- The paper introduces FPI-Det, a large-scale dataset capturing synchronized face and phone annotations to address nuanced human–device interactions.
- It employs detailed bounding box and geometry annotations across workplace, education, transportation, and public spaces to support joint detection and behavior classification.
- Results indicate YOLO variants achieve high accuracy and speed, suggesting strong potential for real-world safety and productivity applications.
FPI-Det: A Benchmark for Fine-Grained Face–Phone Interaction Detection
Motivation and Context
The proliferation of mobile devices has introduced complex challenges for computer vision systems tasked with behavior-aware perception, particularly in safety-critical and productivity-sensitive environments. Detecting phone usage is not a trivial object detection problem; it requires nuanced understanding of human–device interactions, including spatial and contextual relationships between faces, hands, and phones under diverse and often adverse conditions. Existing datasets and benchmarks—such as COCO, PASCAL VOC, WIDER FACE, and HICO-DET—fail to capture the fine-grained, synchronized annotations necessary for robust phone-use detection and understanding. The FPI-Det dataset directly addresses this gap by providing a large-scale, richly annotated resource for the joint detection of faces, phones, and their interaction status across multiple real-world scenarios.

Figure 1: The FPI-Det dataset captures diverse, real-world scenarios for face–phone interaction, including workplace, education, transportation, and public spaces.
Dataset Construction and Annotation Protocol
FPI-Det comprises 22,879 images with synchronized bounding box annotations for faces and phones, collected from surveillance cameras, mobile devices, and online video sources. The dataset spans four primary domains: workplace, education, transportation, and public spaces, reflecting environments where phone usage has significant safety and productivity implications. Annotation was performed in multiple stages, with careful attention to occlusion, scale variation, and ambiguous interaction cues. Each image was reviewed by at least three annotators to ensure high-quality, consensus-based labeling.
The dataset exhibits substantial scale variation (phones as small as 20×20 pixels, faces up to 800×800 pixels), frequent mutual occlusion (e.g., hands covering phones or faces), and diverse capture conditions (low-light, motion blur, compression artifacts). Annotations include not only bounding boxes but also per-instance geometry (pixel coordinates, pairwise distances) and coarse behavior categories (Calling, Using, Seated Using, Sidewise Using). This enables both metric-learning approaches and rule-based inference for interaction understanding.
Benchmark Tasks and Evaluation Protocols
FPI-Det supports two primary tasks:
- Joint Object Detection: Simultaneous localization of faces and phones, with evaluation via mAP at IoU thresholds of 0.5 and 0.95, stratified by object size and occlusion level.
- Phone-Use Behavior Classification: Binary classification of phone usage status, based on co-detection of faces and phones within the same frame, evaluated using Accuracy, Precision, Recall, F1-score, and Specificity.
The dataset is split into training (18,800 images), validation (1,730), and test (2,349) sets, with a balanced distribution of face-only, phone-only, double (both present), and null (neither present) images. A CSV-formatted annotation file provides fine-grained behavior labels for robust evaluation.
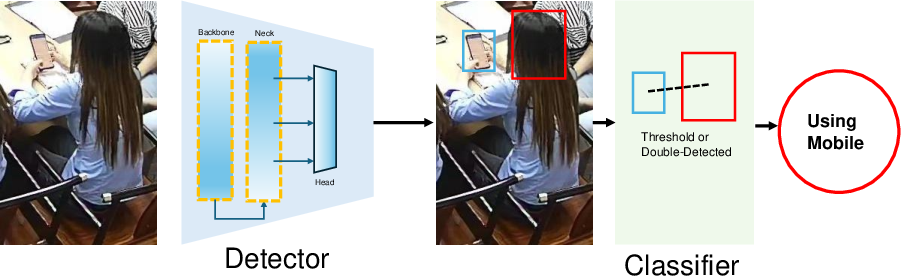
Figure 3: The FPI-Det pipeline supports both joint detection and phone-use behavior classification tasks, leveraging synchronized annotations and geometric cues.
Experimental Evaluation
Model Selection and Training
The benchmark evaluates both one-stage (YOLOv8, YOLOv11) and transformer-based (DETR, Deformable DETR) detection architectures. All models were trained under identical hyperparameter settings (batch size 16, 200–300 epochs) and data augmentation protocols, using a 4× NVIDIA Tesla V100 setup with PyTorch 2.1 and CUDA 12.0.
YOLO variants consistently outperform transformer-based models in both detection accuracy and inference speed. For face detection, YOLOv8-x achieves the highest AP@50 (56.5%) and AP@95 (35.8%), while for phone detection, YOLOv8-x reaches 92.4% AP@50. Deformable DETR outperforms vanilla DETR, particularly at higher IoU thresholds, indicating improved localization precision. However, all models exhibit a significant performance gap between face and phone detection, attributable to the increased difficulty of face detection in crowded, occluded, and diverse pose scenarios.
Throughput
YOLOv8-n achieves the highest throughput (416.7 FPS), making it suitable for real-time applications, while larger YOLO and transformer models trade speed for marginal gains in detection accuracy.
Phone-Use Behavior Classification
A parameter-free binary classifier infers phone-use status based on the co-detection of faces and phones. YOLOv11-x achieves the best overall performance (accuracy 89.5%, F1 87.5%, specificity 89.8%), with YOLOv8-x and DETR variants closely following. The classifier's performance is primarily governed by detector recall; finer localization has limited impact on binary usage classification, as long as both objects are detected.
Error Analysis
Workplace environments yield the highest accuracy, while transportation scenes are most challenging due to occlusion and small object size. Failure cases include false positives on tablet-like objects and false negatives on heavily occluded or diminutive targets.
Implications and Future Directions
FPI-Det establishes a new standard for fine-grained, context-aware phone-use detection, enabling the development and evaluation of models that move beyond binary classification to nuanced interaction understanding. The dataset's scale, diversity, and annotation richness support research in multi-object detection, relational reasoning, and behavior inference under real-world constraints.
Key implications include:
- Deployment Readiness: YOLOv8/YOLOv11 models offer a favorable trade-off between accuracy and speed for edge deployment in safety-critical applications (e.g., driver monitoring, workplace surveillance).
- Research Opportunities: The dataset enables exploration of metric-learning, graph-based relational modeling, and multi-modal fusion for improved interaction understanding.
- Limitations: The current benchmark does not explicitly link detected phones to specific faces in multi-person scenes, nor does it address ambiguous cases such as passive holding versus active use.
Future work should focus on:
- Instance-level attribution of phones to faces to reduce false positives in crowded scenes.
- Incorporation of richer interaction cues (e.g., hand pose, gaze direction) for disambiguating borderline cases.
- Field deployment and evaluation on industrial and traffic surveillance systems.
Conclusion
FPI-Det provides a comprehensive, large-scale benchmark for the detection and understanding of face–phone interactions, addressing a critical gap in existing vision datasets. The dataset's challenging scenarios, synchronized annotations, and robust evaluation protocols facilitate the development of advanced models for behavior-aware perception. The strong baseline results and detailed error analysis highlight both the progress and remaining challenges in this domain, setting the stage for future research in fine-grained human–device interaction understanding.

