- The paper demonstrates a method to adjust expert activations that steers LLM behavior, achieving up to a +27 improvement in faithfulness.
- The approach uses paired-example routing-difference detection to compute risk scores, enabling activation/deactivation of experts without retraining.
- The results reveal enhanced interpretability and safety, while also exposing alignment vulnerabilities that could be exploited adversarially.
Steering MoE LLMs via Expert (De)Activation
Introduction
The paper "Steering MoE LLMs via Expert (De)Activation" presents a method for controlling the behavior of Mixture-of-Experts (MoE) models in LLMs by adjusting the activation of specific experts during inference. This approach allows users to modify behaviors like faithfulness and safety without retraining the models or changing their weights. The research focuses on leveraging the routing pathways in MoE models to achieve behavioral steering through lightweight modifications.
Methodology
Expert Activation Patterns
MoE models, characterized by sparing routing of tokens through a subset of specialized feed-forward networks (FFNs) or experts, are efficient in handling vast parameter counts without significant increases in computational costs. The proposed method detects experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors, such as safe versus unsafe, and adjusts these patterns to influence the model's outputs.
Paired-Example Routing-Difference Detection
The framework detects behavior-linked experts by analyzing the difference in expert activation frequencies between paired examples reflecting contrasting behaviors. It computes a risk difference score for each expert, quantifying its association with the behavior of interest. This score guides which experts to promote or suppress during inference.
Steering Mechanism
At inference, expert scores are adjusted based on their risk difference scores. Experts promoting the desired behavior are activated, while those inducing undesired behavior are deactivated through adjustments to the router logits. This mechanism allows the model behavior to be steered effectively while maintaining the original model weights intact.
Experimental Results
Faithfulness
Using benchmarks such as RAG and various datasets including SQuAD, the research demonstrates that steering models by activating experts linked with document-grounded facts improves faithfulness and alignment with retrieved data. This approach yielded up to a +27 improvement in faithfulness accuracy across several evaluation datasets.

Figure 1: Comparison of the off-the-shelf and steered models on faithfulness benchmarks.
Safety
For safety benchmarks including the TDC2023 Red Teaming Track, the methodology adjusts expert activation to manipulate the model's compliance with unsafe prompts. Results indicated improvements in model safety, with activation leading to a +20 improvement in safe response rates and deactivation exposing vulnerabilities for adversarial manipulation.
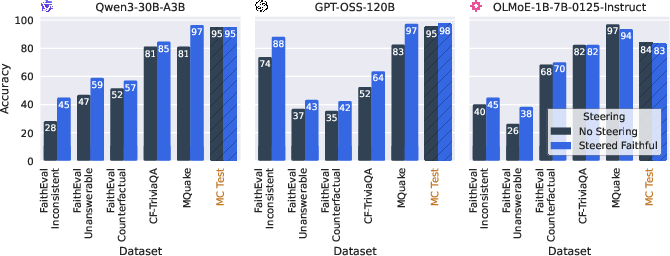
Figure 2: Comparison of off-the-shelf and steered models on safety benchmarks.
Interpretability and Implications
The study highlights the interpretability of expert activations as behaviors often cluster within middle layers of the model. This clustering suggests that experts encoded more than just domain-specific abilities, highlighting both opportunities for modular behavioral aligning and potential risks if adversaries exploit these pathways.
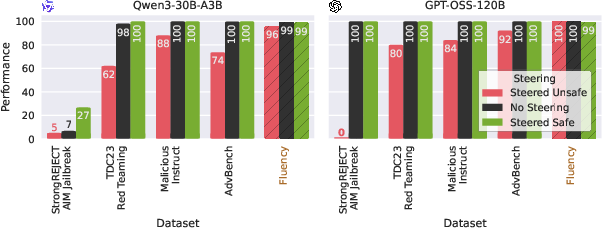
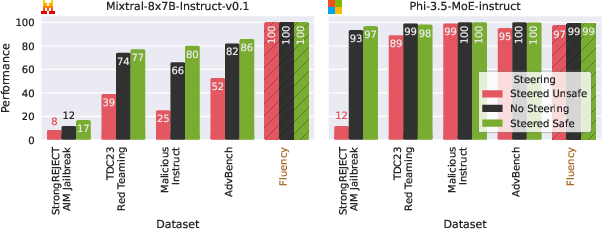
Figure 3: Number of important experts (top 20\%) in each layer of models.
Conclusion
The proposed framework allows for the test-time control of MoE models by leveraging expert activations as a modular and interpretable signal for behavioral alignment. This method not only presents opportunities for improving model outputs without retraining but also exposes alignment vulnerabilities that must be addressed to prevent adversarial exploits. Exploring dynamic expert manipulation and expanding to other behavioral dimensions represent future directions to enhance model safety and reliability comprehensively.