- The paper demonstrates that progressive freezing mitigates representation collapse while reducing computational overhead and memory usage.
- The methodology employs dynamic target evolution, initially predicting pixels and later shifting to deeper latent representations.
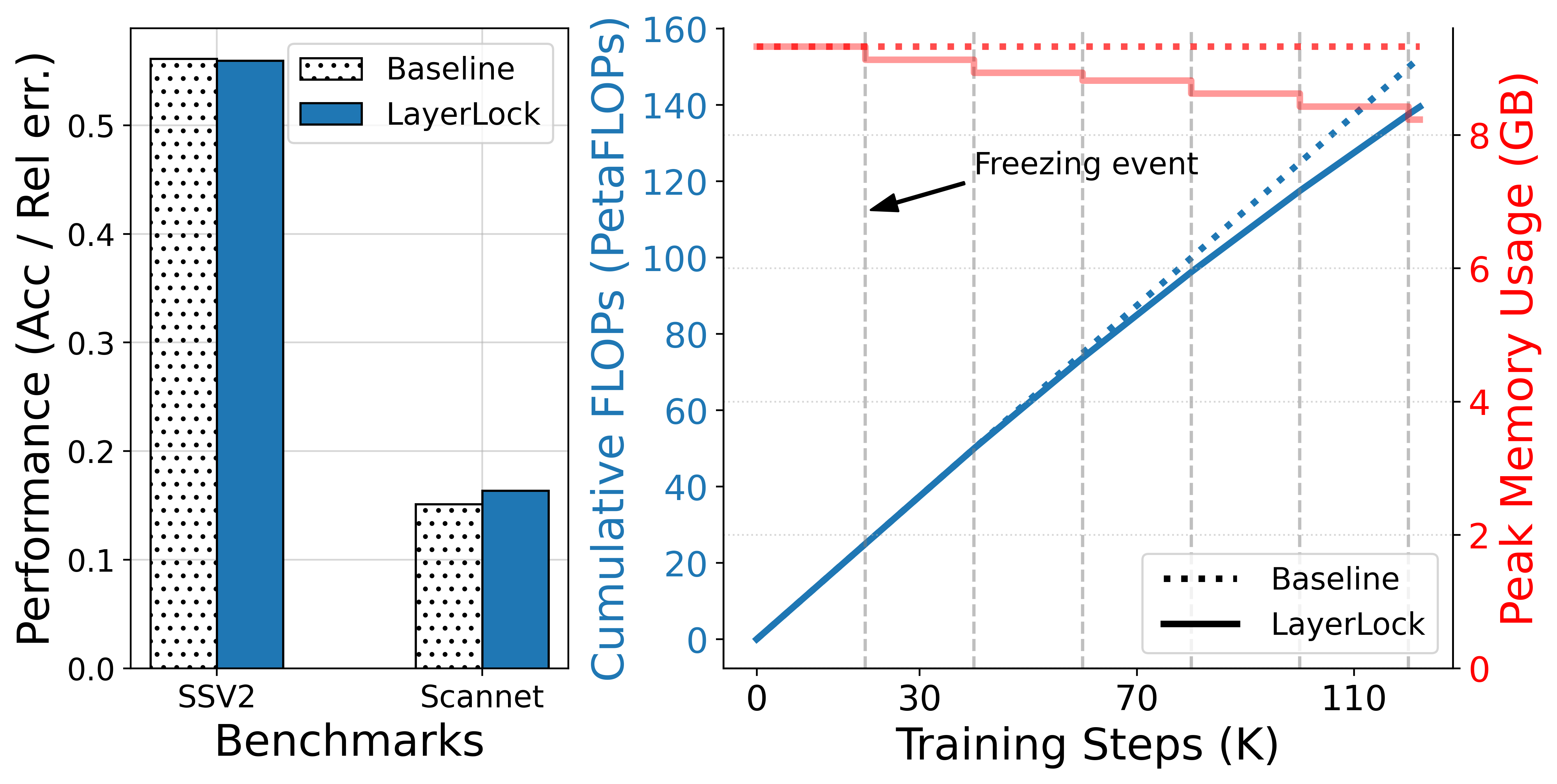
- Empirical results reveal up to a 19% FLOPs reduction and a 2–3% accuracy boost in action recognition benchmarks without sacrificing performance.
