Cross-attention Inspired Selective State Space Models for Target Sound Extraction
Published 7 Sep 2024 in eess.AS and cs.SD | (2409.04803v5)
Abstract: The Transformer model, particularly its cross-attention module, is widely used for feature fusion in target sound extraction which extracts the signal of interest based on given clues. Despite its effectiveness, this approach suffers from low computational efficiency. Recent advancements in state space models, notably the latest work Mamba, have shown comparable performance to Transformer-based methods while significantly reducing computational complexity in various tasks. However, Mamba's applicability in target sound extraction is limited due to its inability to capture dependencies between different sequences as the cross-attention does. In this paper, we propose CrossMamba for target sound extraction, which leverages the hidden attention mechanism of Mamba to compute dependencies between the given clues and the audio mixture. The calculation of Mamba can be divided to the query, key and value. We utilize the clue to generate the query and the audio mixture to derive the key and value, adhering to the principle of the cross-attention mechanism in Transformers. Experimental results from two representative target sound extraction methods validate the efficacy of the proposed CrossMamba.
The paper presents CrossMamba, which enhances target sound extraction by integrating state space models with cross-attention mechanisms.
It reformulates Mamba computations to capture cross-sequence dependencies, reducing computational complexity compared to traditional Transformers.
Experiments on AV-SepFormer and Waveformer demonstrate superior SI-SNR performance and lower MACs/model sizes for efficient real-time processing.
CrossMamba: Selective State Space Models for Target Sound Extraction
Introduction
The paper presents CrossMamba, a novel approach leveraging state space models to enhance target sound extraction (TSE) tasks. This method integrates the computational efficiency of structured state space models with the feature fusion capabilities of cross-attention mechanisms inherent to Transformers. CrossMamba addresses the challenges of capturing dependencies between sequences with reduced computational burden while maintaining the efficacy seen in Transformer-based methods.
Design Principles of CrossMamba
Attention Mechanism
At the core of TSE tasks is the notion of extracting the sound of interest from a blended signal using given clues. Traditional attention mechanisms operate based on queries, keys, and values derived from input sequences, calculated as:
α=softmax(dkQKT)
where α forms the attention matrix facilitating feature fusion.
Mamba State Space Model
Mamba capitalizes on structured state space models (SSMs), which efficiently handle long sequence dependencies with linear time complexity. However, its limitation lies in modeling interactions between sequences. Mamba parameters are input-dependent, facilitating a selective focus on sequence aspects without explicit cross-sequence dependency modeling.
CrossMamba Innovation
To bridge this gap, CrossMamba incorporates a cross-attention-inspired framework, reformulating Mamba computations to include sequence interactions. By utilizing a query from audio clues and keys/values from mixed signals, CrossMamba models sequence interdependencies analogous to Transformer cross-attention mechanics:
yi=j=1∑Nfm,q(xq,i)fm,k(xv,j)Hi,jxv,j
The architecture enhances resource efficiency by leveraging linear projections and bidirectional state space modeling.
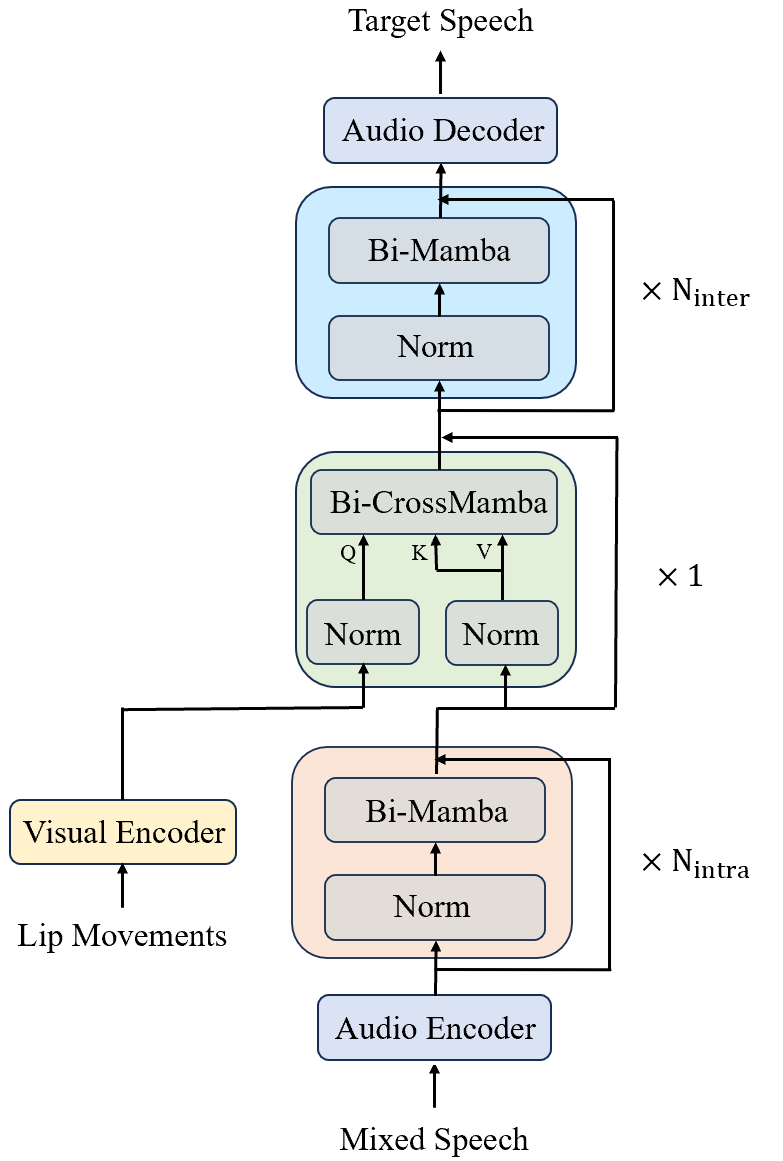
Figure 1: The structure of CrossMamba based AV-SepFormer.
