- The paper introduces TableVault, a metadata management system that captures comprehensive records of data ingestion and lineage in AI workflows.
- It employs ACID-like properties with two-phase locking to ensure consistency and transparency in human-AI collaborative data operations.
- The framework supports dynamic metadata querying during model execution, enabling adaptive decision-making in complex data pipelines.
As datasets become increasingly complex with contributions from numerous systems and individuals, managing metadata in AI-augmented workflows poses unique challenges. These workflows introduce heterogeneity, dynamic execution patterns, and opaque model decisions, complicating comprehensive metadata capture. TableVault is introduced as a metadata governance framework that facilitates transparency and reproducibility in human-AI collaborative data pipelines.
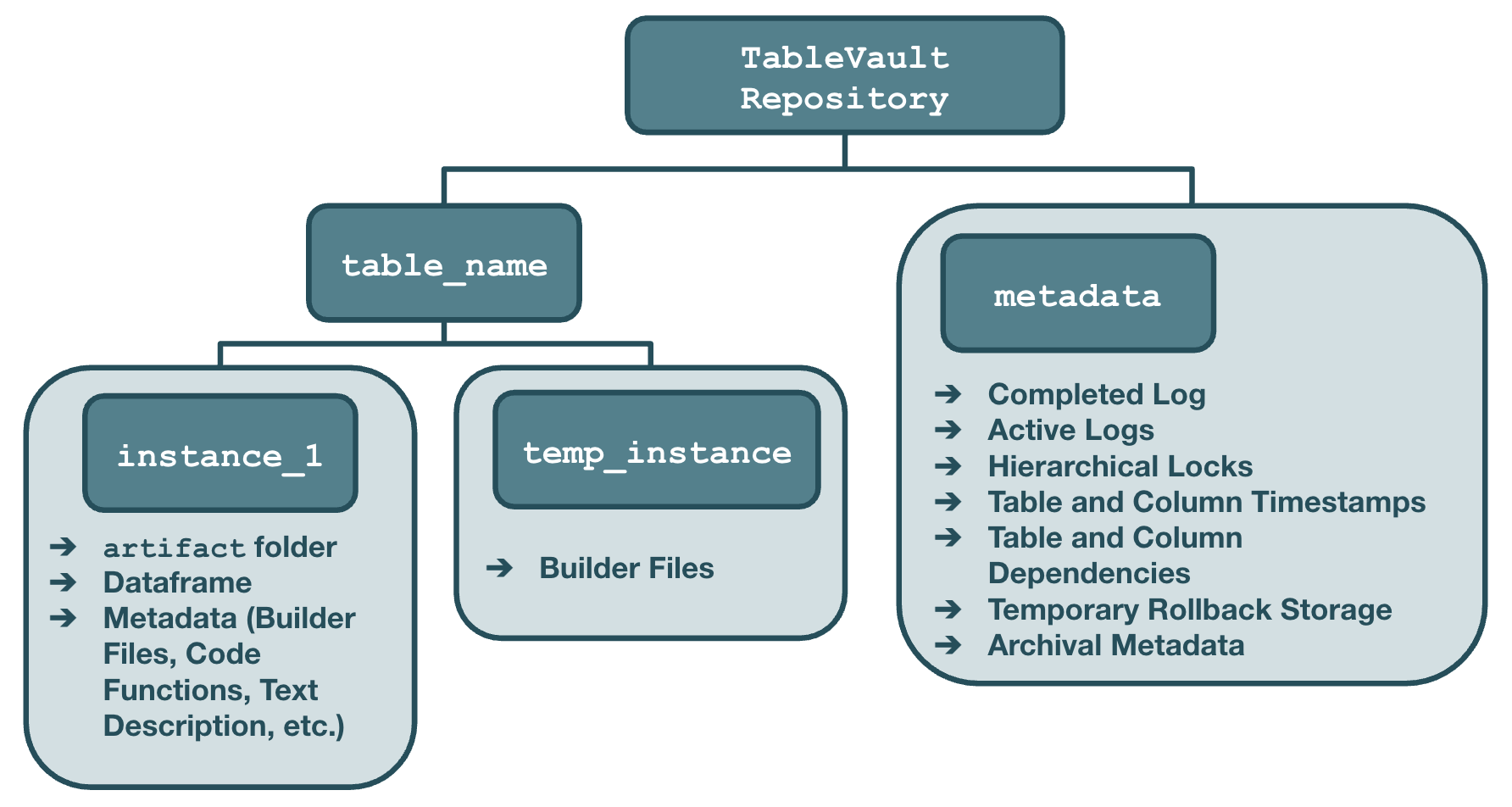
Figure 1: System diagram of TableVault.
Key Features of TableVault
Guaranteed Record of Data Ingestion: TableVault captures comprehensive metadata including data ingestion points, signaling where and when external operations have occurred. This system-centric approach maintains a granular record of data changes.
Robust Operation Status Tracing: Due to the opaque nature of LLMs, capturing data lineage requires a linkage between operations and explainability tools. TableVault's approach provides metadata across these dimensions to aid in tracing complex data transformations.
