On sources to variabilities of simple cells in the primary visual cortex: A principled theory for the interaction between geometric image transformations and receptive field responses
Abstract: This paper gives an overview of a theory for modelling the interaction between geometric image transformations and receptive field responses for a visual observer that views objects and spatio-temporal events in the environment. This treatment is developed over combinations of (i) uniform spatial scaling transformations, (ii) spatial affine transformations, (iii) Galilean transformations and (iv) temporal scaling transformations. By postulating that the family of receptive fields should be covariant under these classes of geometric image transformations, it follows that the receptive field shapes should be expanded over the degrees of freedom of the corresponding image transformations, to enable a formal matching between the receptive field responses computed under different viewing conditions for the same scene or for a structurally similar spatio-temporal event. We conclude the treatment by discussing and providing potential support for a working hypothesis that the receptive fields of simple cells in the primary visual cortex ought to be covariant under these classes of geometric image transformations, and thus have the shapes of their receptive fields expanded over the degrees of freedom of the corresponding geometric image transformations.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to: “On sources to variabilities of simple cells in the primary visual cortex”
Overview
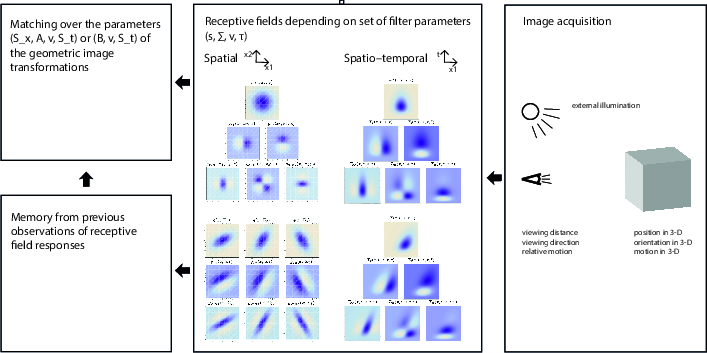
This paper asks a big question: how does your brain keep recognizing things you see, even when they look different because you moved, they moved, you got closer or farther away, or the action sped up or slowed down? The author focuses on “simple cells” in the first part of the brain’s vision system (called V1). These cells each watch a small patch of the visual world and respond to patterns like edges and lines. The paper offers a theory for how the shapes and settings of these cells can change in a principled way so their responses still “match up” across different views of the same scene.
Key questions
- When the image of an object changes on our eyes (because of distance, viewing angle, motion, or speed of events), how do the responses of simple cells change?
- Can we design a set of simple cell “filters” so that, even when the image changes, their outputs change in a predictable way? This predictable behavior is called covariance (also known as equivariance).
- Do the real simple cells in the brain have shapes and settings that “cover” all the kinds of changes that happen in everyday seeing?
How the study works (methods in everyday language)
The author builds a clean, math-based model of what simple cells do. Think of each cell like a tiny tool that:
- Blurs the image a bit (like looking through glass with different amounts of frosting), and then
- Measures how quickly brightness changes in certain directions (like running your finger along the image to find edges at a chosen angle).
To match real life, the model includes space and time:
- Space: where things are in the image.
- Time: how things change from one moment to the next.
The paper studies four common “image changes” that happen when you look at the world:
- Zooming in/out (spatial scaling): the same object looks bigger when you’re closer and smaller when you’re farther.
- Changing view angle (spatial affine change): the object looks stretched or squashed when you look at it from the side.
- Relative motion (Galilean transformation): things shift in the image over time when either they move, you move, or both.
- Speeding up/slowing down events (temporal scaling): the same action (like a wave or a blink) can happen faster or slower.
In symbols, the paper talks about:
- for zoom (size change),
- for stretch/squeeze by viewpoint,
- for motion (a 2D velocity),
- for time speed-up/slow-down.
What do the “filters” look like?
