The (Short-Term) Effects of Large Language Models on Unemployment and Earnings
Abstract: LLMs have spread rapidly since the release of ChatGPT in late 2022, accompanied by claims of major productivity gains but also concerns about job displacement. This paper examines the short-run labor market effects of LLM adoption by comparing earnings and unemployment across occupations with differing levels of exposure to these technologies. Using a Synthetic Difference in Differences approach, we estimate the impact of LLM exposure on earnings and unemployment. Our findings show that workers in highly exposed occupations experienced earnings increases following ChatGPT's introduction, while unemployment rates remained unchanged. These results suggest that initial labor market adjustments to LLMs operate primarily through earnings rather than worker reallocation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the Paper's Topic and Purpose
The paper is about how really smart computer programs, called LLMs, might be affecting people's jobs and salaries. These programs, like ChatGPT, can do things like write essays or answer tricky questions, and they're being used by lots of people. Some people think these programs can help us do our jobs better, but others are worried they could take away jobs.
Key Objectives or Research Questions
The main questions the researchers want to answer are:
- How do LLMs affect people's earnings? They check if people's salaries go up or down in jobs where these programs are used a lot.
- Do LLMs increase unemployment? They look to see if more people are losing jobs in places where these programs are common.
Research Methods or Approach
The researchers used a method called "Synthetic Difference-in-Differences" (SDiD), which is like comparing two groups to see if one has changed a lot more than the other after something new happens. They focused on different jobs and looked at changes in money people earn and unemployment rates before and after ChatGPT was widely used. Think of this like checking two different basketball teams' scores before and after a new training method is introduced to see if it made a big difference.
Main Findings or Results
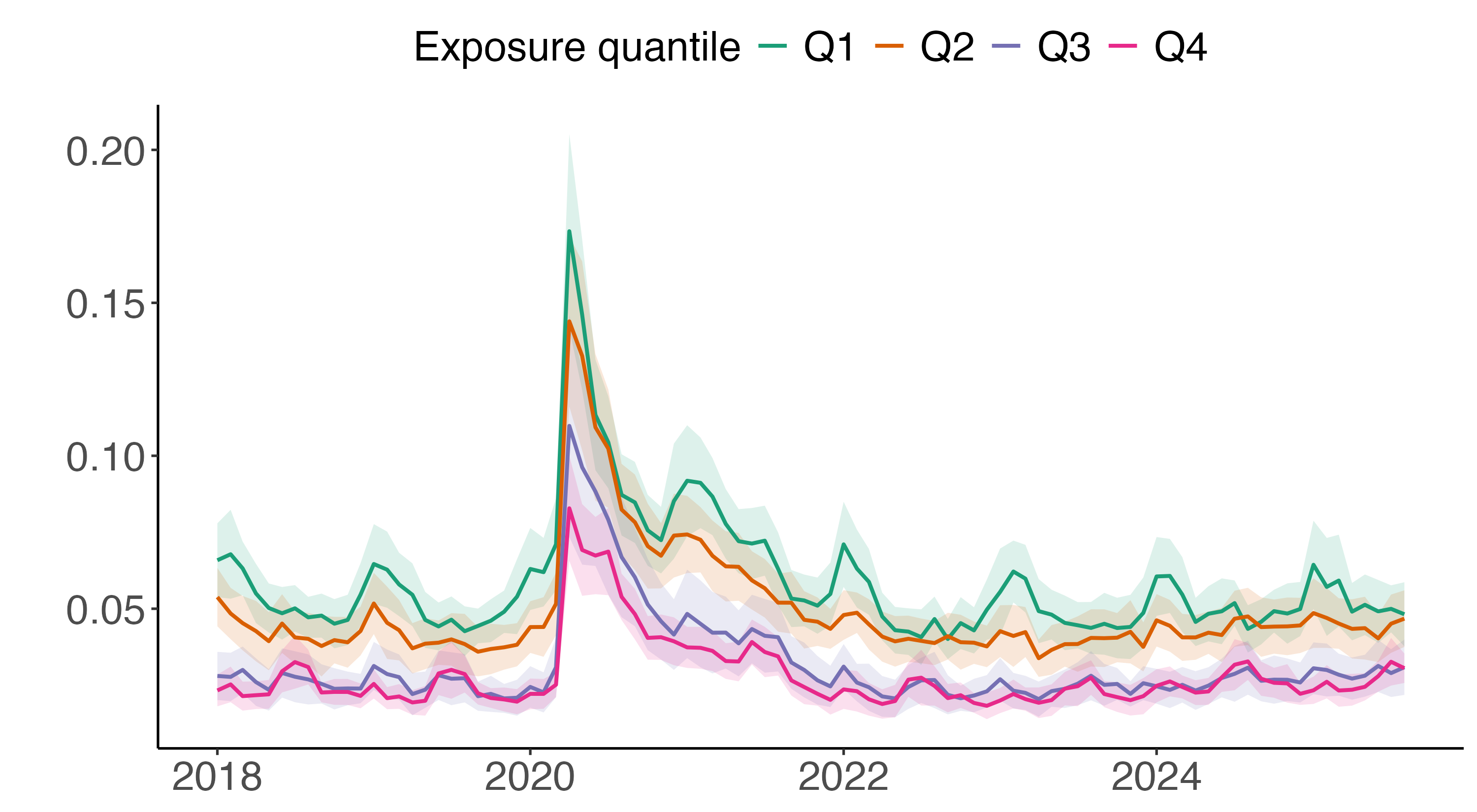
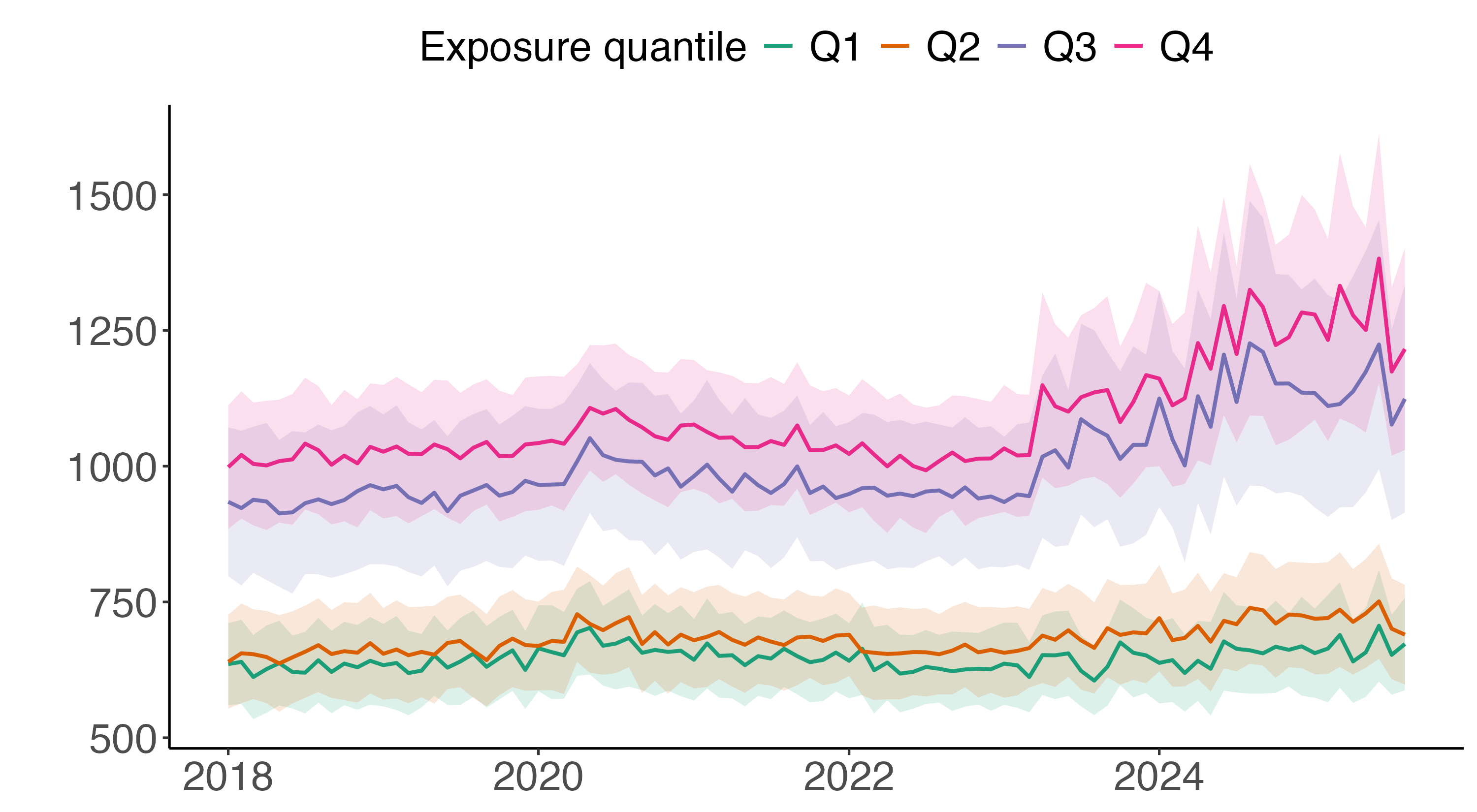
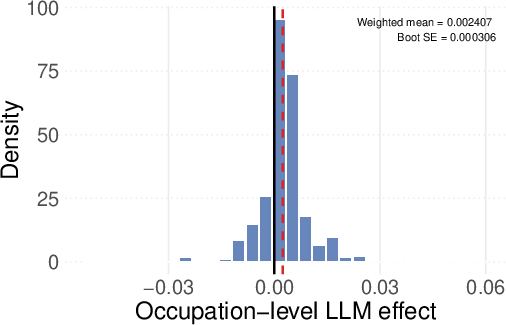
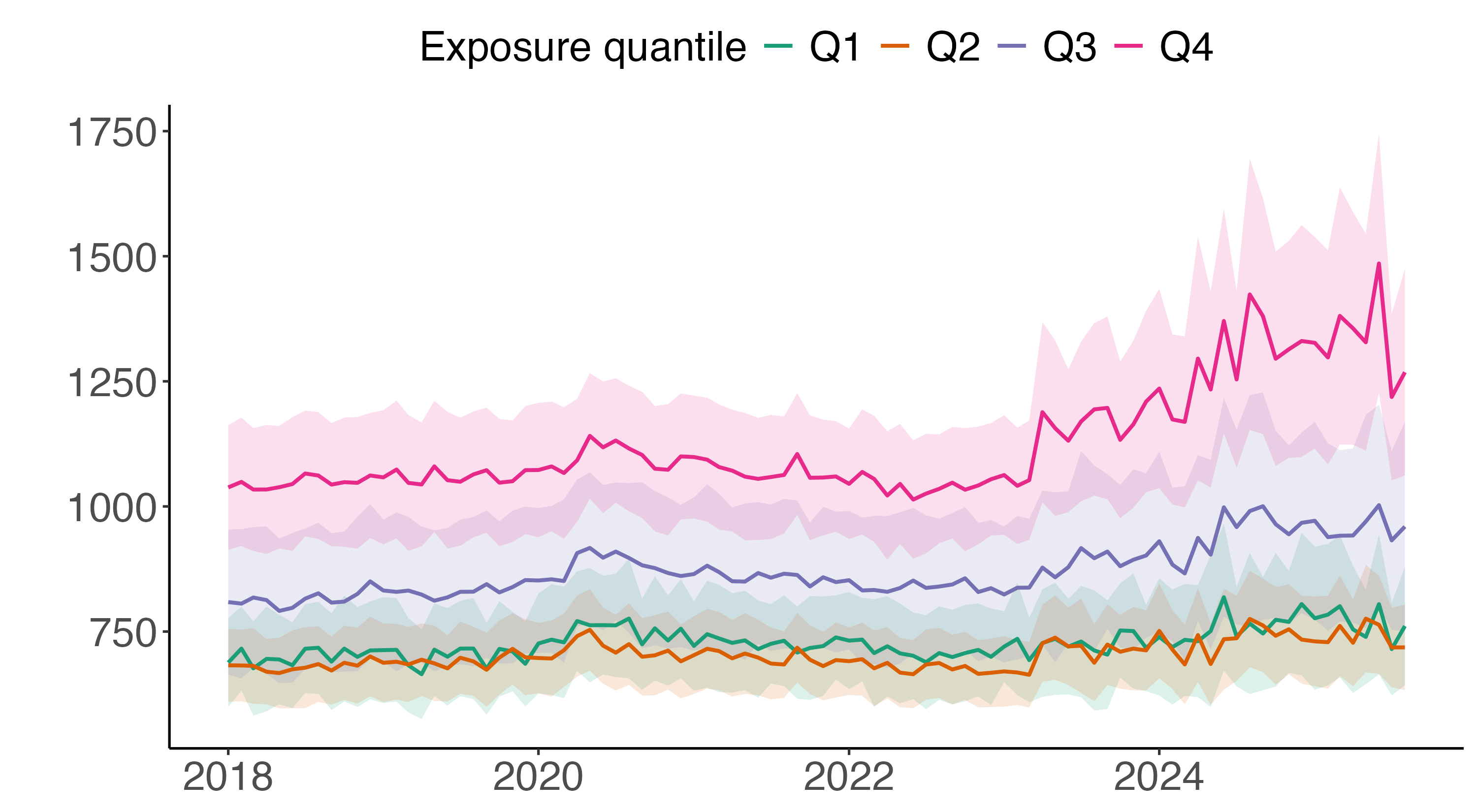
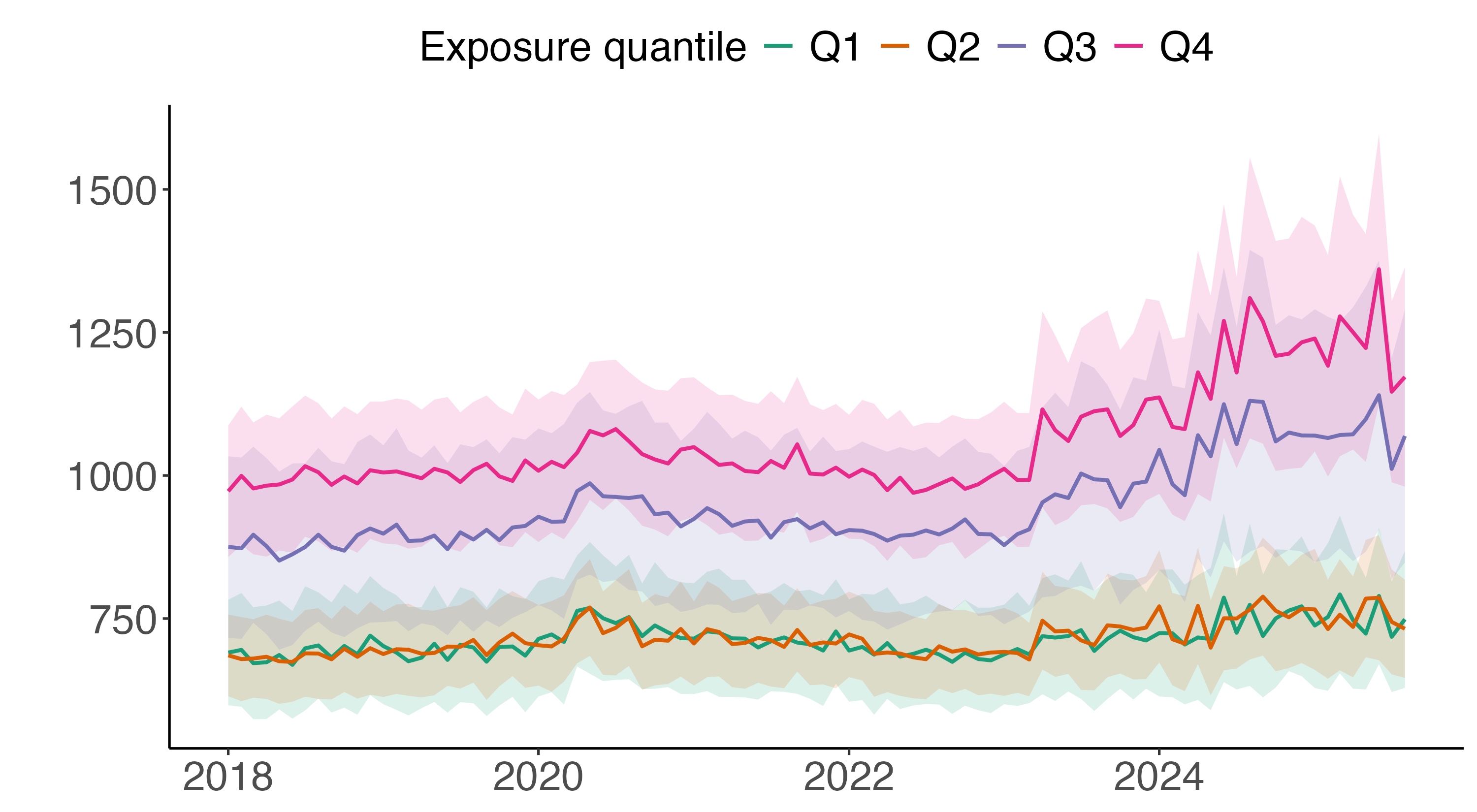
- Earnings: People in jobs where LLMs are used more had their weekly earnings go up by about $89 on average.
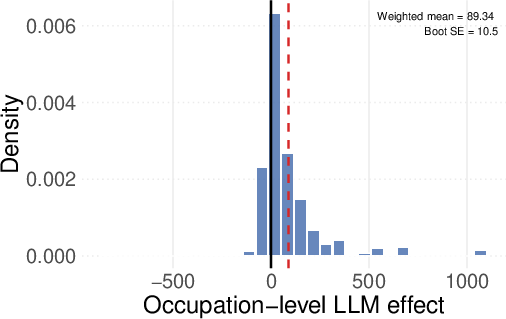
- Unemployment: There wasn’t a big change in the number of people losing jobs in these occupations right after these models were introduced.
These results suggest that while these smart programs help people earn more money, they don't necessarily lead to a lot of job losses immediately.
Implications or Potential Impact
