- The paper proposes a query refinement method that enhances target sound extraction by removing inactive query classes.
- It utilizes a multi-task architecture combining convolutional layers and a BiGRU classifier to jointly perform extraction and sound class estimation.
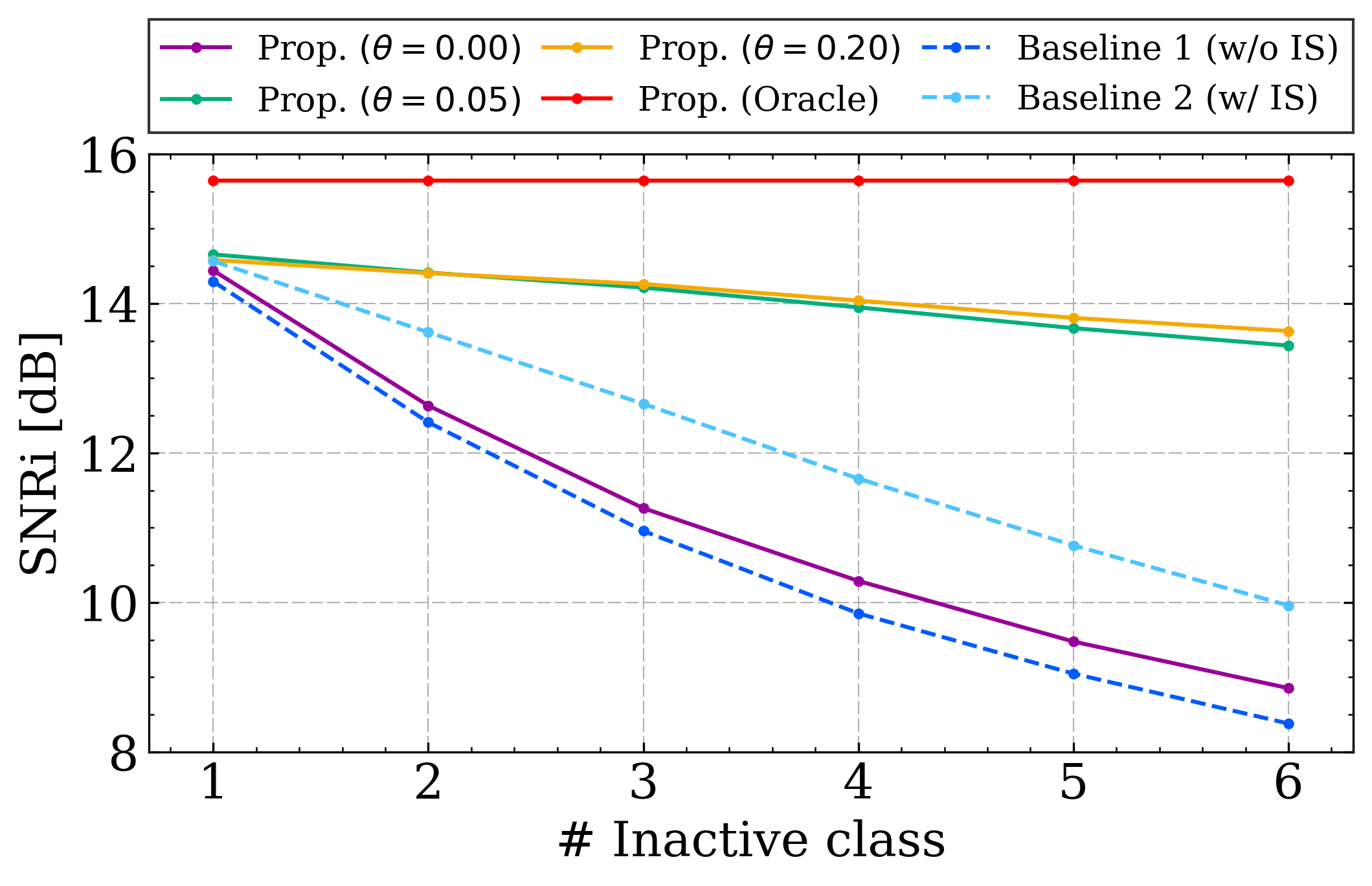
- Experimental results demonstrate maintained SNR improvement under partially matched queries with minimal computational overhead.
