- The paper presents a rigorous survey of LLM architectures, benchmarks, and cross-disciplinary applications as its main contribution.
- It systematically compares models such as GPT-4, Claude, and Gemini, highlighting performance variations across academic fields.
- Practical guidelines for model selection and recommendations for future research address reliability, bias mitigation, and regulatory challenges.
Comprehensive Review of "LLMs4All: A Review on LLMs for Research and Applications in Academic Disciplines"
Introduction and Scope
"LLMs4All: A Review on LLMs for Research and Applications in Academic Disciplines" (2509.19580) provides an exhaustive, methodologically rigorous survey of the integration of LLMs across a broad spectrum of academic fields. The review is structured to address the foundational architectures, evaluation paradigms, and domain-specific applications of LLMs, with a focus on both the technical underpinnings and the practical deployment challenges. The paper is notable for its cross-disciplinary taxonomy, detailed benchmarking, and critical discussion of open problems and future research directions.
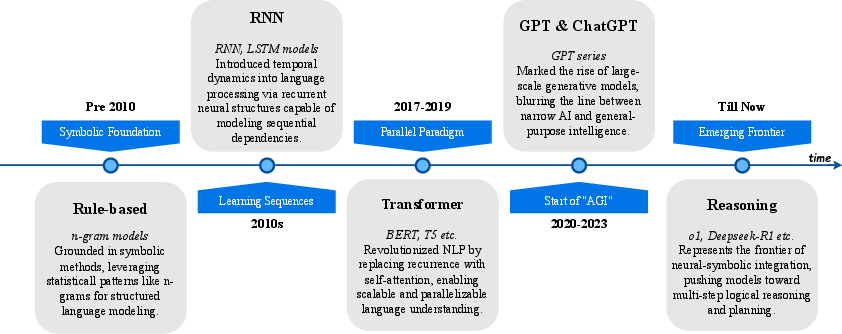
Figure 1: Key milestones in the development of LLMs, from rule-based systems to contemporary multimodal, reasoning-capable architectures.
Historical and Technical Foundations
The review begins with a precise definition of LLMs, emphasizing the transformer architecture and the pretrain–finetune paradigm. The historical trajectory is mapped from rule-based and statistical models, through the RNN and attention-based eras, to the current dominance of transformer-based LLMs. The authors highlight the emergence of autoregressive, decoder-only models (e.g., GPT series) as a methodological inflection point, enabling few-shot and zero-shot generalization and catalyzing the shift toward general-purpose AI assistants.
The survey provides a comparative analysis of major model families, including GPT-4/5, OpenAI’s reasoning models (o1, o3), Claude 3, Gemini 2, Grok, Llama 3, Qwen 2, and DeepSeek. The discussion covers architectural innovations (e.g., Mixture-of-Experts, Grouped Query Attention, Direct Preference Optimization), scaling laws, and the integration of multimodal and tool-use capabilities.
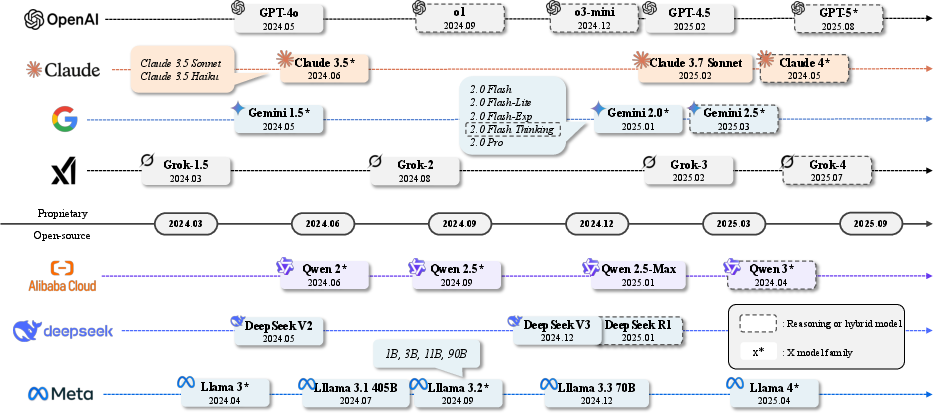
Figure 2: Chronological display of current SOTA LLMs, illustrating the rapid evolution and diversification of model architectures and capabilities.
Evaluation Paradigms and Benchmarking
A significant contribution of the paper is its systematic treatment of LLM evaluation. The authors categorize tasks into text understanding, text generation, complex reasoning, and knowledge utilization, and provide a detailed mapping of benchmarks (e.g., MMLU, BIG-Bench, HumanEval, TruthfulQA, GSM8K). The review distinguishes between basic automatic metrics (accuracy, F1, BLEU, ROUGE), advanced behavioral metrics (trustworthiness, toxicity, fairness, robustness), human evaluation, and the emerging paradigm of LLM-as-a-judge.
Performance synthesis across benchmarks reveals that no single LLM dominates all tasks. Reasoning-optimized models (e.g., DeepSeek R1, Claude 3.7 Sonnet) excel in logical and structured tasks, while general-purpose models (e.g., GPT-4.5, Gemini 2.5 Pro) offer broader but less specialized competence. The review provides actionable guidelines for model selection based on task modality, context window, latency, privacy, and cost constraints.
