- The paper presents MetaPix, a robust platform that integrates DataSources, Datasets, Extractors, and Extensions to efficiently manage unstructured computer vision data.
- The paper details an innovative embedding-based search using AI techniques like CLIP and Elasticsearch to enable effective semantic data discovery.
- The paper demonstrates that modular integration with external annotation and visualization tools enhances dataset quality and scalability for AI applications.
The paper introduces MetaPix, a data-centric AI platform designed for efficient management and utilization of unstructured computer vision data. MetaPix provides comprehensive data management solutions, focusing on data ingestion, processing, storage, versioning, governance, and discovery, which are critical for developing and maintaining high-quality, diverse datasets that improve predictive capabilities and business solutions. The platform's architecture is built around four core concepts: DataSources, Datasets, Extractors, and Extensions.
MetaPix is structured around four key components that collectively facilitate data management and utilization: DataSources, Datasets, Extractors, and Extensions. These components ensure the provision of high-quality, reliable data for machine learning workflows.
DataSources
DataSources manage data ingestion, storage, and governance. They serve as queryable, live data streams enabled with Google BigQuery, and are used to create datasets. Computer vision data, originating from connected vehicles or manufacturing plants, is stored either on-premises or in GCP Cloud Storage Buckets. These buckets are connected to a GCP object table, which indexes all media using a unique generation ID. This architecture is shown in Figure 1.
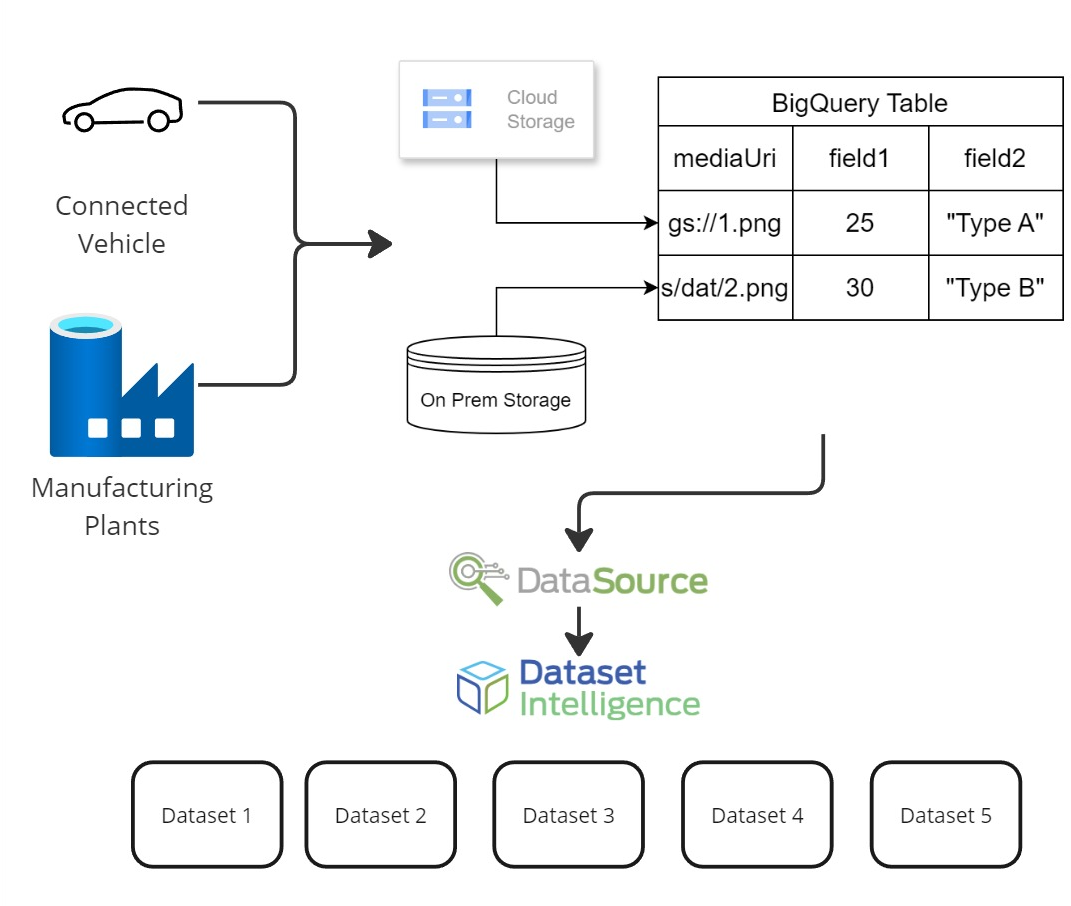
Figure 1: MetaPix DataSource Architecture.
