- The paper introduces a modular RL library tailored for robotics research that enables rapid prototyping and targeted algorithm experimentation.
- The paper details core algorithms like PPO and DAgger-style BC, augmented with techniques such as symmetry augmentation and curiosity-driven exploration.
- The framework supports high-throughput distributed training and sim-to-real deployment, validated in both simulation and real-world robotic experiments.
RSL-RL: A Specialized Reinforcement Learning Library for Robotics
Motivation and Design Philosophy
RSL-RL is an open-source reinforcement learning (RL) library engineered to address the unique requirements of robotics research. Unlike general-purpose RL frameworks, RSL-RL adopts a minimalist, modular architecture that prioritizes codebase compactness and extensibility. The framework is explicitly tailored for rapid prototyping and adaptation, enabling researchers to efficiently implement and modify algorithms for robotics-specific tasks. Its design is centered on three independently modifiable components: Runners, Algorithms, and Networks, facilitating targeted experimentation and extension.
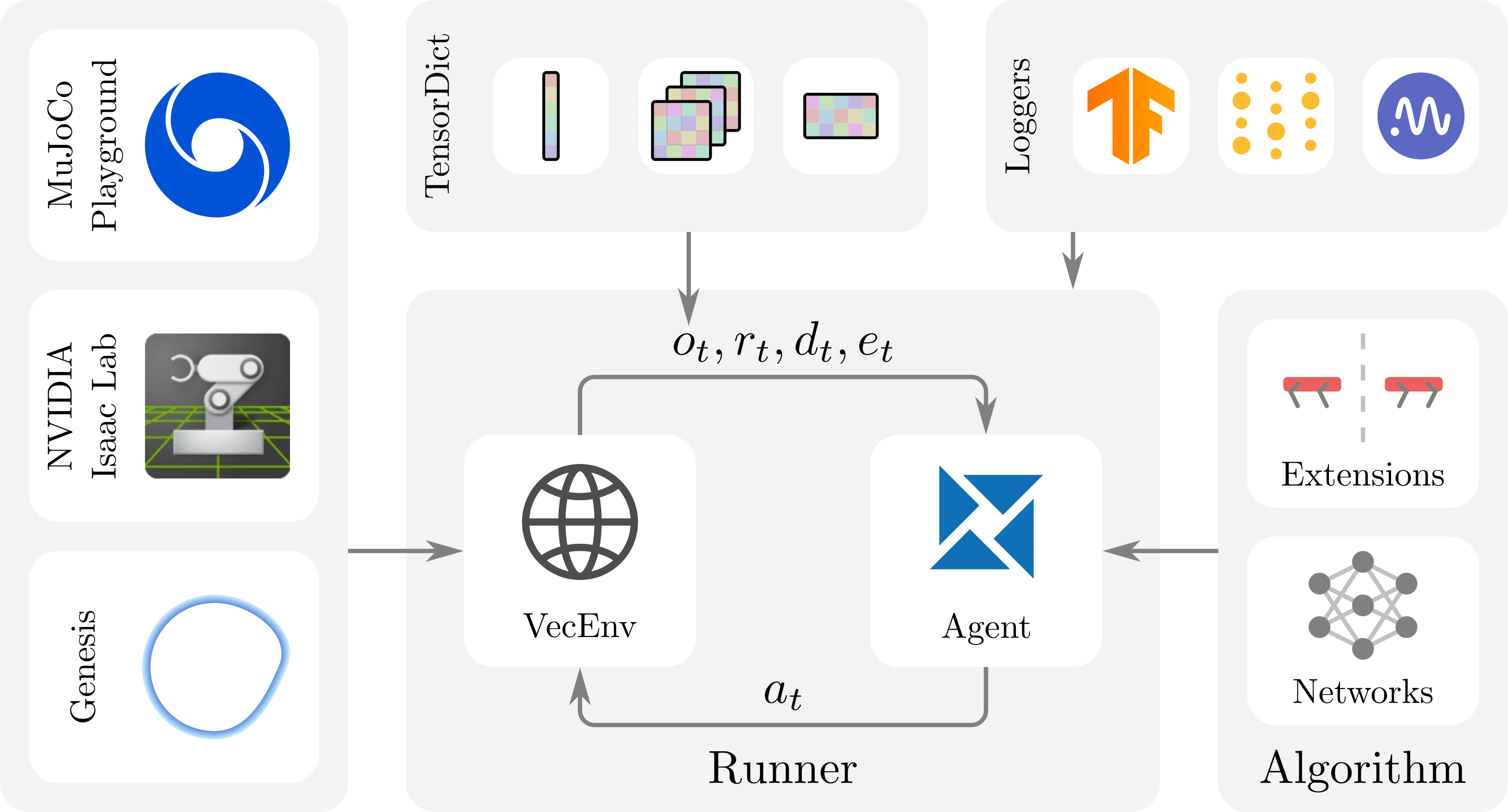
Figure 1: Overview of the RSL-RL framework, highlighting the modular separation of Runners, Algorithms, and Networks, with integrated support for logging and robotics-specific extensions.
