- The paper presents a robust behavioral cloning pipeline that integrates strategic data augmentation, weight perturbation, and a hybrid action space to enhance social robot navigation.
- The methodology employs flip augmentation and action chunking to double data diversity and achieve a 3× success rate improvement with a 6× reduction in collisions.
- Empirical evaluations in simulation and real-world deployments demonstrate that principled imitation learning can safely balance path tracking and human avoidance in dense environments.
Ratatouille: Imitation Learning Ingredients for Real-world Social Robot Navigation
Introduction and Motivation
The paper presents Ratatouille, a comprehensive behavioral cloning (BC) pipeline for social robot navigation in dense, real-world environments. The motivation stems from the limitations of both deep reinforcement learning (DRL) and naïve BC in real-world social navigation. DRL, while effective in simulation, is unsafe and data-inefficient for real-world deployment due to the need for online exploration and the challenge of reward specification for complex social norms. Naïve BC, on the other hand, often fails to generalize in the presence of multimodal, imbalanced, and high-variance data typical of social navigation scenarios.
Ratatouille addresses these challenges by integrating a set of architectural and training "ingredients"—weight perturbation, data augmentation, hybrid action space, action chunking, and neural network optimization strategies—into a unified pipeline. The approach is validated through extensive ablation studies in both simulation and real-world deployments, demonstrating substantial improvements in safety and reliability over baseline BC.
System Architecture and State-Action Representation
The system is built on a Clearpath Jackal robot equipped with an Ouster OS0-128 LiDAR, leveraging a teach-and-repeat (T&R) pipeline for localization and path tracking. Human detection is performed directly on LiDAR reflectivity images using a pre-trained YOLOX model, and tracking is handled by Norfair. The state representation is a structured vector encoding both the local path segment and the spatiotemporal history of nearby humans, capped at 10 steps (2.5s) per agent, sampled at 0.25s intervals.
The model architecture, adapted from prior work, employs a combination of GRUs, multi-head self-attention, and cross-attention modules to process variable-length human histories and path segments.
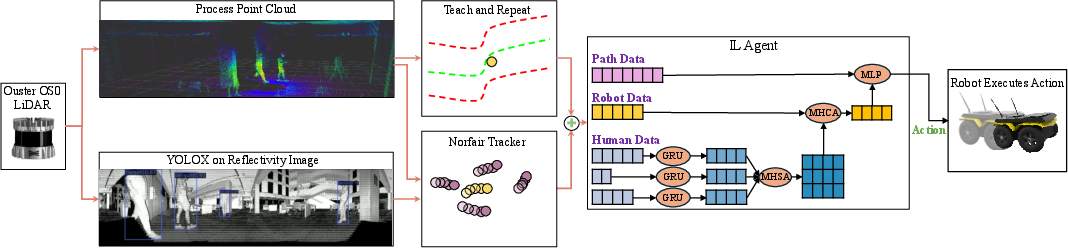
Figure 2: The real-world system architecture, integrating LiDAR-based localization, human detection, and tracking, with a neural policy for social navigation.
Key Ingredients of Ratatouille
Data Augmentation via Flip Augmentation
A critical insight is that standard data augmentation is nontrivial in IL, as state transformations often require recomputation of expert actions. Ratatouille employs a flip augmentation that mirrors the entire scene about the robot's x-axis, negating y-coordinates and angular velocities. This doubles the dataset and introduces diversity in path and human configurations, e.g., generating clockwise (CW) paths from counter-clockwise (CCW) demonstrations.
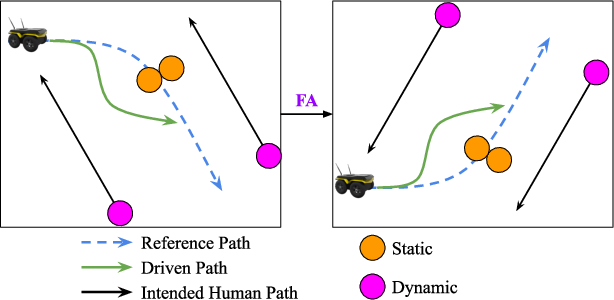
Figure 3: Flip augmentation example, mirroring the robot, humans, and path about the x-axis to increase data diversity.
Action Chunking and Hybrid Action Space
Action chunking predicts a sequence of future actions (horizon H=3), rather than a single step, which empirically improves closed-loop performance. The hybrid action space discretizes angular velocity into three bins (left, straight, right), and for each discrete sequence, predicts a continuous action chunk. The loss combines negative log-likelihood for the discrete path and a weighted MSE for the continuous actions, leveraging the model's confidence in each path.
