AuditoryBench++: Can Language Models Understand Auditory Knowledge without Hearing?
Abstract: Even without directly hearing sounds, humans can effortlessly reason about auditory properties, such as pitch, loudness, or sound-source associations, drawing on auditory commonsense. In contrast, LLMs often lack this capability, limiting their effectiveness in multimodal interactions. As an initial step to address this gap, we present AuditoryBench++, a comprehensive benchmark for evaluating auditory knowledge and reasoning in text-only settings. The benchmark encompasses tasks that range from basic auditory comparisons to contextually grounded reasoning, enabling fine-grained analysis of how models process and integrate auditory concepts. In addition, we introduce AIR-CoT, a novel auditory imagination reasoning method that generates and integrates auditory information during inference through span detection with special tokens and knowledge injection. Extensive experiments with recent LLMs and Multimodal LLMs demonstrate that AIR-CoT generally outperforms both the off-the-shelf models and those augmented with auditory knowledge. The project page is available at https://auditorybenchpp.github.io.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: can AI LLMs understand sounds (like pitch, loudness, and which animal makes which noise) even when they don’t actually hear anything? Humans can imagine the sound of thunder just by reading “stormy night.” The authors built a new test and a new method to see if AI can do that kind of “auditory imagination” too.
Key Questions or Goals
The paper focuses on three easy-to-understand goals:
- Can LLMs reason about sound-related ideas using only text?
- How well do current models handle basic sound facts (like which instrument has a higher pitch) and more complex sound situations (like what’s happening in a scene based on sound clues)?
- Can we teach models to “imagine” sound when needed, so they make better decisions without any actual audio?
How They Did It
AuditoryBench++: a “test suite” for sound knowledge in text
The authors created AuditoryBench++, a set of five tasks that check whether a model understands sound in different ways using only text. Here are the tasks:
- Pitch Comparison: Choose which of two sounds is higher in pitch (like comparing violin vs. cello).
- Duration Comparison: Decide which described sound lasts longer.
- Loudness Comparison: Pick which sound is louder.
- Animal Sound Recognition: Match an onomatopoeia (like “meow”) to the correct animal.
- Auditory Context Reasoning: Answer questions that need understanding sound in everyday situations (for example, linking a description of events and their likely sounds).
To build this test suite, they carefully gathered and cleaned data from multiple sources, removed confusing or unfair examples, and had humans verify the final questions. The idea is to create clear, fair problems that don’t require hearing actual audio.
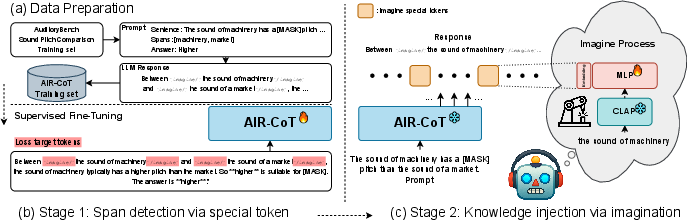
AIR-CoT: teaching models to “imagine” sounds while thinking
The paper introduces a method called AIR-CoT (Auditory Imagination Reasoning with Chain-of-Thought). Think of it like telling the model, “If you need sound knowledge, pause and imagine it, then continue reasoning.”
Here’s how it works, in everyday terms:
- Special signal for imagination: The model learns to insert a special token, like
[imagine], in its answer whenever it reaches a part where sound understanding is needed. This token is a simple flag that means “I need auditory info here.” - Pause and inject “sound knowledge”: When the model hits the closing token
[/imagine], it pauses and uses a tool (called CLAP) that turns sound descriptions into numerical “embeddings.” You can think of an embedding as a compact “fingerprint” that captures key properties of a sound (like what it is and its qualities). - Keep thinking, now with auditory help: The model “injects” that sound fingerprint into its reasoning steps and continues its chain-of-thought with better sound understanding.
Some technical terms explained simply:
- Benchmark: A standardized test to measure how good a model is at something.
- Chain-of-Thought (CoT): The model’s step-by-step reasoning process, like showing your work in math.
- Embedding: A set of numbers that represent something (like a sound or a sentence) in a way the model can use.
- CLAP: A model that can turn audio or audio-related text into embeddings, helping AI link sounds and language.
Main Findings and Why They Matter
- Without any help, most LLMs did poorly on the new sound tests when only text was available. They often performed near random in basic comparisons.