Introduction
The paper addresses a critical gap in Target Sound Extraction (TSE) research: the handling of Partially Matched Query (PMQ) conditions, where user-specified queries may include both active and inactive sound classes. While previous work has focused on Fully Matched Query (FMQ) and Fully Unmatched Query (FUQ) scenarios, the PMQ condition reflects realistic user behavior in applications such as hearables and environmental monitoring, where users may not perfectly identify all active sources. The authors propose a context-aware query refinement method that estimates sound class activity in the mixture and refines the query by removing inactive classes, thereby mitigating performance degradation under PMQ conditions.
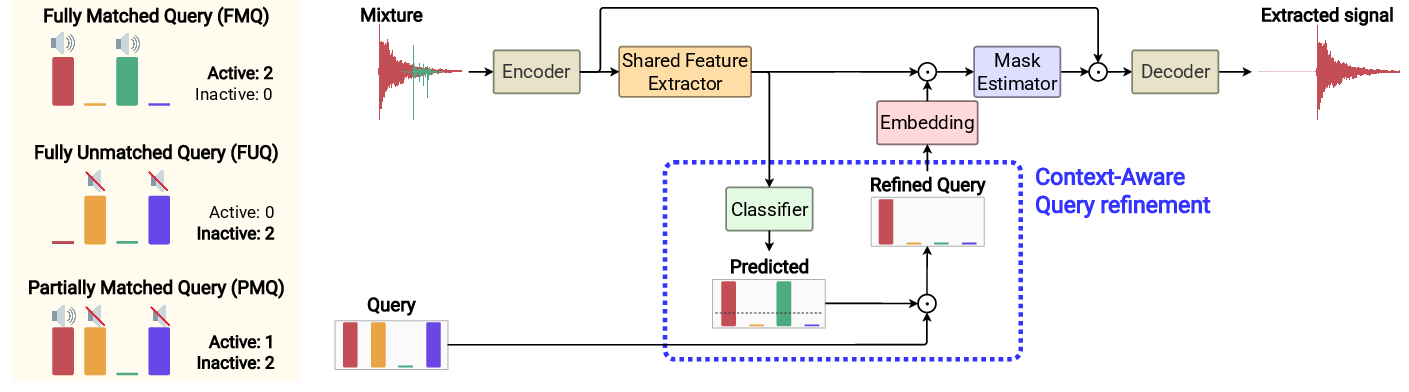
Figure 1: Overall architecture of the proposed query refinement method, illustrating the joint TSE and sound class estimation pipeline and example queries for FMQ, PMQ, and FUQ conditions.
TSE systems typically operate under the assumption that queries specify only active sources (FMQ). However, in practice, queries may include inactive sources, leading to PMQ and FUQ conditions. Existing approaches for FUQ, such as training with inactive samples (IS), can suppress non-target extraction but degrade FMQ performance. Methods that replace output with silence based on target detection are limited to single-class extraction and cannot address PMQ scenarios, where selective extraction of active classes is required.
The PMQ condition introduces a unique challenge: erroneous extraction of non-target sounds when inactive classes are present in the query. The paper is the first to systematically analyze the severity of this issue and propose a solution that generalizes across FMQ, PMQ, and FUQ conditions.
Proposed Method: Context-Aware Query Refinement
The core of the proposed method is a multi-task architecture that jointly performs TSE and sound class estimation. The system comprises:
- Encoder: 1-D convolutional layers transform the input mixture into feature representations.
- Shared Feature Extractor: Stacks of 1-D convolutional blocks (Conv-TasNet style) extract features for both TSE and classification.
- Mask Estimator: Conditions shared features on the query embedding to estimate extraction masks.
- Decoder: Applies the mask to reconstruct the target sound in the time domain.
- Classifier: BiGRU-based module estimates the existence probability of each sound class in the mixture.
During inference, the classifier's output is used to refine the query: classes with estimated probability below a threshold θ are removed. This process is implemented via element-wise multiplication of the binarized classifier output and the original query vector.
