- The paper introduces a novel policy gradient algorithm, Score Entropy Policy Optimization, that fine-tunes discrete diffusion models using non-differentiable rewards.
- The method employs concrete score matching, importance sampling, and a clipping mechanism to enhance stability and scalability in tasks such as DNA sequencing and language modeling.
- Experimental results confirm that the proposed algorithm significantly improves sample quality and aligns with theoretical convergence bounds.
Fine-Tuning Discrete Diffusion Models with Policy Gradient Methods: A Detailed Overview
This paper introduces a novel policy gradient algorithm, Score Entropy Policy Optimization (), for fine-tuning discrete diffusion models over non-differentiable rewards. It addresses the challenges of applying policy gradient methods to discrete diffusion models, particularly in scenarios like Reinforcement Learning from Human Feedback (RLHF). The method's scalability, efficiency, and theoretical justification are demonstrated through numerical experiments on discrete generative tasks.
Background and Motivation
Diffusion models have emerged as powerful generative tools across various domains, including image and video generation. Recent advancements have extended these models to discrete settings, enabling their application in language modeling and other discrete generative tasks. Fine-tuning these discrete diffusion models remains challenging, especially when dealing with non-differentiable rewards. Existing methods often face scalability issues or result in intractable training objectives. Policy gradient methods, like PPO and GRPO, have shown promise in RLHF due to their stability and unbiased gradient estimates. This paper aims to develop policy gradient methods specifically tailored for discrete diffusion models.
Key Contributions
The authors summarize their contributions as follows:
- An explicit characterization of policy gradient algorithms for discrete diffusion models in the concrete score matching framework.
- A scalable algorithm, , for discrete diffusion, with a gradient flow alternative for improved sample quality at a higher complexity cost.
- Numerical experiments on DNA fine-tuning and natural language tasks demonstrating the performance of the methods.
Methodological Approach
The algorithm leverages the concrete score matching framework, which approximates the time reversal of the forward process in discrete diffusion models. The concrete score is learned using a sequence-to-sequence neural network, and the backward equation is simulated using efficient sampling strategies like the tau-leaping algorithm. Fine-tuning is formulated as an optimization problem over implicitly parameterized distributions, where the goal is to maximize a reward function without direct access to the target distribution.
The paper introduces a discrete analogue of the REINFORCE algorithm, which allows for the computation of the gradient of the reward function with respect to the model parameters. To address the high variance of the REINFORCE algorithm, the authors incorporate ideas from Trust Region Policy Optimization (TRPO) using importance sampling. This leads to a modified gradient estimator that constrains the KL divergence between the old and current policies.
The algorithm builds upon PPO and GRPO, incorporating a clipping mechanism to stabilize training. It can be applied conditionally or unconditionally for fine-tuning, offering flexibility in various applications. The algorithm iteratively samples from the target distribution and optimizes the model parameters using a policy gradient objective, refining the policy over multiple iterations. The authors also propose a gradient flow interpretation of sampling, which involves sampling from a specific time-homogeneous CTMC. This approach allows for the use of predictor-corrector techniques to improve sample quality.

Figure 1: Illustration of the iterative fine-tuning process for discrete diffusion models using policy gradient methods.
Theoretical Analysis
The paper provides convergence bounds for the algorithm. By viewing the algorithm as a system of coupled equations, the authors establish the convergence of the average objective gradients under certain assumptions. These assumptions include boundedness of the gradient of the target distribution and Lipschitz continuity of the gradient with respect to the $$ divergence. The convergence result demonstrates the stability and efficiency of the algorithm in optimizing discrete diffusion models.
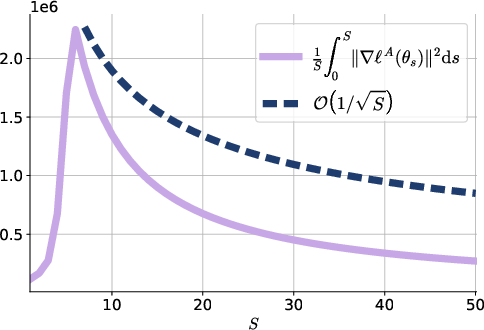
Figure 2: Illustration of the theoretical bound of \cref{thm:stochastic_bound}.
Experimental Validation
The authors conduct experiments on DNA sequence modeling and natural language tasks to demonstrate the effectiveness of their method. In the DNA sequence modeling task, they employ a pre-trained masked discrete diffusion model and use a reward function designed to enhance CG content in DNA sequences. The results illustrate the theoretical bound of the convergence theorem.
In the natural language task, the authors fine-tune SEDD Medium Absorb, a discrete diffusion model with 320M parameters, using an Actor-Critic PPO style approach. They train a reward model using the HH-RLHF dataset and leverage conditional sampling to generate responses. The results demonstrate that the fine-tuned models outperform the pre-trained model in terms of response quality, as evaluated by a Judge LLM.
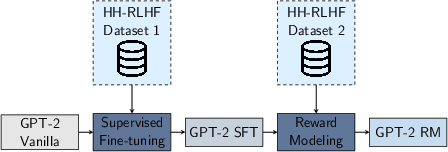
Figure 3: GPT-2 Reward modeling pipeline.
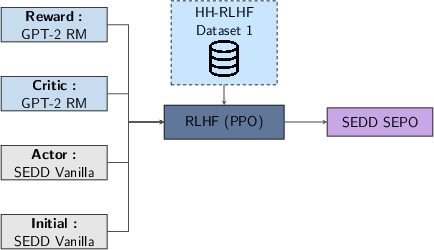
Figure 4: fine-tuning pipeline for SEDD Medium.
Implications and Future Directions
This research has several implications for the field of discrete diffusion models and RLHF. The algorithm provides a practical and theoretically sound approach for fine-tuning discrete diffusion models over non-differentiable rewards. The experimental results demonstrate the effectiveness of the method in enhancing the quality of generated sequences in various domains. Future research directions include refining gradient estimation techniques and exploring applications in structured generative modeling. Additionally, the convergence analysis provides insights into the behavior of the algorithm and suggests potential avenues for further improvement.
Conclusion
The paper presents , a policy gradient method tailored for fine-tuning discrete diffusion models. By leveraging concrete score matching, importance sampling, and a clipping mechanism, the algorithm achieves scalability, stability, and efficiency. The theoretical analysis and experimental results provide strong evidence for the effectiveness of the approach. This work contributes to the growing body of literature on discrete diffusion models and opens up new possibilities for fine-tuning these models in various applications.