Weight Perturbation and Regularization
Inspired by findings on loss of plasticity in deep continual learning, Ratatouille periodically perturbs model weights towards a randomly initialized network, with the perturbation magnitude decayed over time. This, combined with high weight decay and the AdamW optimizer, preserves the network's adaptability and prevents overfitting to dominant modes in the data (e.g., path tracking over human avoidance).
Latent Dimension Balancing
To prevent over-reliance on path information, the dimensionality of the path-tracking embedding is reduced relative to the human-avoidance embedding, encouraging the model to attend to human features.
Empirical Evaluation
Real-world Data Collection
The dataset comprises 11 hours of in-the-wild demonstrations on a university campus, with a mix of high-density (5–30 people) and low-density (0–4 people) scenes. The majority of actions are path-tracking, reflecting the natural imbalance in real-world navigation.

Figure 1: Data collection in dense, unconstrained campus environments, yielding diverse human-robot interactions.
Real-to-Sim and Real-to-Real Evaluation
The evaluation suite includes 27 unique scenarios in simulation, varying path geometry and human configurations (static and dynamic, regular and aggressive). In real-world tests, 24 episodes are conducted across diverse human-robot interaction scenarios.
Ratatouille achieves a 3× improvement in success rate (28% → 98%) and a 6× reduction in collisions per meter (0.06 → 0.01) over the Base BC model in simulation. In real-world tests, Ratatouille outperforms both the Base model and SCAND, with higher success rates and lower collision rates.
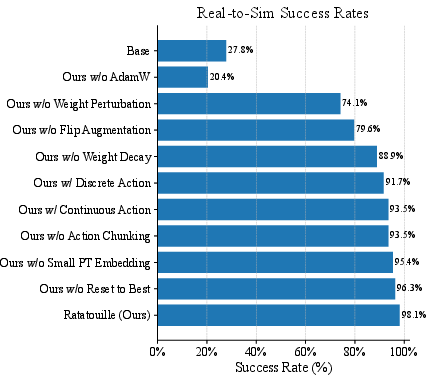
Figure 4: Real-to-sim success rates, highlighting the impact of each ingredient. AdamW, weight perturbation, and flip augmentation are most critical.
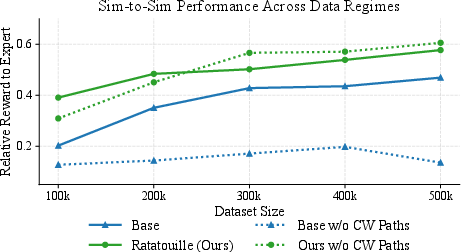
Figure 7: Ratatouille consistently outperforms the Base model across all data regimes, with flip augmentation ensuring generalization to unseen path types.
Ablation Studies
Ablations reveal that AdamW, weight perturbation, and flip augmentation are the most impactful components. The hybrid action space provides a modest gain, while action chunking exhibits an inverted-U effect, with H=3 optimal. Notably, the continuous action representation outperforms the discrete one, even in multimodal settings, contradicting some prior expectations.
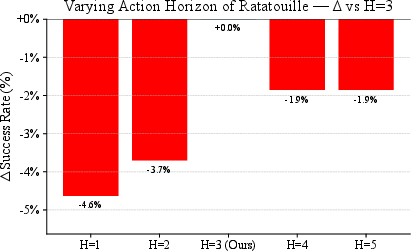
Figure 5: Action chunking ablation, showing performance degradation for H=3.
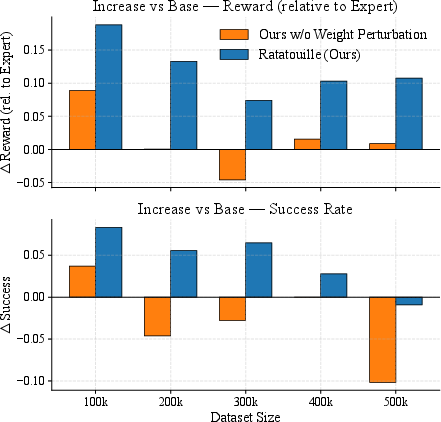
Figure 8: Weight perturbation consistently improves performance across all data regimes.
Qualitative Results
In public food court deployments, Ratatouille demonstrates smooth, socially compliant navigation, including turning around static groups and adjusting speed in cluttered environments. Collisions, when they occur, are minor (e.g., clipping during turns) rather than head-on, indicating improved safety.
