- The paper introduces the Astralora framework, which employs a low-rank surrogate model for gradient propagation through non-differentiable physical layers.
- It utilizes stochastic zeroth-order optimization to update black-box hardware parameters via efficient forward queries, bypassing traditional backpropagation.
- Experimental results on image, audio, and language tasks demonstrate that near-digital accuracy is maintained with various physical layer implementations.
Low-Rank Surrogate Modeling and Stochastic Zero-Order Optimization for Training Neural Networks with Black-Box Layers
Introduction and Motivation
The paper addresses the challenge of integrating non-differentiable physical components—such as photonic, neuromorphic, or analog hardware—into deep neural network (NN) training pipelines. These components, often modeled as black-box (BB) linear operators, lack explicit gradient information and may exhibit limited expressiveness, noise, or drift. Standard backpropagation is inapplicable, impeding end-to-end optimization. The authors propose a general framework, astralora (Adaptive Surrogate TRAining with LOw RAnk), that enables efficient training of hybrid digital-physical NNs by combining stochastic zeroth-order (ZO) optimization for hardware parameter updates with a dynamically refined low-rank surrogate model (SM) for gradient propagation.
Framework Overview
Astralora replaces a selected linear layer in a NN with a BB physical layer, modeled as $y = \fbb(x) = A x$, where A is a hardware-dependent matrix. The framework consists of two synergistic components:
- Low-Rank Surrogate Model (SM): A parameter-disentangled, rank-r approximation A≈USVT is maintained and updated online. This surrogate enables gradient flow through upstream layers during backpropagation, despite the non-differentiability of the BB layer.
- Stochastic Zeroth-Order Optimization: The BB parameters are updated using Monte Carlo finite-difference gradient estimates, requiring only forward queries to the hardware. This approach is query-efficient and robust to hardware constraints.
The SM is updated after each training step using an implicit projector-splitting integrator (I-PSI), which leverages incremental changes in A to avoid costly full matrix reconstruction.
Physical Layer Models