Cross-Disciplinary Applications
Arts, Letters, and Law
The review delineates the transformative impact of LLMs in the humanities and law, organizing applications into narrative/interpretive, quantitative/scientific, and comparative/cross-disciplinary categories.
- History: LLMs are leveraged for narrative generation, interpretive analysis, and large-scale data processing (e.g., entity extraction, timeline generation). The review notes that LLMs can simulate historical personas and psychological responses, but warns of factual hallucination, temporal reasoning deficits, and bias amplification.
- Philosophy: LLMs support normative debate, logical analysis, and cross-cultural comparison. The authors highlight the use of LLMs for simulating ethical reasoning, argument mining, and ontology mapping, while emphasizing the risks of oversimplification and lack of epistemic transparency.
- Political Science: LLMs automate text analysis (e.g., sentiment, ideology classification), simulate public opinion, and generate persuasive messaging. The review discusses the dual-use potential for both legitimate campaign optimization and disinformation, underscoring the need for bias auditing and adversarial robustness.
- Arts and Architecture: LLMs enable co-creative workflows in visual, literary, and performing arts, as well as architectural design and analysis. The review details the integration of LLMs with multimodal models for image generation, style classification, and spatial reasoning, but notes persistent challenges in creativity, context sensitivity, and authorship attribution.
- Law: LLMs are applied to legal QA, document drafting, case analysis, and judgment prediction. The review provides a taxonomy of legal tasks and discusses the use of retrieval-augmented generation, domain-specific fine-tuning, and hybrid modeling. The authors highlight strong empirical results on benchmarks such as LegalBench, but caution about factual reliability, interpretability, and jurisdictional adaptation.
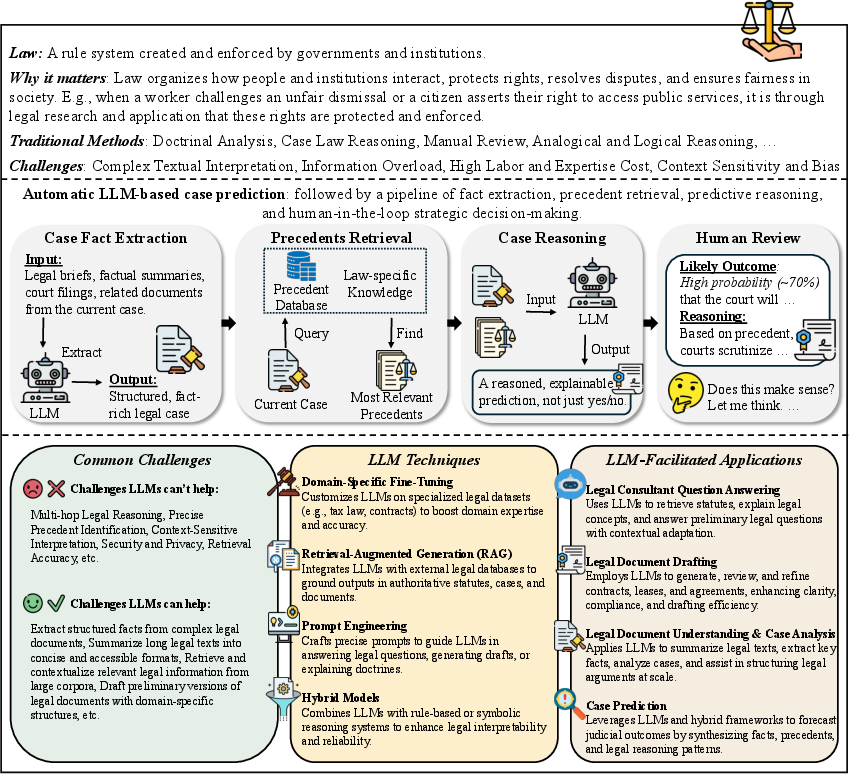
Figure 3: Overview of LLM Applications in Legal Research, mapping core challenges, key tasks, and dominant techniques.
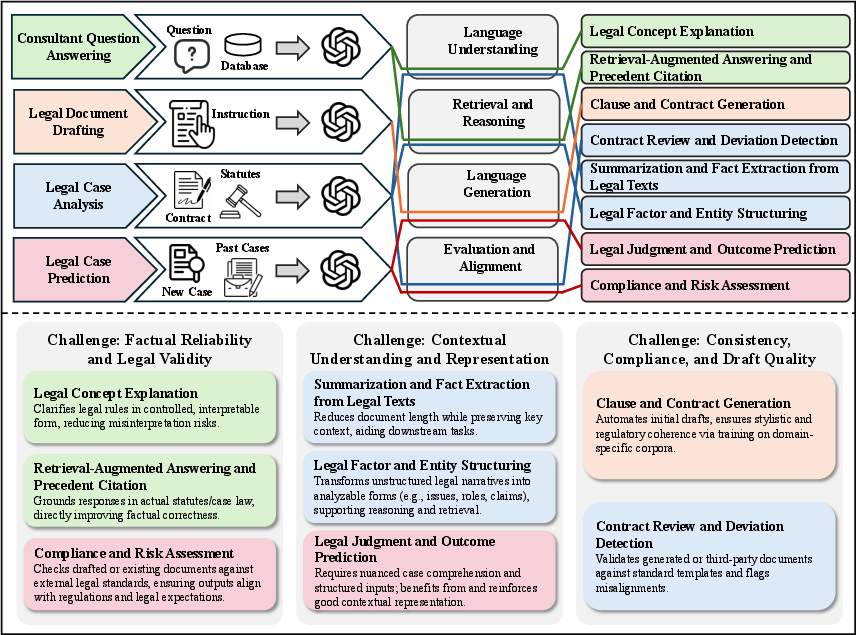
Figure 4: LLM-Driven Workflow in Legal Tasks, illustrating end-to-end paradigms for consultant QA, drafting, analysis, and prediction.