The research shows that these smart programs might help improve how much people earn without causing many job losses in the short term. But it also means that people working in jobs using these models can be more productive, and that productivity improvement is very important in today's work environment. The researchers think more changes might happen in the future as these programs and their uses continue to evolve, so it's important to keep studying their effects.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future research could address:
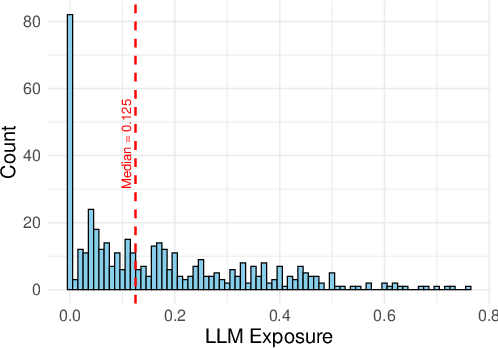
- Measurement of exposure vs adoption: The exposure metric reflects potential applicability (prompt-task links) rather than realized, time-varying adoption by workers or firms; direct adoption measures (e.g., enterprise AI usage logs, job-posting text, firm surveys) are needed to validate and scale effects.
- Model- and platform-specific exposure: Exposure is derived from Anthropic Claude prompts; results may not generalize to other LLMs (e.g., GPT-4/4o, Gemini, open-source models) or enterprise tools. Replicate using multi-model, multi-platform prompt data.
- Static exposure in a rapidly evolving technology: Occupation exposure is treated as fixed around the ChatGPT release; incorporate dynamic exposure scores that evolve with model capabilities (e.g., multimodal, agentic, tool-use) and track timing of capability thresholds.