The framework is validated on several photonic layer architectures:
- Matvec Layer: Directly programmable matrix-vector multiplication.
- MRR Layer: Microring resonator banks for wavelength-selective operations.
- SLM Layer: Spatial light modulator-based free-space optical multipliers.
- SLM Monarch Layer: Structured Monarch matrices implemented with SLM blocks.
- Planar Meshes: Mach-Zehnder interferometer (MZI) and 3-MZI meshes for unitary transformations.
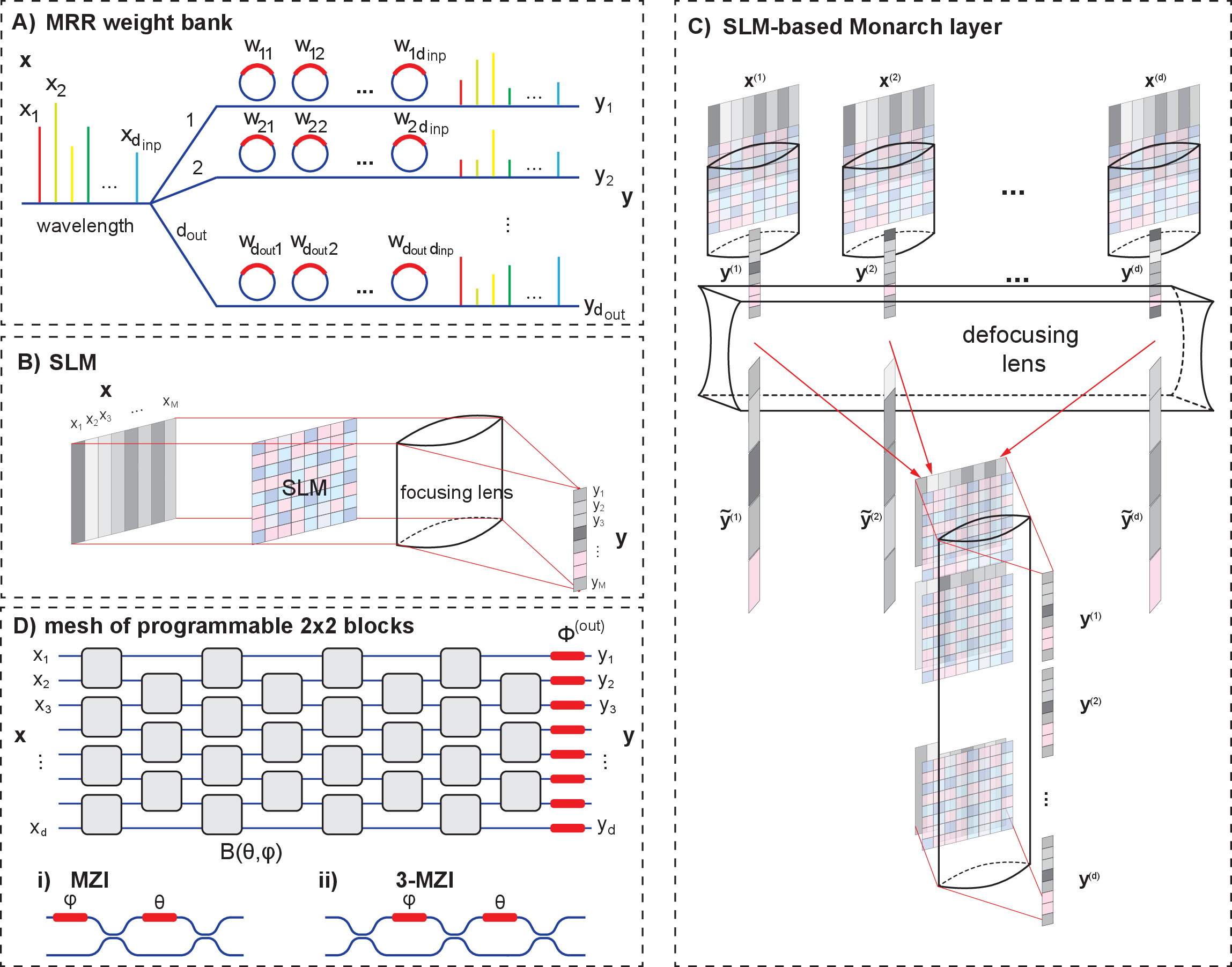
Figure 1: Illustration of the physical layers simulated in this work: a) MRR weight banks, b) SLM-based multiplier, c) Monarch matrix multiplier exploiting SLM-based optical blocks, d) planar interferometric meshes of the MZI (i) and 3-MZI (ii) blocks.
Each layer presents distinct parameter-to-matrix mappings, ranging from simple (matvec) to highly nonlinear (MZI meshes), testing the generality of the proposed training approach.
Algorithmic Details
Zeroth-Order Gradient Estimation
For BB parameter updates, the gradient of the loss with respect to BB parameters is approximated via stochastic finite differences:
$g(x, v) \approx \frac{1}{\mu M_{BB}} \sum_{i=1}^{M_{BB}} \langle \fbb[\omega + \mu u_i](x) - \fbb[\omega](x), v \rangle$
where ui are random perturbations and μ is a scalar step size. This requires MBB+1 forward queries per update.
Surrogate Model Update (I-PSI)
The I-PSI algorithm incrementally updates the low-rank factors (U,S,V) using only a small number of forward queries to the BB layer, exploiting the change ΔA between consecutive parameter states. This avoids full matrix reconstruction and maintains numerical stability and low-rank structure.
Training Pipeline
During each training step:
- Forward pass: The BB layer computes $y_{bb} = \fbb(x_{in})$.
- Backward pass: The SM propagates gradients upstream.
- BB parameters are updated via ZO optimization.
- SM is realigned with the new BB state using I-PSI.
This pipeline is agnostic to the specific hardware implementation and can be applied to any non-differentiable or hardware-constrained module.
Experimental Results
CIFAR-10 Image Classification
A deep convolutional NN with one linear layer replaced by a BB photonic layer is trained on CIFAR-10. The accuracy is evaluated for various surrogate ranks r and query budgets M.