Economics and Business
- Finance: LLMs are deployed for trading, portfolio management, financial report analysis, stock movement prediction, fraud detection, credit scoring, ESG scoring, and robo-advisory. The review synthesizes results from multi-agent LLM systems, multimodal integration, and domain-specific fine-tuning, noting strong gains in interpretability and adaptability but persistent limitations in numerical reasoning and robustness to distribution shifts.
- Economics: LLMs are used for behavioral simulation, agent-based macroeconomic modeling, strategic/game-theoretic interaction, and economic reasoning. The review highlights the use of LLMs as synthetic agents in experimental economics, but points to challenges in rationality, prompt sensitivity, and causal inference.
- Accounting: LLMs enhance auditing, financial/managerial accounting, and taxation through automation, co-piloting, and compliance checks. The review discusses the integration of LLMs with RPA, the use of domain-specific models (e.g., TaxBERT), and the need for explainable, verifiable outputs.
- Marketing: LLMs support consumer insight extraction, content generation, campaign design, and market intelligence. The review emphasizes the scalability and personalization enabled by LLMs, while noting the risks of bias, hallucination, and lack of causal inference.
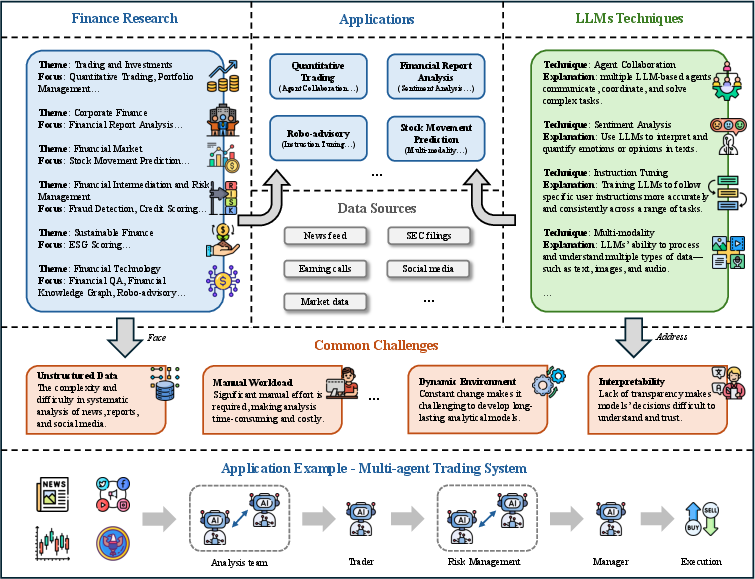
Figure 5: Overview of LLMs' Applications in Finance Research, mapping subfields and representative use cases.
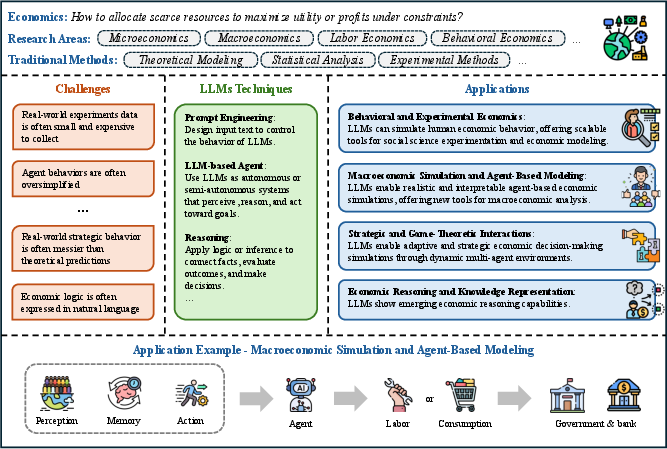
Figure 6: Overview of LLMs' Applications in Economics Research, highlighting behavioral, macro, strategic, and reasoning tasks.
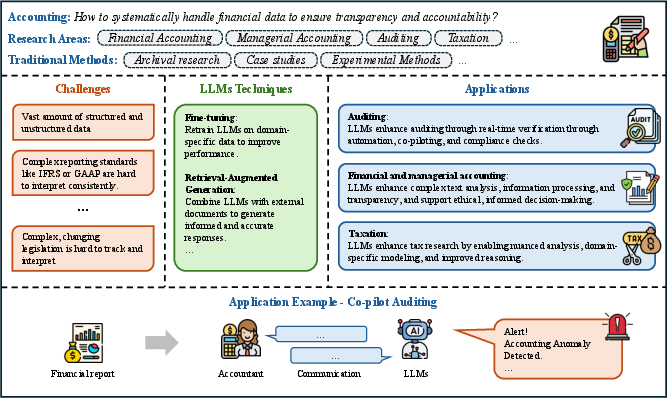
Figure 7: Overview of LLMs' Applications in Accounting Research, spanning auditing, reporting, and taxation.
