- The paper introduces ELIB as a new framework for benchmarking LLM inference on edge devices using the Model Bandwidth Utilization (MBU) metric.
- It outlines a comprehensive methodology measuring FLOPS, throughput, latency, and accuracy, with insights on GPU acceleration and low-bit quantization.
- The study highlights trade-offs between throughput, latency, and accuracy, offering practical insights for optimizing edge-based LLM deployment.
Evaluation of LLM Inference on Edge Devices
LLMs, including models like LLaMA, have grown in complexity and capability, requiring substantial computational resources. Traditionally hosted on cloud infrastructures, LLM inference on edge devices offers several advantages, particularly in terms of data privacy and latency. This paper introduces ELIB, a benchmarking tool designed to evaluate LLM performance on edge platforms, accompanied by a novel metric called Model Bandwidth Utilization (MBU).
ELIB Framework Overview
ELIB serves as a comprehensive platform for deploying LLMs on edge devices, addressing hardware variability and optimizing inference performance. It consists of several core components responsible for model adaptation, deployment, inference, and processing of performance metrics.
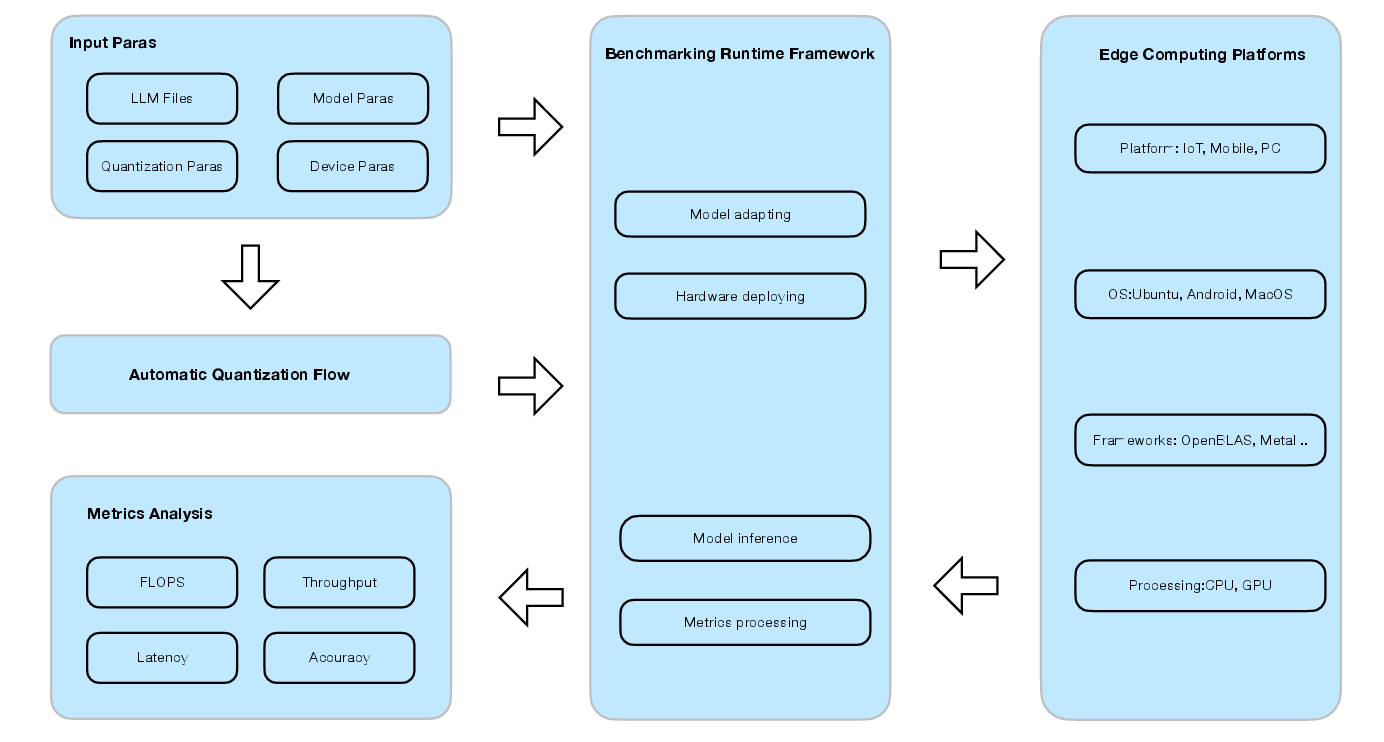
Figure 1: The design overview of ELIB indicates that the core component is the benchmarking runtime framework, including model adaptation, hardware deployment, model inference, and metrics processing.
The benchmark framework simplifies edge deployment through a Model-Graph-Kernel structure, allowing users to efficiently manage dependencies and optimize kernel performance across various platforms.

Figure 2: Model-Graph-Kernel structure of benchmark runtime framework offers a more elegant design methodology to deployment, operation, and expansion.
Benchmarking Methodology
ELIB evaluates five key metrics: FLOPS, throughput, latency (TTLM and TTFT), accuracy, and MBU. These metrics provide a holistic view of model performance across board compute-bound and memory-bound scenarios.
FLOPS and Throughput Analysis
Results indicate significant variability in FLOPS across different edge devices and acceleration frameworks. The use of hybrid computing (GPU acceleration) proves advantageous.
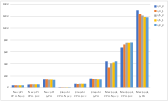
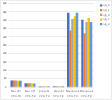
Figure 3: (a) The comparison of FLOPS measured in billions of floating-point operations per second (GFLOPS), is presented between the non-accelerated and accelerated versions for three platforms across five testing quantization models. (b) Provides a comparison of the FLOPS measured in GFLOPS for 4 threads and 8 threads.
Throughput improvements are observed with low-bit quantization models but can adversely affect accuracy. Hardware optimization and careful model selection are crucial.
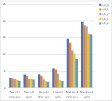
Figure 4: Inference throughputs results, measured in tokens per second.
Latency Considerations
Loading times, as shown in Figure 5, depend heavily on RAM bandwidth, with low-bit models witnessing decreased latency.
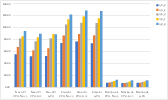
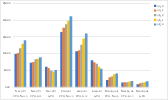
Figure 5: (a) The time measured in second required to load a model (TTLM) on each device varies for different quantized models. (b) The time it takes to the first token (TTFT) after the user input, measured in second.
Accuracy Measures
Accuracy, expressed in perplexity scores, remains stable under CPU conditions regardless of quantization methods. However, there are noticeable discrepancies under GPU configurations, highlighting the necessity for rigorous hardware testing.
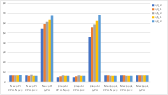
Figure 6: Inference accuracy measure in perplexity score.
Implications and Future Work
Optimizing inference performance on edge devices requires careful trade-offs between throughput, latency, and accuracy. Increasing MBU can enhance computational efficiency without sacrificing performance, provided memory constraints are managed effectively. The study suggests integrated evaluation across platforms and various configurations to achieve optimal deployment.
Further research will expand ELIB's support to include more diverse models, quantization methodologies, and edge computing devices, providing robust tools for refining edge-based LLM deployment strategies.
Conclusion
Deploying LLMs on edge devices involves navigating complex hardware variability and memory limitations. ELIB offers a versatile platform for benchmarking these deployments, providing valuable insights into optimizing performance metrics for specific applications. Balancing throughput, latency, and accuracy is fundamental, and advancements in optimization frameworks ensure these objectives are met effectively. Future adaptations of ELIB aim to broaden compatibility and enhance practical deployment guidelines.

