- The paper introduces a localization framework that uses navigational signs and public maps to bypass pre-deployment sensor mapping.
- It extracts unified navigational graphs from heterogeneous map data and uses vision-language models for robust sign parsing and directional cue extraction.
- Robust particle filtering achieves rapid convergence in diverse environments, validating seamless indoor-outdoor deployment with minimal observations.
SignLoc: Robust Localization using Navigation Signs and Public Maps
Introduction and Motivation
SignLoc introduces a global localization framework for mobile robots that leverages navigational signs and publicly available human-centric maps—specifically, floor plans and OpenStreetMap (OSM) graphs—to achieve robust localization without the need for prior sensor-based mapping. The approach is motivated by the observation that navigational signs and human-centric maps are ubiquitous in human environments, encode symbolic locational and directional information, and are purposefully designed to support wayfinding at scale. Despite their prevalence, these resources have been underutilized in robotic localization systems, which typically rely on geometric features or require pre-deployment mapping.
Map Extraction and Navigational Graph Construction
The first stage of SignLoc is the extraction of a unified navigational graph G=(V,E) from heterogeneous map sources. The pipeline processes both floor plans (as 2D images) and OSM graphs, extracting three node types: intersection nodes (junctions), place nodes (named regions), and portal nodes (doors, lifts, stairs). Edges represent traversable connections, discretized into 8 cardinal directions to preserve coarse directional information.
The extraction process employs computational geometry techniques, including skeletonization in polygon-space, connected components analysis, and polygonal skeletonization for traversable areas. Text and symbol extraction is performed using OCR (PaddleOCR) and VLM-based symbol detection, with manual correction available via a GUI tool (NavGraphApp) for cases where automated extraction is insufficient.
Multi-floor and multi-building alignment is achieved by registering extracted floor plan polygons to OSM polygons using a similarity transform that maximizes the intersection-over-union (IoU) between polygons, embedding the navigational graph in a global coordinate frame.
Figure 1: The map extraction pipeline, from venue map or floor plan to navigational graph, integrating geometry, text, and symbols.
Sign Parsing via Vision-LLMs
The sign parsing module identifies candidate navigational signs in RGB images using fast text spotting (PaddleOCR) and open-set object detection (GroundingDINO). Candidate signs are then processed by a VLM-based sign understanding system, which extracts navigational cues as tuples (signloc,signdir), where signloc is a location label and signdir is a probability distribution over 8 cardinal directions.
The VLM is prompted iteratively to generate a set of cues C={(signlocj,signdirj)}, with uncertainty in directionality empirically estimated from the model's responses. This approach enables robust parsing of diverse, in-the-wild sign layouts, and supports open-set recognition of place names and directions.
Sign-Centric Monte Carlo Localization
SignLoc employs a particle filter for global localization, where the robot's state is defined as (v,θ)—the current node in the navigational graph and heading. The observation model computes the likelihood of observing a set of navigational cues C given the robot's state and the map, using a geometric mean over individual cue likelihoods.
For each cue, the model considers the top-k most similar node labels (using normalized Levenshtein distance) and evaluates the likelihood that the direction of shortest travel from the current node to the candidate node matches the observed direction distribution. This is formalized as:
p(toward(u)=d∣xt,G)=p(dedge=d)exp(−(dedge⋅dact)2)
where dedge is the direction of the edge along the shortest path, dact is the robot's actual heading, and p(dedge=d) is the prior from the sign parsing module.