Lineage Capture of Execution Parameters: Execution decisions, driven by data-centric algorithms like hyperparameter tuning and prompt engineering, require lineage tracking of both data artifacts and influencing parameters. TableVault integrates this capability, ensuring that the data lineage comprehensively includes parameter influences.
Metadata Querying Within Model Executions: The system allows model-based agents to access metadata, supporting dynamic workflows where metadata can be queried programmatically during execution. This feature advances the potential for adaptive and intelligent data operations.
Architectural Components
TableVault is implemented in Python and leverages structured dataframes. It addresses the dual aspects of data operation execution and artifact management, ensuring oversight at each stage of data creation. The system supports linking data operations to authors, whether human or AI, and provides metadata access for partially-complete operations only to authors, maintaining data integrity until operations finalize.

Figure 2: Breakdown of a TableReference string.
TableVault organizes data in human-readable files on the native filesystem, categorized into semantic collections called "tables" and specific data instances. Each instance encapsulates a dataframe and its unstructured data, with metadata preserved within descriptive YAML files.
Execution and Operation in TableVault
The system employs ACID-like properties, supporting atomic execution of data operations with two-phase locking and copy-on-write strategies to preserve data consistency. Authors, whether human or automated, are granted access to workflow metadata, enabling dynamic, informed decision-making.
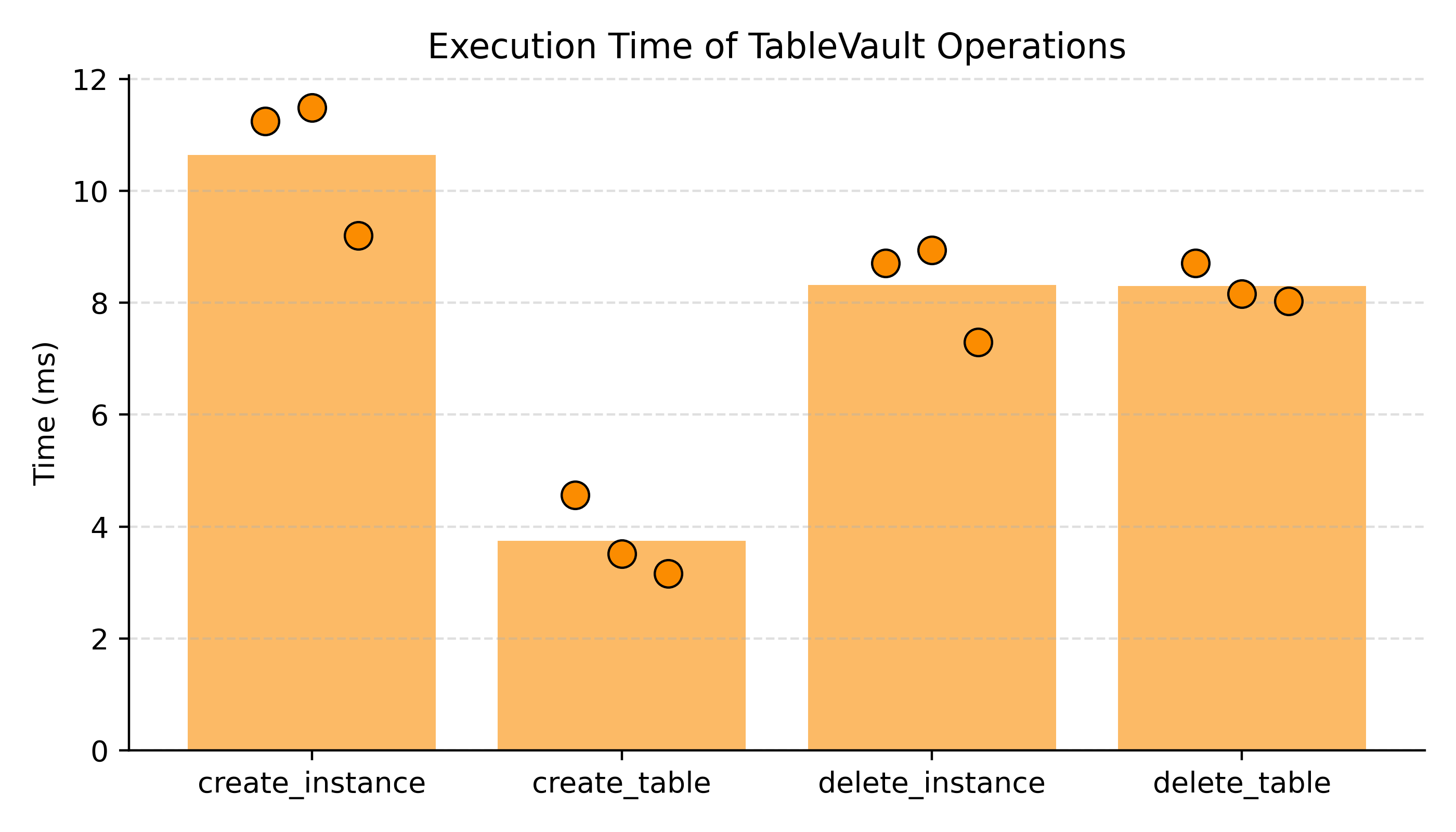
Figure 3: Execution time of basic TableVault operations.