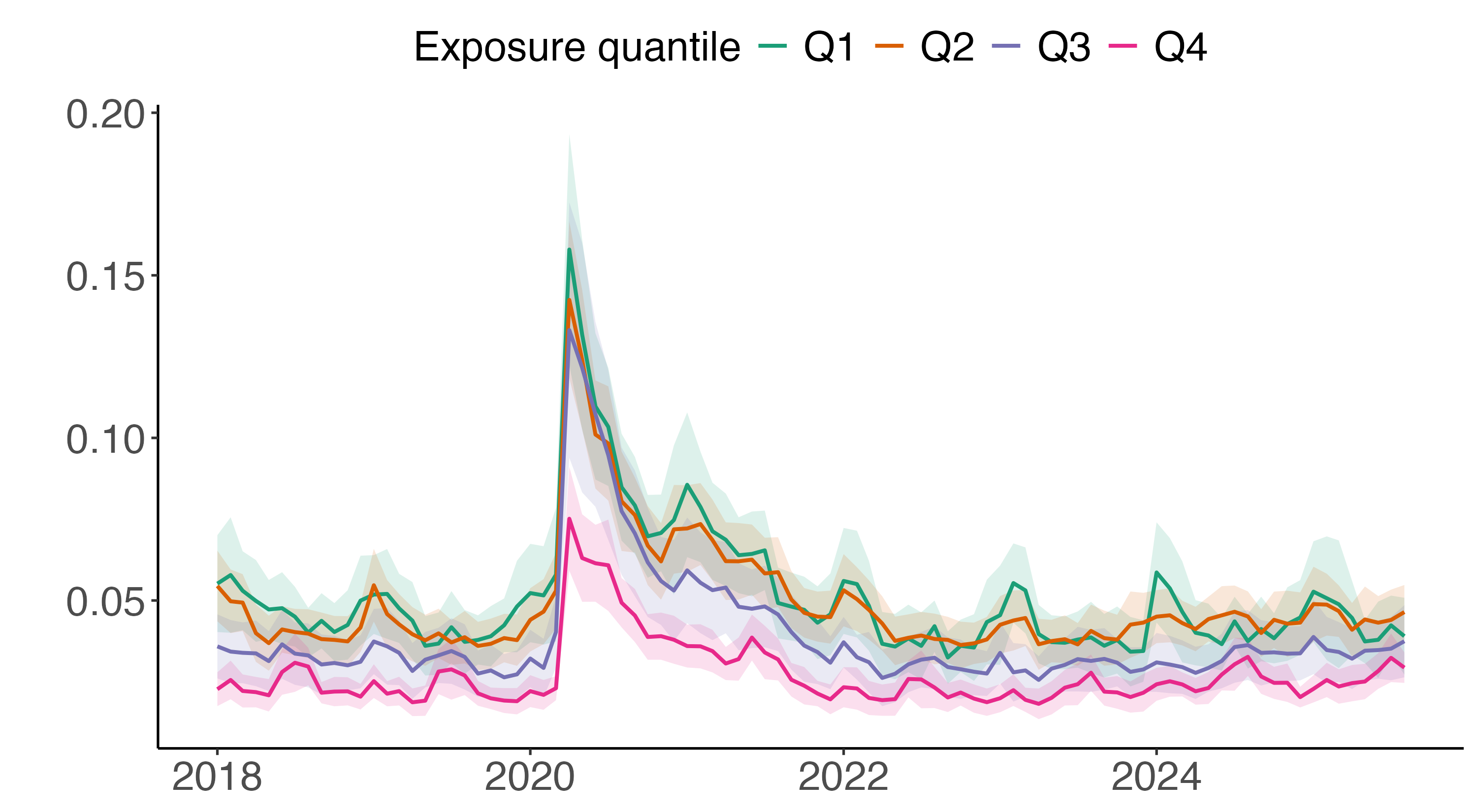
- Binarization of exposure: Main analyses hinge on “above-median” exposure; estimate dose–response relationships and nonlinearities using continuous exposure, and test sensitivity to alternative cutoffs.
- Task taxonomy rigidity: O*NET tasks are relatively slow-moving and may not reflect rapid within-occupation task recomposition due to LLMs; integrate dynamic task content from job postings and worker resumes to update exposure in near-real time.
- Mapping uncertainty: Crosswalks between O*NET-SOC and Census 2010 occupation codes introduce classification error; quantify mapping uncertainty and propagate it to effect estimates (e.g., via multiple imputation).
- Common treatment timing assumption: The design imposes a universal treatment start (Nov 2022) despite staggered, gradual adoption; model staggered adoption explicitly or instrument for adoption timing at the occupation/industry/firm level.
- Concurrent technology shocks: Other major releases (e.g., GPT-4 in Mar 2023), enterprise AI rollouts, and policy shifts coincide with the period; separate effects across waves of capability releases and corporate adoption policies.
- Macroeconomic confounding: Post-2022 macro dynamics (inflation, post-COVID sectoral rebalancing, remote/hybrid work) may differentially affect occupations; include occupation-specific trends or controls for sectoral demand shocks.
- Limited outcomes: Only weekly earnings and unemployment are analyzed; examine hourly wages, hours worked, earnings dispersion, job-to-job transitions, occupation/industry switching, labor force participation, vacancies, and job postings.
- Mechanisms untested: The paper interprets wage gains as productivity-driven complementarity and suggests inelastic labor supply, but does not test mechanisms; link to productivity metrics, adoption intensity, training, and firm-level complementarities.
- Composition effects within occupations: Averaging unweighted CPS earnings within occupations may conflate wage changes with changing worker composition (age, education, tenure); construct composition-adjusted wage indices or control for worker covariates.
- Top-code handling and comparability: CPS earnings top-code changed in Apr 2024; beyond inflating to 2010 dollars, implement and report consistent top-code correction (e.g., Pareto imputation) and test sensitivity of results.
- Weighting choices: The decision to not use CPS sampling weights within occupations may bias occupation-level aggregates; compare results using population-weighted within-occupation means and alternative weighting schemes.
- Small-cell noise and sample selection: Monthly occupation cells can be thin; SDiD’s balanced-panel requirement may exclude smaller occupations non-randomly. Report included/excluded occupations and assess selection bias.
- Identification assumptions in SDiD: SDiD relies on an interactive fixed-effects structure; provide placebo tests, pre-period fit diagnostics (e.g., RMSPE), donor-pool sensitivity, and leave-one-out analyses to probe robustness.
- Unemployment vs employment levels: An unchanged unemployment rate can mask declines in occupation employment shares via reallocation; analyze employment levels, occupation shares, and transition matrices (entry/exit/switching).
- Heterogeneity gaps: Systematic heterogeneity by age, gender, race, education, region, union coverage, firm size, and sector is not explored; estimate subgroup-specific effects to reconcile mixed findings in the literature.
- Augmentation vs automation effects: While augmentation/automation exposure measures are referenced, the paper does not estimate or test differential causal effects across these categories with formal interaction or split-sample SDiD.
- Temporal dynamics and persistence: Are wage effects transitory or persistent? Estimate dynamic treatment effects with longer post windows, distributed lags, and tests for fade-out or amplification.
- Spillovers and general equilibrium: Potential spillovers across occupations (e.g., downstream/upstream task complementarities) and GE wage effects are not modeled; incorporate network-based exposure and input–output linkages.
- Enterprise policy heterogeneity: Firm-level AI governance (bans, restricted access, enterprise licenses) likely shapes adoption; link outcomes to firm policy variation and procurement timing.
- Regional adoption gradients: Geographic differences in tech ecosystem density, broadband, and labor markets are not examined; test region-by-exposure interactions and spatial spillovers.
- External validity: The analysis focuses on the U.S. CPS; cross-country replication (with different labor institutions) is needed to generalize findings.
- Robustness to alternative exposure measures: Validate results using other exposure frameworks (e.g., Felten-Raj-Seamans abilities, Webb patent-based exposure, dynamic expert/model ratings) to assess measurement dependence.
