- The paper introduces the TSAIA benchmark as a systematic framework for evaluating LLMs in multi-step time series reasoning.
- It demonstrates that while LLMs perform well on simple forecasting tasks, they struggle with complex contextual reasoning and constraint satisfaction.
- Empirical results show that integrating code-execution feedback improves performance on diagnostic, analytical, and decision-making tasks.
Evaluating LLMs for Multi-Step Time Series Reasoning: The TSAIA Benchmark
Motivation and Problem Statement
The application of LLMs to time series analysis remains underexplored, particularly for tasks requiring compositional, multi-step reasoning, numerical precision, and adherence to domain-specific constraints. While LLMs have demonstrated strong performance in language, code, and scientific reasoning, their ability to function as general-purpose time series inference agents—capable of constructing end-to-end analytical workflows—has not been systematically evaluated. Existing benchmarks are limited in scope, often focusing on isolated tasks, lacking real-world operational constraints, and failing to assess the assembly of complex analytical pipelines.
TSAIA Benchmark: Design and Task Taxonomy
The TSAIA (Time Series Artificial Intelligence Assistant) benchmark is introduced to address these gaps. It is constructed from a survey of over 20 academic publications and comprises 33 real-world task formulations, spanning predictive, diagnostic, analytical, and decision-making tasks. The benchmark emphasizes compositional reasoning, comparative and commonsense reasoning, decision-oriented analysis, and numerical precision. Tasks are drawn from domains such as energy, finance, climate science, and healthcare, and are categorized by difficulty and reasoning requirements.
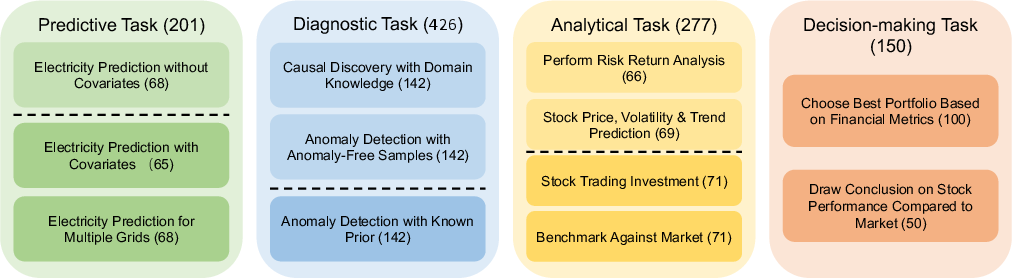
Figure 1: Task taxonomy in TSAIA, with color intensity indicating difficulty.
The benchmark's extensibility is achieved via a modular, programmatic pipeline for task instance generation. This pipeline supports dynamic expansion as new datasets or task types are introduced, ensuring long-term relevance and adaptability.
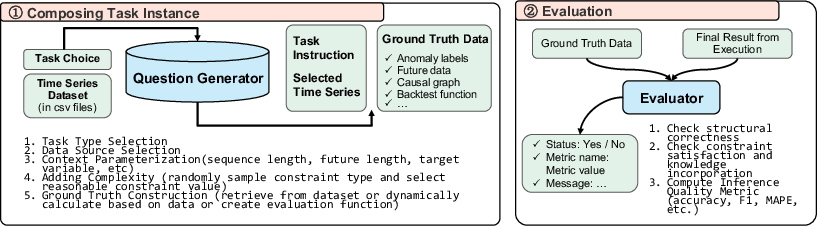
Figure 2: Pipeline for generating and evaluating multi-step time series inference tasks.
Each task instance consists of a natural language instruction, a serialized time series dataset, and a ground truth output, supporting both automatic and robust evaluation.
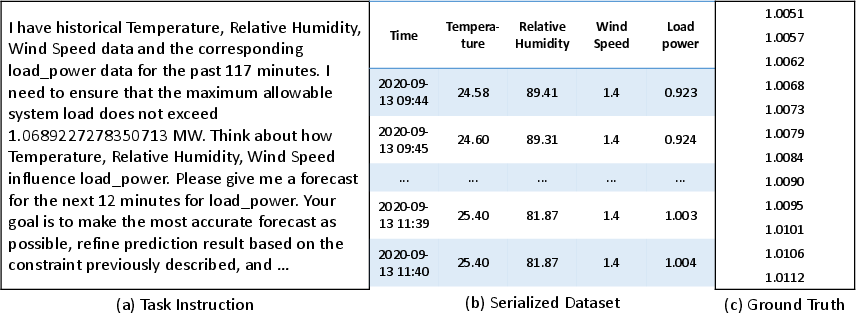
Figure 3: Example of a task instance, including instruction, serialized data, and ground truth.