LayerLock: Non-collapsing Representation Learning with Progressive Freezing
Introduction and Motivation
LayerLock introduces a progressive freezing paradigm for self-supervised visual representation learning, specifically targeting video masked auto-encoding (MAE) models with Vision Transformer (ViT) backbones. The central observation motivating LayerLock is that ViT layers converge in order of their depth during training: shallow layers stabilize early, while deeper layers require more iterations. This ordered convergence enables a training strategy where layers are progressively frozen as they converge, reducing computational overhead and memory usage without sacrificing performance.
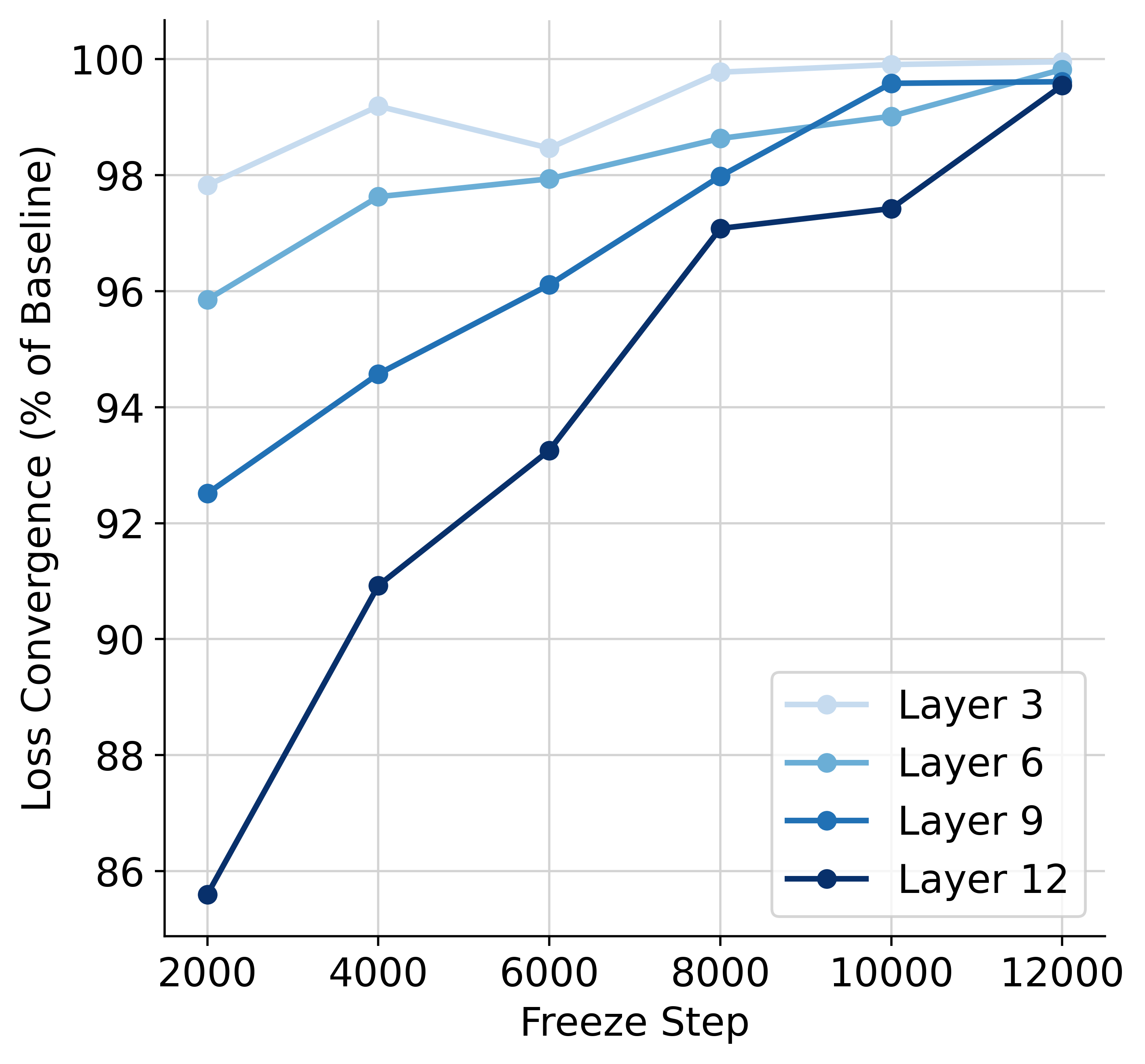
Figure 1: In video masked auto-encoding, network layers converge during training in order of their depth, as measured by final loss after freezing up to layer L at step T.