- Distributional impacts: Average wage gains may conceal rising inequality; examine impacts across the earnings distribution (quantile effects) and on within-occupation inequality.
- Contract type and job quality: Effects on non-wage job quality (benefits, job security, contract/permanent status) and contingent work are not studied; integrate supplemental datasets or survey modules.
- Model upgrades and multimodality: Future capability jumps (tools, agents, autonomy) may change exposure rankings; develop forward-looking scenarios and update estimates as models evolve.
- Replicability and data access: The prompt–task mapping underlying exposure may not be publicly accessible; provide reproducible exposure construction or open-sourced proxies to facilitate replication.
Practical Applications
Immediate Applications
The following items translate the paper’s short-run findings and methods into concrete actions that organizations and individuals can deploy now.
- Compensation calibration for AI-exposed roles (HR, software, media, customer support, professional services)
- Use case: Adjust salary bands, bonuses, and merit budgets upward for occupations with high LLM exposure, expecting wage pressure rather than immediate employment changes.
- Potential tools/products/workflows: “LLM Exposure Compensation Analyzer” that maps firm job families to O*NET tasks and prompt-based exposure; integrate with HRIS and compensation planning software.
- Assumptions/Dependencies: Wage gains are driven by productivity complementarity; accurate mapping between firm roles and O*NET tasks; adoption intensity is sufficient within the firm.
- Augmentation-first rollout playbooks (Operations/IT, software engineering, marketing, analytics)
- Use case: Prioritize LLM use cases that augment—not automate—core tasks (writing, coding, information synthesis), anticipating wage-linked productivity gains and minimal short-run displacement.
- Potential tools/products/workflows: Standard operating procedures for prompt libraries; team-specific “LLM Enablement Kits”; governance frameworks for responsible AI.
- Assumptions/Dependencies: Worker training and change management are funded; LLM capabilities align with the target tasks; data access and compliance are in place.
- Pricing and rate card updates for client-facing work (Professional services, agencies, consultants)
- Use case: Revise billing rates in lines of work with high LLM exposure to reflect productivity gains and tighter labor markets for these occupations.
- Potential tools/products/workflows: “Rate Card Optimizer” tied to exposure scores; internal dashboards linking productivity gains to price schedules.
- Assumptions/Dependencies: Clients accept value-based pricing; measurable quality improvements; contractual flexibility.
- Union and workforce agreements incorporating AI productivity dividends (Labor relations, policy)
- Use case: Negotiate clauses to share gains from LLM-enabled productivity (e.g., bonuses indexed to exposure-adjusted output), given findings of wage effects without employment loss.
- Potential tools/products/workflows: “AI Productivity Dividend Calculator” using SDiD-estimated wage effects by occupation; contract templates with AI clauses.
- Assumptions/Dependencies: Trust in exposure measures; agreement on output metrics; minimal conflict with existing pay structures.
- Wage-inflation monitoring dashboards for policymakers (Policy, labor statistics)
- Use case: Track earnings growth in high-exposure occupations to preempt inflationary pressures and identify inequality trends rather than focusing solely on unemployment.
- Potential tools/products/workflows: CPS-ORG–based “AI Exposure Wage Monitor”; integration with central statistical agency dashboards.
- Assumptions/Dependencies: Timely and stable survey data; consistent handling of top-code changes; sectoral breakdowns are available.
- Investment and credit analysis factor for AI exposure (Finance)
- Use case: Tilt portfolios or credit models toward firms with workforces concentrated in augmentation-prone, high-exposure roles likely to realize productivity gains.
- Potential tools/products/workflows: “AI Exposure Factor” linking occupational mix to firm-level financials; screens for complementarity-heavy sectors.
- Assumptions/Dependencies: Availability of workforce composition data; generalizability of wages-productivity linkage; macro conditions don’t dominate firm outcomes.
- Academic and evaluation practice: SDiD adoption for tech shocks (Academia, applied economics, policy evaluation)
- Use case: Apply unit-by-unit Synthetic Difference-in-Differences to other technology or policy shocks where parallel trends are suspect, improving causal inference.
- Potential tools/products/workflows: Open-source SDiD code modules; replication packages for CPS-ORG data workflows.
- Assumptions/Dependencies: Balanced panels or careful donor pool selection; sufficient pre-period length; latent factor structure approximated by SDiD.
- Organizational “Task Exposure Audit” (Enterprise analytics, compliance)
- Use case: Audit internal job descriptions and task inventories to quantify LLM exposure at the task level and identify priority areas for augmentation.
- Potential tools/products/workflows: Automated crosswalk from internal roles to O*NET-SOC and task lists; prompt libraries mapped to tasks; exposure scoring service.
- Assumptions/Dependencies: High-quality job descriptions; domain-specific prompts; data privacy and compliance controls.
- Worker-facing pay and training decisions (Daily life, education)
- Use case: Workers in writing, coding, and content-intensive roles use evidence to renegotiate pay or pivot into high-exposure specialties; select microcredentials focused on LLM-amenable tasks.
- Potential tools/products/workflows: “Personal AI Exposure Scorecard” app; curated learning paths for augmentative tasks.
- Assumptions/Dependencies: Local labor markets mirror national short-run dynamics; employers recognize and reward exposure-linked productivity.
Long-Term Applications
These items require further research, scaling, or product development to fully realize impact.
- Dynamic exposure tracking platforms with multimodal capabilities (Enterprise software, analytics)
- Use case: Continuously update occupation and task exposure as LLMs gain vision, audio, and tool-use reasoning, informing strategic workforce planning.
- Potential tools/products/workflows: “Dynamic AI Exposure Index” SaaS; connectors to HRIS, ATS, and project tooling; alerts for rising automation risk.
- Assumptions/Dependencies: Consensus on exposure metrics; access to updated LLM capability assessments; integration with firm data.
- Compensation forecasting modules tied to AI adoption (HR tech, finance)
- Use case: Forecast compensation budgets for high-exposure job families, integrating expected wage pressures and productivity dividends.
- Potential tools/products/workflows: “AI-Induced Wage Forecast” embedded in compensation planning suites; scenario analysis for adoption intensities.
- Assumptions/Dependencies: Robust medium-run causal models; macro controls; validated links between adoption and wages.
- Standardized reporting of AI exposure and labor outcomes (Policy, governance)
- Use case: Develop regulatory guidance requiring firms to disclose AI exposure of roles and observed wage impacts, enabling evidence-based policy.
- Potential tools/products/workflows: Exposure reporting templates; audit protocols; public dashboards.
- Assumptions/Dependencies: Agreement on measurement standards; legal frameworks for disclosure; enforcement capacity.
- Inequality and social policy design for AI-driven wage dynamics (Policy, social insurance)
- Use case: Create targeted tax credits, training subsidies, or wage insurance addressing differential wage gains and potential future displacement risks.
- Potential tools/products/workflows: “AI Wage Dynamics Policy Simulator” using SDiD-inspired models; longitudinal tracking of cohorts.
- Assumptions/Dependencies: Long-run evidence on displacement; political support; funding and administrative capacity.
