- The paper presents an expert-in-the-loop probing pipeline to assess LLMs' comprehension of temporal aspects in narratives.
- The experiments reveal that LLMs perform well on prototypical perfective events but struggle with imperfective events, affecting causal inference.
- The study indicates that LLMs rely on linguistic prototypes, resulting in less human-like causal reasoning and inconsistent aspectual judgments.
LLMs' Temporal Comprehension in Narratives
This paper (2507.14307) investigates the extent to which LLMs comprehend the temporal meaning of linguistic aspect within narratives. The authors employ an Expert-in-the-Loop probing pipeline, adapting experimental methodologies from cognitive science to assess whether LLMs construct semantic representations and pragmatic inferences akin to human cognition. The study reveals that LLMs exhibit an over-reliance on prototypical linguistic structures, produce inconsistent aspectual judgments, and struggle with causal reasoning derived from aspect, indicating a fundamental difference in how LLMs process aspect compared to humans. The authors also introduce a standardized experimental framework to assess cognitive and linguistic capabilities of LLMs.
Experimental Design and Methodology
The study is based on narratives previously used in human studies, focusing on the manipulation of grammatical aspect (perfective vs. imperfective) to influence causal inference. The narratives are structured to include two potential causes (C1 and C2) followed by an effect, with the aspect of C1 varied to assess its impact on the perceived causality of the effect.
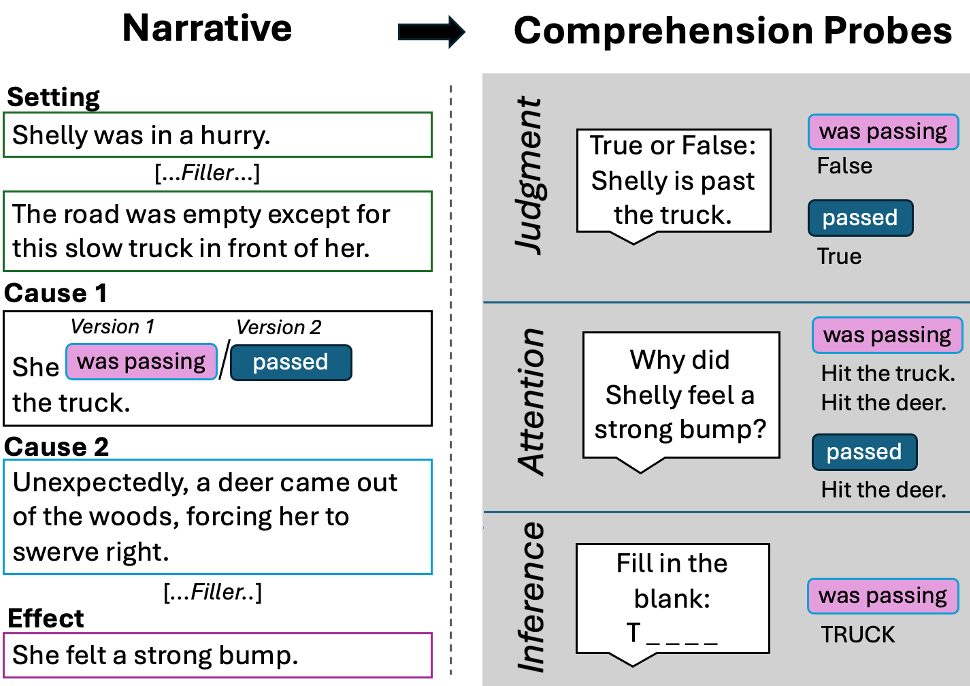
Figure 1: We examine how LLMs understand differences in aspect by presenting LLMs with narratives that have a key word either in the imperfective or perfective (e.g., was passing'' vs.passed'') followed by comprehension probes adapted from previous human studies.
The Expert-in-the-Loop probing pipeline (Figure 2) is designed to facilitate controlled behavioral experiments with LLMs. It incorporates three core stages: prompting, prompt paraphrasing, and model inference. Prompts are constructed to mirror human experimental designs, and prompt paraphrasing introduces controlled variations to ensure robustness. The experiments are conducted across multiple LLMs to support model-agnostic behaviors. This pipeline is applied iteratively, with experts assessing intermediate results to gather converging evidence.