When new images or media are added, the corresponding index changes are pushed to the object table, which is linked to a BigQuery table containing additional metadata. This combined table, referred to as the extended attribute table, is associated with a DataSource, facilitating user access. The platform uses data crawlers to monitor and search media stored on on-premises servers to populate these tables. The DataSource object includes properties such as 'Cat_level' for data privacy risk assessment, GCP Project ID, table name, GCP BigQuery view for index creation, and the column name holding the target media location (mediaUri). For dynamic data, the 'storage_locations' property lists storage locations for the crawling service to monitor. Vector embeddings for images are generated during DataSource creation to enhance efficiency for subsequent datasets.
Datasets
Datasets are logical abstractions within MetaPix, representing subsets or derivatives of a DataSource, or complete datasets. They store only metadata and paths to the media, enabling versioning and linking to AI-powered tools. The MetaPix Dataset Intelligence workbench supports dataset exploration and integration with connected services. Key features include data quality monitoring, versioning, data lineage, and prevention of data duplication, achieving storage cost savings by efficiently managing data duplication. Users can create dataset objects by providing a prepared JSONL or COCO JSON file specifying storage locations, or by executing an SQL query on a DataSource. The "versions" property tracks the development of a dataset through progressive stages of enhancement and refinement, ensuring a systematic and traceable enhancement process.