- AIR-CoT improved results a lot on:
- Pitch Comparison
- Animal Sound Recognition
- Auditory Context Reasoning
In these areas, “imagining” sound during the reasoning process made the model much smarter.
- Improvements were smaller for Duration and Loudness. Why? Current sound embeddings are great at capturing “what” a sound is (its meaning), but not as good at exact time length (duration) or exact volume (loudness). These require precise timing and amplitude information that typical embeddings don’t represent well.
This shows that giving models an imagination step can boost their reasoning about sound—especially when the task depends on sound meaning or typical sound associations.
Implications and Impact
- Better reading comprehension: Models could answer story questions that involve sound without needing audio—like inferring that “sirens” mean an emergency, or that “soft footsteps” suggest quiet movement.
- Smarter assistants: Chatbots could handle everyday sound-related questions, instructions, and explanations more naturally.
- Stronger multimodal reasoning: Even when audio isn’t available, AI could still “fill in the gaps” by imagining what the sound would be and using that to make decisions.
- Future research: To improve duration and loudness tasks, we need sound representations that capture time and volume more precisely, not just meaning. That could lead to even more human-like understanding.
In short, this work shows that with the right tests and training, LLMs can learn to “imagine” sounds and use that imagination to reason better—just like people do when they read.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of missing pieces and unresolved issues that future work could address.
- Benchmark coverage is narrow: no tasks for timbre, rhythm/tempo, speech prosody, spatialization/localization, reverberation, sound mixtures/polyphony, environmental acoustics, or sound illusions—add targeted, text-only tasks for these phenomena.
- Auditory Context Reasoning set is very small (75 items) and may be underpowered—scale it up, diversify domains, and report item-level difficulty and reliability.
- Loudness labels use peak dB, which poorly reflects perceived loudness—replace with psychoacoustic measures (e.g., LUFS, A-weighting, Zwicker loudness) and validate with human judgments.
- Duration comparison relies on segment annotations without modeling temporal structure—evaluate embeddings that explicitly encode time (e.g., T-CLAP, temporal pooling) and add tasks that require fine-grained temporal reasoning.
- The “imagination” embedding generation is underspecified: how are audio embeddings produced without audio input (CLAP text encoder vs. audio encoder, retrieval vs. generation)?—document the pipeline and ablate alternative encoders/sources.
- Dataset construction for context reasoning depends on model-generated captions (Qwen2-Audio) and GPT-4o rewrites—quantify and mitigate biases/leakage; include human-authored variants and cross-model rewrites to test robustness.
- Cross-task generalization of AIR-CoT is unclear: Stage 1 trains only on pitch; Stage 2 training data scope is ambiguous—run controlled experiments showing transfer when training on one task and testing on others.
- No ablations on AIR-CoT design choices—evaluate the necessity of special tokens, pause/injection mechanics, location/layer of embedding injection, and training which components (LM vs. projector vs. both).
- Span detection quality is not analyzed—measure precision/recall of [imagine] emission, over/under-triggering rates, and impact on downstream accuracy.
- Computational overhead and latency of AIR-CoT (pause, embedding generation, injection) are not reported—benchmark throughput, memory, and inference-time cost versus baselines.
- Interpretability of imagined audio content is not assessed—develop methods to render or paraphrase imagined embeddings, and run human studies to verify alignment with intended auditory properties.
- Limited gains on duration/loudness suggest representation mismatches—test specialized modules (e.g., pitch trackers like CREPE, amplitude envelopes, temporal encoders) and hybrid symbolic/learned representations.
- Multilingual and cultural variability (e.g., onomatopoeia across languages, culturally specific sound associations) are unaddressed—create multilingual versions and evaluate cross-lingual transfer.
- Fairness of baseline comparisons is not established—standardize prompting (e.g., CoT vs. no-CoT), parameter counts, and decoding settings; include stronger baselines (larger LLMs/LALMs) and report statistical significance.
- Potential evaluation contamination from using GPT-4o/Qwen-family models to rewrite/describe test items—audit overlap with training corpora of evaluated models and release contamination analyses.
- Data splits, annotation protocols, and inter-annotator agreement are not detailed—publish train/val/test splits, guidelines, quality control, and agreement metrics to improve reproducibility.
- Human performance baselines are missing—measure human accuracy and variability to contextualize model scores and establish upper bounds.
- Effects on non-auditory tasks and overall LM behavior are unknown—test whether AIR-CoT harms or helps general reasoning, language tasks, and calibration.