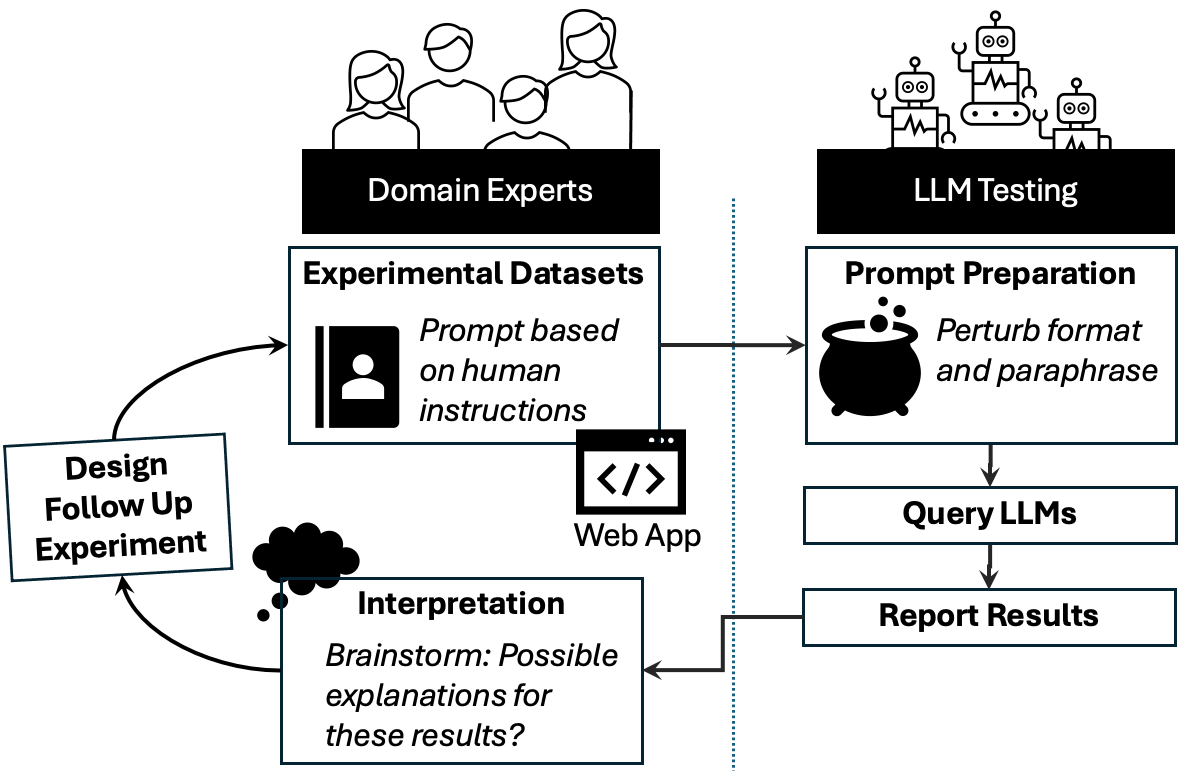
Figure 2: A conceptual overview of our Expert-in-the-Loop probing pipeline for assessing cognitive abilities of LLMs, designed in close collaboration with domain experts from cognitive science.
Key Findings
The paper presents three main experiments: truth value judgments, word completion tasks, and open-ended causal questions.
Truth Value Judgments
The truth value judgment experiment probes the LLMs' ability to infer the completion of events in narratives. The results indicate that LLMs perform well with perfective events but struggle with imperfective events, demonstrating a difficulty with non-prototypical aspect usage.