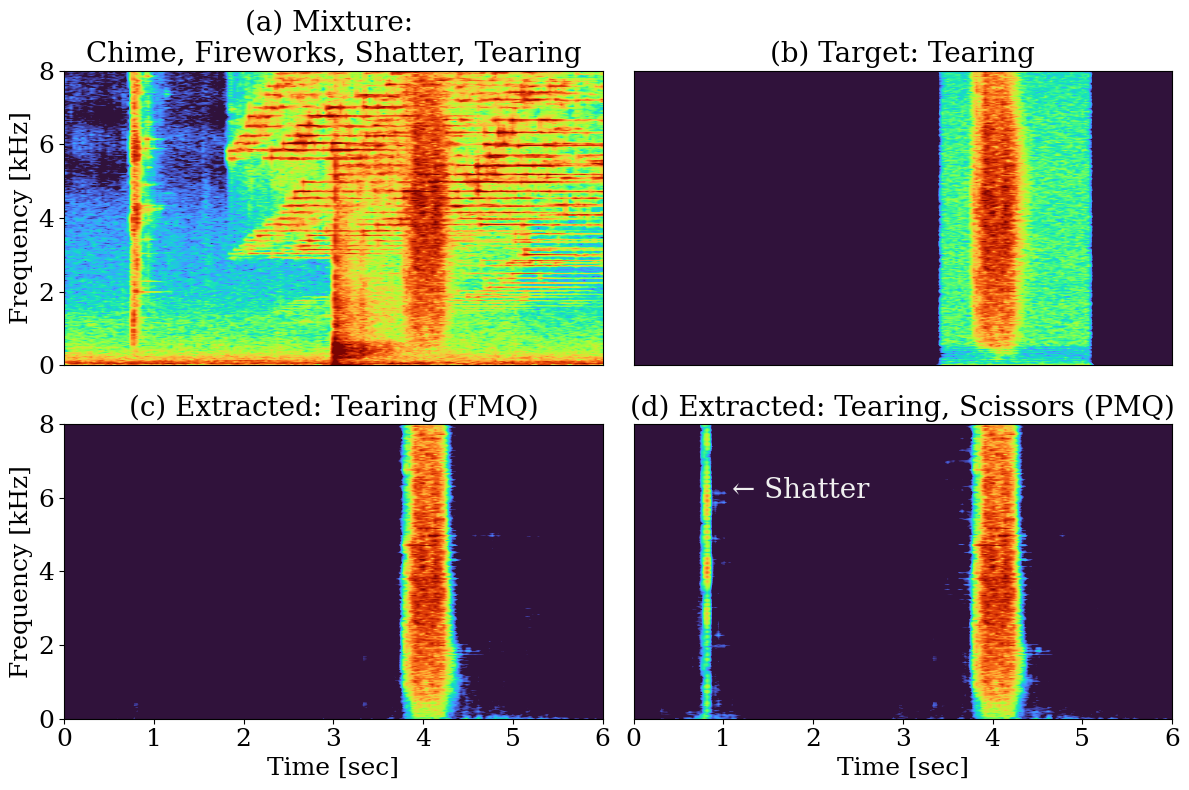
Figure 2: Example of performance degradation under the PMQ condition using baseline 1, showing erroneous extraction when an inactive class is included in the query.
The training regime uses only FMQ conditions, optimizing a weighted sum of TSE loss (negative thresholded SNR) and classification loss (binary cross-entropy). This design maximizes extraction performance while enabling robust query refinement at inference.
Experimental Results
Experiments were conducted using a dataset with class label-based queries, evaluating performance under FMQ, PMQ, and FUQ conditions. The main metrics are SNR improvement (SNRi) for extraction and attenuation ratio for silence approximation.
Key findings:
The classifier achieves a Macro F1 score of ~0.65, and the additional computational cost is modest (4.7% increase in MACs, 4.6% in parameters). The trade-off is that false negatives in classification can degrade FMQ performance by erroneously removing active target classes from the query. Lowering the threshold θ mitigates this risk.
Trade-offs, Limitations, and Implications
The main trade-off is between robustness to PMQ/FUQ conditions and optimal FMQ performance. The classifier's accuracy, particularly the false negative rate, is critical; improvements in sound event detection could further enhance query refinement. The architecture is efficient and scalable, suitable for real-time applications with minimal overhead.
Practically, the method enables more user-friendly TSE systems that tolerate imperfect queries, a necessity for deployment in consumer devices. Theoretically, it establishes a framework for integrating context-aware inference in query-conditioned source separation.
Future Directions
Potential future work includes:
- Leveraging temporal information from sound event detection for frame-level query refinement.
- Addressing intra-clip PMQ conditions where class activity varies within an audio segment.
- Exploring more sophisticated classifier architectures or pre-trained audio foundation models to improve query refinement accuracy.
- Extending the approach to multi-modal queries (e.g., text, audio, and visual cues).
Conclusion
The paper presents a context-aware query refinement method for TSE, addressing the overlooked PMQ condition and demonstrating robust extraction performance under diverse query scenarios. The approach is efficient, generalizes across FMQ, PMQ, and FUQ conditions, and is readily applicable to real-world systems. The main limitation is the dependency on classifier accuracy, but the framework provides a solid foundation for future advances in context-aware source separation.