- The paper presents a biologically grounded benchmark evaluating both visual robustness and neural alignment in RL agents and mice.
- The study employs a naturalistic foraging task in a 3D Unity environment with over 70% success in mice and comprehensive neural recordings.
- Empirical findings reveal a significant robustness gap and limited neural alignment in AI agents compared to mice, urging improvements in model design.
Mouse vs. AI: A Neuroethological Benchmark for Visual Robustness and Neural Alignment
Introduction
This paper introduces the Mouse vs. AI: Robust Foraging competition, a neuroethological benchmark designed to evaluate both visual robustness and neural alignment in reinforcement learning (RL) agents. The benchmark is grounded in a biologically inspired foraging task performed by both artificial agents and real mice within a shared, naturalistic 3D Unity environment. The competition is structured into two tracks: (1) visual robustness under distributional shift, and (2) alignment of internal model representations with large-scale neural recordings from mouse visual cortex. The benchmark provides a multimodal dataset, including behavioral performance and two-photon calcium imaging data from over 19,000 neurons, enabling direct comparison between artificial and biological systems.
Benchmark Design and Task Structure
The core task is a visually guided navigation problem in a Unity-based environment, where agents and mice must locate and reach a visually cued target object using egocentric visual input. The environment incorporates naturalistic features—textured trees, shrubs, dynamic lighting, and wind-driven motion—to approximate real-world visual statistics and introduce trial-to-trial variability. The target object is designed to be nontrivial to segment, with luminance matched to its surroundings and randomized spatial offsets.
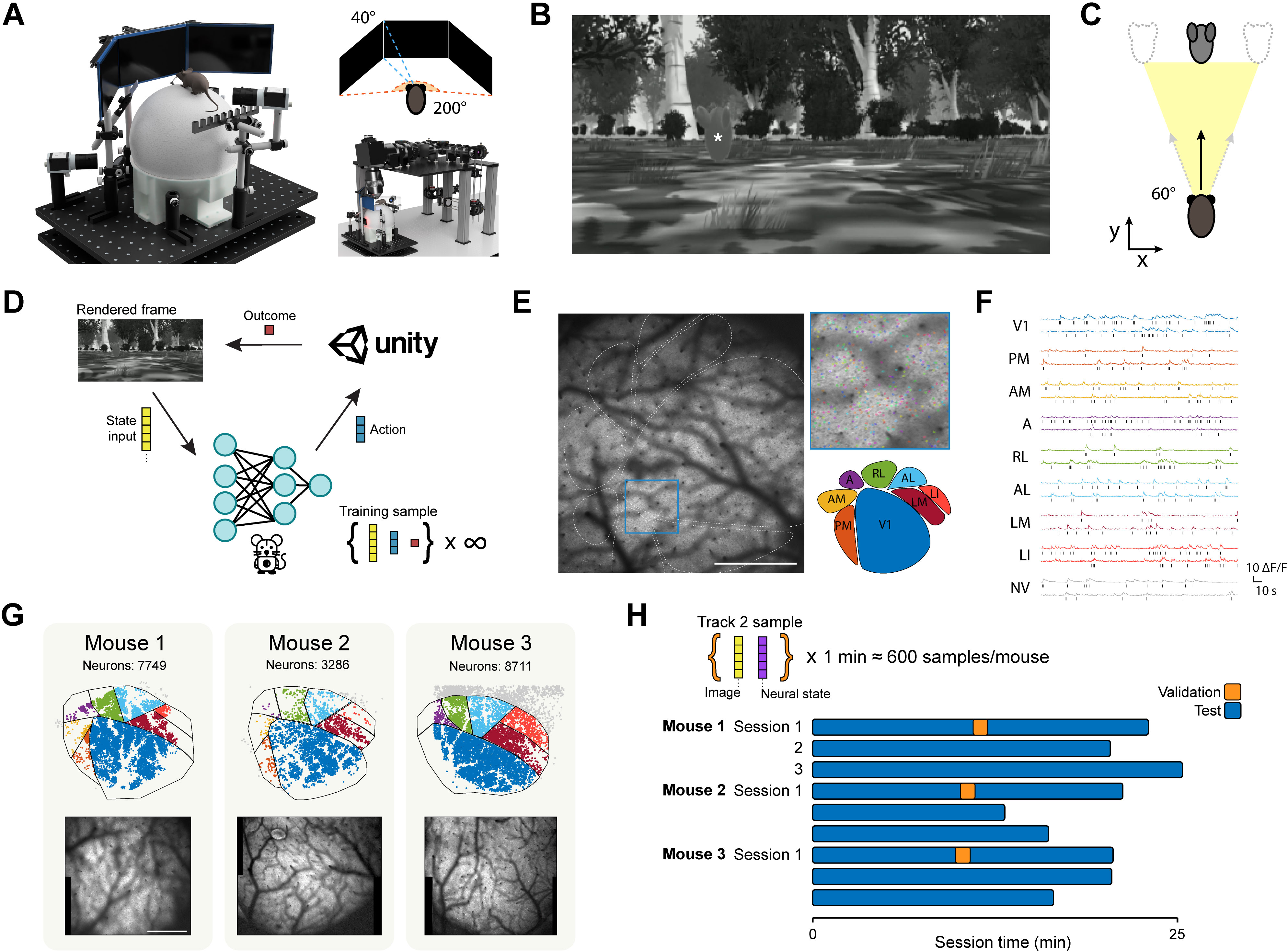
Figure 1: Overview of the mouse VR setup, Unity environment, trial structure, imaging field of view, and dataset composition.
