- The paper presents FCPE, a fast and robust pitch estimation model leveraging a Lynx-Net backbone with depthwise separable convolutions for efficient feature extraction.
- It employs targeted training strategies—noise augmentation, spectrogram masking, and key shifting—to significantly improve accuracy and noise resilience.
- FCPE achieves 96.79% raw pitch accuracy with only 10.64M parameters and an RTF of 0.0062, making it ideal for real-time applications and deployment on resource-constrained devices.
FCPE: A Fast Context-based Pitch Estimation Model
Introduction and Motivation
Pitch estimation (PE) in monophonic audio is a foundational task for applications such as MIDI transcription and singing voice conversion (SVC). Traditional PE methods—time-domain, frequency-domain, and hybrid approaches—have achieved moderate success but remain vulnerable to noise and polyphonic interference. Deep learning-based models, notably CREPE, DeepF0, HARMOF0, and RMVPE, have advanced the state-of-the-art in accuracy and robustness. However, these models often incur substantial computational costs and latency, limiting their utility in real-time and resource-constrained scenarios.
FCPE (Fast Context-based Pitch Estimation) addresses these limitations by leveraging a Lynx-Net backbone with depthwise separable convolutions, enabling efficient feature extraction from mel spectrograms while maintaining robust performance under noisy conditions. The model is designed to deliver high accuracy with significantly reduced inference time and computational requirements.
Model Architecture
FCPE processes input audio by first converting the waveform into a log-mel spectrogram, which is then embedded via shallow 1D convolutional layers. An optional harmonic embedding augments the input sequence to enhance harmonic feature representation. The core of FCPE is a stack of Lynx-Net blocks, each employing depthwise Conv1D layers for local pattern extraction, pointwise convolutions for channel management, and residual connections to facilitate deep network training. The output stage projects the refined features to a pitch probability matrix over 360 cent bins, covering six octaves with 20-cent resolution.
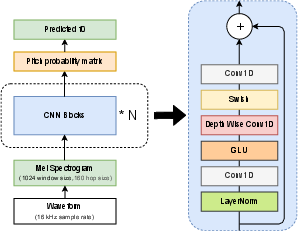
Figure 1: Overall architecture of FCPE, illustrating the input embedding, Lynx-Net backbone, and output projection stages.
Decoding employs a local weighted average around the peak probability bin, yielding a more precise and robust f0 estimate than simple argmax. The model is trained using binary cross-entropy loss over the pitch bins, with targets defined as in CREPE.
Training Strategies
To ensure objective ground truth and mitigate manual labeling errors, training data is re-synthesized using DDSP from M4Singer and VCTK datasets. Three key data augmentation strategies are employed:
- Random Key Shifting: Increases pitch diversity and expands the model's vocal range.
- Noise Augmentation: Superimposes various noise types (white, colored, real-world) to enhance robustness.
- Spectrogram Masking: Applies blank or Gaussian masks to compel the model to infer pitch from temporal context rather than isolated frames.
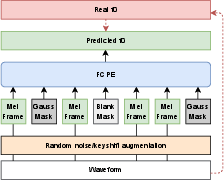
Figure 2: Details of training strategies, including key shifting, noise augmentation, and spectrogram masking.
These strategies are empirically validated to significantly improve robustness, especially under severe noise conditions.
Experimental Results
Accuracy and Robustness
FCPE is benchmarked against RMVPE, CREPE, PESTO, PM, and Harvest on MIR-1K, Vocadito, TONAS, and THCHS30-Synth datasets under clean and noisy conditions. FCPE achieves 96.79% Raw Pitch Accuracy (RPA) on MIR-1K, matching or surpassing state-of-the-art models with only 10.64M parameters—substantially fewer than RMVPE (90.42M) and CREPE (22.24M). Notably, FCPE maintains high accuracy even at low SNRs and under real-world noise, demonstrating strong noise tolerance.
Computational Efficiency
FCPE's Real-Time Factor (RTF) is 0.0062 on a single RTX 4090 GPU, outperforming RMVPE (0.0329), PESTO (0.0164), and CREPE (0.4775) by large margins. The model requires only 1.06 GFLOPS to process one second of audio, making it suitable for real-time applications and deployment on edge devices.
Ablation Study
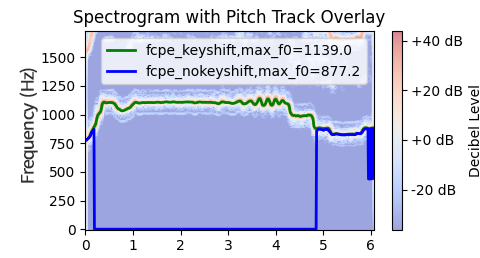
Ablation experiments systematically remove each augmentation strategy to quantify their contributions:
Implications and Future Directions
FCPE demonstrates that efficient context modeling via Lynx-Net and targeted data augmentation can yield high-accuracy, low-latency pitch estimation suitable for real-time and large-scale applications. The use of DDSP-resynthesized data for training further addresses data scarcity and enhances generalization. The model's architecture and training strategies are broadly applicable to other audio analysis tasks requiring robust, efficient temporal modeling.
Future work may explore extending FCPE to polyphonic pitch estimation, integrating it into end-to-end SVC pipelines, and optimizing deployment for mobile and embedded platforms. The demonstrated efficiency and robustness suggest potential for widespread adoption in both research and industry.
Conclusion
FCPE introduces a fast, context-based approach to pitch estimation, achieving state-of-the-art accuracy and robustness with minimal computational overhead. The combination of Lynx-Net architecture and advanced training strategies enables real-time performance and strong generalization, establishing FCPE as a practical solution for diverse pitch estimation tasks.