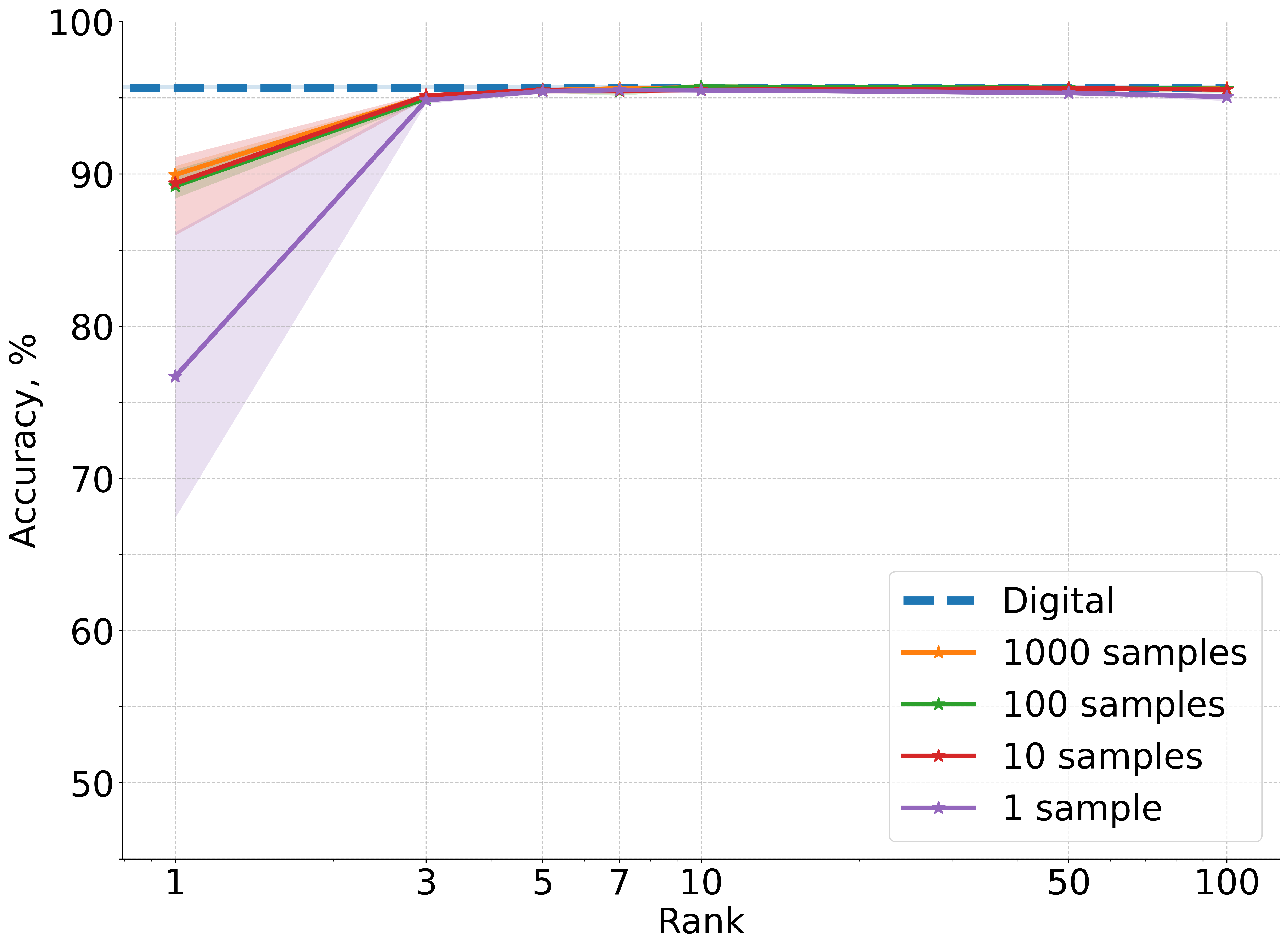
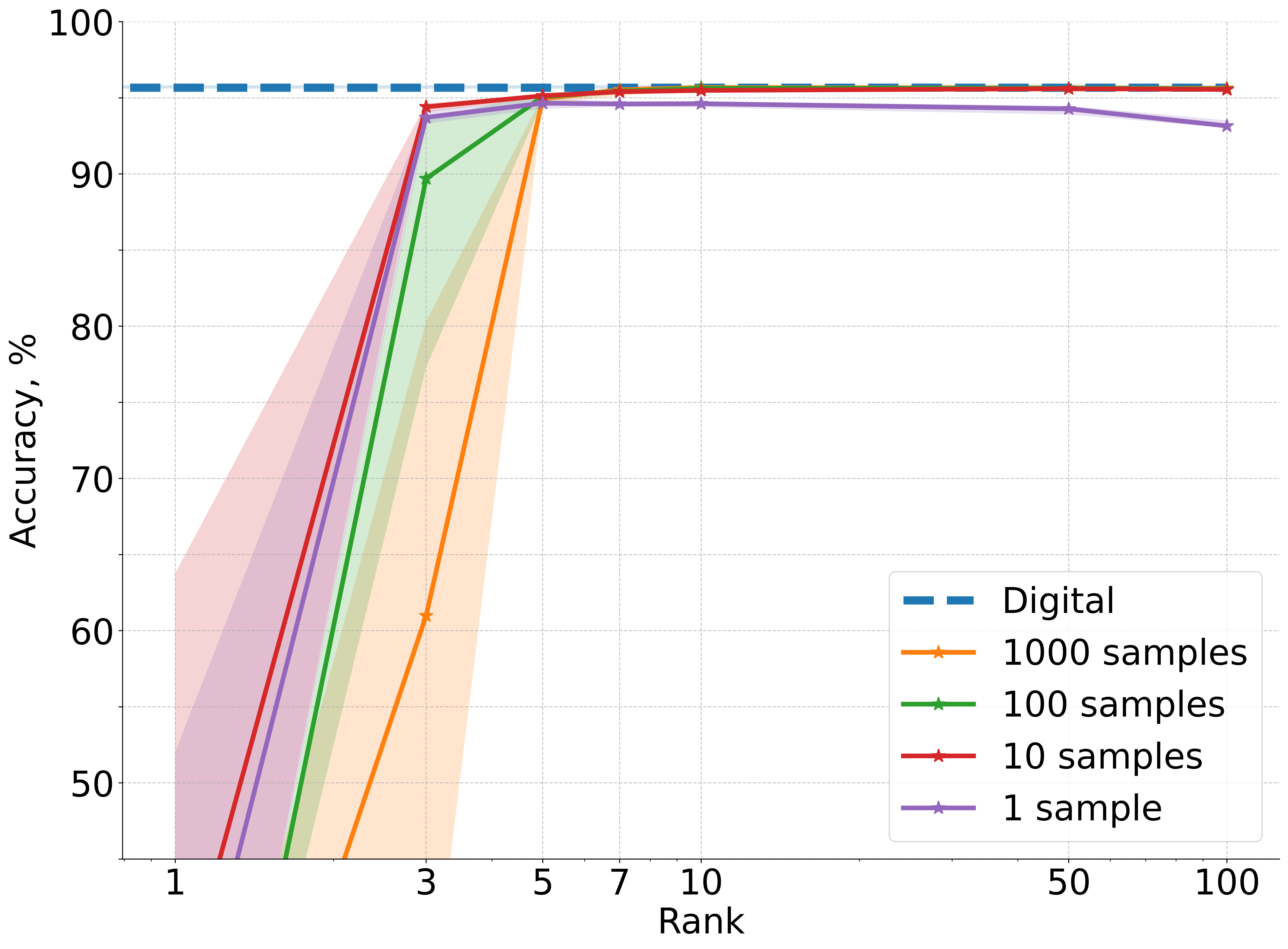
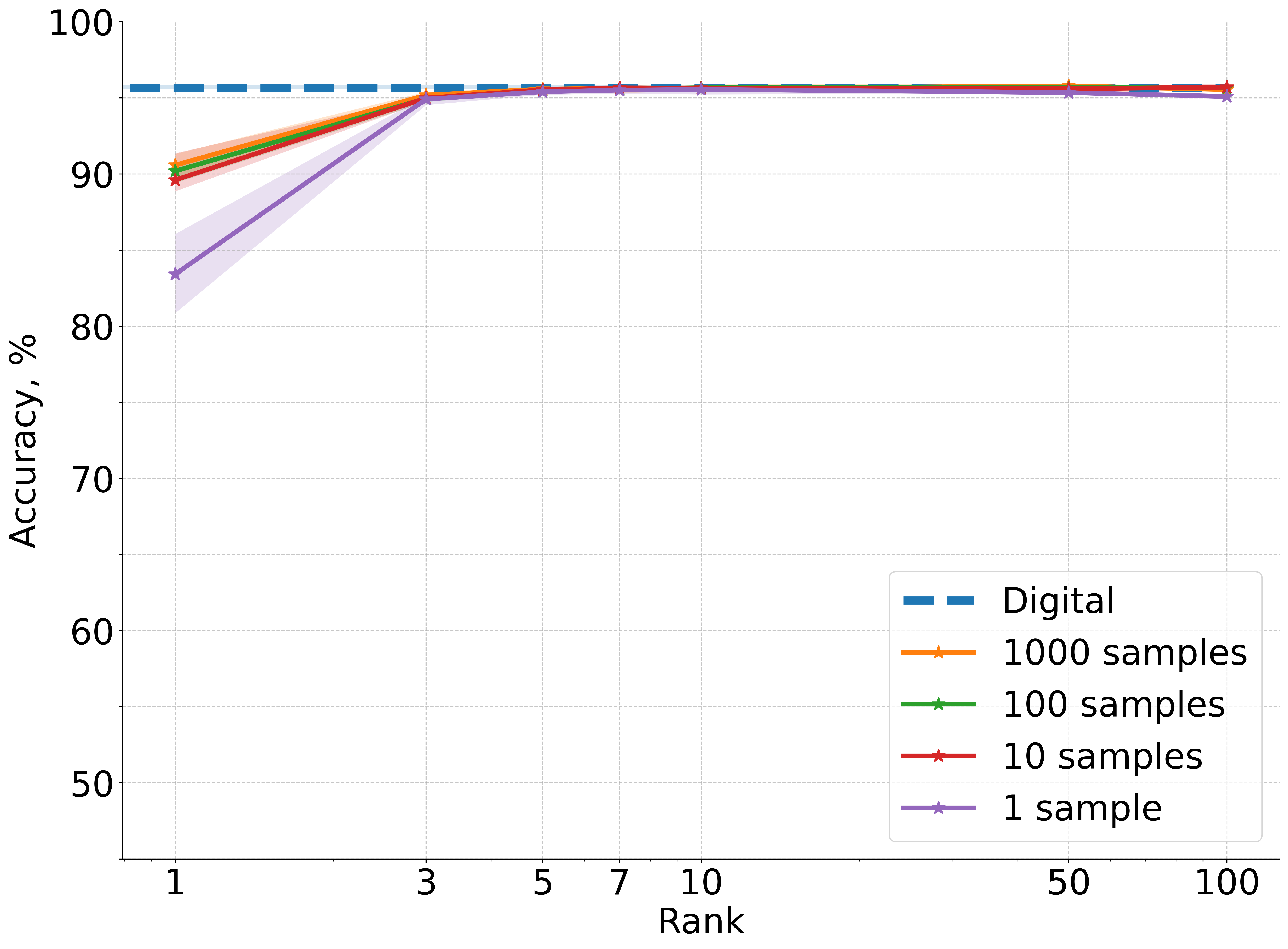
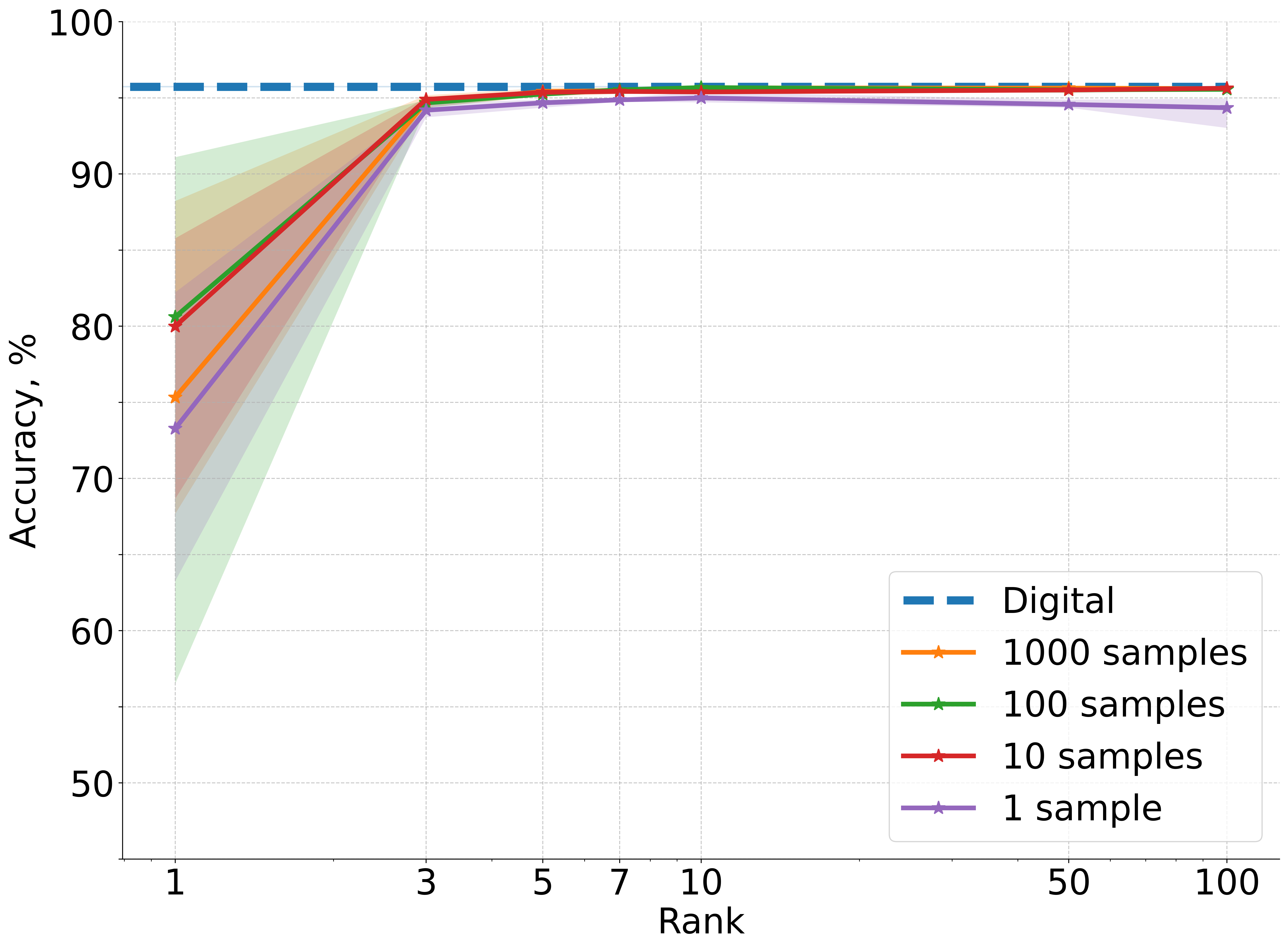
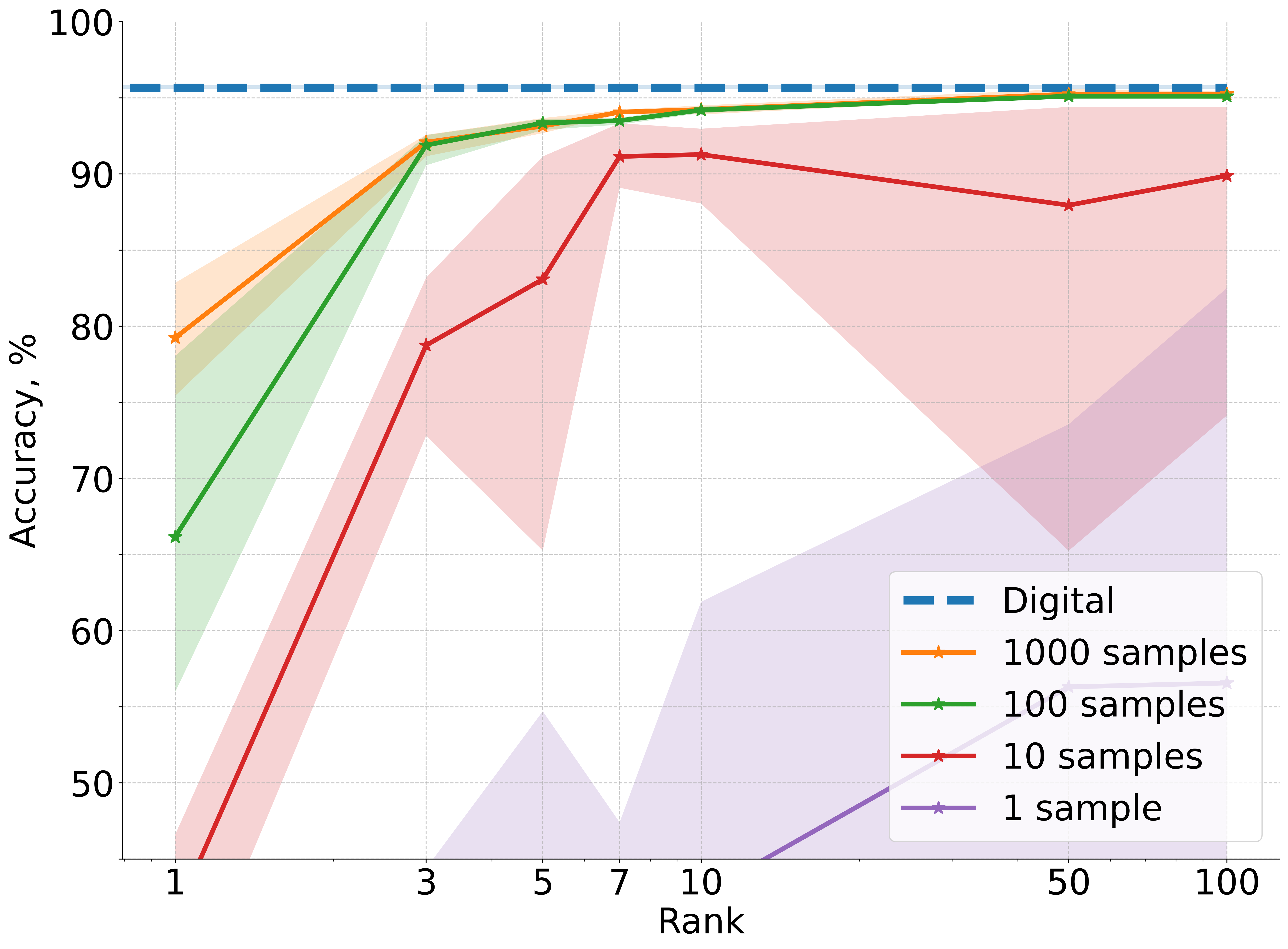
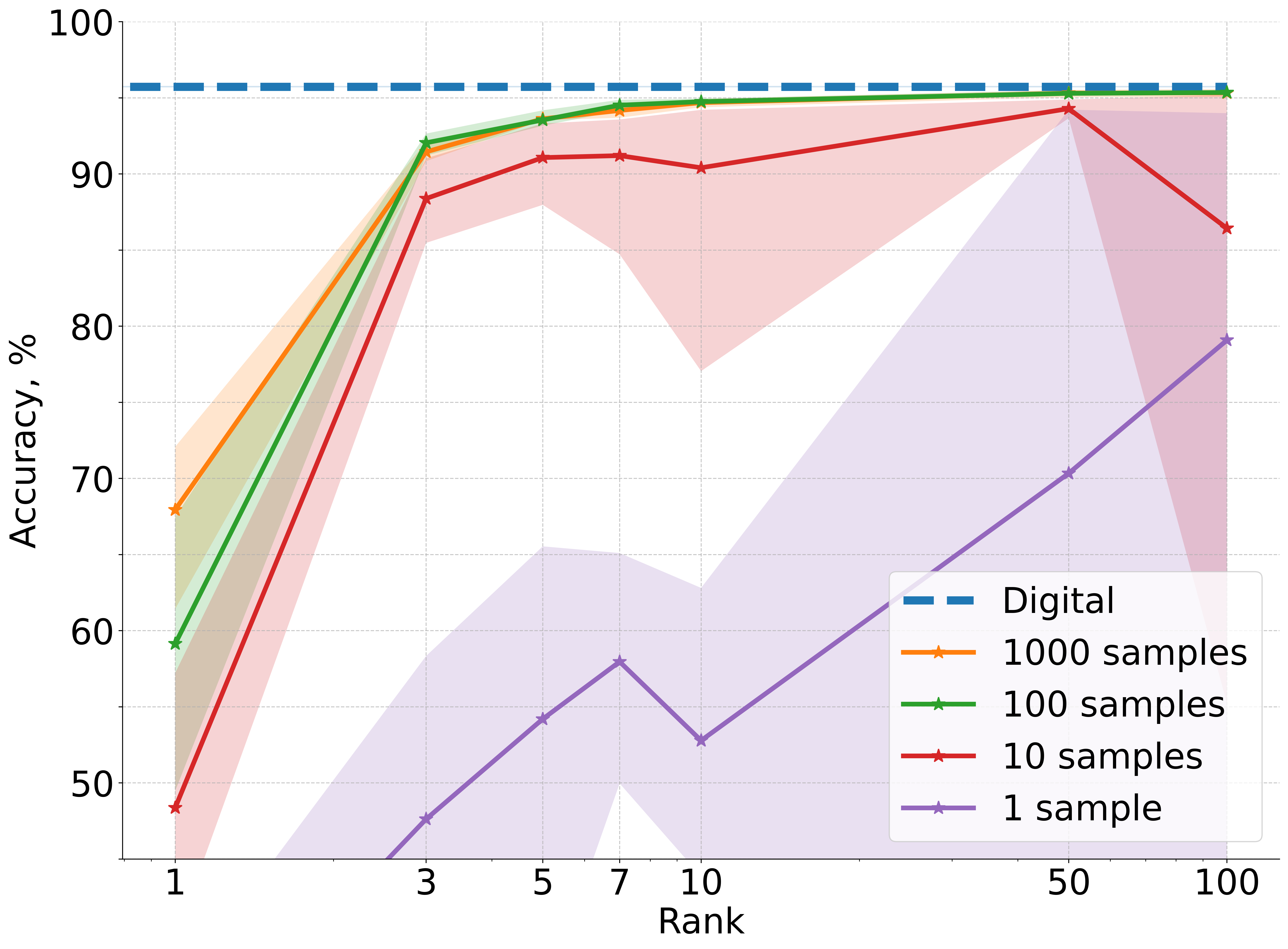
Figure 2: Accuracy results averaged over five independent runs for CIFAR-10 image classification using a deep convolutional neural network architecture where one linear layer is replaced with non-differentiable physical photonic layer.