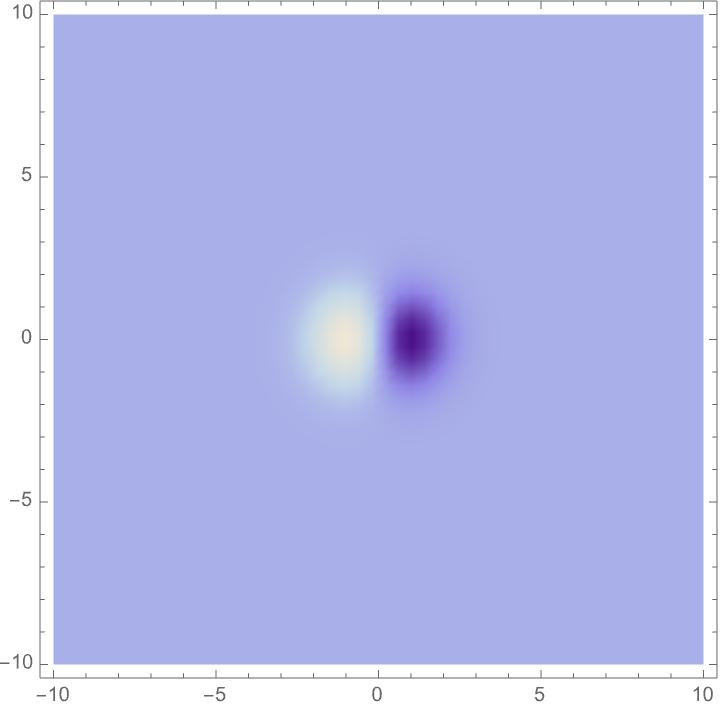
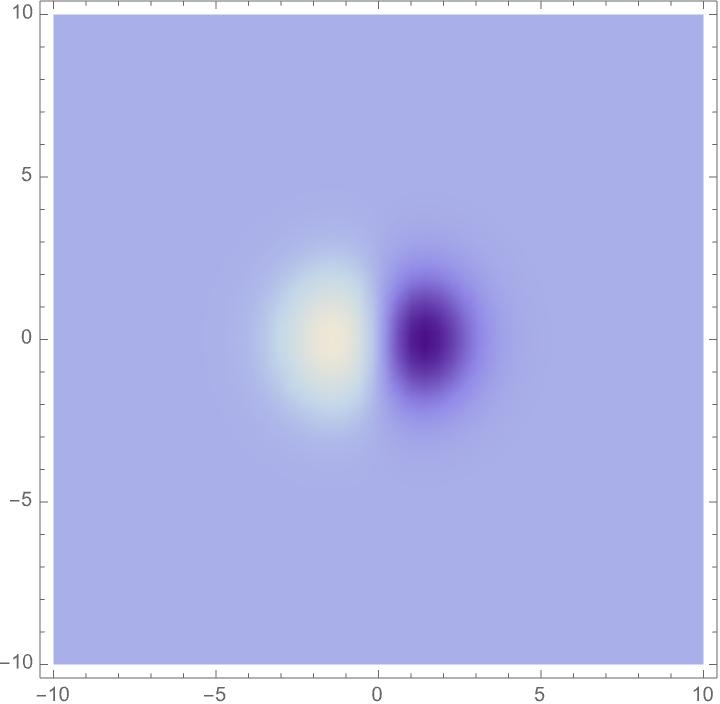
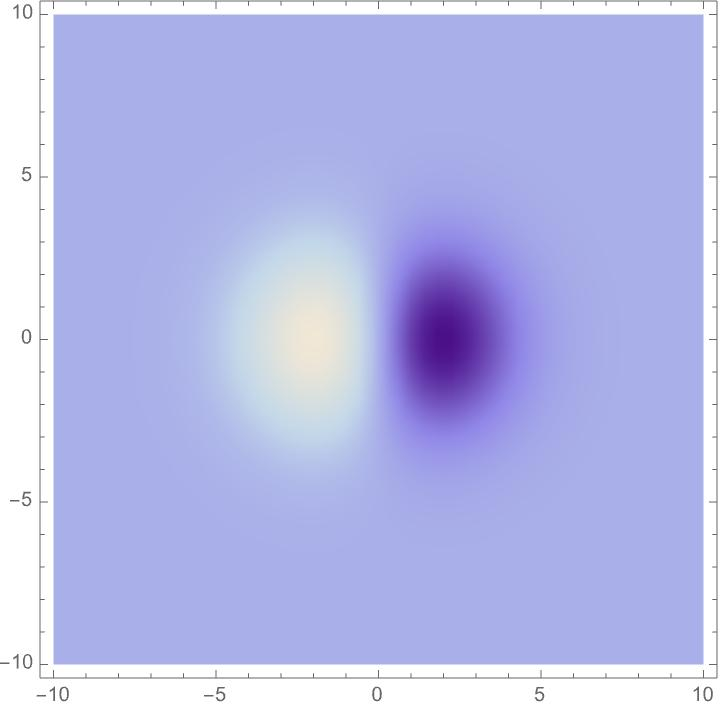
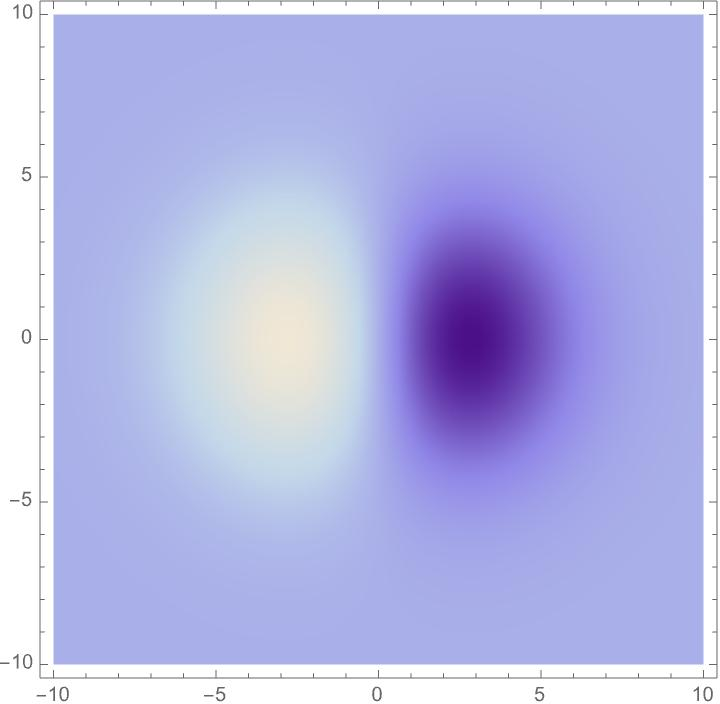
- Spatial part: Gaussian smoothing (a gentle blur) with different sizes and shapes, then derivatives (which detect changes) in chosen directions. This captures edges at different scales and angles, and can be more circular or more elongated to match how a tilted surface looks.
- Temporal part: two options:
- A standard Gaussian blur in time (good for analyzing recorded videos).
- A “time-causal” blur for real-time seeing (you can’t peek into the future). Imagine a chain of tiny cups slowly leaking water into the next—this creates a smooth, delayed response that only depends on the past. The model can then take time-derivatives (to detect when things start or stop changing) and can even “tilt” these time measurements along the direction of motion to track moving patterns.
The key idea: choose a family of these filters that covers different sizes, angles, elongations, motion speeds, and time scales. Then show that when the image changes by zooming, tilting, moving, or time scaling, the filter responses change in a predictable way (covariance). That makes it possible to match responses across different views.
Main findings
- The proposed filters (Gaussian smoothing plus spatial and temporal derivatives) are covariant under the four common changes:
- Spatial scaling (zoom),
- Spatial affine changes (viewpoint stretch/squeeze),
- Galilean transformations (relative motion),
- Temporal scaling (speeding up/slowing down).
- This means if you transform the image (say, zoom in) and then apply the filter, you get the same kind of result as if you first applied a related filter (e.g., one set to a different size) and then accounted for the zoom. The outputs “track” the changes.