- Robustness to adversarial or misleading prompts (e.g., forced [imagine] tokens, contradictory cues) is not evaluated—build stress tests and safety checks for token misuse.
- Realistic narrative settings are limited—add long-form, open-ended text scenarios and generative tasks (e.g., explain plausible sound evolution in a scene) beyond multiple-choice/binary formats.
- Integration with actual audio at inference is not studied—evaluate hybrid settings where sparse audio is available, and test whether AIR-CoT complements LALMs with audio inputs.
- Confidence calibration and uncertainty reporting are absent—include calibrated probabilities, reliability diagrams, and significance tests to assess trustworthiness of auditory reasoning.
Practical Applications
Below is a structured overview of practical, real-world applications enabled by the paper’s benchmark (AuditoryBench++) and method (AIR-CoT), mapped to sectors, potential tools/workflows, and feasibility conditions.
Immediate Applications
These can be deployed with existing tooling (LLMs, CLAP), modest engineering, and limited domain adaptation.
- Model evaluation and selection for auditory reasoning
- Sectors: AI/ML industry, academia
- Tools/Workflows: AuditoryBench++ test suite integrated into CI/CD; dashboards/leaderboards for regression testing and model comparison
- Assumptions/Dependencies: Access to benchmark data; reproducible evaluation; acceptance of accuracy as the primary metric; appropriate licensing for internal use
- Auditory-aware chatbots that handle text-only sound-related queries
- Sectors: software, customer support, education, consumer electronics
- Tools/Workflows: AIR-CoT-style inference wrapper (span detection via special tokens, imagination pause, CLAP embedding injection) for chat assistants; prompt templates for auditory tasks (pitch/loudness/duration comparisons, animal-sound mapping, context reasoning)
- Assumptions/Dependencies: Ability to fine-tune or extend the base LLM; availability of CLAP or equivalent audio-text encoders; risk controls for hallucinations
- Content creation co-pilot for sound cue suggestion
- Sectors: media/entertainment, game development, advertising
- Tools/Workflows: “Sound cue suggester” plug-in that adds likely auditory descriptors to scripts/storyboards; retrieval of matching audio assets (via embedding similarity)
- Assumptions/Dependencies: Access to sound libraries; correct mapping between imagined audio descriptors and searchable audio embeddings
- Sound asset search and tagging from text
- Sectors: media asset management, stock audio platforms, post-production
- Tools/Workflows: Text-to-audio embedding retrieval (CLAP) that links textual descriptions to candidate audio clips; tagging automation using imagined auditory properties
- Assumptions/Dependencies: Quality and coverage of audio libraries; effective embedding alignment; domain-specific taxonomy for sound classes
- Accessibility: augmenting text with auditory annotations
- Sectors: accessibility, publishing, education
- Tools/Workflows: Automatic insertion of concise auditory descriptors into articles, transcripts, and e-learning modules (e.g., “[soft humming of machinery]”)
- Assumptions/Dependencies: Cultural variance in auditory commonsense; careful UX to avoid noise or misinformation; human-in-the-loop review for high-stakes content
- Curriculum and assessment for auditory commonsense
- Sectors: education (K–12, higher ed), edtech
- Tools/Workflows: Quiz generators and tutoring flows that use AuditoryBench++ tasks; formative assessment of sound-related reasoning (pitch/loudness/duration, contextual cues)
- Assumptions/Dependencies: Licensing for educational content; clear learning objectives; calibration of difficulty per grade level
- Benchmark-informed procurement and risk assessment
- Sectors: policy/compliance, operations, public-sector IT procurement
- Tools/Workflows: Require baseline performance on AuditoryBench++ for vendors whose systems must reason about sound in text-only contexts (e.g., contact centers, public information systems)
- Assumptions/Dependencies: Governance policies recognizing the benchmark; domain-specific thresholds; transparent reporting of evaluation results
- Data curation pipelines for comparison tasks
- Sectors: academia, ML engineering
- Tools/Workflows: Adopt the paper’s statistical process (IQR filtering, significant pairwise contrasts) to build robust comparison datasets in other domains (e.g., image brightness, tactile intensity)
- Assumptions/Dependencies: Availability of annotated data; sufficient sample sizes; domain-relevant statistical criteria
Long-Term Applications
These require further research (especially on duration/loudness representations), broader validation, or integration at scale.