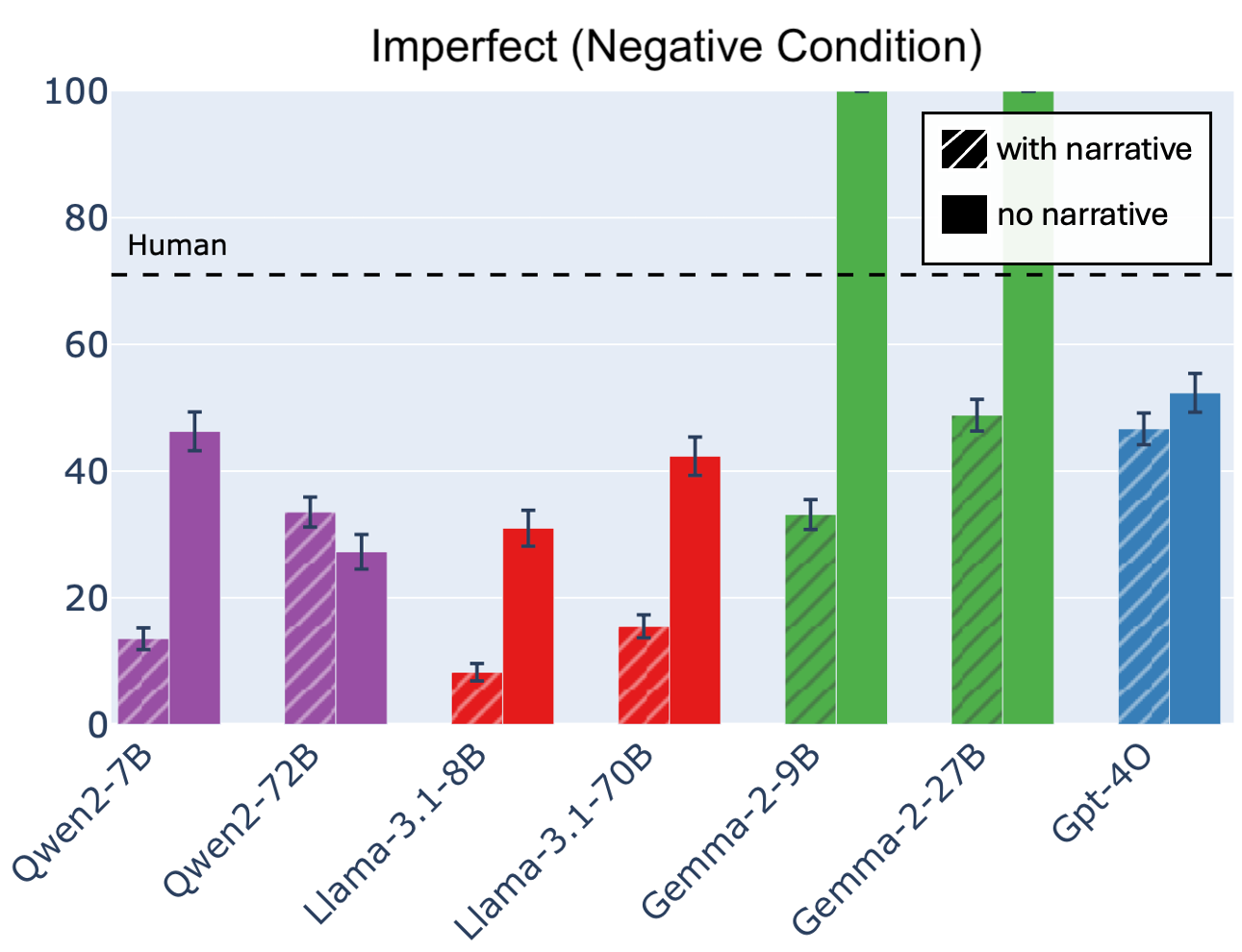
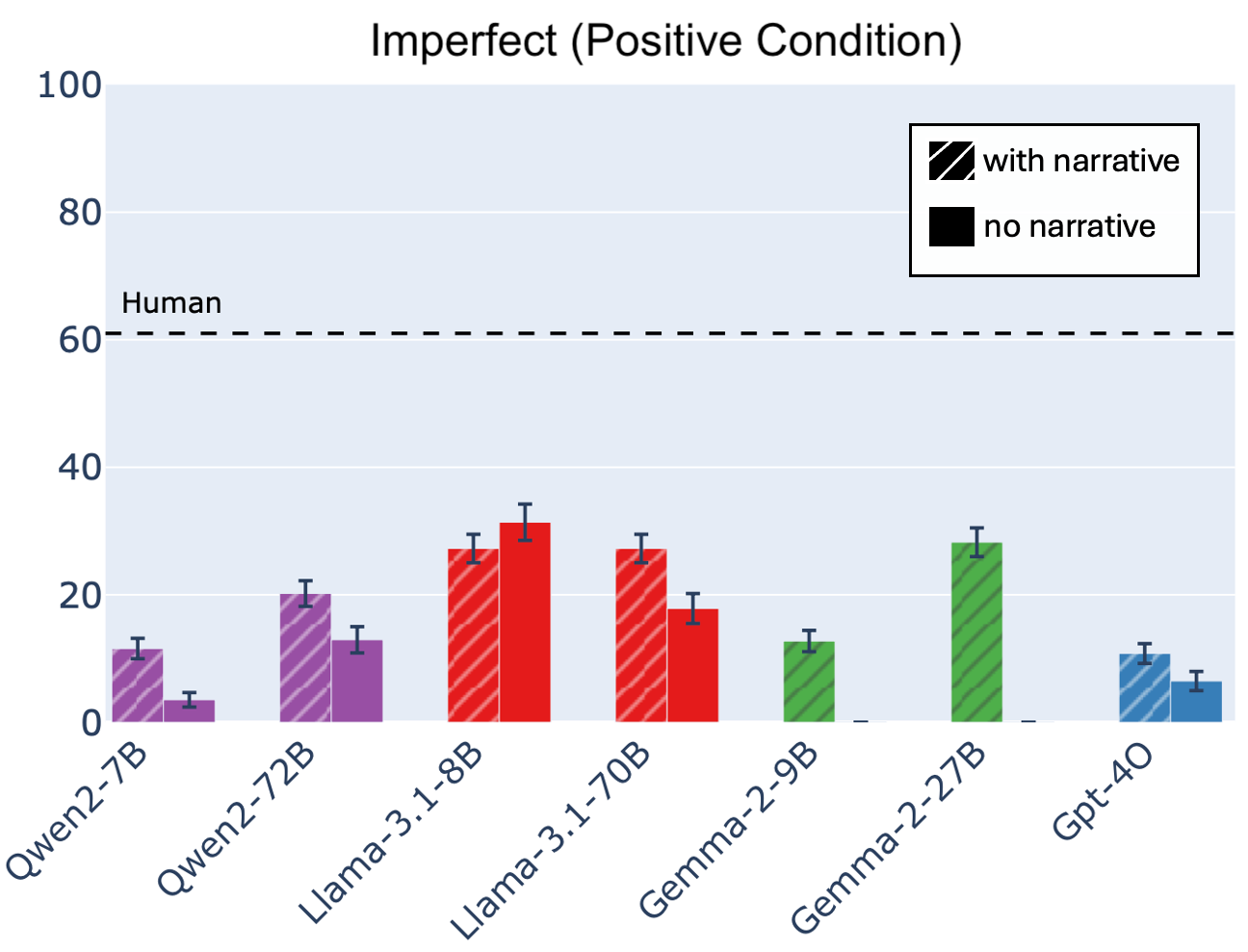
Figure 3: Accuracy in semantic truth-value judgments for events marked with imperfective aspect for LLMs, when the events are embedded within a narrative (shaded bars) versus not. For imperfective events, LLMs have much lower accuracy rates than humans when judging whether the event's resulting final state is valid. Further, LLMs seem to be heavily affected by the presence or absence of a narrative, especially when judging the negative polarity of final states. Notably, the