- Because of this, you can make the filter responses from two different views of the same scene line up. In other words, you can tell it’s the same thing even though it looks different on the screen or retina.
- The model predicts that real simple cells should come in many variations that “span” all the needed settings:
- Multiple sizes (for near and far),
- Many orientations (for edges at different angles),
- Different elongations (to handle viewpoint slant),
- Different preferred speeds (to follow moving patterns),
- Different time scales (to catch fast and slow events).
- The paper argues that such diversity in cell shapes and settings, often seen in experiments, is not random—it's exactly what’s needed to handle everyday changes in what we see.
Why this is important
- For the brain: If early vision cells are covariant (predictably changing with the image), then later brain areas can combine their outputs to build invariant recognition (stable identity) across distance, viewpoint, motion, and speed changes. This helps explain how we recognize the same object in many situations.
- For experiments: The theory suggests what to look for in neurophysiology and psychophysics—namely, whether simple cells’ shapes and settings cover the space of scales, orientations, elongations, motion speeds, and time scales in a systematic way.
- For technology: The ideas connect to modern AI (“geometric deep learning”), where networks are designed to behave predictably under transformations. Using these biologically inspired filters can help build vision systems that are robust to zoom, viewpoint, motion, and timing changes.
In short, the paper provides a clear, principled reason for why simple cells in the visual cortex should be so varied: their variety is exactly what’s needed to keep our perception stable when the world—or we—move and change.
Collections
Sign up for free to add this paper to one or more collections.