Core Algorithms and Auxiliary Techniques
RSL-RL currently implements two principal algorithms: Proximal Policy Optimization (PPO) and a DAgger-style Behavior Cloning (BC) method. PPO is widely adopted in robotics for its robustness in continuous control domains, including locomotion, manipulation, and navigation. The BC algorithm enables policy distillation, allowing the transfer of behaviors from expert policies—often trained in simulation with privileged information—to student policies suitable for real-world deployment.
The framework incorporates auxiliary techniques to address robotics-specific challenges:
- Symmetry Augmentation: This method leverages physical symmetries of robotic systems to augment training data, accelerating sample generation and promoting symmetric behaviors. The augmentation is reinforced via an additional symmetry loss, improving policy generalization and stability.
- Curiosity-Driven Exploration: RSL-RL implements a modified Random Network Distillation (RND) approach, focusing intrinsic rewards on selected state subspaces. This targeted curiosity mechanism enhances exploration in sparse reward environments, reducing reliance on hand-crafted dense rewards and enabling efficient learning in complex tasks.
Implementation Details and Extensibility
RSL-RL is implemented in Python and PyTorch, with a custom VecEnv interface requiring environments to support same-step reset and return batched PyTorch tensors structured as TensorDicts. This design enables flexible routing of observation components and seamless integration of auxiliary techniques such as RND and latent reconstruction.
The PPO implementation incorporates best practices for large-batch training, including random early episode termination to mitigate correlated rollouts and explicit management of recurrent network hidden states for correct Backpropagation Through Time (BPTT). The framework supports distributed training across multiple GPUs and nodes, facilitating high-throughput experimentation in large-scale simulation environments.
Logging, Evaluation, and Integration
RSL-RL provides native support for TensorBoard, Weights & Biases, and Neptune, enabling both local and cloud-based experiment tracking. The framework is integrated with major GPU-accelerated robotic simulation platforms, including NVIDIA Isaac Lab, MuJoCo Playground, and Genesis, allowing out-of-the-box deployment for a wide range of robotic systems.
Empirical Validation and Research Applications
RSL-RL has been validated in both simulation and real-world robotic experiments. Initial demonstrations achieved rapid training of legged locomotion policies in minutes using massively parallel simulation. Subsequent research has leveraged the framework for sim-to-real transfer, whole-body control, mixed action distributions, teacher-student distillation, attention-based architectures, adversarial and DeepMimic style training, and constraint-aware RL via P3O and CaT. The symmetry augmentation methods have been applied to multi-agent coordination and low-level control, evidencing the framework's versatility in advanced robotics research.
Limitations and Appropriate Use Cases
RSL-RL is optimized for robotics research, particularly for developing and deploying RL-based controllers in real-world systems. Its compact codebase and focused algorithm set make it ideal for researchers seeking rapid prototyping and extensibility. However, the library is not suited for general-purpose RL benchmarking or pure imitation learning, as it intentionally restricts algorithmic breadth to maintain simplicity and relevance for robotics.
Implications and Future Directions
The deliberate specialization of RSL-RL for robotics research has practical implications for accelerating the development and deployment of learning-based controllers. Its modularity and extensibility lower the barrier for implementing novel algorithms and integrating domain-specific techniques. The framework's emphasis on sim-to-real transfer and support for distributed, high-throughput training positions it as a valuable tool for advancing real-world robotic autonomy.
Future developments may include the addition of further RL algorithms, expanded auxiliary techniques, and enhanced support for emerging simulation platforms. The continued evolution of RSL-RL will likely track advances in RL for robotics, such as hierarchical control, multi-agent coordination, and improved sim-to-real adaptation strategies.
Conclusion
RSL-RL provides a compact, extensible, and robotics-focused RL library that addresses the practical needs of robotics researchers. Its modular architecture, curated algorithm set, and integration with leading simulation platforms facilitate efficient development and deployment of learning-based controllers. While not intended for general-purpose RL research, RSL-RL is well-positioned to support ongoing advances in robotics, particularly in domains requiring rapid prototyping, sim-to-real transfer, and specialized learning techniques.