Example of Implementation: Through the API, TableVault enables seamless repository creation, management of data instances, execution of operations, and manual data edits. A typical use case includes document categorization via OpenAI API calls, where TableVault demonstrates its capabilities for managing AI-augmented workflows.
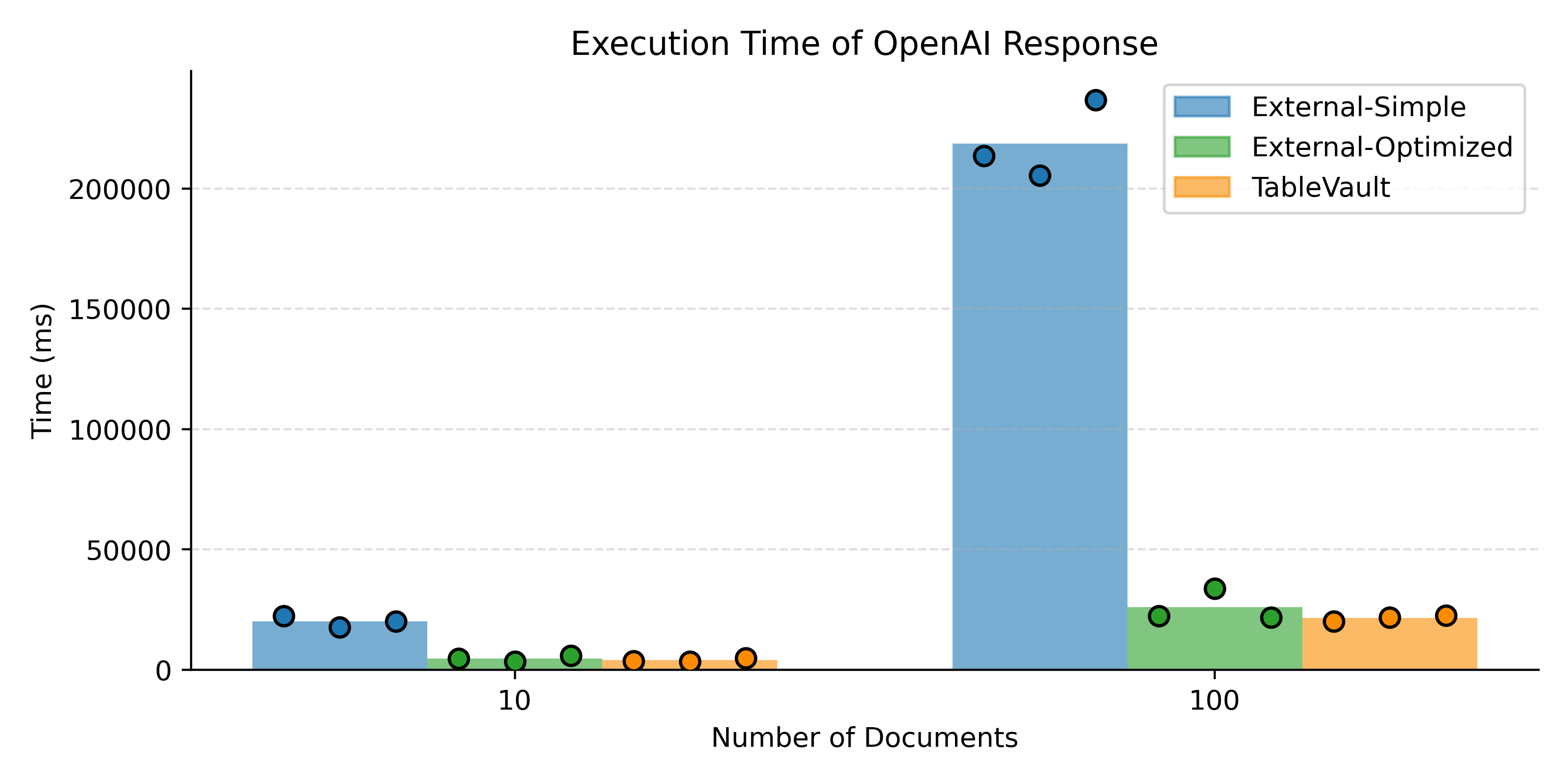
Figure 4: Execution time of OpenAI response over documents.
Implications and Future Developments
The implications of TableVault's design are profound for AI data workflows. It underscores the importance of comprehensive metadata management in facilitating reproducibility, transparency, and accountability. As AI models continue to evolve, TableVault offers a pathway to more robust metadata handling in increasingly autonomous and complex workflows.
In future iterations, enhancing performance scalability and integrating more autonomous model-agent interactions remain pivotal. The development of standardized protocols and practices will further bolster metadata alignment with advanced AI-driven workflows.
Conclusion
TableVault represents a significant advancement in metadata management for AI-driven data workflows, ensuring meticulous tracking and governance of data operations. As AI continues to shape data analytics, TableVault’s principles provide a framework for navigating these complex interactions while adhering to the FAIR principles, crucial for fostering a trusted and transparent data ecosystem.