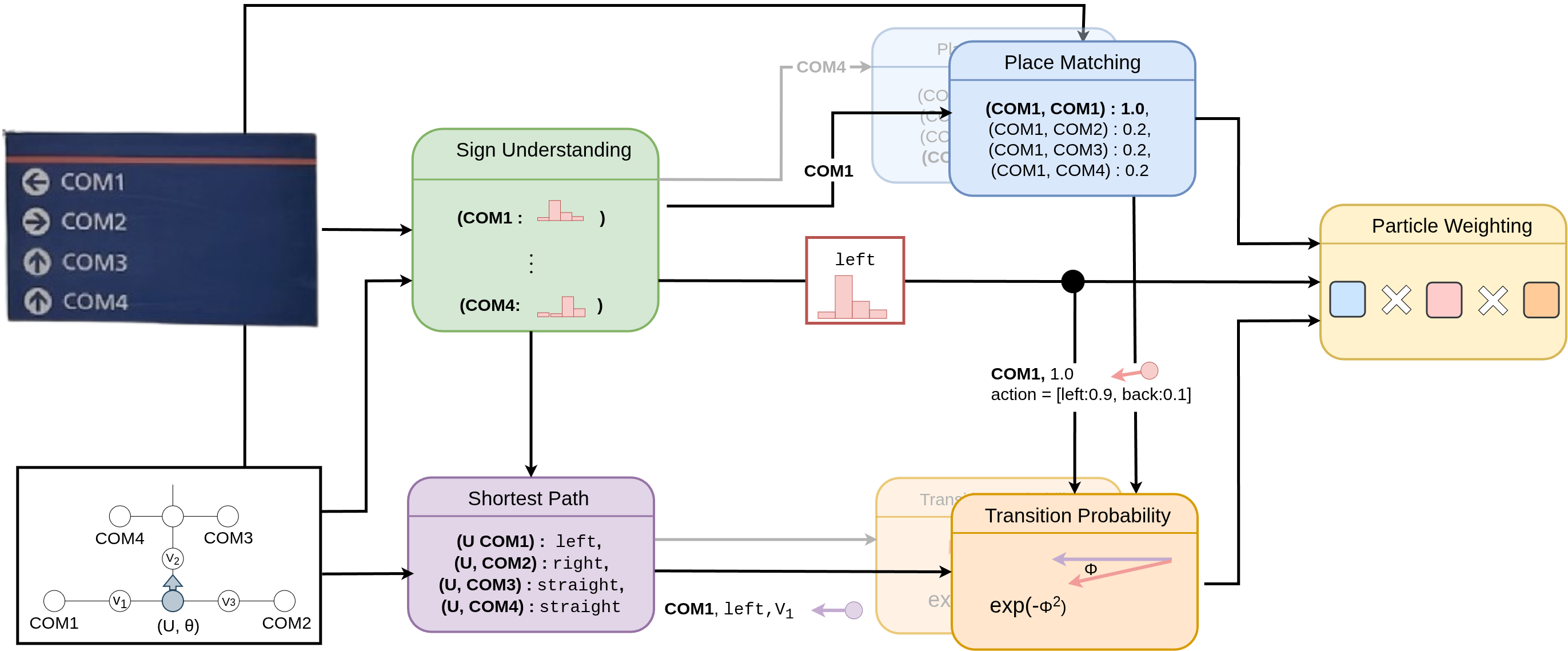
Figure 2: The observation model computes the likelihood of observing a sign for each particle, reweighting particles accordingly.
Resampling is performed using a mixture of reciprocal and low-variance sampling, with particles sampled near nodes and orientations proportional to their weights. The motion model supports both topological (discrete actions) and topometric (continuous pose) localization, with odometry or action priors as appropriate.
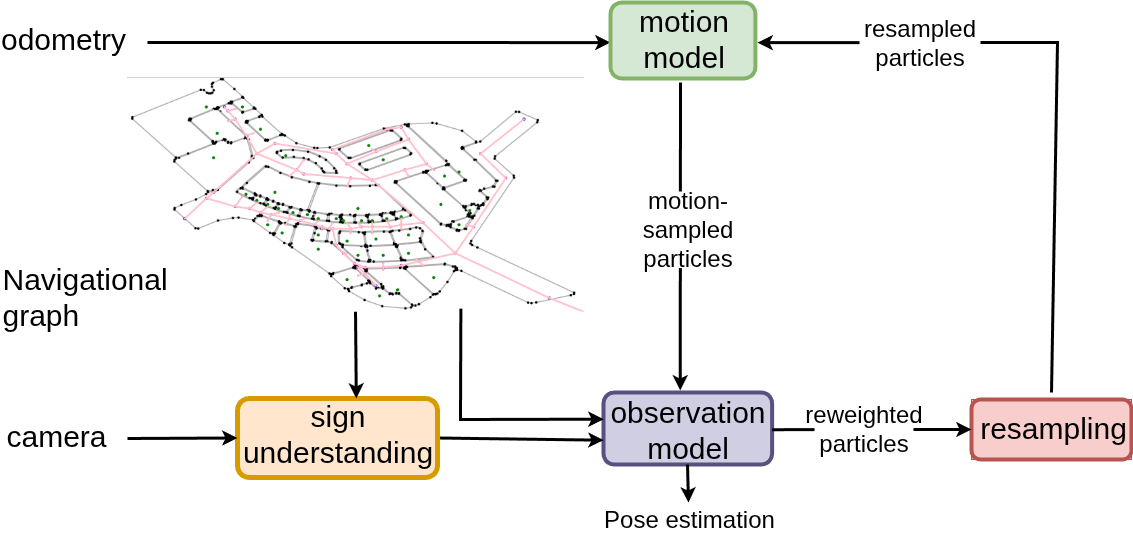
Figure 3: Overview of the localization approach, integrating the navigational graph and sign-based cues.