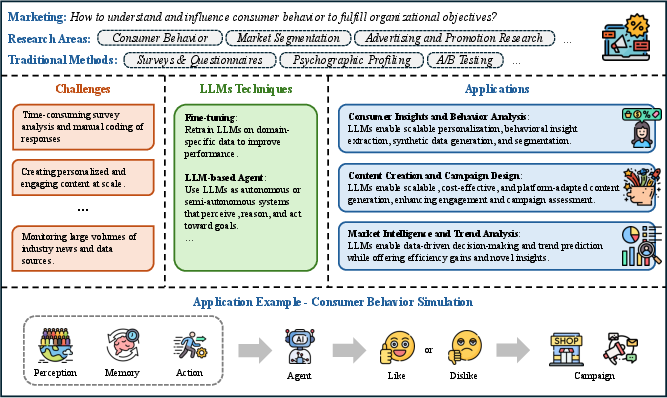
Figure 8: Overview of LLMs' Applications in Marketing Research, covering consumer insights, content, and trend analysis.
Science and Engineering
- Mathematics: LLMs are applied to proof assistance, conjecture generation, pattern recognition, and education. The review details the integration of LLMs with formal proof systems (e.g., Lean, Metamath), the use of evolutionary programming (e.g., AlphaEvolve), and the impact on personalized learning. The authors report that LLMs now outperform traditional proof assistants on several benchmarks, but highlight ongoing limitations in multi-step reasoning and abstraction.
- Physics and Mechanical Engineering: LLMs support documentation, design ideation, simulation, and experiment interpretation. The review discusses the use of LLMs for parametric drafting, multimodal lab analysis, and interactive reasoning, but notes challenges in integrating physical constraints and domain-specific knowledge.
- Chemistry and Chemical Engineering: LLMs are used for molecular reasoning, property prediction, materials optimization, and reaction-data organization. The review emphasizes the role of LLMs in automating literature mining, hypothesis generation, and experimental planning.
- Life Sciences and Bioengineering: LLMs facilitate genomic analysis, clinical data integration, biomedical reasoning, and hybrid outcome prediction. The review highlights the need for rigorous validation and domain adaptation.
- Earth Sciences and Civil Engineering: LLMs are applied to geospatial data analysis, simulation, document workflows, and predictive maintenance. The review discusses the integration of LLMs with physical modeling pipelines and the challenges of long-context reasoning.
- Computer Science and Electrical Engineering: LLMs are leveraged for code generation, debugging, large-codebase analysis, hardware description, and functional verification. The review details the use of LLMs for high-level synthesis and the need for purpose-built benchmarks.
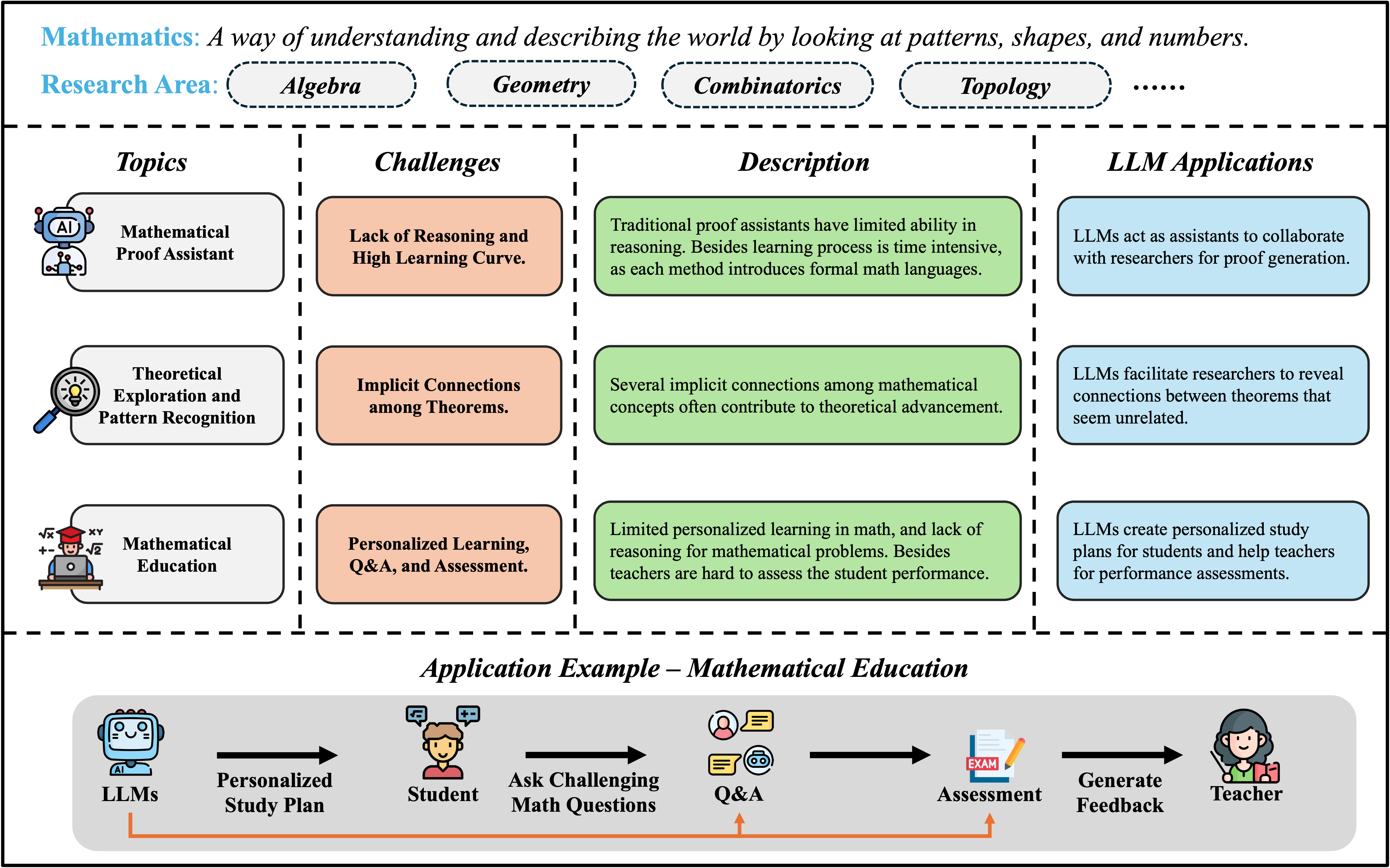
Figure 9: Overview of topics in Mathematics Discipline with LLMs solution, mapping proof assistance, exploration, and education.
