Published 12 Aug 2024 in cs.LG and stat.ML | (2408.05885v2)
Abstract: Generative Flow Networks (GFlowNets) have been shown effective to generate combinatorial objects with desired properties. We here propose a new GFlowNet training framework, with policy-dependent rewards, that bridges keeping flow balance of GFlowNets to optimizing the expected accumulated reward in traditional Reinforcement-Learning (RL). This enables the derivation of new policy-based GFlowNet training methods, in contrast to existing ones resembling value-based RL. It is known that the design of backward policies in GFlowNet training affects efficiency. We further develop a coupled training strategy that jointly solves GFlowNet forward policy training and backward policy design. Performance analysis is provided with a theoretical guarantee of our policy-based GFlowNet training. Experiments on both simulated and real-world datasets verify that our policy-based strategies provide advanced RL perspectives for robust gradient estimation to improve GFlowNet performance.
The paper introduces a novel training method that reformulates the GFlowNet flow balance objective as an expected reward maximization problem using policy gradients.
It details a coupled training strategy that jointly optimizes forward and backward policies via TRPO to enhance training stability and efficiency.
Experimental results across domains like hyper-grid modeling and biological sequence design validate improved performance over traditional value-based methods.
GFlowNet Training via Policy Gradients
This paper introduces a novel GFlowNet training paradigm that leverages policy-dependent rewards to bridge the gap between GFlowNets and traditional RL. The core idea involves reformulating the flow balance objective in GFlowNets as an expected accumulated reward maximization problem in RL, enabling the use of policy gradient methods for GFlowNet training. Additionally, the paper presents a coupled training strategy that jointly optimizes the forward policy and backward policy design, enhancing training efficiency. The theoretical analysis and empirical evaluations across various datasets validate the effectiveness of the proposed policy-based GFlowNet training approach.
Bridging GFlowNets and Reinforcement Learning
The paper addresses the similarity between GFlowNets and RL, highlighting their shared foundation in Markovian Decision Processes (MDPs) with a reward function R(x). While existing GFlowNet training strategies are value-based, this work proposes policy-dependent rewards for GFlowNet training, effectively bridging GFlowNets to RL. This reformulation enables the derivation of policy-based training strategies that directly optimize the accumulated reward by its gradients with respect to the forward policy.
The authors define two reward functions, RF(s,a;θ) and RB(s′,a;ϕ), which depend on the forward and backward policies, respectively. These rewards are used to formulate two MDPs with policy-dependent rewards, where the transition environment is deterministic. By minimizing the expected value functions JF and JB, GFlowNet training can be converted into an RL problem.
Policy Gradient and TRPO-Based Training
The paper presents a policy-based method that generalizes TB-based training with PD equal to PF. The policy-based method approximates the advantage function AF(s,a) functionally by AFλ(s,a), where λ∈[0,1] controls the bias-variance trade-off for gradient estimation. Furthermore, the paper introduces a TRPO-based objective for updating the forward policy πF, aiming to improve training stability.
Coupled Training Strategy for Forward and Backward Policies
The paper formulates the design of backward policies in GFlowNets as an RL problem. A conditional guided trajectory distribution PG(τ∣x) is introduced, and the design problem is formulated as minimizing the objective LTBG. A new reward function RBG(s′,a;ϕ) is defined, allowing the backward policy design problem to be solved by minimizing JBG. The authors propose a coupled training strategy that jointly optimizes JF and JBG, avoiding the need for two-phase training. The workflow of the coupled training strategy is summarized in Algorithm 1 of the paper and depicted by Figure 1.
(Figure 1)
Figure 1: Dotted lines illustrate the spanning range of trajectories, where PB and PG share the ground-truth terminating distribution R(x)/Z∗, and pushing PF to match PB trajectory-wise pushes PF⊤(x) to match R(x)/Z∗.
Theoretical Analysis
The paper provides theoretical analyses to guarantee the performance of the proposed methods. Theorem 1 states that by minimizing JF and JBG jointly, the upper bound of JFG decreases. Theorem 2 introduces upper bounds for the TRPO-based objective, motivating the use of TRPO for updating the forward and backward policies. Theorem 3 provides a theoretical guarantee that policy-based methods with policy-dependent rewards can asymptotically converge to stationary points.
Experimental Validation
The paper presents experimental results on three application domains: hyper-grid modeling, biological and molecular sequence design, and Bayesian Network structure learning. The results demonstrate that the proposed policy-based training strategies improve GFlowNet performance compared to existing value-based methods.