- Multimodal assistants with generalized imagination across modalities
- Sectors: software, robotics, AR/VR
- Tools/Workflows: Unified “imagination tokens” for audio, vision, and other modalities that pause inference to synthesize intermediate representations before continuing CoT reasoning
- Assumptions/Dependencies: Better audio embeddings capturing temporal and amplitude properties; standardized interfaces for cross-modal knowledge injection
- Telemedicine triage from patient-described sounds
- Sectors: healthcare
- Tools/Workflows: Triage assistants that parse textual descriptions (e.g., “wheezing,” “murmur-like”) and recommend next steps; decision support linked to clinical pathways
- Assumptions/Dependencies: Clinical validation and regulatory approval; domain-specific data; robust risk management and audit trails; high accuracy on context reasoning
- Industrial maintenance and predictive diagnostics from textual incident logs
- Sectors: manufacturing, energy, transportation
- Tools/Workflows: Ticket triage systems that map descriptions like “grinding,” “rattling,” “high-pitched whine” to probable failure modes; escalation workflows
- Assumptions/Dependencies: Domain adaptation with labeled examples; integration with CMMS/EAM systems; continuous monitoring of false positives/negatives
- Autonomous systems that plan with imagined auditory cues
- Sectors: robotics, smart home, automotive
- Tools/Workflows: Agents that predict and reason about likely sounds (alarms, traffic, machine operation) when planning tasks, even in text-only simulations
- Assumptions/Dependencies: Real-time inference integration; robust generalization; combination with audio sensing for closed-loop validation
- Audio synthesis and sound design co-pilots
- Sectors: music tech, film, gaming
- Tools/Workflows: Use imagined audio embeddings to guide generative audio models (foley/sound effects “autofill”); iterative refinement via text prompts
- Assumptions/Dependencies: High-fidelity generative audio systems; licensing/rights for downstream use; accurate mapping from textual cues to acoustic attributes
- Emergency communications enriched with auditory context
- Sectors: public safety, policy, city services
- Tools/Workflows: Text alerts that include standardized auditory descriptors (e.g., siren types, alarm cadence) to improve situational awareness for all citizens
- Assumptions/Dependencies: Human review and domain guidelines; localization; validation to prevent confusion or panic
- Multilingual, culturally aware auditory commonsense
- Sectors: academia, global software, policy
- Tools/Workflows: AuditoryBench++ variants per language/culture (e.g., onomatopoeia differences), and culturally informed reasoning calibrations
- Assumptions/Dependencies: Cross-lingual data; diverse annotators; fairness audits and bias mitigation
- Standardization and certification for auditory reasoning in LLMs
- Sectors: policy/regulatory, standards bodies
- Tools/Workflows: Formal benchmarks, thresholds, and auditing protocols for text-only auditory reasoning as part of AI certification programs
- Assumptions/Dependencies: Multi-stakeholder governance; test coverage across sectors; periodic updates
- STEM curricula focused on auditory reasoning and perception
- Sectors: education, workforce development
- Tools/Workflows: Modules that teach physics/acoustics concepts, leveraging AI tutors that can reason about sound without audio input
- Assumptions/Dependencies: Teacher training; alignment to standards; assessment validity studies
- Research agenda for audio representations that encode quantitative properties
- Sectors: academia, foundation model R&D
- Tools/Workflows: Development of embeddings capturing time-axis and amplitude (duration/loudness), e.g., temporal-enhanced CLAP variants, and integration into AIR-CoT
- Assumptions/Dependencies: Open datasets with ground-truth quantitative labels; compute resources; community benchmarks to validate progress
In summary, AuditoryBench++ offers an immediate evaluation lever for text-only auditory reasoning, while AIR-CoT enables a practical inference workflow that “imagines” acoustic knowledge on demand. Short-term deployments are feasible in evaluation, content creation, accessibility, and chat assistants. Longer-term impact hinges on improved audio representations (duration/loudness), domain-specific validation (healthcare/industry), and evolution toward standards, certification, and cross-modal imagination frameworks.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve generalization in training deep models. "learning rate of , and the AdamW~\cite{loshchilov2018decoupled} optimizer."
- AIR-CoT: Auditory Imagination Reasoning Chain-of-Thought; a method that triggers auditory imagination during inference and integrates imagined audio knowledge into reasoning. "we introduce AIR-CoT, a novel auditory imagination reasoning method that generates and integrates auditory information during inference through span detection with special tokens and knowledge injection."
- AudioBERT: A LLM augmented with audio knowledge to improve auditory understanding in text tasks. "we compare our approach with auditory knowledge injection methods such as AudioBERT~\cite{ok2025audiobert} and Imagine to Hear~\cite{yoo2025imagine}."
