- The paper’s main contribution is the conditional diffusion-based framework that refines depth estimates to overcome local minima in multi-view stereo.
- It employs a lightweight 3D U-Net for initial depth estimation and a convolutional GRU for iterative denoising, ensuring high efficiency and accuracy.
- Confidence-aware sampling adaptively generates multiple depth hypotheses per pixel, enhancing robustness and performance across diverse benchmarks.
Lightweight and Accurate Multi-View Stereo with Confidence-Aware Diffusion Model
Introduction and Motivation
This work introduces a novel multi-view stereo (MVS) framework leveraging conditional diffusion models for efficient and accurate 3D reconstruction from calibrated images. The approach addresses key limitations in prior learning-based MVS methods, particularly the tendency to get trapped in local minima during depth refinement and the computational inefficiency of large 3D CNNs or transformer-based architectures. By formulating depth refinement as a conditional diffusion process, the framework injects random perturbations to escape local minima while maintaining deterministic estimation via a carefully designed condition encoder. The proposed methods, DiffMVS and CasDiffMVS, demonstrate state-of-the-art (SOTA) performance and efficiency across multiple benchmarks.
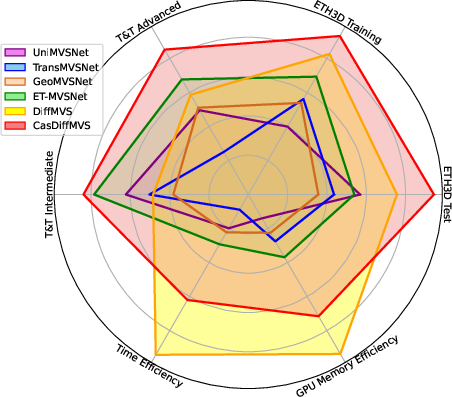
Figure 1: Comparison between DiffMVS, CasDiffMVS, and SOTA learning-based MVS methods on reconstruction performance, run-time, and GPU memory. CasDiffMVS achieves superior reconstruction with lower resource consumption.
Methodology
Overall Pipeline
The framework consists of two main modules: depth initialization and diffusion-based depth refinement. Depth initialization produces a coarse depth map at low resolution using a lightweight cost volume and 3D U-Net regularization. The subsequent diffusion-based refinement iteratively denoises the coarse depth map, guided by a condition encoder that fuses geometric matching, image context, and depth context features.
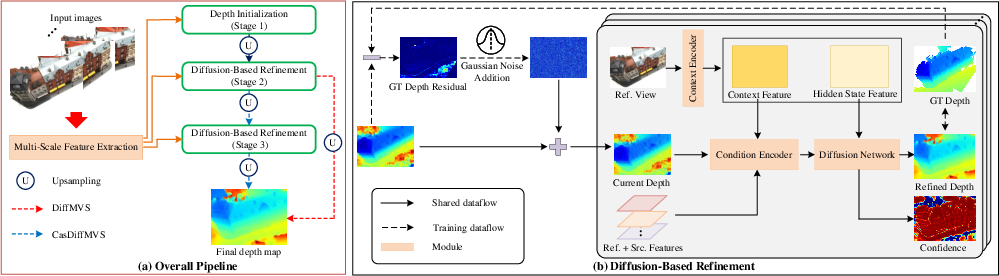
Figure 2: Overview of DiffMVS and CasDiffMVS pipelines. DiffMVS uses a single diffusion-based refinement stage, while CasDiffMVS employs cascade refinement for higher accuracy.
Depth Initialization
Depth hypotheses are uniformly sampled in the inverse depth range, and group-wise correlation is used to construct similarity volumes. Pixel-wise view weights are predicted to aggregate matching information robustly, accounting for occlusions. The aggregated cost volume is regularized by a lightweight 3D U-Net, and the initial depth is computed as the expectation in the inverse range.

Figure 3: Pipeline of depth initialization using a lightweight cost volume and 3D U-Net regularization.
Diffusion-Based Refinement
Conditional Diffusion Process
Depth refinement is cast as a conditional diffusion process, where the normalized inverse depth is iteratively denoised. The condition encoder fuses local cost volume, depth hypotheses, and image context features to guide the diffusion network.
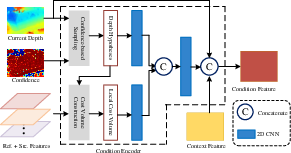
Figure 4: Structure of the condition encoder, integrating cost volume, depth hypotheses, and image context.
