- The paper demonstrates that KA geometry, marked by zero rows in the Jacobian, naturally emerges in shallow MLPs when trained on nonlinear functions.
- It employs statistical measures such as participation ratios, random rotation ratios, and column divergences to rigorously quantify the KA structure.
- Results reveal that optimal training regimes trigger sharp emergence of KA geometry, offering promising directions for interventions in deep learning architectures.
Emergence of Kolmogorov-Arnold Geometry in Shallow MLPs
Introduction and Motivation
The paper investigates the spontaneous emergence of Kolmogorov-Arnold (KA) geometry in shallow multilayer perceptrons (MLPs), specifically single hidden layer networks trained via conventional optimization. The Kolmogorov-Arnold representation theorem guarantees that any continuous multivariate function can be represented by a single hidden layer network with sufficiently many neurons, but the required inner functions are highly non-smooth and their explicit construction is nontrivial. This work departs from engineered KA architectures (e.g., KANs) and instead empirically studies whether KA-like geometric structures arise naturally during training of standard MLPs.
The focus is on the local geometry of the first-layer map, characterized by the Jacobian J(x) as the input x varies. The central question is whether the distinctive KA geometry—marked by a majority of locally inactive coordinates and strong minor concentration in the Jacobian—emerges through gradient-based optimization, and under what conditions.
Theoretical Framework: KA Geometry
The KA theorem provides a universal representation for f:In→R as
f(x1,…,xn)=j=1∑mgj(i=1∑nϕij(xi))
with m≥2n+1. The inner function Φ:In→Rm is constructed so that, at every input, the Jacobian J(x) has at least m−n zero rows, i.e., most hidden coordinates are locally constant. This property is essential for the iterative construction of the outer functions gj and underpins the convergence of the KA scheme.
In conventional MLPs, the first-layer map is an affine transformation followed by a nonlinearity (GeLU in this study). The Jacobian is given by
Jji(x)=σj′AjiT
where σj′ is the derivative of the activation. Zero rows in J can arise either from vanishing σj′ or from sparse AT.
Empirical Methodology
The study uses 1-hidden layer MLPs with n=3 inputs and m∈{4,8,16,32} hidden neurons, trained on three function types: linear (easy), xor (nonlinear, "Goldilocks" regime), and random (unlearnable). Models are initialized identically across function types and trained with Adam and MSE loss. The critical batch size is used to avoid confounding effects from batch size variation.
KA geometry is quantified via statistical analysis of the Jacobian and its exterior powers (minors), focusing on:
- Zero Rows: Fraction of rows in the k-th minor matrix below a data-driven threshold.
- Participation Ratio: L1/L2 norm ratio of minor matrices, indicating concentration.
- Random Rotation Ratio: Ratio of maximal minor to its value under random orthogonal rotations, probing alignment.
- Column Divergence: KL divergence between trained and initial minor matrix columns, measuring distributional shift and alignment.
Results: Spontaneous KA Geometry
Zero Rows and Minor Concentration
Training on the xor function induces a statistically significant fraction of zero rows in the Jacobian and its higher minors, far exceeding the false-positive rate set by initialization. This is not observed for linear or random functions. The effect intensifies with increasing hidden dimension m and minor size k.
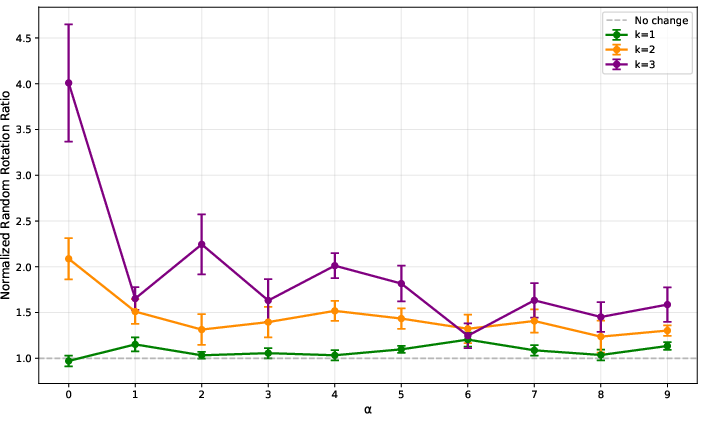
Figure 1: Participation ratios for size-k minors across hidden dimensions, showing pronounced concentration for xor models compared to linear and random baselines.
Participation ratios decrease markedly for xor models in higher minors, indicating that a few large minors dominate while most are near zero—consistent with KA geometry. Random rotation ratios exceed unity for xor models, confirming that large minors arise from structured alignment rather than chance. Column divergences also increase with k and m for xor, reflecting emergent alignment in the trained inner map.
Dynamics and Interpolation
KA geometry emerges sharply as training progresses and correlates with model performance (R2). Interpolation experiments with the λ-xor family reveal a "Goldilocks regime" (0.7≲λ≲1.2) where KA metrics peak, coinciding with optimal learnability. For functions outside this regime (too simple or too complex), KA geometry does not develop.
Batch Size and Latent KA Geometry
Batch size modulates the emergence of KA geometry. At small batch sizes, consistently zero rows (dead neurons) appear, but these are not example-dependent and do not reflect true KA patterning. At full batch, even random functions can induce KA-like geometry in the inner map, but the linear outer map lacks capacity to exploit it. Bootstrapping with a second hidden layer enables memorization, confirming that KA geometry can arise latently even when not directly utilized.
Implications and Future Directions
The findings demonstrate that KA geometry—characterized by local inactivity and minor concentration in the Jacobian—can emerge spontaneously in shallow MLPs trained on sufficiently complex functions. This suggests that gradient-based optimization can discover highly expressive, KA-like representations without explicit architectural engineering.
Practically, the results motivate interventions to accelerate learning by promoting KA geometry, e.g., via oscillatory activation functions or targeted regularization. However, computational cost remains a concern for large models, where exhaustive analysis of Jacobians and minors is infeasible. Mapping the "KA phase diagram"—identifying when and where KA geometry emerges in deep architectures—will be essential for scalable application.
Theoretically, the work bridges classical approximation theory and modern deep learning, highlighting the relevance of fine-scale geometric patterning in neural representations. The observed coupling between large-scale learning and fine-scale KA patterning suggests new avenues for understanding abstraction and generalization in neural networks.
Conclusion
This study provides compelling evidence that KA geometry, as predicted by the Kolmogorov-Arnold theorem, can arise organically in shallow MLPs trained on nonlinear functions. The emergence of zero rows and minor concentration in the Jacobian is tightly linked to function complexity and model capacity, and is absent for trivial or unlearnable tasks. These results open the door to principled interventions for accelerating learning and abstraction in neural networks, and call for further exploration of KA geometry in large-scale and deep architectures.