- Career matching to augmentation-prone occupations (Labor platforms, education)
- Use case: Recommend career transitions into roles where LLM complementarity is strong and employment resilience is high; offer stackable credentials.
- Potential tools/products/workflows: “AI-Augmented Career Navigator” combining exposure scores, local demand, and training pathways.
- Assumptions/Dependencies: Stable demand signals; validated augmentation benefits; equitable access to training.
- Enterprise governance for AI productivity sharing (Corporate policy, labor relations)
- Use case: Institutionalize frameworks to share productivity gains between firms and employees, reducing resistance to adoption and improving retention.
- Potential tools/products/workflows: Model policy toolkits; outcome-based bonus schemes; internal SDiD impact reviews.
- Assumptions/Dependencies: Measurable productivity; trust and transparency; scalable performance attribution.
- Longitudinal research on employment displacement and entry-level impacts (Academia, policy analysis)
- Use case: Track medium-run employment outcomes, especially for entry-level workers, as automation exposure rises; design targeted apprenticeships.
- Potential tools/products/workflows: Cohort panels linked to dynamic exposure; evaluation of apprenticeship efficacy with SDiD or similar designs.
- Assumptions/Dependencies: Sustained data collection; evolving LLM capabilities; collaboration across institutions.
- Curriculum redesign at scale (Education: K–12, higher ed, vocational)
- Use case: Embed LLM literacy, prompt engineering, and augmentation skills into curricula for writing, coding, analysis, and communication tasks.
- Potential tools/products/workflows: Competency frameworks aligned to O*NET tasks; assessment of augmentation proficiency.
- Assumptions/Dependencies: Standards adoption; teacher training; resource allocation.
- Infrastructure planning for scaled LLM use (Energy, IT)
- Use case: Plan compute, storage, and energy footprints to support widespread augmentation while managing costs and sustainability.
- Potential tools/products/workflows: “AI Workload Planner” with cost, latency, and carbon budgets; hybrid on-prem/cloud strategies.
- Assumptions/Dependencies: Stable cost curves; reliable supply chains; regulatory clarity on data and sustainability.
- Risk products for AI-driven wage volatility (Insurance, fintech)
- Use case: Develop insurance or financial products that help firms and workers manage wage volatility tied to tech adoption shocks.
- Potential tools/products/workflows: Wage volatility indices; parametric covers triggered by exposure-linked wage shifts.
- Assumptions/Dependencies: Sufficient historical data; actuarial validation; regulatory approval.
- International generalization and policy transfer (Global policy, development)