LayerLock further extends this idea by dynamically evolving the prediction target throughout training. Initially, the model predicts low-level features (pixels or early layer activations), and as layers are frozen, the prediction target transitions to deeper latent representations. This approach combines the stability of pixel prediction with the semantic richness of latent prediction, while avoiding representation collapse—a common failure mode in latent-based self-supervised learning.
Methodology
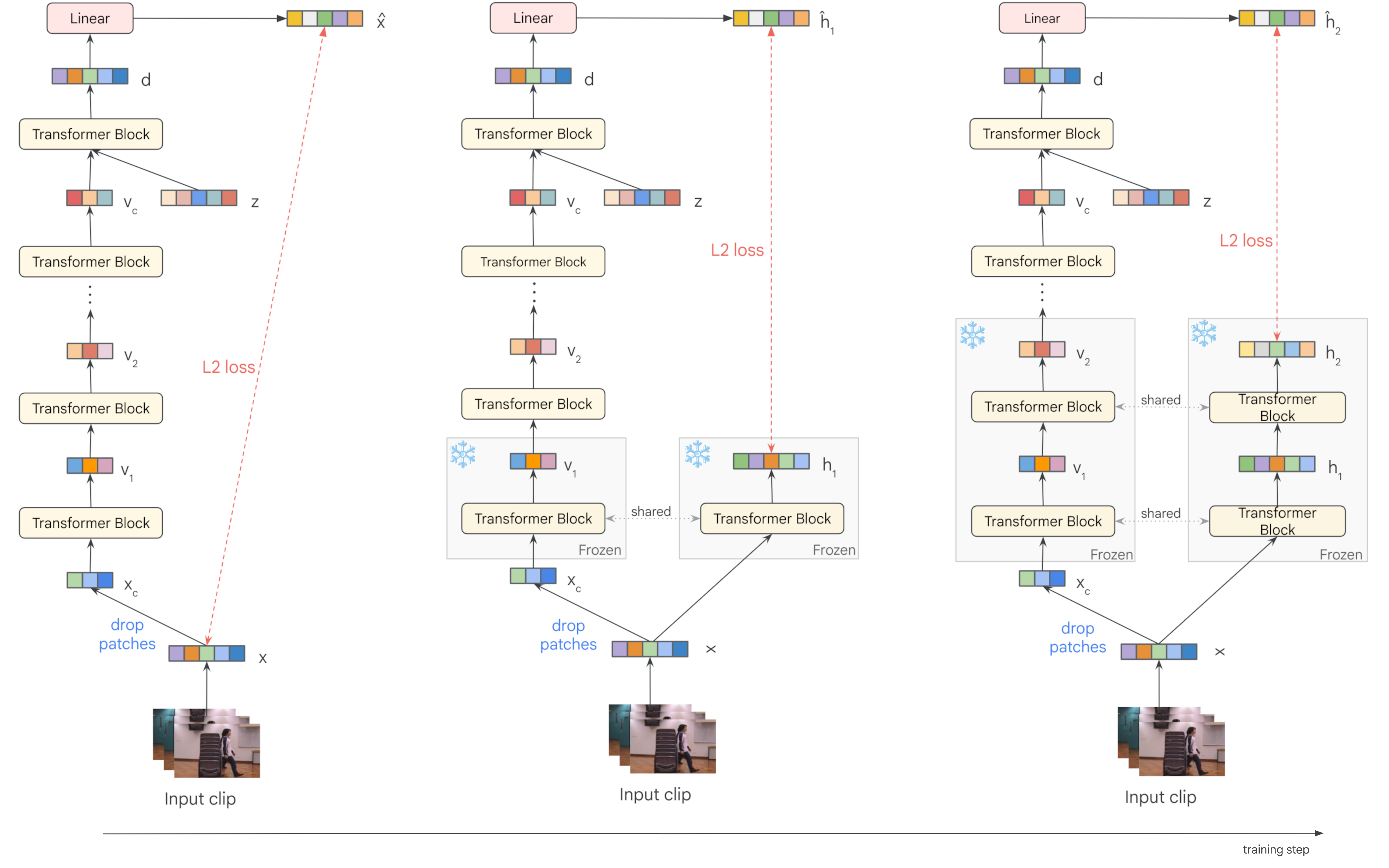
LayerLock is implemented within the standard MAE framework, where a masked video clip is encoded and the model reconstructs the masked regions. The key innovation is the progressive freezing schedule and dynamic target selection:
The architecture leverages a ViT backbone, patchifying input videos and applying novel 3D rotary positional embeddings (RoPE) to encode spatiotemporal position. Decoding latents are concatenated before the final Transformer blocks, and a patch-wise linear decoder projects tokens to the target space (pixels or latent activations).
A simple L2 loss is used between the predicted and target representations. For efficiency, latent loss can be computed on a subset of patches, with ablations showing that even 5% patch selection maintains strong performance.
LayerLock achieves substantial efficiency gains over vanilla MAE by reducing the number of layers involved in the backward pass as training progresses. Empirical results demonstrate:
Empirical Results
LayerLock was evaluated on large-scale video datasets (174M web videos, 1B training examples) and compared against strong pixel (4DS MAE) and latent (V-JEPA) prediction baselines. Key findings include:
- Action Recognition (SSv2, Kinetics700): LayerLock models consistently outperform baselines, with improvements of 2–3% in Top-1 accuracy.
- Depth Estimation (ScanNet): LayerLock maintains or slightly improves relative error compared to baselines.
- Generalization: LayerLock is effective for both pixel and latent prediction paradigms, demonstrating its versatility.
Ablation studies confirm the necessity of progressive freezing to avoid representation collapse when introducing latent losses. The use of 3D RoPE embeddings further boosts performance, and single-target prediction (latest frozen layer) is sufficient, simplifying implementation.