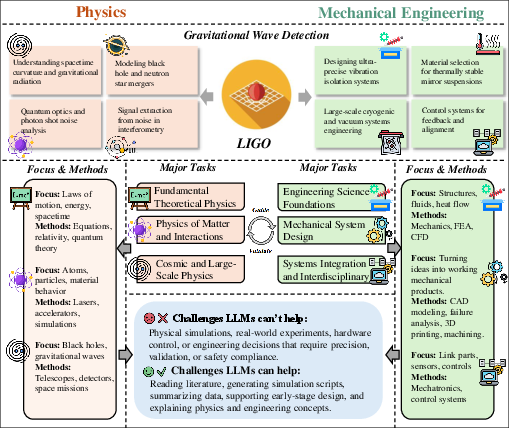
Figure 10: The relationships between major research tasks between physics and mechanical engineering.
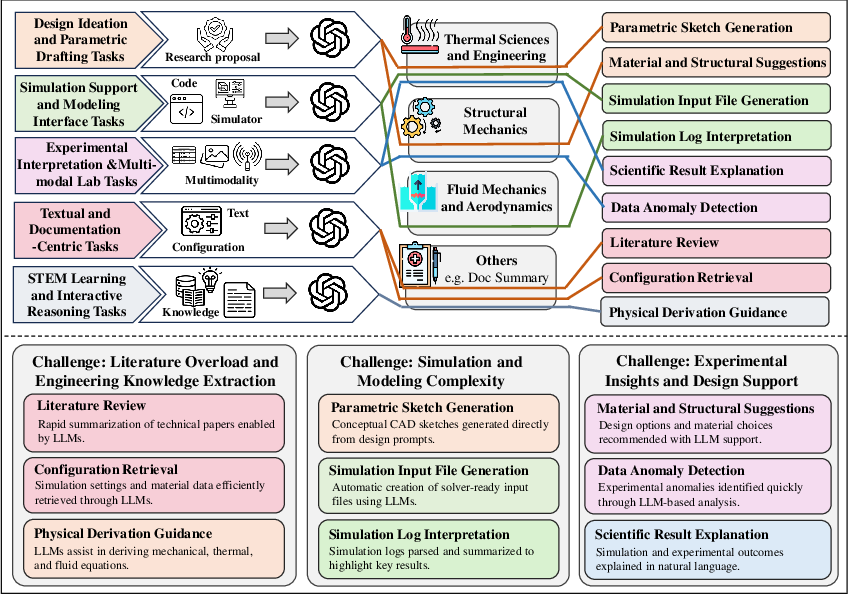
Figure 11: The pipelines of physics and mechanical engineering.
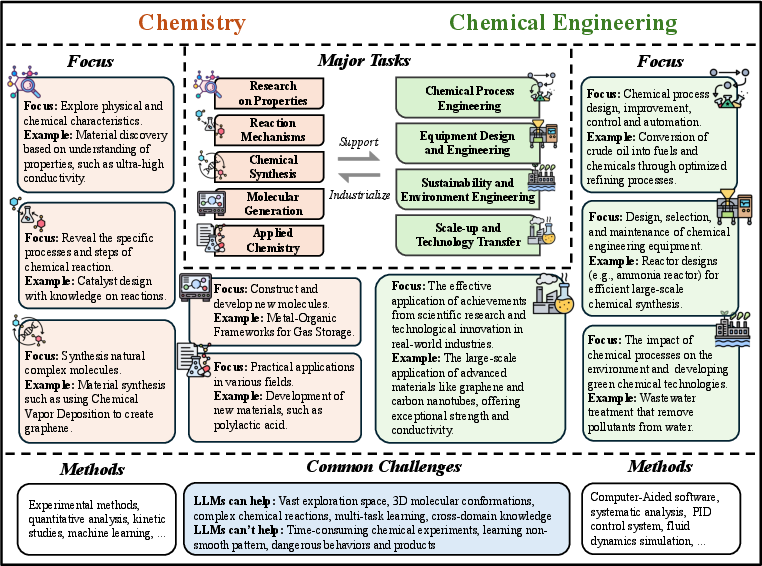
Figure 12: The relationships between major research tasks in chemistry and chemical engineering.