- Use case: Adapt exposure measures and wage-impact monitoring to non-U.S. contexts; support labor ministries with AI readiness tools.
- Potential tools/products/workflows: Localization of O*NET-style task taxonomies; country-specific SDiD implementations.
- Assumptions/Dependencies: Comparable labor statistics; cultural/task differences; institutional capacity.
Cross-cutting assumptions and dependencies
- The paper’s effects are short-run (post–Nov 2022 to Aug 2025) in the U.S.; generalization to other periods or geographies requires validation.
- Exposure is measured via prompt-task mapping (based on Anthropic Claude data), which reflects potential capability rather than realized adoption; firm-level audits may find different intensities.
- SDiD mitigates latent-factor bias but depends on sufficiently rich pre-periods, balanced panels, and appropriate donor pools.
- Labor markets exhibit frictions and relatively inelastic short-run supply across occupations; macroeconomic conditions could modulate observed wage dynamics.
- Organizational outcomes depend on governance, training, data access/privacy, and change management; heterogeneous effects are expected across occupations and firms.
Glossary
- Augmentative: Tasks where AI supports or enhances human work rather than replacing it. "classify tasks as “automative,” “augmentative,” or neither; occupational exposure is defined as the share of tasks with at least one prompt."
- Average Treatment Effect on the Treated (ATT): The expected causal effect of treatment for the treated group. "The coefficient identifies the average treatment effect on the treated (ATT), , under the parallel trends assumption:"
- Automative: Tasks where AI automates work previously done by humans. "classify tasks as “automative,” “augmentative,” or neither; occupational exposure is defined as the share of tasks with at least one prompt."
- Balanced panel: A dataset where every unit is observed in all required time periods. "the SDiD estimator requires a balanced panel in order to be implemented."
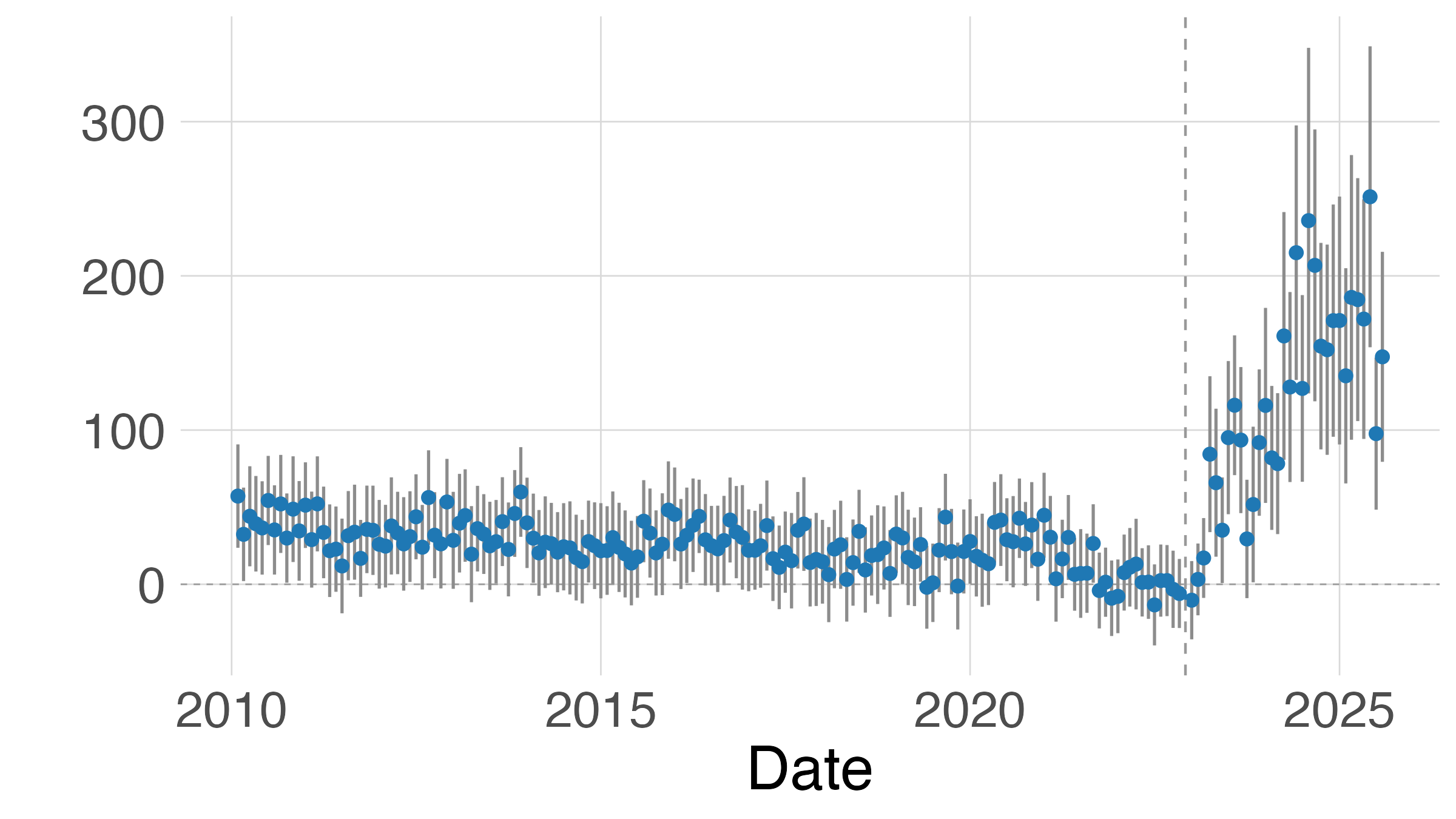
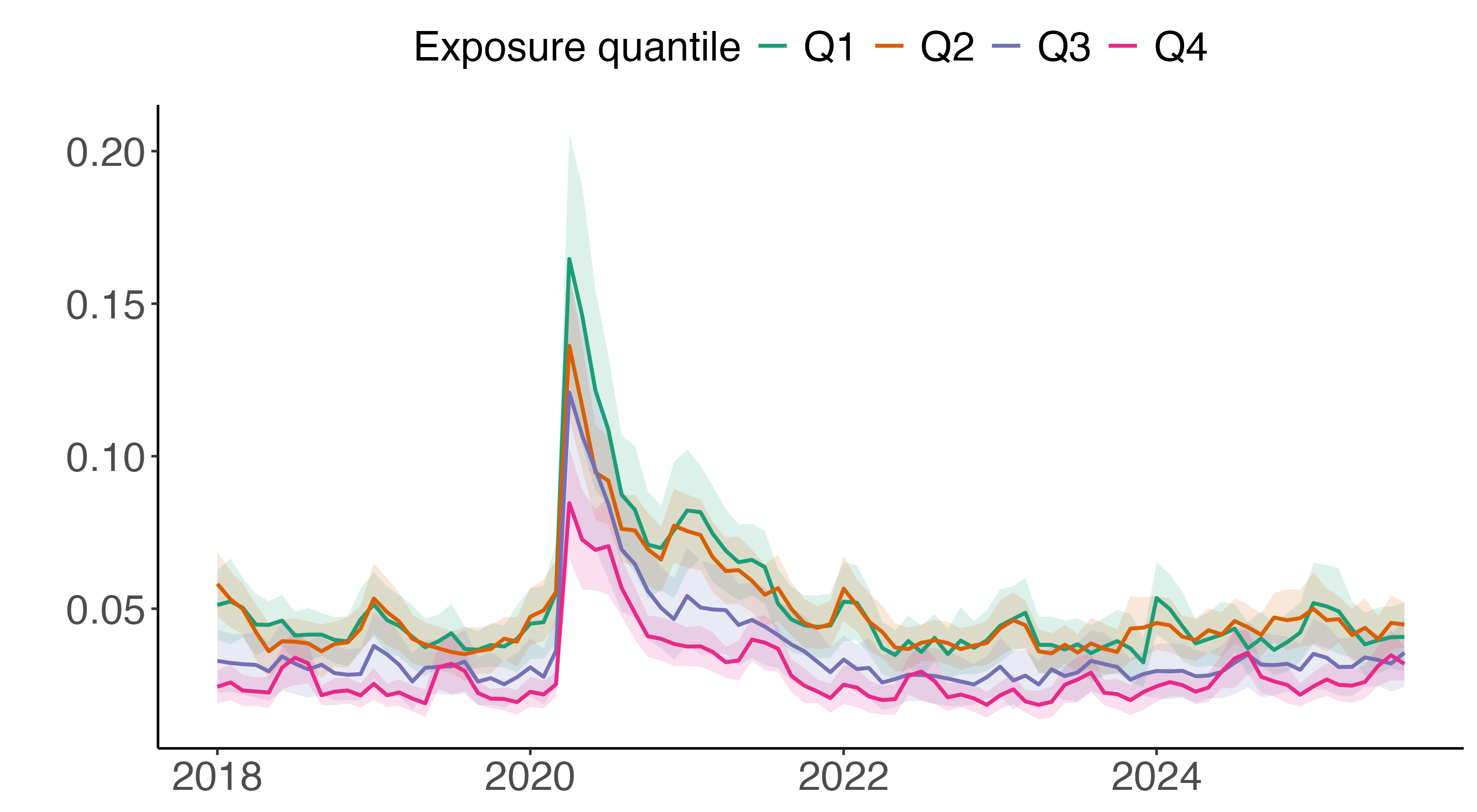
- Clustered standard errors: Standard errors adjusted for correlation within groups (clusters). "The gray lines indicates the 95% confidence interval, computed using clustered standard errors."
- Counterfactual outcomes: Outcomes that would have occurred for treated units if they had not been treated. "allows us to estimate counterfactual outcomes for occupations highly exposed to LLMs by constructing synthetic control groups from less exposed occupations."
- Crosswalk: A mapping between different classification systems. "through the standard crosswalk between O*NET-SOC and Census 2010 occupation codes"
- Current Population Survey (CPS): A U.S. household survey measuring labor force characteristics. "we use data from the Current Population Survey (CPS) from the Integrated Public Use Microdata Series (IPUMS)."