Implementation Considerations
- Freezing Schedule: Optimal schedules involve gradual freezing (e.g., freeze one layer every 10K steps after an initial pixel prediction phase), with earlier layers frozen first.
- Latent Loss Patch Selection: Computing latent loss on a subset of patches (e.g., 5%) offers a trade-off between efficiency and performance, with minimal degradation for semantic tasks.
- Positional Embeddings: 3D RoPE applied after the first normalization layer in ViT blocks yields superior results compared to standard attention-based RoPE.
- Warmup Strategy: Mini learning rate warmups when switching targets improve stability and final accuracy.
- Scaling: LayerLock is demonstrated on models up to 4B parameters and is compatible with large-scale distributed training (256 TPUs).
Theoretical and Practical Implications
LayerLock provides a principled approach to non-collapsing representation learning by leveraging the natural convergence order of deep networks. The method bridges pixel and latent prediction, enabling stable training of large models without the need for architectural asymmetry or auxiliary target encoders. The efficiency gains in compute and memory are particularly relevant for scaling to longer video sequences, higher resolutions, and deeper architectures.
The progressive freezing paradigm may have broader applicability in other domains where layerwise convergence is observed, such as NLP or multimodal transformers. The dynamic target evolution strategy could inform future work on curriculum learning and adaptive self-supervision.
Conclusion
LayerLock introduces a progressive freezing and dynamic target prediction strategy for self-supervised video representation learning, yielding efficient, stable, and high-performing models. The approach is validated across multiple tasks and model scales, with extensive ablations confirming its robustness and generality. Future research may explore more granular freezing schedules, application to other modalities, and integration with advanced readout architectures for further gains in representation quality and efficiency.