconstructed images using 8-bit quantization drop to ~0.1 at 6 dB SNR, indicating high perceptual similarity. IEEE 754 encoding requires >12 dB SNR to achieve comparable quality.
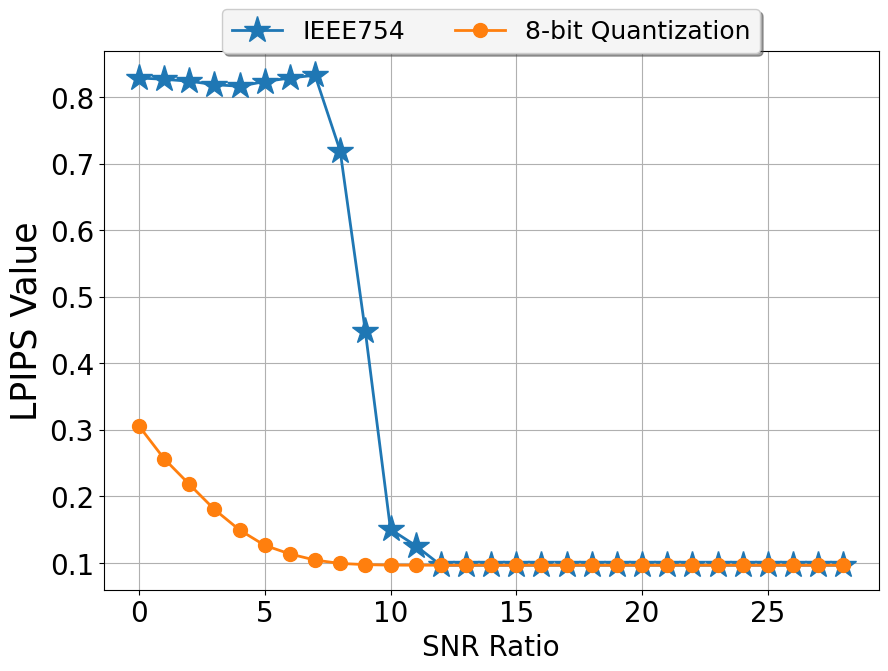
Figure 10: LPIPS value of the reconstructed images.

Figure 11: Visual comparison of original and reconstructed images transmitted using 8-bit Quantization and IEEE 754 bitstream encoding across varying SNR levels.
LLM Response Accuracy
Fine-tuned LLaVA 1.5 7B achieves 89% accuracy on reconstructed cropped images, compared to 93% on original cropped images. LLaMA 3.2-11B Vision-Instruct provides more verbose responses but incurs higher inference latency and resource consumption. LLaVA is preferable for real-time applications due to its concise outputs and lower computational requirements.

Figure 12: LLM LLaVA and LLaMA Output Comparison.
Implementation Considerations
- Edge Deployment: YOLOv11 and ViT can be efficiently deployed on edge devices with moderate GPU resources. Embedding generation incurs minimal latency (~0.16s per ROI).
- Cloud Inference: LLaVA 1.5 7B requires ~14.2 GB VRAM and 4.7 GB disk space, supporting rapid inference (<1.5s per image+prompt). LoRA fine-tuning enables efficient domain adaptation.
- Bandwidth and Scalability: Embedding-based transmission is highly scalable, with memory requirements independent of image resolution and only linearly dependent on the number of detected ROIs.
- Trade-offs: Extreme compression via embeddings introduces a modest accuracy drop in LLM responses. Quantization encoding is recommended for robust, low-bandwidth transmission.
Implications and Future Directions
The proposed semantic edge-cloud pipeline demonstrates that transformer-based visual embeddings, combined with multimodal LLMs, enable efficient, scalable, and context-aware traffic monitoring in smart cities. The framework is extensible to other ITS applications, including anomaly detection, predictive traffic management, and multi-modal sensor fusion.
Future work should explore:
- Integration of context-aware semantic communication for dynamic environments.
- Evaluation of alternative vision-LLMs (e.g., BLIP-2, Qwen-VL) for improved reasoning.
- Predictive modeling for event anticipation and proactive traffic control.
- Real-world deployment with heterogeneous edge hardware and variable network conditions.
Conclusion
This work establishes a practical and efficient semantic communication framework for real-time urban traffic surveillance, achieving near-optimal bandwidth savings and high LLM response accuracy. The integration of YOLOv11, ViT, and LLaVA 1.5 7B, with quantization-based transmission, provides a robust solution for scalable, low-latency traffic monitoring in edge-cloud architectures. The demonstrated trade-offs between transmission efficiency and inference accuracy inform future research on semantic communication systems for intelligent transportation and smart city applications.