- Difference-in-Differences (DiD): A causal inference method comparing changes over time between treated and control groups. "Our strategy begins with the canonical difference-in-differences (DiD) design and extends it with the synthetic difference-in-differences (SDiD) estimator"
- Donor pool: The set of control units used to construct synthetic comparisons. "we restrict the donor pool to control units that form a balanced panel with it"
- Endogeneity: A situation where explanatory variables are correlated with the error term, biasing estimates. "it avoids endogeneity that would arise if we measured exposure from realized adoption"
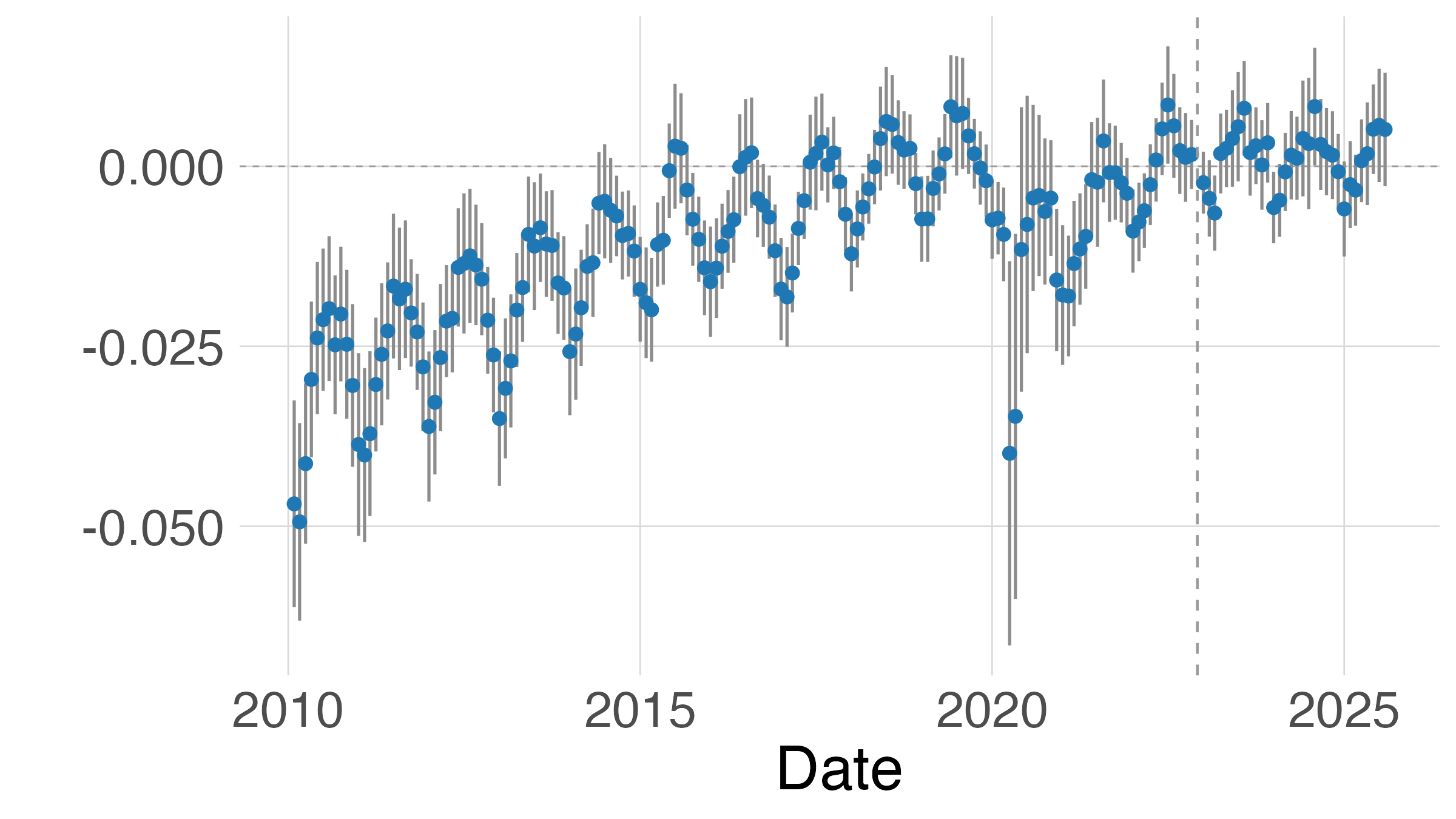
- Event study: A model tracing dynamic effects over time relative to an event. "we also estimate an event-study model:"
- Exogenous: External or not caused by variables in the model; not correlated with error terms. "heterogeneity in exposure that is plausibly exogenous to short-run labor market outcomes."
- General-purpose technology: A technology with broad, pervasive impacts across sectors. "assess whether LLMs meet the criteria of a general-purpose technology"
- Integrated Public Use Microdata Series (IPUMS): A harmonized collection of survey microdata. "we use data from the Current Population Survey (CPS) from the Integrated Public Use Microdata Series (IPUMS)."
- Interactive fixed-effects: A model that includes unit and time effects plus latent factor interactions. "The SDiD framework can be interpreted within an interactive fixed-effects model for untreated potential outcomes:"
- Intent-to-treat effect: The effect of being exposed/assigned to treatment, regardless of actual take-up. "our estimates resemble an “intent-to-treat” effect, with actual adoption rates varying across contexts."
- Labor-demand curve: The relationship between wages and the quantity of labor demanded by firms. "When they complement workers by raising task productivity, the labor-demand curve shifts outward, increasing wages andâafter market adjustmentâemployment."
- Latent factors: Unobserved variables that drive systematic variation over time or across units. "driven by latent factor." / "represents latent factors driving persistent heterogeneity in trends across occupations."
- Machine-learning suitability scores: Metrics indicating how well tasks can be addressed by machine learning. "a rubric of LLM capabilities modeled on machine-learning suitability scores"
- Multimodal reasoning capabilities: The ability of models to reason across multiple data modalities (e.g., text, images). "once models acquire multimodal reasoning capabilities."
- O*NET: The Occupational Information Network, a database of job characteristics and tasks. "who identify tasks in the Occupational Information Network (O*NET) that are potentially affected by LLMs."
- O*NET-SOC: The standardized occupational classification within O*NET used for mapping tasks to occupations. "through the standard crosswalk between O*NET-SOC and Census 2010 occupation codes"
- Outgoing Rotation Group (ORG): CPS subsample where detailed earnings questions are asked. "we use the CPS Outgoing Rotation Group (ORG) earnings data."
- Panel (data): Data containing repeated observations over time for the same units. "We study the impact of LLMs on employment and earnings through a panel of occupations by month-year."
- Parallel trends assumption: The requirement that treated and control groups would have followed similar trends absent treatment. "The coefficient identifies the average treatment effect on the treated (ATT) ... under the parallel trends assumption:"
- Quasi-experimental variation: Variation that mimics random assignment due to an external shock. "leveraging the quasi-experimental variation generated by the sudden public release of ChatGPT."
- Sampling weights: Weights applied to survey data to make estimates representative of the population. "We do not apply the CPS sampling weights at the occupation level"
- Synthetic control: A method that constructs a weighted combination of control units to match treated units’ pre-treatment trajectories. "Unit weights $\omega = (\omega_1,\dots,\omega_{N_{\mathrm{co})$, which, similar to synthetic control, are assigned to control occupations"
- Synthetic Difference-in-Differences (SDiD): An estimator combining synthetic control weighting with DiD to correct for non-parallel trends. "Our empirical strategy employs the Synthetic Difference-in-Differences (SDiD) methodology"
- Time weights: Weights over pre-treatment time periods used to predict post-treatment outcomes in SDiD. "Time weights $\lambda = (\lambda_1,\dots,\lambda_{T_{\mathrm{pre})$, assigned to pre-treatment periods"
- Top-coded earnings: Earnings values censored at an upper threshold to protect confidentiality. "The reported income in the IPUMS CPS data is top-coded earnings."
- Two-way fixed effects: A regression specification with unit and time fixed effects. "The baseline two-way fixed-effects specification is"
- Unit weights: Weights across control units used to match treated units’ pre-treatment paths in SDiD. "Unit weights $\omega = (\omega_1,\dots,\omega_{N_{\mathrm{co})$, which, similar to synthetic control, are assigned to control occupations, chosen to match the average pre-treatment path of treated units"
Collections
Sign up for free to add this paper to one or more collections.