Extractors are AI-powered tools integrated into MetaPix's backend processing pipeline for data processing and enhancement. These tools utilize computer vision and natural language processing techniques to automatically extract meaningful information from unstructured data. One primary feature is embedding-based search, which enables semantic search and data discovery. MetaPix leverages on-premises resources to handle GPU-intensive embedding creation, using services such as GCP Pub/Sub, MongoDB, and Elasticsearch. The embedding-based search involves generating embeddings for content using CLIP (Contrastive Language-Image Pretraining) and storing the resulting vectors in a vector database (Figure 2).
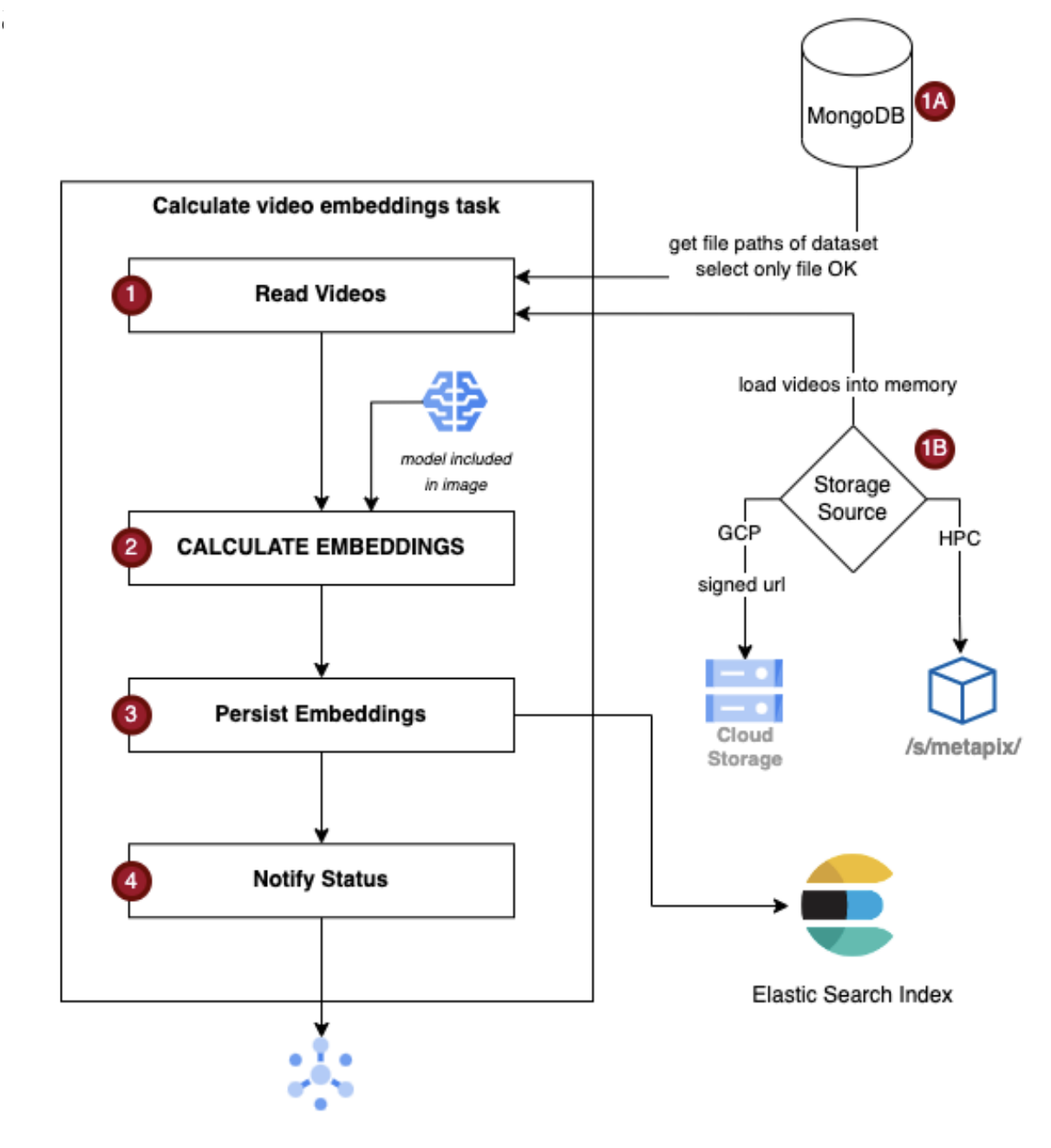
Figure 2: Schematic Representation of the Embeddings Creation Process.
When a user creates a dataset, a Pub/Sub message initiates the embedding creation process. The UI service sends a request to the MetaPix search service, which submits a batch job executed in a Kubernetes container (Figure 3).
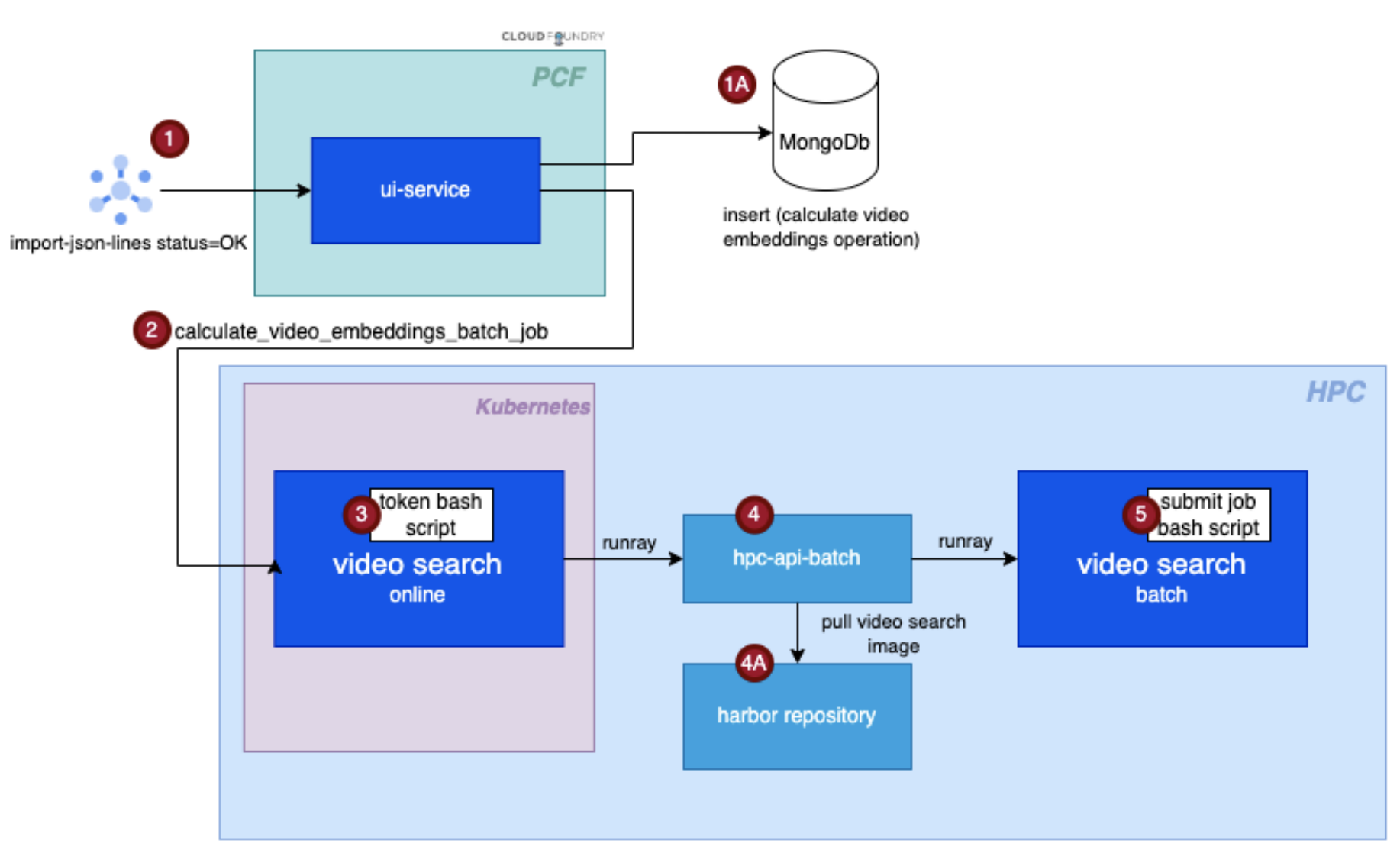
Figure 3: Workflow Diagram of Batch Job Submission to Calculate Embeddings.
Once the embeddings are calculated and stored in Elasticsearch, they are accessible for similarity search. The MongoDB collection is consulted using a dataset ID and version, and a list of relevant segments is returned to the UI for visualization.
Extensions
Extensions are fully-fledged tools outside the MetaPix ecosystem, such as annotation studios, data visualization platforms, or model tracking tools. They integrate seamlessly to enrich MetaPix's capabilities, often through partnerships with specialized vendors. The Annotations service ensures that each external tool adheres to a common format for interacting with MetaPix Datasets. MetaPix Annotations comprise an additional collection of files designed to store metadata related to external annotations, facilitating the import and export of unstructured data to other tools and use cases (Figure 4).