CrossMamba Application in TSE Models
AV-SepFormer Model
AV-SepFormer, which utilizes lip movements for audio separation, implements CrossMamba for its CrossModalTransformer layer. By replacing Transformer layers with bidirectional Mamba blocks and cross-attention-based blocks, AV-SepFormer achieves computational gains while preserving separation performance.
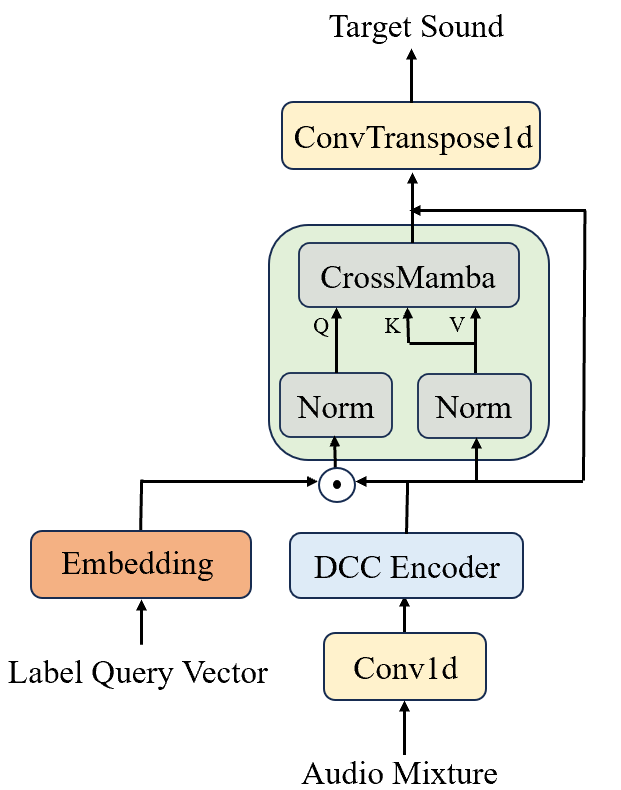
Figure 2: The structure of CrossMamba based Waveformer.
Waveformer Model
Waveformer, a real-time TSE task using class labels, substitutes its Transformer decoder with causal CrossMamba blocks. This integration ensures real-time processing capabilities, vital for immediate sound extraction, without compromising efficiency.
Experimental Results
CrossMamba was evaluated across multiple metrics including SI-SNR and model complexity. Results demonstrate CrossMamba's superiority in delivering enhanced performance with reduced MACs and model sizes for both AV-SepFormer and Waveformer implementations.
AV-SepFormer Results
The AV-SepMamba models demonstrated a significant reduction in MAC operations and model size compared to their Transformer counterparts, while achieving comparable or superior SI-SNR metrics.
Waveformer Results
The application of CrossMamba in Waveformer similarly showed computational benefits with enhanced SI-SNRi results, underscoring CrossMamba's ability to optimize lightweight models for real-time TSE tasks.
Conclusion
CrossMamba offers a promising avenue for effectively modeling sequence dependencies in TSE tasks with reduced computational requirements. Its intrinsic design fostering sequence interaction modeling via state space constructs holds potential for broader applications across various tasks requiring attention mechanisms. As demonstrated, CrossMamba equips target sound extraction models with both efficiency and robust performance, paving the way for future advancements in sound processing technologies.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.