presence or absence of a narrative changes responses in inconsistent directions. Error bars represent the standard error.
Word Completion Task
The word completion task assesses whether LLMs treat aspect in narratives as a temporary signal for retaining or encoding an event. While LLMs exhibit some alignment with human patterns when the word completion is near Cause 1, the frequency of target word responses decreases when the completion is placed near the Effect. This suggests a lack of distal causal narrative integration capabilities.
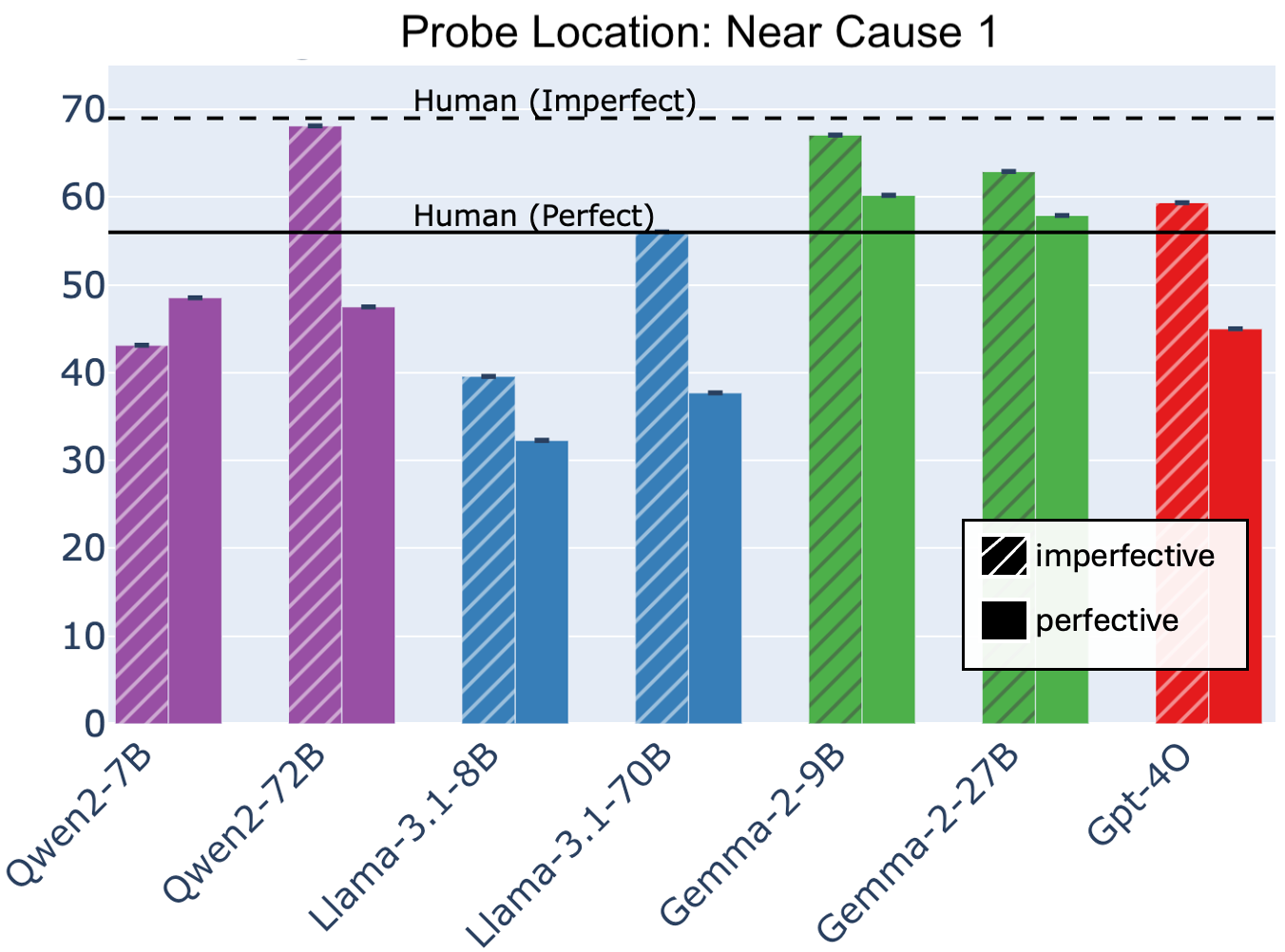
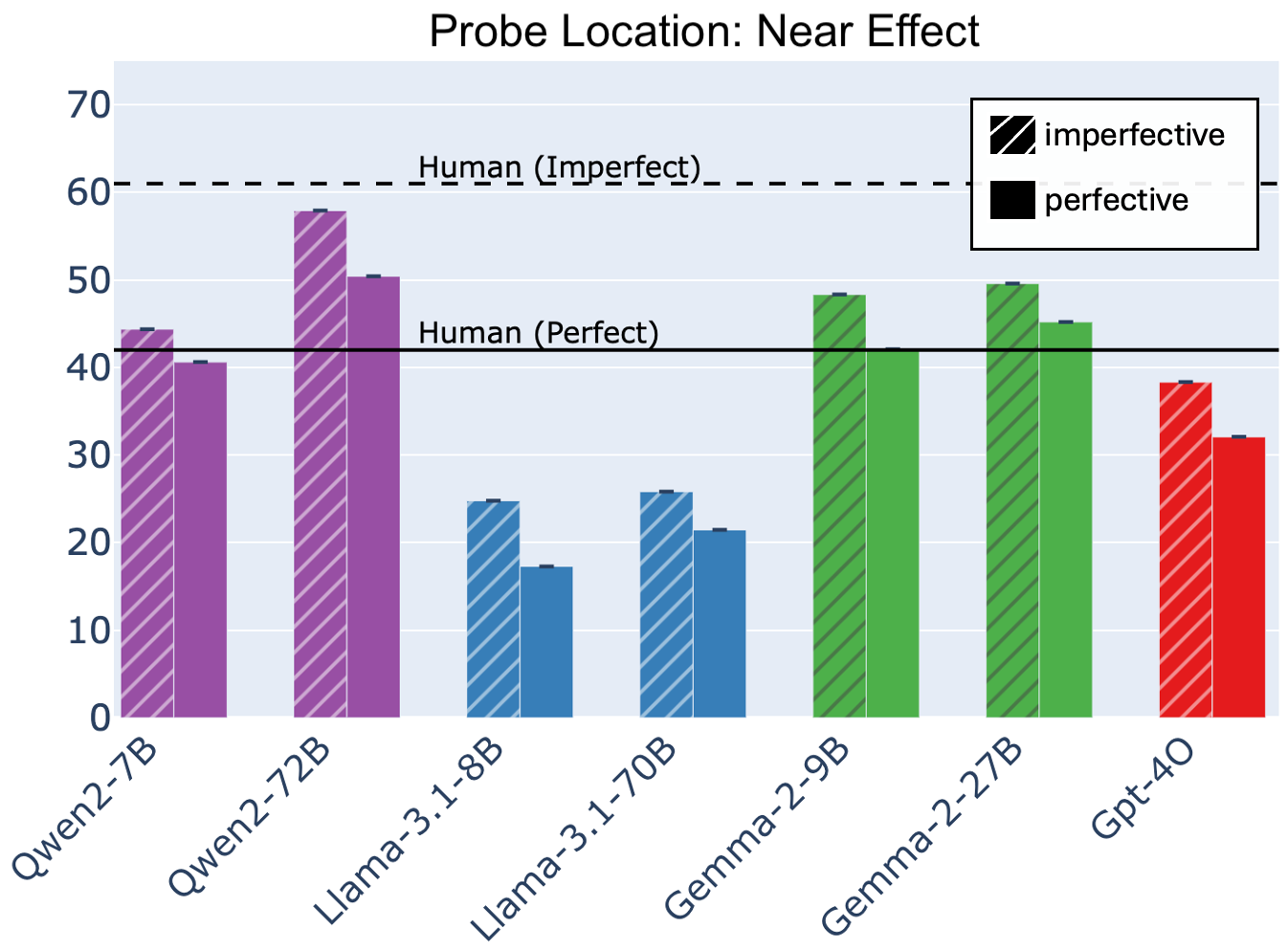
Figure 4: Frequencies at which word completion rates match the target word from Cause 1 across models. Shaded bars are for imperfective aspect in Cause 1. LLM completions have significantly higher match frequencies when the probe directly follows Cause 1 (top) and are reduced after the effect (bottom).
Open-Ended Causal Questioning
The open-ended causal questioning examines whether LLMs' causal inferences are affected by aspect. The results show that LLMs are more likely to infer that Cause 