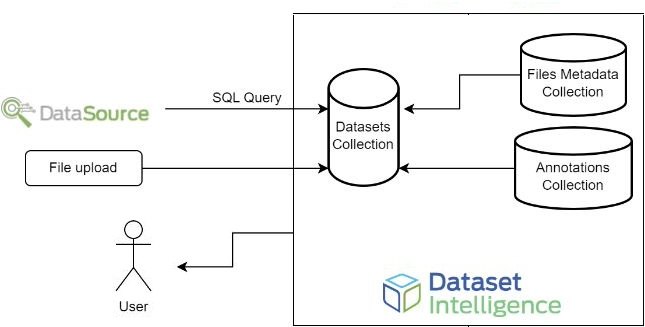
Figure 4: Storage Architecture for Datasets Metadata.
Each dataset and version has a list of linked annotations, detailed with properties like type and properties, which are utilized by Parsers to access the source file or import annotations into a new context.
Implications and Future Directions
The MetaPix platform represents a significant advancement in data-centric AI development, providing a comprehensive solution for managing and utilizing unstructured computer vision data. By addressing the critical aspects of data ingestion, processing, storage, versioning, governance, and discovery, MetaPix enables organizations to develop AI applications more effectively. The platform's modular design, incorporating DataSources, Datasets, Extractors, and Extensions, allows for flexibility and scalability, accommodating various data types and use cases. The emphasis on data quality and accessibility ensures that machine learning models are trained on reliable and well-curated datasets, leading to improved predictive capabilities and smarter business solutions. As AI technology continues to evolve, platforms like MetaPix will play an increasingly important role in enabling organizations to leverage their data assets for strategic advantage.
Conclusion
MetaPix offers a robust and adaptable solution for managing unstructured data, addressing critical needs in data ingestion, processing, storage, versioning, governance, and discovery. By streamlining data management and promoting data quality, MetaPix empowers organizations to harness their data assets for strategic decision-making and enhanced operational efficiency.