Experimental Evaluation
SignLoc was evaluated in three large-scale environments: a university campus, a shopping mall, and a hospital complex, encompassing multi-floor, multi-building, and indoor-outdoor transitions. The dataset was collected using a Boston Dynamics Spot robot and a hand-held setup, with only odometry and RGB streams.
Across 10 trajectories in three environments, the sign understanding pipeline achieved cue precision/recall of 0.82–0.85 and sign accuracy of 0.43–0.69, with the main failure mode being ambiguous direction parsing in complex signs. Despite imperfect parsing, the high cue-level accuracy ensures that sufficient information is available for robust localization.
The map extraction pipeline was tested on 13 floor plans/venue maps from 7 buildings, including multi-floor and multi-building scenarios. The approach successfully extracted navigational graphs from all tested maps, including those where prior methods (e.g., Xie et al. [xie2020icra]) failed. The extracted graphs were seamlessly augmented with OSM road networks to support indoor-outdoor localization.
Figure 4: Qualitative results of map extraction, showing multi-floor, multi-building navigational graphs from public maps.
Localization Accuracy
Nine sequences (5 sign sightings each) and one long sequence (7 signs, 300m trajectory) were used to evaluate localization. The particle filter was globally initialized (uniform over all traversable nodes), with up to 4448 particles for the largest graph. Localization converged to the correct node and orientation after observing only 1–2 signs in 80% of cases, and always remained correct after convergence, yielding a 100% success rate. The system demonstrated robustness to perception noise, with identical performance when using ground-truth sign annotations.
No existing baseline supports both indoor and outdoor localization with public maps; VPR methods (e.g., Lalaloc++) are limited to floor plans, and methods like OrienterNet cannot handle indoor spaces.
Runtime and Deployment Considerations
SignLoc was deployed on a Jetson Orin onboard the Spot robot. For a 605-node graph with 4448 particles, the observation model executes in 25ms and the motion model in 12ms per step. Sign parsing (VLM query) requires ~2.5s per sign, but this latency is masked by requiring the robot to be static during parsing. The system operates online in real time, and the open-source implementation is available.
Implications and Future Directions
SignLoc demonstrates that navigational signs and public maps can be effectively leveraged for robust, scalable, and mapless localization in large, heterogeneous environments. The approach eliminates the need for pre-deployment mapping, supports seamless indoor-outdoor transitions, and is robust to perception noise and map imperfections. The reliance on semantic cues aligns with human wayfinding strategies and enables deployment in previously unseen environments.
Future work may focus on improving symbol/text extraction from maps, integrating additional semantic cues (e.g., objects, affordances), and extending the framework to support dynamic environments or multi-robot systems. The use of VLMs for open-set sign understanding is promising, but further advances in multimodal perception and map parsing will be required to handle the full diversity of real-world signage and map formats.
Conclusion
SignLoc provides a practical and robust solution for global localization in large-scale, human-centric environments by matching directional cues from navigational signs to a navigational graph extracted from public maps. The system achieves rapid convergence with minimal observations, supports both indoor and outdoor localization, and operates in real time on embedded hardware. The results validate the utility of semantic features and human-centric priors for scalable robot localization, and open new avenues for deploying robots in complex, unmapped environments.