Evaluation Protocol and Metrics
Given the heterogeneity of tasks, TSAIA employs task-specific success criteria and tailored inference quality metrics. For example, constrained forecasting tasks require predictions that satisfy operational constraints (e.g., load limits, ramp rates), while anomaly detection tasks require non-trivial binary outputs. Analytical and decision-making tasks, particularly in finance, demand correct computation of risk/return metrics and selection of optimal portfolios or strategies. Evaluation is multi-stage: outputs are first validated for structural correctness, then checked for constraint satisfaction and domain knowledge incorporation, and finally scored using task-appropriate metrics.
Experimental Setup
Eight state-of-the-art LLMs are evaluated: GPT-4o, Qwen2.5-Max, Llama-3.1 Instruct 70B, Claude-3.5 Sonnet, DeepSeek, Gemini-2.0, Codestral, and DeepSeek-R. All models are deployed under the CodeAct agent framework, which enables code-based interaction—LLMs generate executable Python code, receive execution feedback, and iteratively refine their outputs. This approach mitigates issues with premature output truncation and tokenization of numerical values.
Empirical Results and Analysis
Predictive and Diagnostic Tasks
Models generally achieve high success rates on simple predictive tasks (e.g., maximum/minimum load forecasting) but exhibit significant performance degradation on tasks requiring temporal smoothness (ramp rate, variability control) or increased data dimensionality (multi-grid forecasting). For diagnostic tasks, such as anomaly detection with reference samples, models frequently fail to leverage contextual information, often defaulting to trivial outputs (e.g., all-zero anomaly labels). This highlights a deficiency in compositional and contextual reasoning.
Analytical and Decision-Making Tasks
In financial forecasting, models perform adequately on price and volatility prediction but struggle with trend prediction and complex risk/return analysis. Success rates are highly variable across metrics, with models biased toward familiar or formulaically simple metrics (e.g., Sharpe ratio). In multiple-choice decision-making tasks, most models do not exceed chance-level accuracy, with DeepSeek-R being a notable exception due to its persistent, exploratory problem-solving strategy.
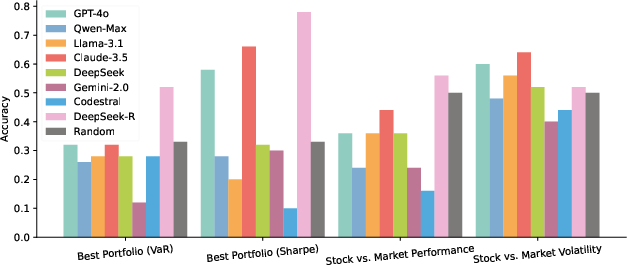
Figure 4: Model performance on decision-making and analysis-interpretation tasks in multiple choice format.
Agent Behavior and Error Analysis
Analysis of agent behavior reveals that more difficult tasks require a greater number of interaction turns, underscoring the importance of execution feedback loops for solution refinement. DeepSeek-R consistently takes more turns and uses more tokens, correlating with higher success rates on complex tasks but at the expense of efficiency.
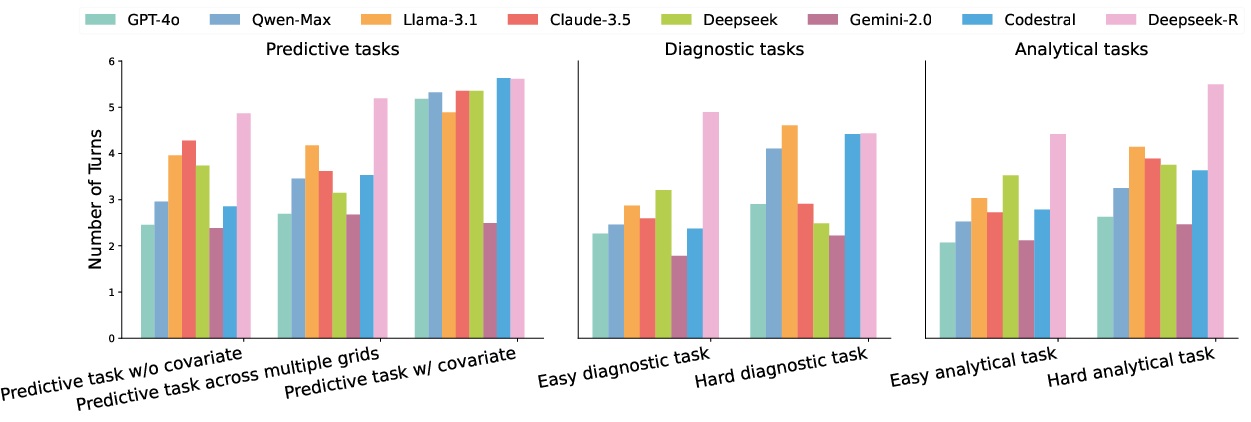
Figure 5: Average number of turns required to reach a solution, grouped by task difficulty.