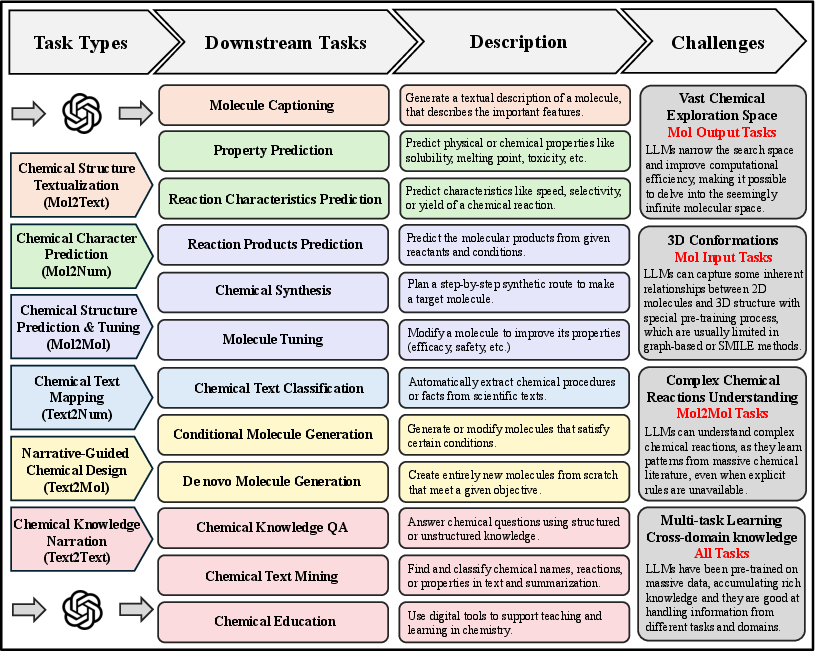
Figure 13: A taxonomy of chemical tasks enabled by LLMs, categorized by input-output types and downstream objectives.
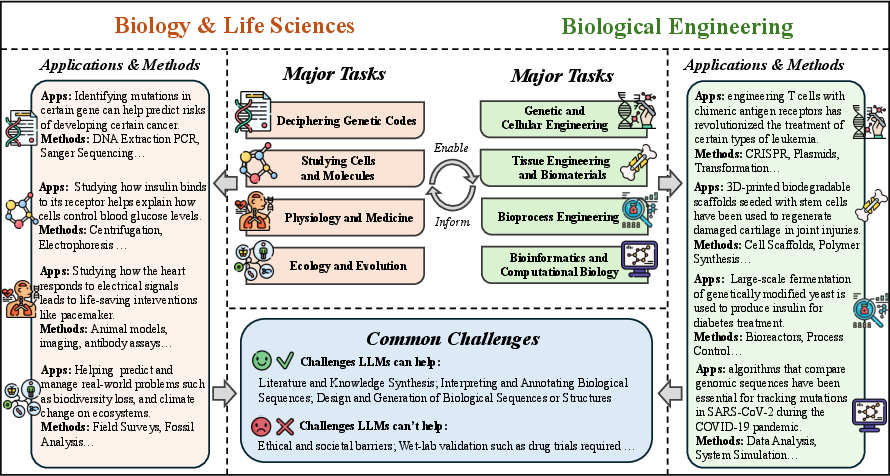
Figure 14: The relationships between major research tasks between biology and bio-engineering.
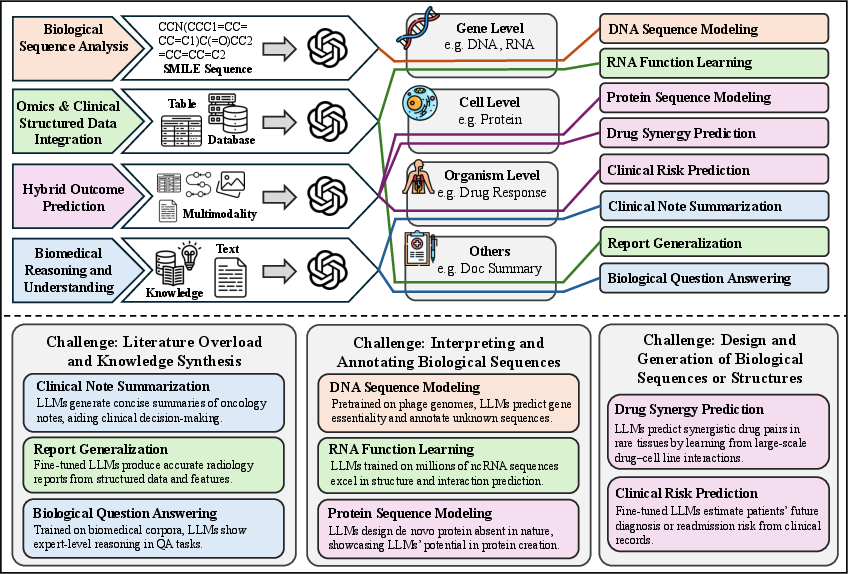
Figure 15: Taxonomy for life sciences and bio-engineering.