1 caused the effect in the imperfective condition, similar to humans. However, LLMs make this inference less frequently than humans, and they are less likely to offer a perfective Cause 1 as their answer, indicating an over-reliance on prototypicality.
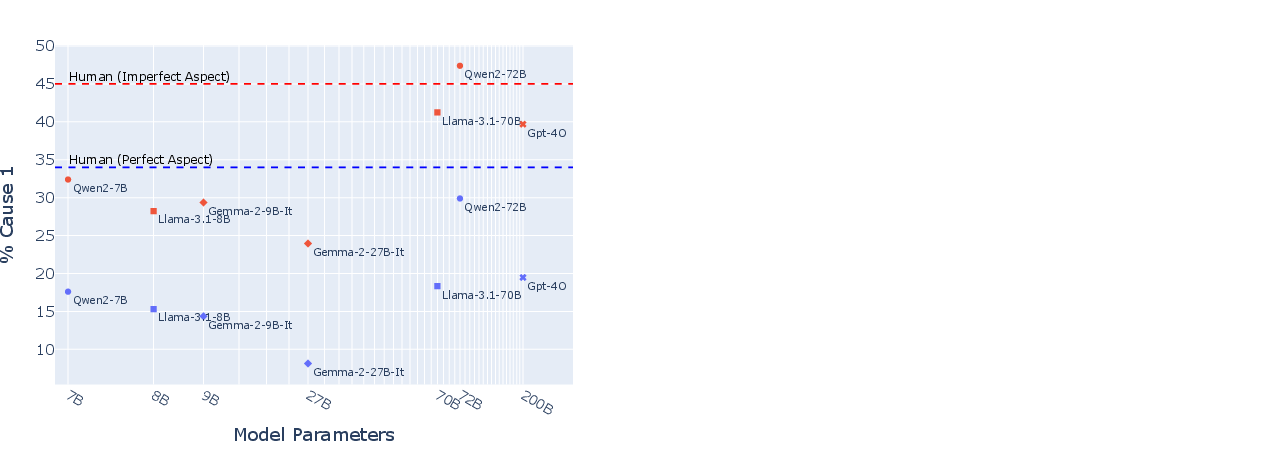
Figure 5: As LLM parameter size increases, there is a trend towards more human-like causal inferences with respect to the Cause 1 event when Cause 1 is in the imperfective. When Cause 1 is in the perfective, LLMs are consistently below human causal inference rates.