Agents receive grayscale frames (86×155 pixels) and output continuous actions for translation and rotation. The reward structure is sparse: +20 for reaching the target, −1 otherwise. Mice are trained via water restriction and progress through a phased curriculum, ultimately achieving expert performance (>70% success rate) over hundreds of trials.
Competition Tracks and Evaluation Metrics
Track 1: Visual Robustness
Agents are trained under normal and fog-perturbed conditions, then evaluated on held-out visual perturbations (including three hidden types) to assess generalization under distributional shift. Performance is measured by:
- Average Success Rate (ASR): Mean success rate across all perturbation conditions.
- Minimum Success Rate (MSR): Lowest success rate across conditions, capturing worst-case robustness.
Leaderboard ranking uses a weighted combination: Score1=0.5⋅ASR+0.5⋅MSR.
Track 2: Neural Alignment
After training, agents' visual encoders are evaluated for alignment with mouse visual cortex activity. Mouse behavioral visual input is replayed through the agent's encoder (with frozen weights), and hidden activations are extracted. A linear regression is trained to predict recorded neural responses from these activations, with alignment quantified by the mean Pearson correlation across held-out neurons. The final score is the highest average correlation across all layers: Score2=l∈{1,…,L}maxρ(l).
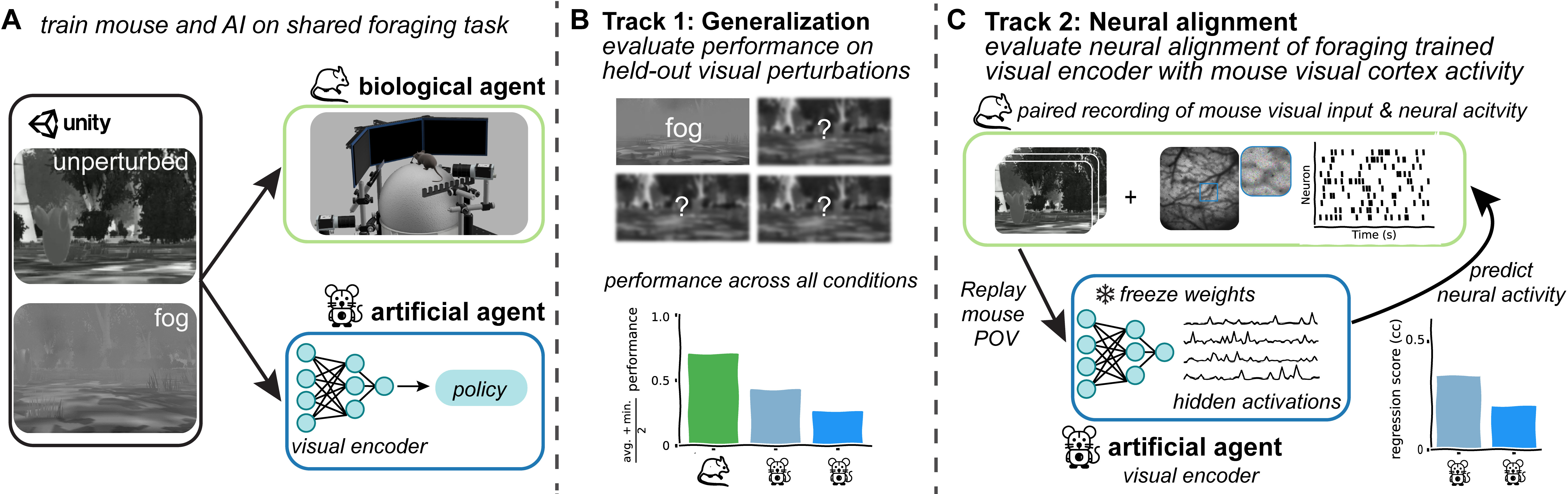
Figure 2: Schematic of the Mouse vs. AI competition, illustrating the shared foraging task, robustness evaluation, and neural alignment procedure.