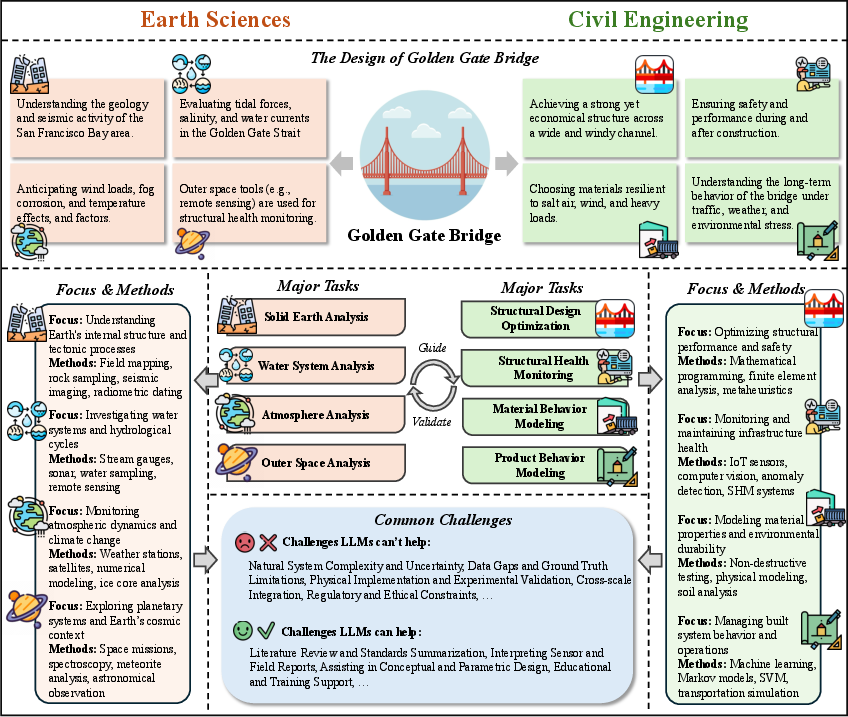
Figure 16: The relationships between major research tasks between earth sciences and civil engineering.
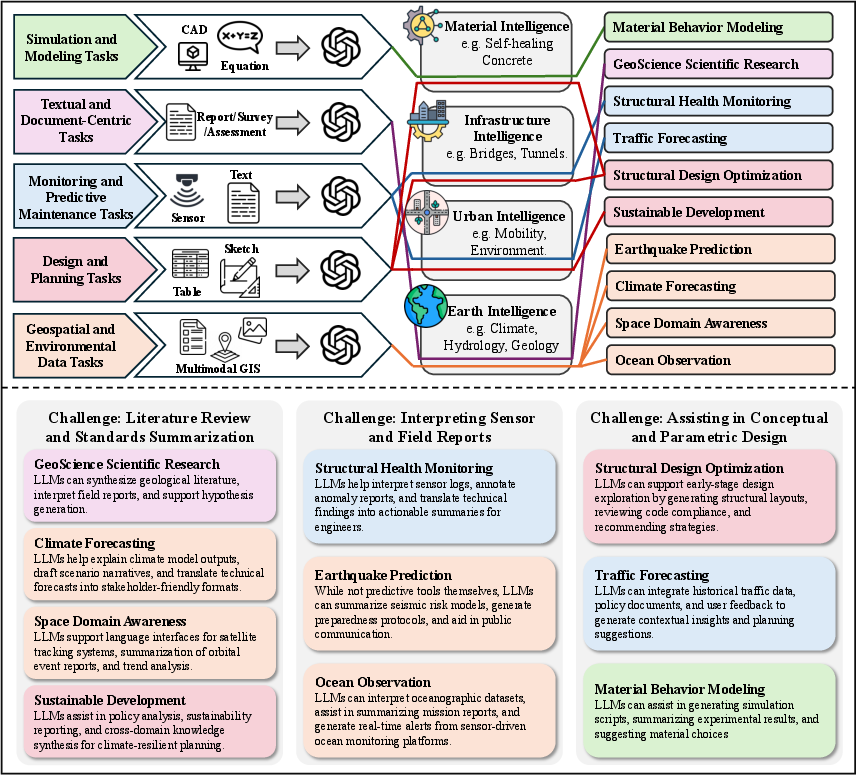
Figure 17: The pipelines of Earth sciences and civil engineering.