Diffusion Network Architecture
A lightweight 2D U-Net is combined with a convolutional GRU, enabling multi-iteration refinement within each diffusion timestep. This design circumvents the need for large or stacked U-Nets, significantly improving efficiency.
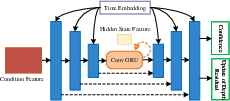
Figure 5: Structure of the diffusion network, combining 2D U-Net and convolutional GRU for iterative denoising.
Confidence-Based Sampling
A novel confidence-based sampling strategy adaptively generates multiple depth hypotheses per pixel. The per-pixel confidence, predicted by the diffusion model, adjusts the sampling range: high confidence narrows the range for fine refinement, while low confidence broadens it to recover from errors. This mechanism provides informative first-order optimization directions, enhancing the denoising process.
Learned Upsampling
Between stages, learned upsampling with a mask is used instead of bilinear or nearest interpolation, improving depth map quality by leveraging local neighborhood information.
Training and Inference
The loss function incorporates L1 error in normalized inverse depth, weighted by confidence and regularized to avoid trivial solutions. Exponentially increasing weights balance supervision across stages and iterations. During inference, DDIM sampling is used for efficiency, with only one timestep required due to the strong initialization.
Experimental Results
DiffMVS and CasDiffMVS are evaluated on DTU, Tanks and Temples, and ETH3D datasets. CasDiffMVS achieves SOTA reconstruction accuracy and completeness, outperforming prior methods in both indoor and outdoor scenes. DiffMVS offers competitive accuracy with unmatched efficiency in run-time and memory.

Figure 6: Qualitative comparisons of reconstruction errors on Tanks and Temples dataset.

Figure 7: Qualitative comparisons of reconstruction errors on ETH3D dataset.
Efficiency Analysis
DiffMVS achieves the highest efficiency in both run-time and GPU memory among all evaluated methods. CasDiffMVS, despite its cascade refinement, remains more efficient than transformer- and 3D CNN-based competitors.
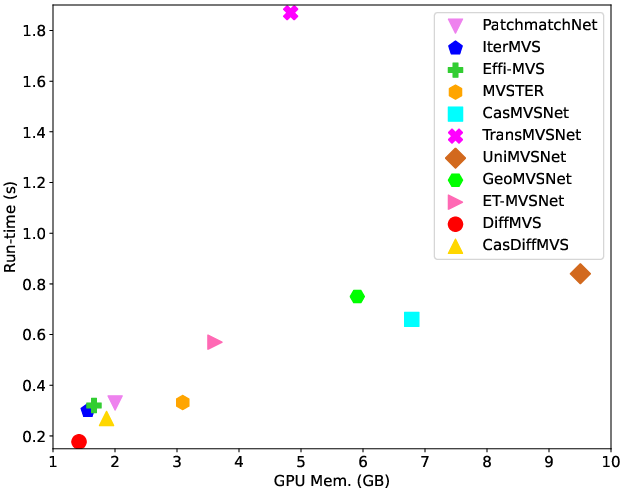
Figure 8: Efficiency comparison with SOTA MVS methods on DTU in terms of run-time and GPU memory.
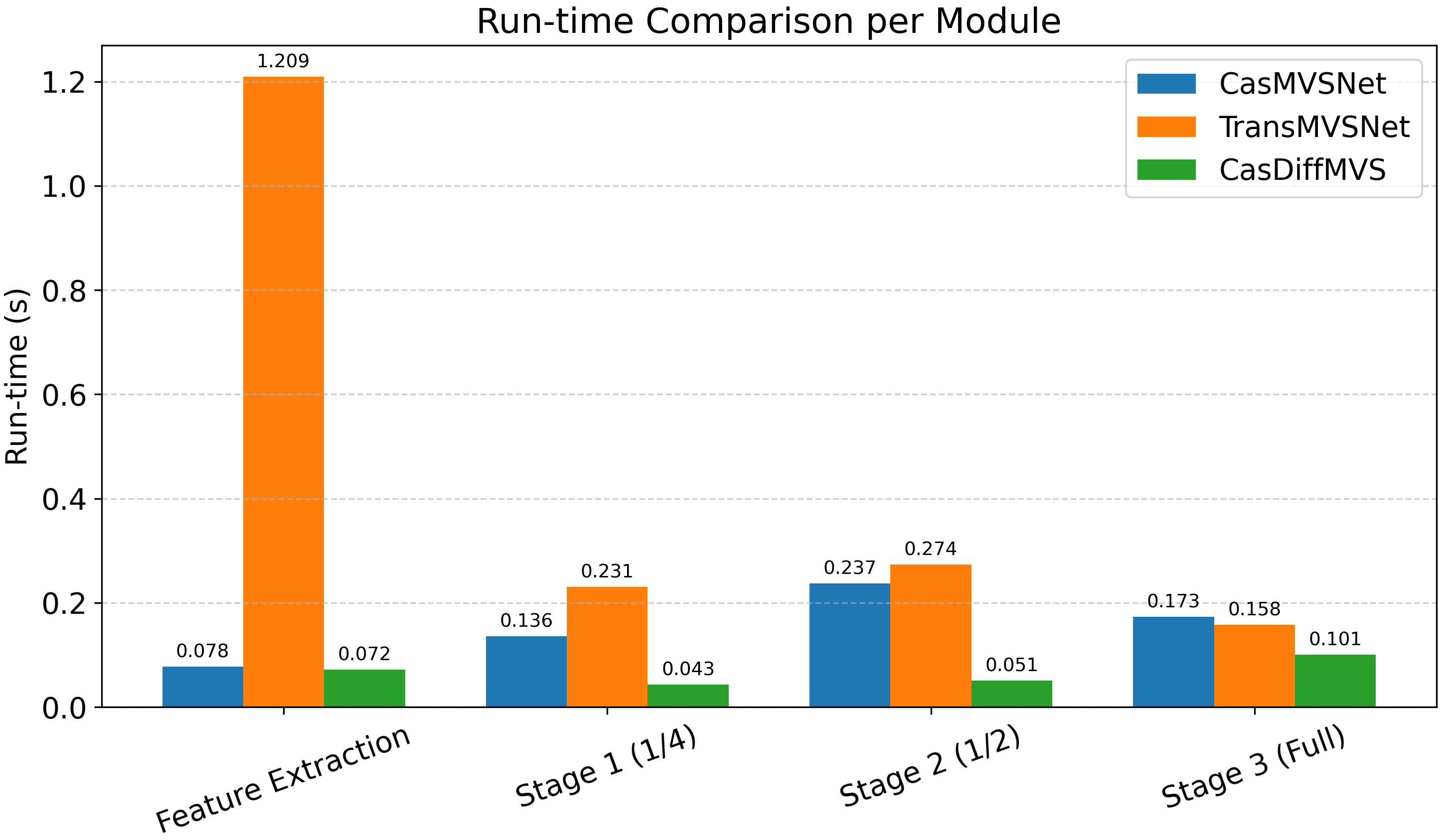
Figure 9: Run-time comparison per module on DTU, highlighting the advantages of the proposed architecture.