Hyper-Grid Modeling Results
Experiments were conducted on 256×256, 128×128, 64×64×64, and 32×32×32×32 grids. The training curves by DTV across five runs for 256×256 and 128×128 grids are plotted in Figure 2, and Table 1 reports the mean and standard deviation of metric values at the last iteration. The graphical illustrations of PF⊤(x) are shown in Figures 12 and 13. The policy-based methods demonstrated better performance than the value-based training methods, achieving smaller DTV and faster convergence. RL-G achieved the smallest DTV and converged much faster than other methods. RL-T outperformed RL-U and behaved more stably during training, demonstrating that trust regions help reduce sensitivity to estimation noises.
Biological and Molecular Sequence Design Results
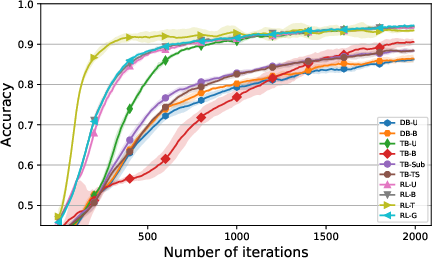
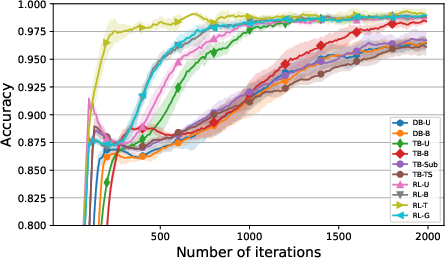
The paper used GFlowNets to generate nucleotide strings and molecular graphs, using datasets SIX6, PH04, QM9, and sEH. The training curves by mode accuracy Acc for SIX6 and QM9 datasets are shown in Figure 3, and Figure 4 in the Appendix. For evaluation consistency, the curves by DTV are provided in Figure 5 in the Appendix, along with the metric values at the last iteration summarized in Tables 2 and 3 in the Appendix. The graphical illustrations of PF⊤(x) are shown in Figures 16 and 17.
Figure 3: Training curves by Acc of PF⊤ w.r.t. P∗ for SIX6 (left) and QM9 (right) datasets, plotted as means and standard deviations across five runs, smoothed by a sliding window of length 10, with metric values computed every 10 iterations.
The results indicate that TB-based and policy-based methods achieved better performance than DB-based methods. While the converged Acc values of TB-based methods and policy-based methods were similar, the latter converged much faster. RL-T had the fastest convergence rates in both experiments.
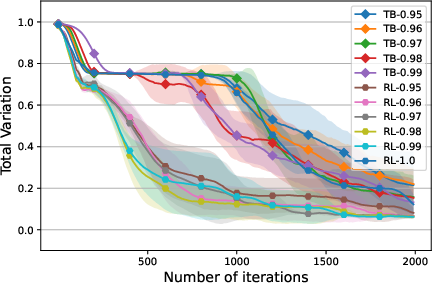
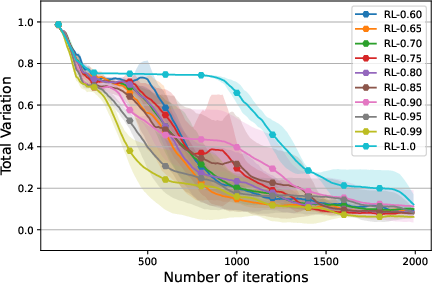
Ablation Study of λ Results
To investigate the effect of λ on the robust estimation of gradients, experiments were conducted in the 256×256 grid environment. The training curves by DTV across five runs are shown in Figure 6 in the Appendix. The results verified that by controlling λ, the policy-based methods provided more robust gradient estimation than TB-based methods.
Figure 6: Performance comparison between RL-U with different λ values and TB-U with different γ values, plotted as means and standard deviations across five runs, smoothed by a sliding window of length 10, with metric values computed every 10 iterations.
Conclusion
This paper successfully bridges flow-balance-based GFlowNet training to RL problems by developing policy-based training strategies, enhancing training performance compared to existing value-based strategies. The experimental results support the claims made in the paper, demonstrating the effectiveness of the proposed approach. The method intrinsically corresponds to minimizing the KL divergence between two distributions, which does not necessitate G to be a DAG, and future work will focus on extending the proposed methods to general G with the existence of cycles for more flexible modeling of generative processes of object x∈X.