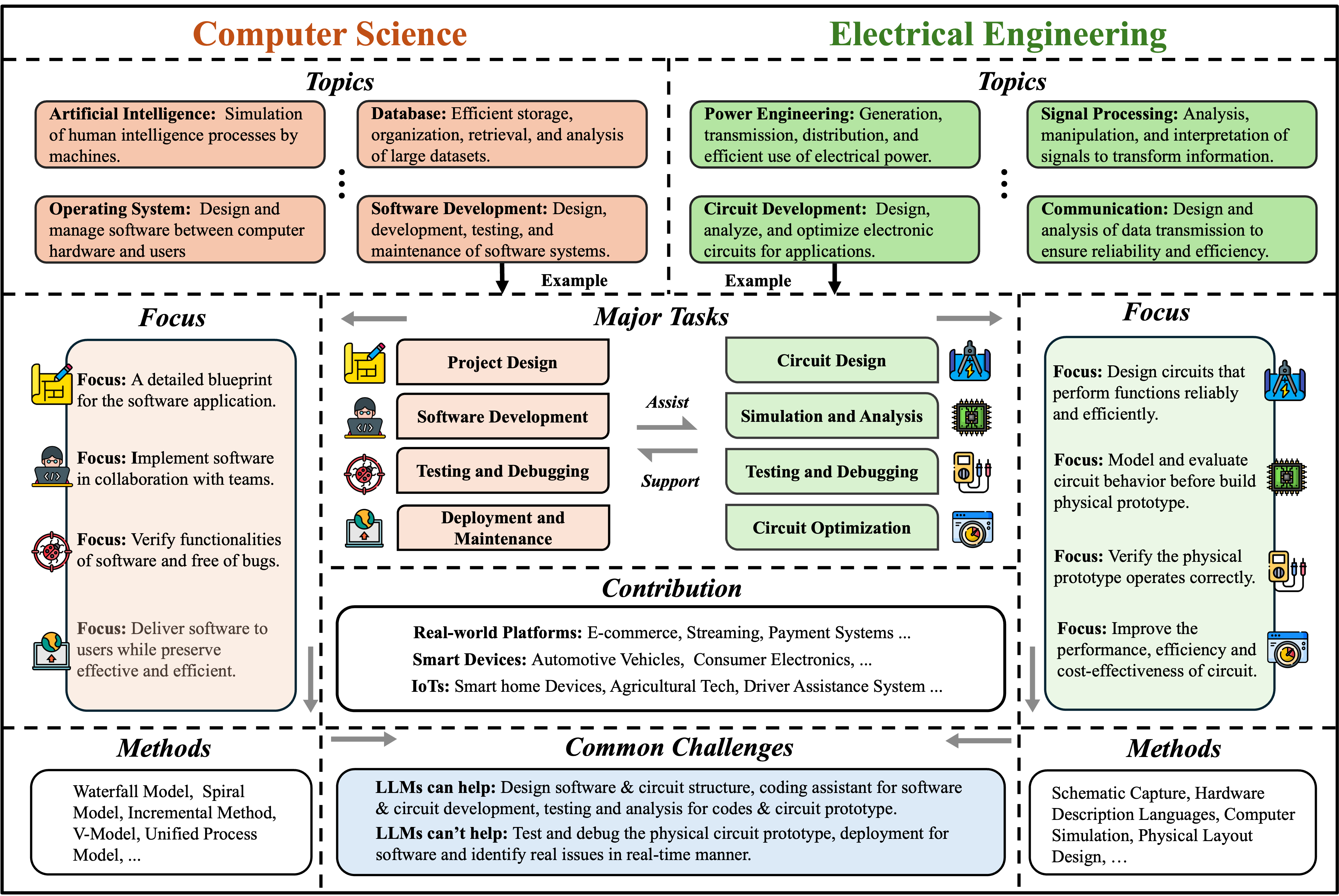
Figure 18: The relationships between software development in computer science and circuit design in electrical engineering.
Limitations, Open Challenges, and Future Directions
The review is explicit in its discussion of LLM limitations:
- Factual Hallucination and Reliability: LLMs remain prone to generating plausible but incorrect outputs, especially in high-stakes domains (e.g., law, finance, medicine).
- Reasoning and Abstraction: Multi-step, causal, and domain-specific reasoning remain challenging, with performance degrading on complex or novel tasks.
- Bias and Representation: LLMs inherit and may amplify biases present in training data, risking the marginalization of underrepresented perspectives.
- Transparency and Attribution: The lack of source citation and explainability complicates verification and trust, particularly in academic and legal contexts.
- Domain Adaptation and Robustness: General-purpose LLMs often underperform in specialized domains, necessitating fine-tuning, retrieval augmentation, and hybrid modeling.
- Ethical and Regulatory Concerns: Issues of privacy, liability, and governance are acute in sensitive applications, requiring human-in-the-loop oversight and transparent audit trails.
The authors propose a set of research directions:
- Schema-Aligned Multimodality and Grounded Attribution: Integrating structured data, multimodal inputs, and source-grounded outputs to enhance reliability and interpretability.
- Tool-Augmented and Rule-Governed Computation: Embedding LLMs within formal, tool-augmented pipelines to enforce domain constraints and reproducibility.
- Agentic Simulation and Temporal-Causal Adaptation: Advancing agent-based, temporally aware models for dynamic, interactive reasoning.
- Human Oversight and Transparent Governance: Developing frameworks for human-in-the-loop control, safety, and compliance.
- Education-Led Capacity Building: Leveraging LLMs for scalable, personalized education while embedding safety and ethical guardrails.
Implications and Future Outlook
The review provides a practical, auditable, and scalable blueprint for cross-disciplinary LLM adoption. It emphasizes that LLMs are not panaceas, but powerful tools that, when properly aligned, can augment human expertise, accelerate discovery, and democratize access to knowledge. The synthesis of model architectures, evaluation paradigms, and domain-specific applications offers a common vocabulary and task taxonomy for researchers and practitioners.
The authors anticipate ongoing developments as LLMs evolve toward greater reasoning, multimodality, and agentic autonomy. They stress the importance of defensible evaluation, failure mode anticipation, and responsible governance to ensure that LLMs deliver reliable, auditable, and genuinely useful capabilities across academic disciplines.
Conclusion
"LLMs4All" stands as a comprehensive, technically rigorous reference for the state of LLM research and application in academia. Its cross-disciplinary taxonomy, detailed benchmarking, and critical discussion of limitations and future directions provide a valuable resource for both researchers and practitioners. The review’s emphasis on methodological soundness, domain adaptation, and responsible deployment will inform the next generation of LLM research and real-world adoption.