Implications and Future Directions
The study suggests that LLMs process aspect in narratives differently from humans due to a lack of pragmatic context-level understanding. The semantic exploration of truth value conditions connected with prototypical and non-prototypical pairings of events indicates that LLMs represent aspect distributionally rather than based on the concepts expressed by aspect.
The findings also reveal a disconnect between declarative knowledge and implicit application in LLMs. While LLMs can articulate the definition of aspect, they fail in implicit application tasks. Future research should explore how this tension extends to other linguistic and cognitive domains.
The authors contribute a generalizable experimental pipeline for assessing LLMs' cognitive capabilities. The pipeline (Figures 6 and 7) includes the creation of datasets with multiple stimuli groups. This framework facilitates future research on the cognitive evaluation of LLMs.
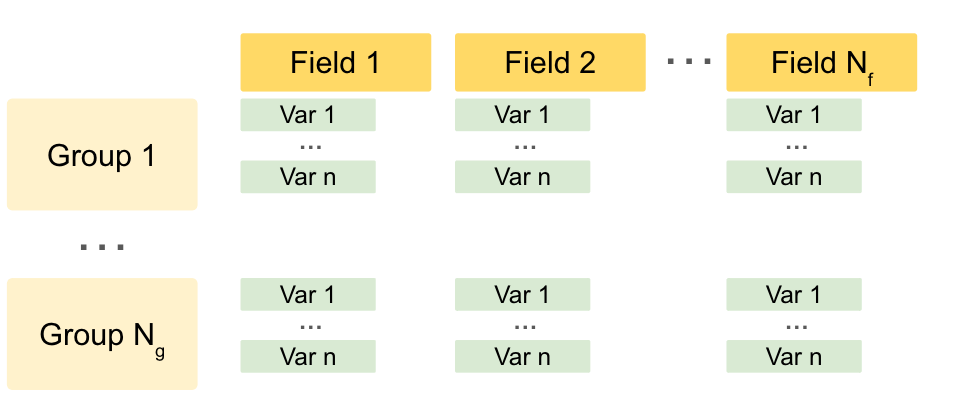
Figure 6: We assume as little structure as possible for experimental datasets to allow for generalizability to other domains. Datasets consist of multiple groups of stimuli, which have different independent variable values (users can indicate which fields are independent variables). Human studies often compare metrics across different stimuli groups to draw conclusions about the effects of independent variables.

