- The paper presents a novel FTR framework that integrates explicit user feedback with an advanced decoding strategy to overcome the limitations of prompt-based self-correction in LLMs.
- LTM decoding employs dynamic multipath exploration to enhance deep reasoning and sequence coherence while adaptively managing computational overhead.
- Empirical evaluations demonstrate 10–20% performance improvements on tasks like mathematical reasoning and code generation across models up to 13B parameters.
Feedback-Triggered Self-Correction and Long-Term Multipath Decoding for LLMs
Motivation and Limitations of Prompt-Based Self-Correction
LLMs exhibit strong performance across a range of tasks, yet their inference remains susceptible to factual errors and shallow reasoning. Prompt-based self-correction methods, which rely on introspective prompts to guide LLMs in revising their own outputs, have been widely adopted. However, empirical analysis reveals two critical limitations: (1) the lack of reliable guidance signals for error localization, and (2) the restricted reasoning depth imposed by conventional next-token decoding. These limitations result in frequent conversion of correct answers into incorrect ones and poor correction of erroneous responses, as evidenced by the distribution of answer changes induced by self-correction prompts.
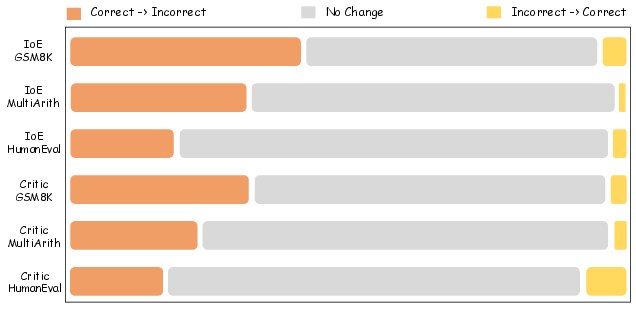
Figure 1: The percentage distribution of answer changes induced by self-correction using If or Else (IoE) Prompts and Critic Prompts, highlighting the instability of prompt-based self-correction.
Feedback-Triggered Regeneration (FTR): Framework and Rationale
To address the aforementioned limitations, the paper introduces Feedback-Triggered Regeneration (FTR), a two-stage self-correction framework that leverages explicit user feedback as a trigger for response regeneration. In FTR, the LLM generates an initial response to the input. If negative feedback is received, the model reprocesses the original input using an advanced decoding strategy, without introducing additional prompts. This design circumvents the pitfalls of prompt-induced solution drift and avoids unnecessary reprocessing of correct outputs.
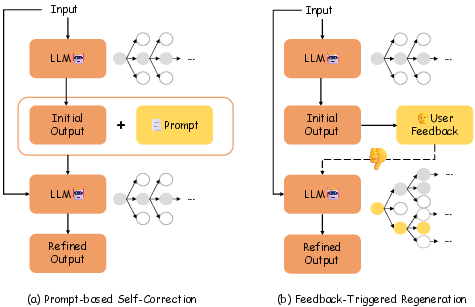
Figure 2: (a) Standard prompt-based self-correction workflow. (b) FTR framework utilizing user feedback and advanced decoding for targeted regeneration.
The FTR approach is further contrasted with conventional methods in terms of self-assessment, feedback-prompted revision, and feedback-triggered regeneration.

Figure 3: Comparison of self-correction paradigms: (a) self-assessment and update, (b) revision with user feedback prompt, (c) regeneration triggered by user feedback.
Long-Term Multipath (LTM) Decoding: Deep Reasoning via Multipath Exploration
Standard autoregressive decoding in LLMs is inherently myopic, optimizing for next-token probability and failing to evaluate the global quality of the output sequence. The proposed Long-Term Multipath (LTM) decoding strategy enables systematic exploration of multiple reasoning trajectories by dynamically retaining top candidate sequences at each step, based on perplexity (PPL) and cumulative probability thresholds. Unlike fixed-width beam search, LTM adaptively adjusts the candidate set size, prioritizing long-term sequence coherence and semantic consistency.
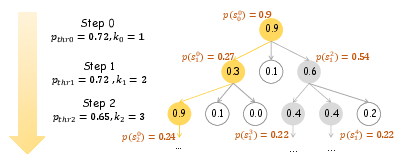
Figure 4: Illustration of LTM decoding strategies (V=3), showing token likelihoods and sequence likelihoods for multipath exploration.
LTM decoding is activated only during the regeneration phase triggered by negative feedback, thereby enabling deep reasoning for error correction without incurring excessive computational overhead. The adaptive mechanism allows the model to retrospectively correct errors and avoid local optimum traps, as demonstrated in comparative decoding scenarios.