Key findings:
- All photonic layer types (matvec, mrr, slm, monarch, mzi, 3-mzi) achieve near-digital baseline accuracy when r≥10 and M≥100.
- The framework is robust to the specific nonlinearities and parameter mappings of different hardware layers.
Audio Classification (UrbanSound8K, ECAPA-TDNN)
Replacing a critical linear layer with a BB photonic layer, the framework achieves accuracy within 1−2% of the digital baseline for r≥10. The monarch layer slightly surpasses the baseline at high rank, indicating beneficial architectural bias.
Large-Scale Language Modeling (GPT-2, FineWeb)
Experiments with a 417M-parameter GPT-2-like model show:
- Replacing up to 12 linear layers or entire MLP blocks with BB layers results in graceful degradation of validation perplexity.
- The model remains trainable even when the number of digitally updated parameters is reduced by more than half.
- Performance is consistent across all photonic layer types.
Implications and Future Directions
The results demonstrate that accurate backpropagation is not strictly necessary for end-to-end training of hybrid NNs with non-differentiable layers. Efficient surrogate modeling and ZO optimization suffice, provided query budgets and surrogate ranks are chosen appropriately. This finding has significant implications for hardware-aware AI, enabling scalable integration of photonic, neuromorphic, or analog accelerators into deep learning systems.
Potential future developments include:
- Extending the framework to nonlinear or multi-layer physical modules.
- Adaptive rank selection and query budgeting for further efficiency.
- Hardware-in-the-loop experiments to validate real-world performance and robustness.
- Application to edge devices and resource-constrained environments.
Conclusion
Astralora provides a principled, generalizable solution for training hybrid digital-physical neural networks with non-differentiable black-box layers. By combining stochastic zeroth-order optimization with dynamic low-rank surrogate modeling, the framework achieves near-digital accuracy across diverse tasks and hardware implementations, with strong query efficiency and scalability. This work advances the practical integration of physical computing platforms into modern AI pipelines, supporting the development of energy-efficient, high-performance machine learning systems.