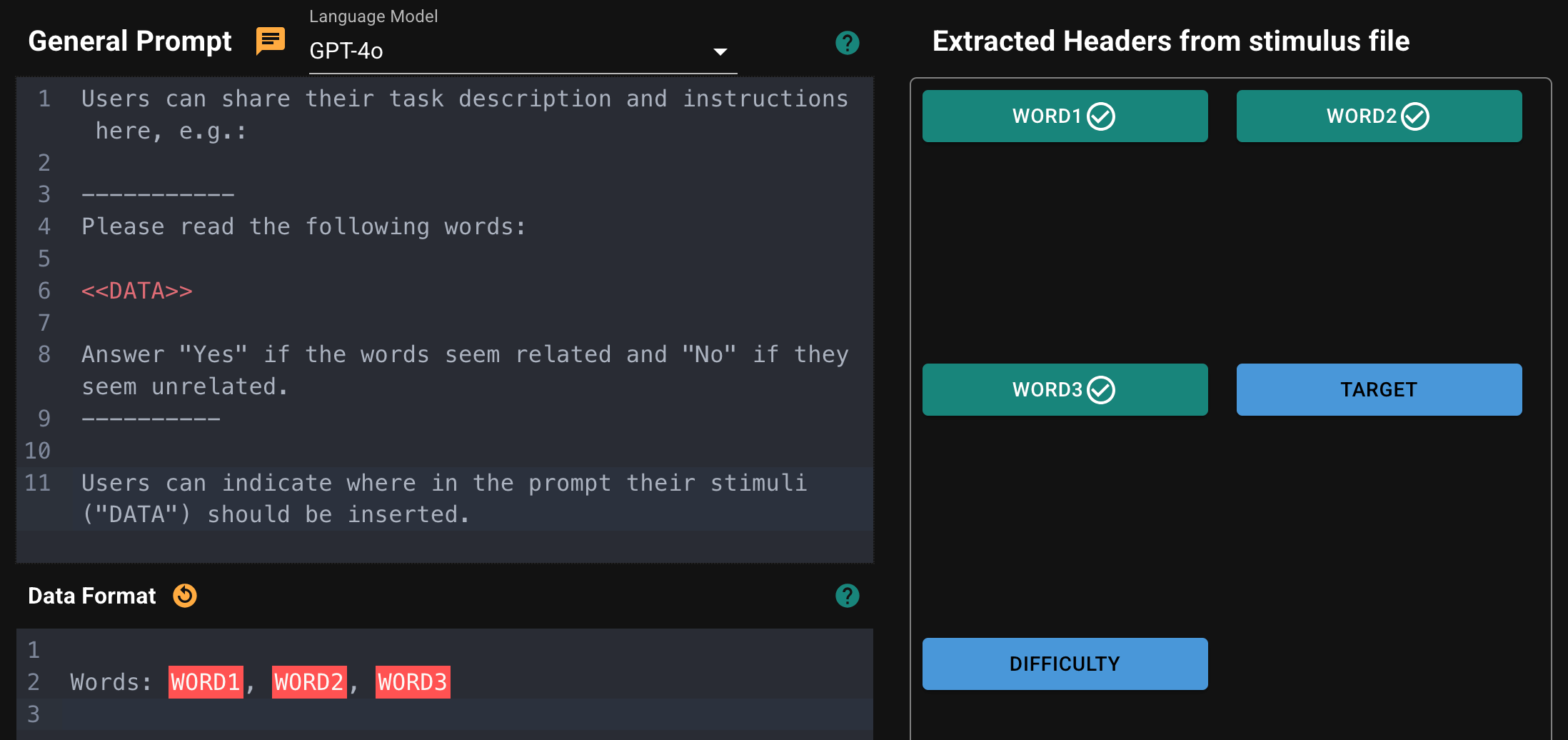
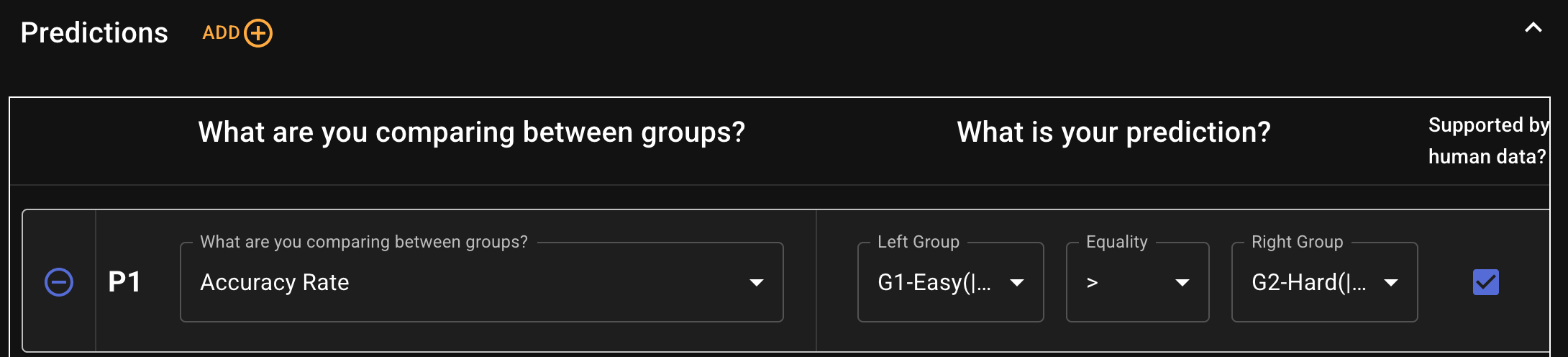
Figure 7: Important components of our web application for collaborating with cognitive scientists. Top: A navigation bar showing the pipeline that cognitive scientists complete to submit an experiment to the pipeline. Middle: Cognitive scientists can share task instructions and select which columns from their uploaded stimulus file should be included in the prompt (we then post-process the prompts and create 30 paraphrased versions). Bottom: Cognitive scientists identify independent variables from their uploaded stimulus file and define groups based on these independent variables.
Conclusion
The study's comprehensive analysis of LLMs' cognitive capabilities in processing linguistic aspect reveals critical limitations in their narrative comprehension. The Expert-in-the-Loop probing pipeline and the experimental findings contribute to the growing understanding of LLM cognition, underscoring the need for further research into the cognitive foundations of LLM behavior.