Dataset and Experimental Pipeline
The benchmark provides:
- Unity builds for agent training and validation under normal and fog conditions.
- Behavioral baselines from expert mice, enabling direct performance comparison.
- Paired video-neural recordings from mice performing the task, with population activity from V1 and higher visual areas (HVAs) acquired via mesoscale two-photon imaging.
Imaging data are preprocessed using Suite2P for motion correction and segmentation, with spike inference performed via Bayesian MCMC. Neural and screen data are temporally aligned and binned in 100 ms windows, with spatial downsampling to match agent input resolution.
Baseline Agents and Starter Kit
A comprehensive starter kit is provided, including:
- Unity environment with Python API (ML-Agents framework).
- Baseline PPO agents with various encoder backbones (FC, CNN, ResNet-18, neuro-inspired CNN).
- Evaluation scripts for both tracks.
- Reproducibility toolkit (Conda environment, Jupyter notebooks).
Baseline agents are trained from scratch on normal and fog environments using identical hyperparameters. Performance metrics for these agents serve as reference points for participants.
Empirical Findings and Robustness Gap
Initial results demonstrate a pronounced robustness gap: mice maintain high success rates under challenging visual perturbations, while baseline RL agents exhibit significant performance degradation. This discrepancy persists despite the use of modern architectures and training regimes, highlighting the limitations of current artificial systems in generalizing under distributional shift. The biological baseline underscores the need for improved inductive biases and training strategies in RL agents.
Neural Alignment and Representational Analysis
The neural alignment track reveals that spontaneous emergence of brain-like representations in RL agents is nontrivial. While some architectures (e.g., neuro-inspired CNNs) achieve moderate alignment, the overall correlation with mouse neural activity remains limited. The benchmark's post hoc linear readout approach avoids overfitting and enables principled comparison of representational similarity, but strong alignment does not consistently co-occur with robust task performance. This finding challenges the assumption that behavior-driven learning alone suffices for neural predictivity and suggests that additional architectural or training constraints may be necessary.
Implications and Future Directions
The Mouse vs. AI benchmark advances the field by embedding robustness and neural alignment evaluation within a unified, behaviorally grounded framework. Its design enables systematic investigation of the computational principles underlying robust, biologically inspired vision. The ability to manipulate visual input with experimental precision supports causal analyses and hypothesis-driven testing of model inductive biases.
Potential future extensions include:
- Expanding visual perturbations to probe additional forms of sensory degradation.
- Increasing task complexity with multi-step objectives, distractors, or dynamic reward contingencies.
- Incorporating ecologically relevant behavioral motifs (e.g., predator-prey dynamics).
- Leveraging the Unity environment for reproducible, interpretable experiments.
The benchmark provides a rich multimodal dataset linking visual input, behavior, and large-scale neural activity, facilitating research at the intersection of neuroscience, RL, and computer vision.
Conclusion
The Mouse vs. AI: Robust Foraging competition establishes a rigorous, biologically grounded benchmark for evaluating visual robustness and neural alignment in artificial agents. By pairing a shared foraging task with multimodal mouse data, it enables direct comparison between artificial and biological systems under matched conditions. Empirical results highlight persistent gaps in robustness and neural alignment, motivating further research into architectural and training principles for biologically inspired AI. The benchmark's extensibility and experimental control position it as a valuable resource for advancing robust, generalizable, and brain-like vision models.