Confidence Visualization
The learned confidence maps reliably reflect depth error distributions, with high confidence in regions of low error and vice versa, despite unsupervised training.

Figure 10: Visualization of reference image, depth map, depth error map, and confidence map on BlendedMVS validation set.
Ablation Studies
Comprehensive ablations validate the contributions of each component:
- Diffusion Process: Removing diffusion or replacing it with noise augmentation degrades performance, confirming the necessity of the conditional diffusion mechanism.
- Condition Encoder: Excluding cost volume, depth context, or image context features reduces accuracy, demonstrating the importance of each.
- Confidence-Based Sampling: Fixed or single-sample strategies underperform compared to adaptive, confidence-driven sampling.
- Diffusion Network Design: The convolutional GRU enables iterative refinement with fewer parameters and better convergence than stacked U-Nets.
Implementation Considerations
- Resource Requirements: DiffMVS is suitable for real-time and resource-constrained applications, while CasDiffMVS targets high-accuracy scenarios.
- Scaling: The lightweight architecture and efficient sampling enable deployment on standard GPUs and potential adaptation for mobile devices.
- Limitations: The method relies on accurate initial depth estimation; extreme noise or poor initialization may affect convergence.
Implications and Future Directions
The integration of conditional diffusion models into MVS offers a principled approach to escaping local minima and balancing efficiency with accuracy. The confidence-aware sampling mechanism provides a robust optimization direction, and the lightweight network design facilitates practical deployment. Future research may explore further reduction of computational overhead, adaptation to uncalibrated or sparse-view scenarios, and extension to other geometry estimation tasks such as surface normal or optical flow estimation.
Conclusion
This work presents a conditional diffusion-based MVS framework with a confidence-aware sampling strategy and lightweight network architecture. DiffMVS and CasDiffMVS set new baselines for efficient and accurate multi-view depth estimation, demonstrating strong generalization and resource efficiency. The approach provides a foundation for future advances in learning-based 3D reconstruction and related vision tasks.