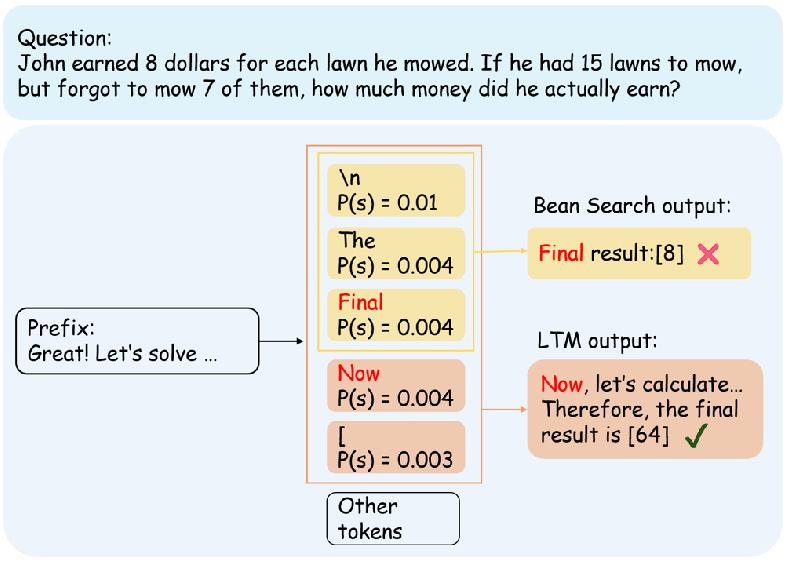
Figure 5: Decoding process comparison between Beam Search (fixed beam width=3) and LTM on a MultiArith question, illustrating LTM's dynamic candidate set advantage.
Empirical Evaluation: Mathematical Reasoning and Code Generation
The FTR framework is evaluated on GSM8K, MultiArith, and HumanEval datasets using open-source LLMs ranging from 1B to 13B parameters. Two evaluation protocols are employed: (1) supervised ground-truth feedback, and (2) human-mimicking proxy feedback via GPT-4o. Across all datasets and model scales, FTR consistently achieves substantial performance gains (10–20% improvement) over state-of-the-art prompt-based self-correction methods. Notably, baseline methods often degrade performance relative to initial outputs, confirming the instability of prompt-based introspection.
User Feedback Integration: Prompt vs. Indicator
A critical ablation investigates the optimal utilization of user feedback. Encoding feedback as a natural language prompt for refinement yields inferior results compared to using feedback solely as a binary trigger for regeneration. The feedback-as-indicator approach significantly outperforms feedback-as-prompt, empirically supporting the recommendation to use feedback exclusively as a regeneration signal.
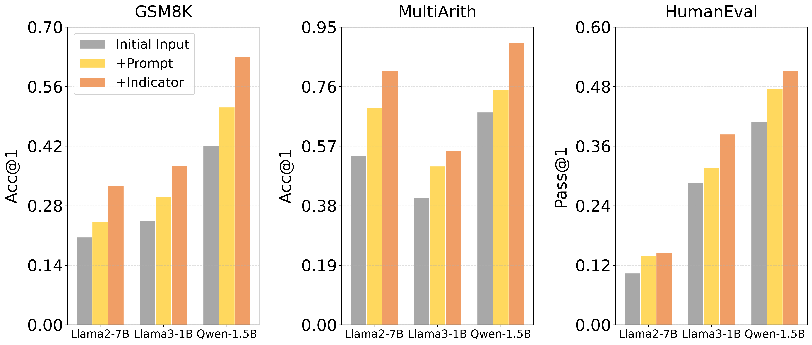
Figure 6: Performance comparison of user feedback utilization approaches, demonstrating the superiority of feedback-as-indicator over feedback-as-prompt.
Decoding Strategy Comparison
LTM decoding is benchmarked against greedy decoding, beam search, combined sampling, and adaptive decoding. LTM consistently outperforms all baselines, particularly in scenarios requiring deep reasoning and global sequence evaluation. Its dynamic candidate set mechanism enables more effective resource allocation and error correction.
Computational Efficiency and Scalability
While LTM introduces additional computational overhead, FTR's design mitigates this cost by triggering regeneration only for samples with negative feedback. Inference time analysis demonstrates that FTR achieves net efficiency gains in low error rate scenarios, with parallelization further reducing per-sample regeneration cost. The framework is validated on models up to 13B parameters, with future work needed to assess scalability to larger architectures.
Theoretical and Practical Implications
The integration of explicit user feedback and advanced decoding strategies in FTR represents a shift from introspective prompt-based correction to externally guided, targeted regeneration. This approach enhances both the accuracy and coherence of LLM outputs, particularly in tasks requiring deep reasoning. The findings challenge the efficacy of prompt-based self-correction in open-source models and highlight the importance of feedback-driven mechanisms for robust human-AI interaction.
Future Directions
Potential avenues for future research include the development of redundancy mitigation techniques in LTM decoding, such as dynamic path pruning based on semantic similarity and diverse beam search. Systematic evaluation of LTM's scalability across larger LLMs and real-time deployment scenarios will further elucidate its impact on computational efficiency and interaction quality.
Conclusion
The paper presents a comprehensive framework for feedback-triggered self-correction in LLMs, combining user feedback with long-term multipath decoding to address the limitations of prompt-based methods. Empirical results demonstrate consistent and significant improvements in reasoning and code generation tasks, with robust performance across model scales and feedback protocols. The proposed approach offers a flexible and adaptive solution for enhancing LLM reliability in practical human-AI interaction settings, while also motivating further research into scalable, feedback-driven correction mechanisms.