- Auditory commonsense: Shared human knowledge about typical sounds and their properties or sources. "auditory commonsense (e.g., animal-sound associations)"
- Auditory context reasoning: Reasoning about situations using textual descriptions of sounds, sources, and acoustic cues. "Auditory Context Reasoning: This component evaluates a model's ability to perform contextual auditory reasoning, focusing on interpreting nuanced auditory cues and situational contexts in a multiple-choice format."
- Auditory imagination: The internal generation of sound-related representations to support reasoning without actual audio input. "enabling LLMs to seemingly hear through explicit auditory imagination."
- AuditoryBench: An earlier benchmark focusing on auditory knowledge in LLMs, used as a resource in this work. "For pitch comparison, we use only the wiki set of AuditoryBench~\cite{ok2025audiobert}"
- AuditoryBench++: A comprehensive text-only benchmark evaluating auditory knowledge and reasoning across multiple tasks. "we present AuditoryBench++, a comprehensive benchmark for evaluating auditory knowledge and reasoning in text-only settings."
- AudioTime: A dataset with temporally aligned audio-text annotations used to construct duration and loudness comparisons. "we build new datasets from AudioTime~\cite{xie2025audiotime}, leveraging its segment-level annotations."
- Chain-of-Thought (CoT): A reasoning paradigm where models generate intermediate steps to solve complex problems. "we introduce the auditory imagination reasoning Chain-of-Thought (AIR-CoT), a novel method to equip LLMs with auditory capabilities and thereby enable reasoning grounded in auditory commonsense."
- CLAP: Contrastive Language-Audio Pretraining; a model that learns joint audio-text embeddings, used here to produce audio embeddings for imagination. "We leverage audio models (e.g., CLAP~\cite{elizalde2023clap}) to produce audio embeddings and inject them into the {\footnotesize\tt[/imagine]} token."
- Decibel: A logarithmic unit measuring sound intensity, used here to quantify loudness. "In the loudness task, peak decibel levels are calculated to provide a consistent measure of intensity across samples, ensuring clear distinctions between label pairs and minimizing ambiguity."
- Interquartile Range (IQR): A robust statistical range used for outlier removal. "Outliers are removed using the interquartile range (IQR) rule"
- Knowledge injection: Incorporating external or generated knowledge (e.g., audio embeddings) into a model’s hidden states during reasoning. "span detection with special tokens and knowledge injection."
- Large Audio-LLMs (LALMs): Models that jointly process audio and text modalities. "recent advances in large audio-LLMs (LALMs) have shown promising results when processing audio inputs"
- LLMs: High-capacity LLMs trained on large corpora. "Do LLMs share a similar commonsense?"
- Multimodal LLMs: LLMs that can process and integrate multiple modalities such as text, audio, and images. "Extensive experiments with recent LLMs and Multimodal LLMs demonstrate that AIR-CoT generally outperforms both the off-the-shelf models and those augmented with auditory knowledge."
- Onomatopoeic expression: A word that phonetically imitates a sound, used here to map to sound sources like animals. "This task requires predicting the correct animal corresponding to a given onomatopoeic expression (e.g., 'meow')."
- p-value (p < 0.01): A statistical significance threshold indicating strong evidence against the null hypothesis. "select label pairs with statistically significant contrasts ()."
- Projector (MLP projector): A small neural network used to map embeddings (e.g., from CLAP) into the LLM’s hidden space. "integrate a CLAP encoder with a 2-layer MLP projector to align audio embeddings."
- Qwen2-Audio: An audio-LLM used to generate audio captions for text-only problem construction. "Each audio clip is first described using Qwen2-Audio~\cite{chu2024qwen2}, generating detailed captions"
- Qwen2.5: A family of LLMs used both as a base model and for generating training rationales. "we employ the Qwen2.5-32B~\cite{qwen2025qwen25technicalreport} model for this generation process"
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled examples to specialize its behavior. "we apply SFT to train the model to detect spans requiring auditory knowledge during decoding via special tokens."
- Span detection: Identifying text spans that require specific types of knowledge (e.g., auditory) during generation. "Stage 1: Span detection via special token."
- Special token: A reserved token used to signal a specific behavior or mode in the model, such as triggering imagination. "we introduce a special token, {\footnotesize\tt[imagine]}\xspace, emitted by the model whenever auditory reasoning is required."
Collections
Sign up for free to add this paper to one or more collections.