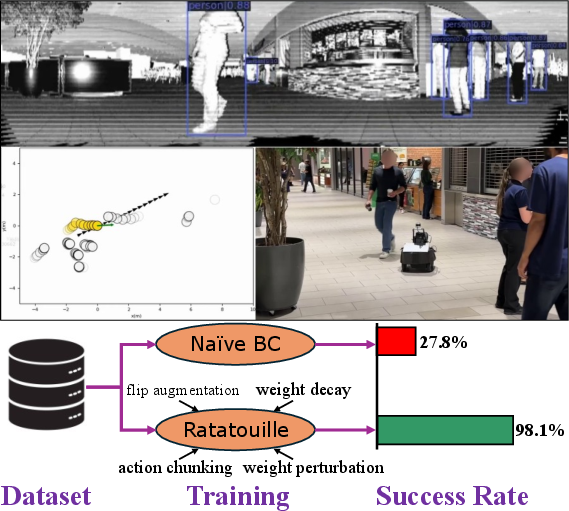
Figure 10: Real-world evaluation in a food court, with the robot navigating around stationary and moving humans.
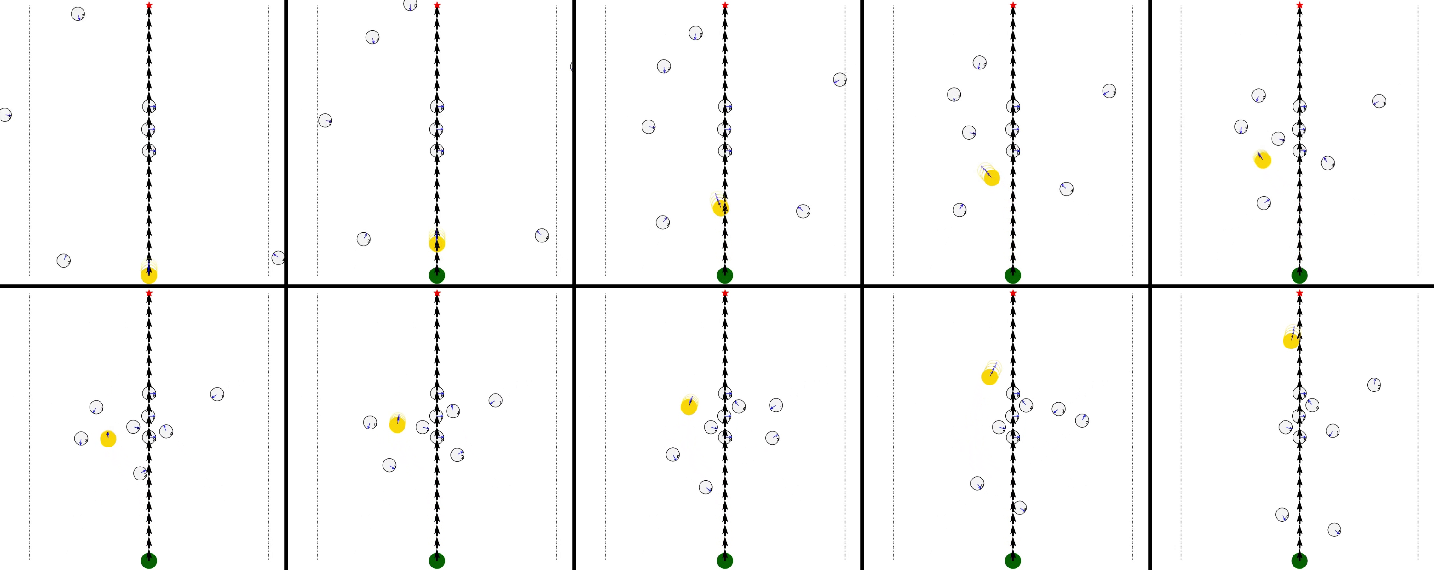
Figure 6: Real-to-sim qualitative episode, with the robot dynamically avoiding multiple humans.
Theoretical and Practical Implications
The results underscore that principled IL design, rather than increased data volume, is critical for robust social navigation. The findings on weight perturbation and regularization suggest that multi-objective IL tasks (e.g., path tracking and human avoidance) are susceptible to loss of plasticity, and that techniques from continual learning and evolutionary algorithms can be fruitfully adapted.
The hybrid action space and flip augmentation provide a template for handling multimodality and data imbalance in other IL domains. The empirical superiority of continuous over discrete action heads in this context challenges some established assumptions and warrants further investigation.
Limitations and Future Directions
The primary limitation is the perceptual gap between the expert and the robot; the expert has access to richer cues and perfect perception, while the robot relies on position-only observations. Future work could explore restricting the expert's view to match the robot's sensors or leveraging generative models for more sophisticated data augmentation. The strong effect of weight perturbation invites further study in other IL settings and multi-objective learning problems.
Conclusion
Ratatouille demonstrates that a carefully engineered BC pipeline, integrating targeted data augmentation, action representation, and regularization strategies, can achieve high-performance, safe, and reliable social navigation in real-world environments. The approach provides a robust foundation for future research in scalable, data-efficient, and socially compliant robot navigation.