Error analysis for GPT-4o demonstrates that tasks involving covariates or multiple time series are particularly prone to execution and constraint violation errors. In diagnostic tasks, the inability to orchestrate multi-step workflows (e.g., threshold calibration using reference samples) is a dominant failure mode. Analytical tasks involving benchmarking against market indices or less conventional financial metrics also exhibit high rates of execution errors and inadequate results.
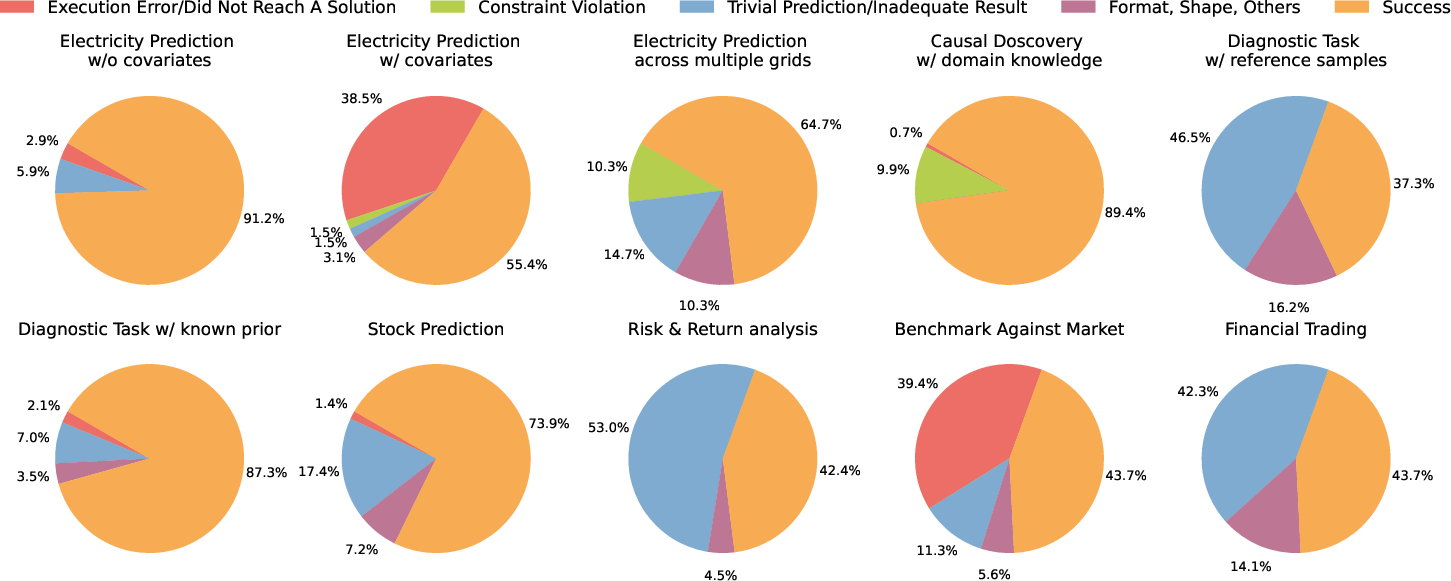
Figure 6: Error distribution for GPT-4o across tasks and difficulty levels.
Implications and Future Directions
The results indicate that current LLMs, even when augmented with code execution capabilities, are not yet reliable general-purpose time series inference agents. Key limitations include:
- Inadequate compositional and contextual reasoning for multi-step analytical workflows.
- Poor integration of domain-specific constraints and external knowledge.
- Limited numerical precision and robustness in structured output generation.
These findings suggest that further progress will require hybrid approaches that tightly integrate symbolic reasoning, program synthesis, and domain alignment. The TSAIA benchmark provides a rigorous foundation for systematic evaluation and development of such methodologies.
Conclusion
TSAIA establishes a comprehensive, extensible benchmark for evaluating LLMs as time series AI assistants, emphasizing real-world analytical workflows and multi-step reasoning. Empirical evaluation of leading LLMs reveals substantial limitations in compositional reasoning, constraint satisfaction, and domain adaptation. The benchmark highlights the need for specialized architectures and hybrid agentic frameworks to advance LLM-based time series analysis. Future work should focus on expanding domain coverage, increasing task diversity, and developing models with improved reasoning and execution capabilities for complex, domain-grounded time series inference.